本章是系列文章的第八章,用着色算法进行寄存器的分配过程。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
硬盘硬件或者编译器的限制,某些值只能保存在特定的寄存器中
虚拟寄存器(程序中的变量)和物理寄存器(实际的寄存器)
calling convention(调用约定)
同一个程序点alive的多个变量必须指派不同的寄存器
最小寄存器数量 ≥ 最大生命周期变量集合
不过DCC888课程胶片里面给的这个例子,我不太认同:
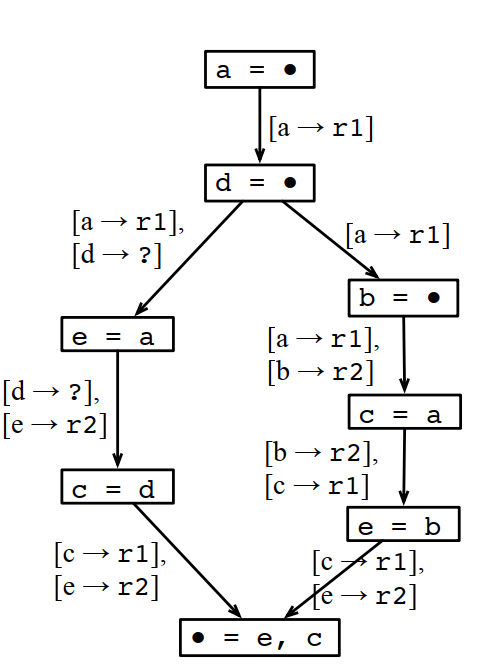
这样分配下来虽然MaxLive是2个,但MinReg需要3个。
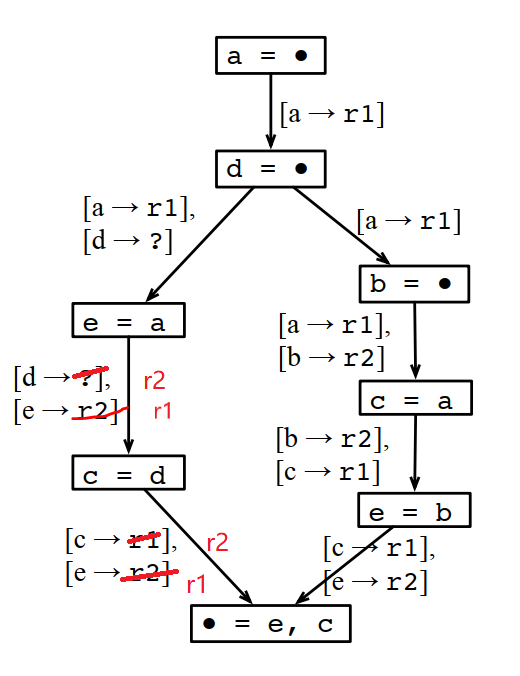
为什么不能这样分配?因为最后输出是e和c,如果多个分支使用的e和c的寄存器不一样,那到汇聚点的时候,就没法直接用,还要做一次转移,这个转移也是需要额外的寄存器的,或者至少需要额外的计算。如果不做转移,就要插入一条store和一条load指令,这个成本更高。
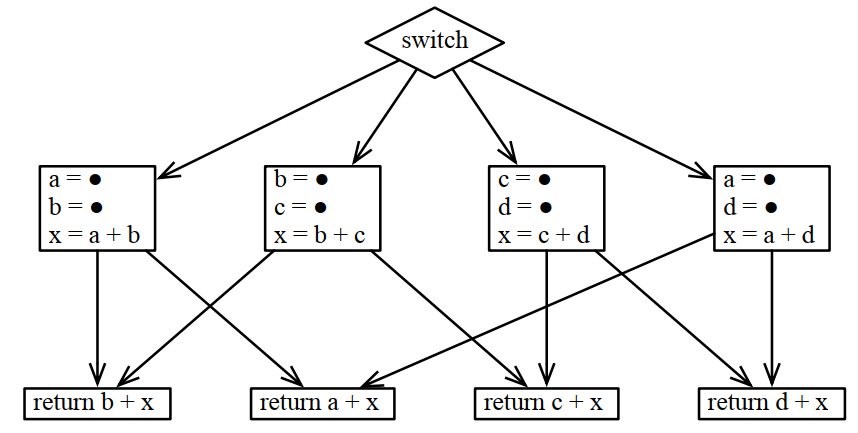
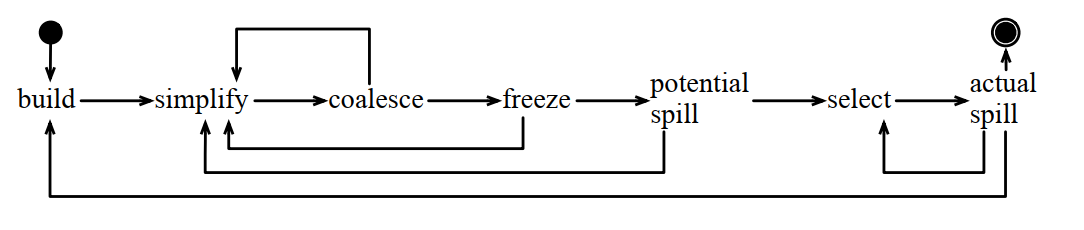
它的复杂度和逻辑等同于图的着色问题。
同样的,对于这样的CFG,同样汇聚点上输出的变量往上的多个分支中,同一个变量需要使用同样的寄存器:
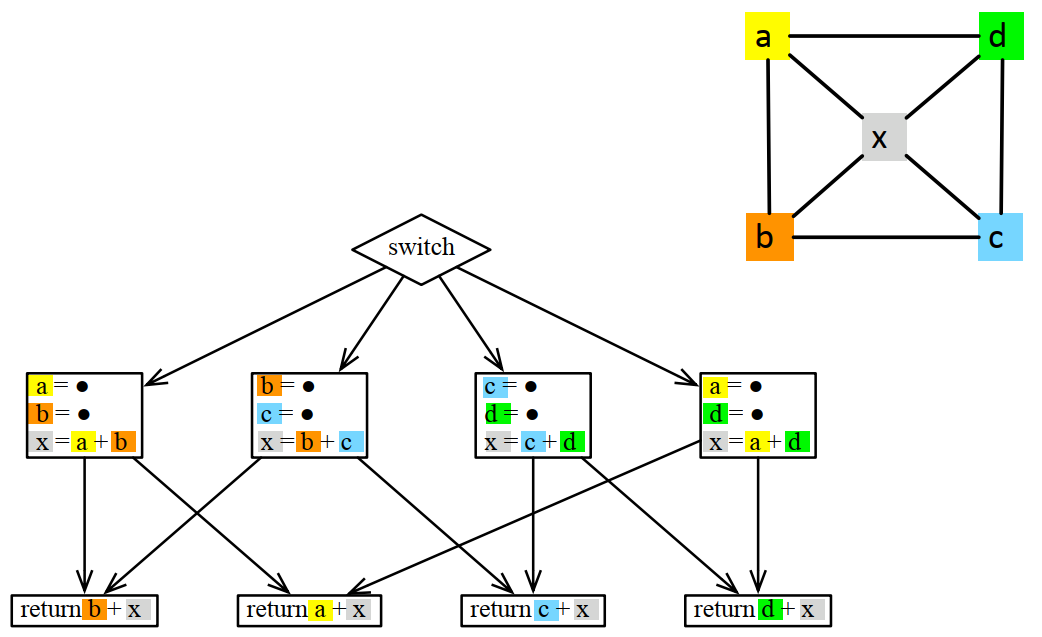
转换成着色问题的逻辑变成这样,对下面的k种颜色,需要k+1个寄存器:
线性扫描基于区间图的贪婪着色算法:
通常用逆后根排序对CFG做排序生成线性化的BB块序列(前面worklist算法也用了逆后根排序,看来这个排序和程序执行之间的关系非常密切)。
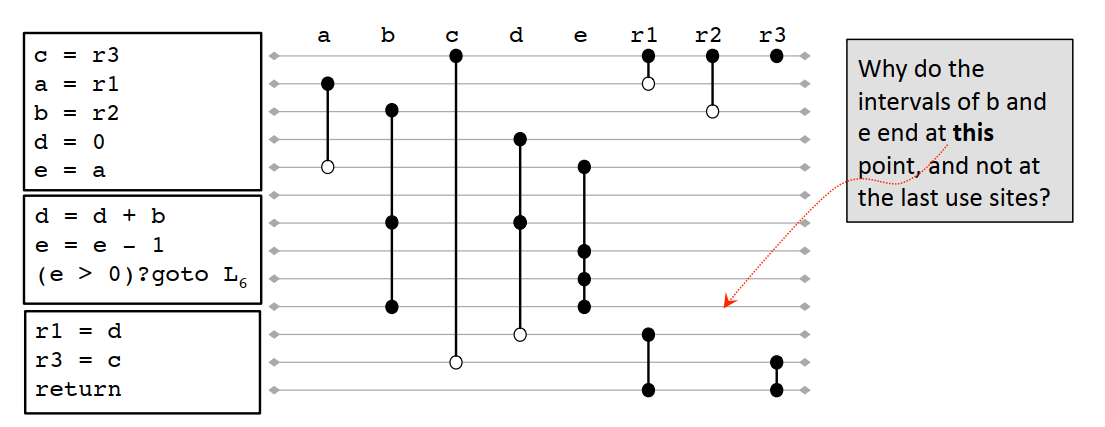
变量v的区间线Iv从v的生命期开始的程序点开始,到v的生命期结束的程序点结束。
为什么b和e的区间线要到第二个BB块最后,而不是在最后一次使用后就结束?因为后面还有分支,根据条件不同,第二个BB块还有可能从L6继续执行。
算法描述如下
1 LINEARSCANREGISTERALLOCATION♧
2 active = {}
3 foreach interval i, in order of increasing start point
4 EXPIREOLDINTERVALS(i)
5 if length(active) = R then
6 SPILLATINTERVAL(i)
7 else
8 register[i] = a register removed from the pool of free registers.
9 Add i to active, sorted by increasing end point
10
11 EXPIREOLDINTERVALS(i)
12 foreach interval j in active, in order of increasing end point
13 if endpoint[j] ≥ startpoint[i] then
14 return
15 remove j from active
16 add register[j] to pool of free registers
17
18 SPILLATINTERVAL(i)
19 spill = last interval in active
20 register[i] = register[spill]
21 location[spill] = new stack location
22 remove spill from active
23 add i to active, sorted by increasing end point
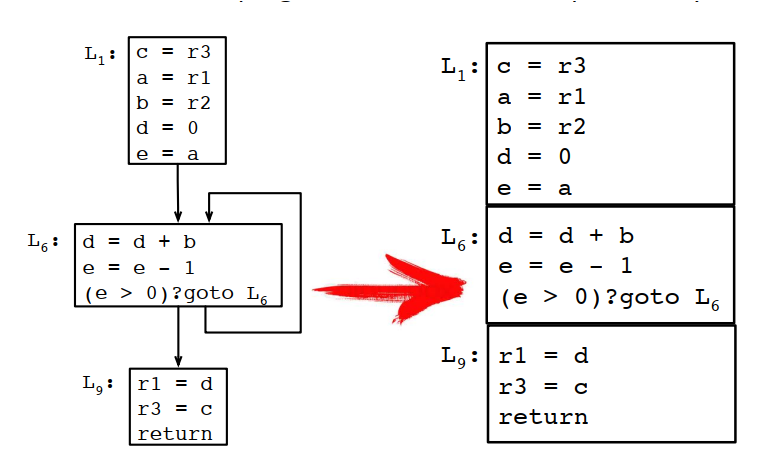
上面的例程经过算法处理之后的寄存器分配结果如下:
上面的结果还不是最优解,需要经过合并
带合并过程的线性扫描算法如下:
1 LINEARSCANREGISTERALLOCATIONWITHCOALESCING
2 active = {}
3 foreach interval i, in order of increasing start point
4 EXPIREOLDINTERVALS(i)
5 if length(active) = R then
6 SPILLATINTERVAL(i)
7 else
8 if definition of i is "a = b" and register[b] ∈ free registers
9 register[i] = register[i(b)]
10 remove register[i(b)] from the list of free registers
11 else
12 register[i] = a register removed from the list of free registers
13 add i to active, sorted by increasing end point
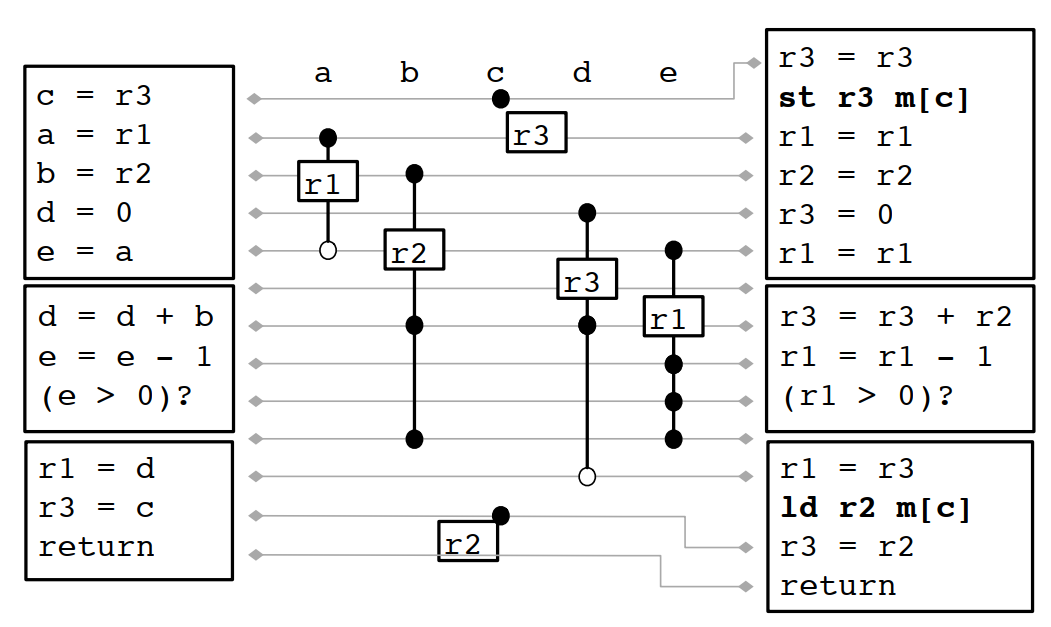
合并之后的结果如下:

线性扫描不是最优解,在一些场景下,和最优解相差还非差大,例如多个分支之间存在生命周期黑洞的情况。
例如对下面的CFG:
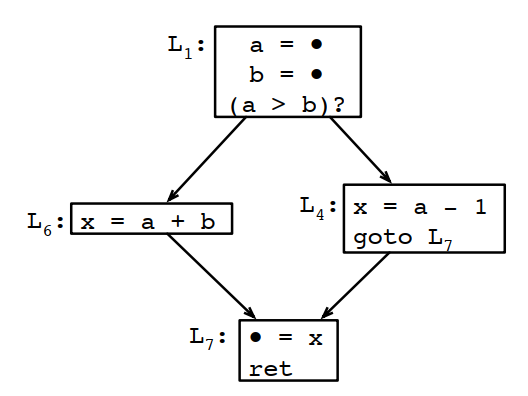
线性扫描处理的结果如下:
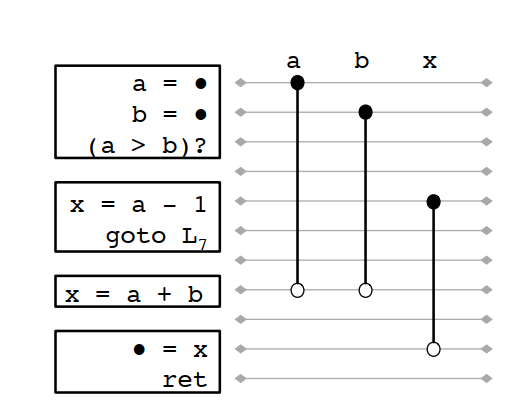
按线性扫描的结果x和a是不能共寄存器的。但如果看生命周期分析结果:
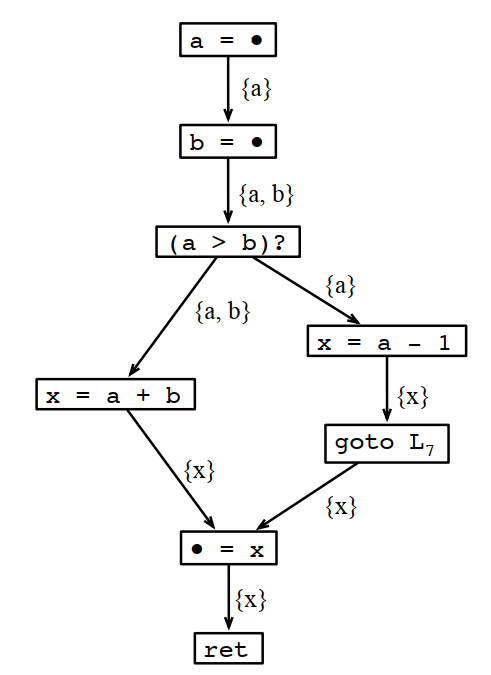
x出现后,a和b都不会再使用,也就是说x肯定是可以和a或者b共用一个寄存器的。
最常见的寄存器分配算法家族是基于干涉图的理念推演出来的。
干涉图是基于控制流图中变量的生命周期范围的网络图:
如果图中存在一个节点m,它的邻接节点小于k,设G' = G \ {m},如果G'能被k种颜色着色,那么G也能被k种颜色着色。
通过肯普简化算法,可以将图简化到只有一个节点,或者简化到只剩下一些高阶节点,这样方便求出图的最小可着色的颜色数。
下面是简化过程:
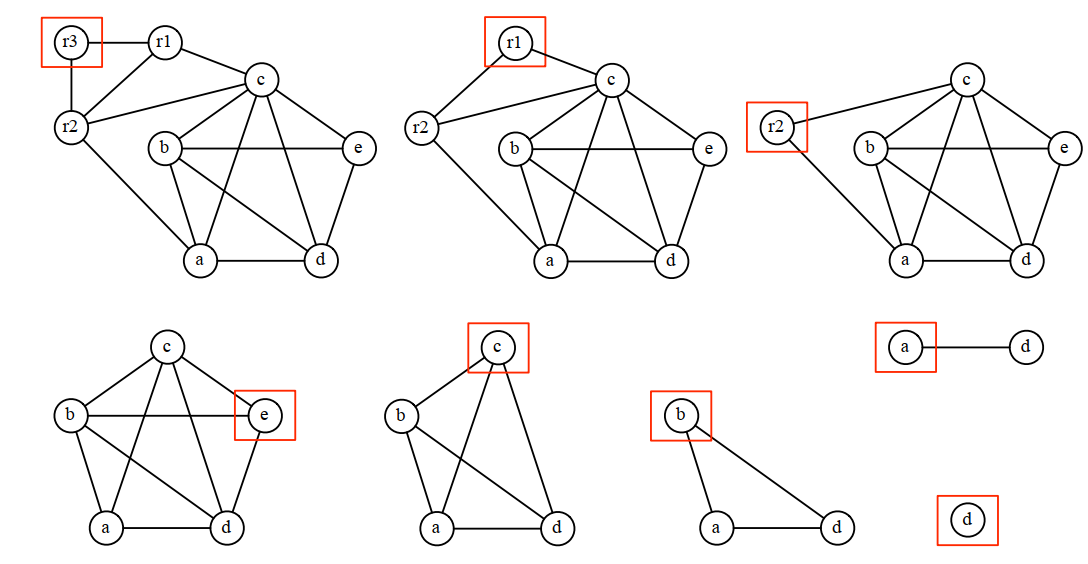
贪婪着色的顺序是肯普简化算法删除节点的顺序的逆序,每次着色都要找一个邻接节点中不存在的颜色进行着色。
针对上面的简化过程,着色过程是这样的:

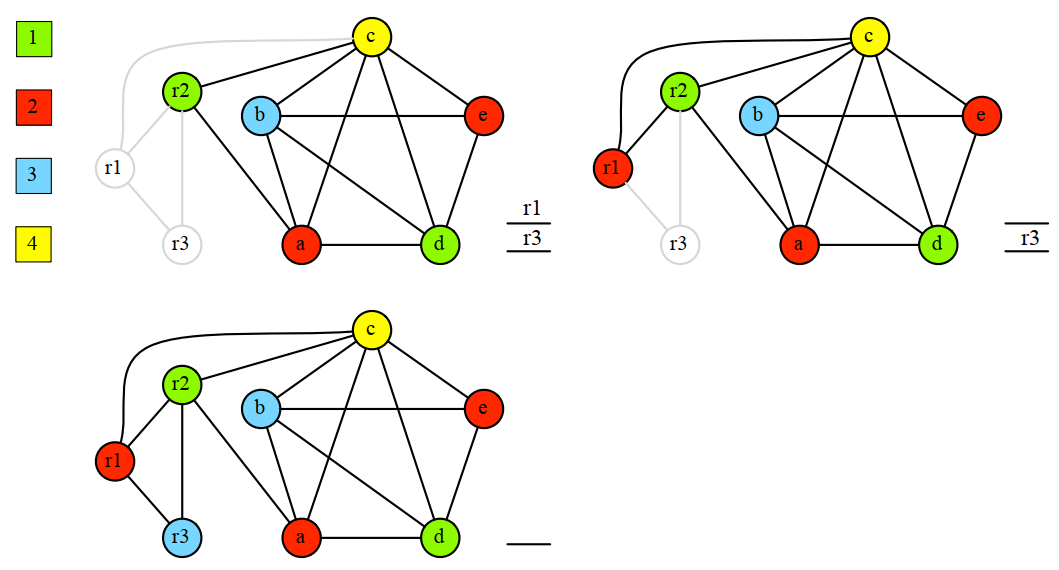
注意,上面的算法只是为了证明一个图是否能被K种颜色进行着色,但不关心是否可以用更少的颜色来着色。
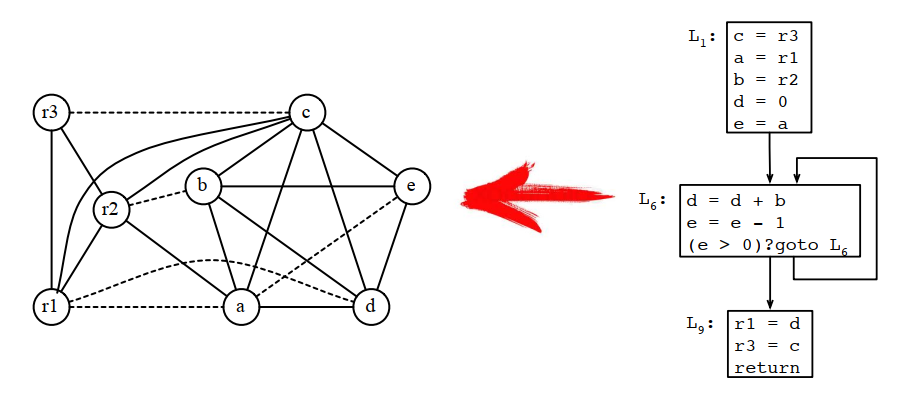
就是基于生命周期生成干涉图的过程:
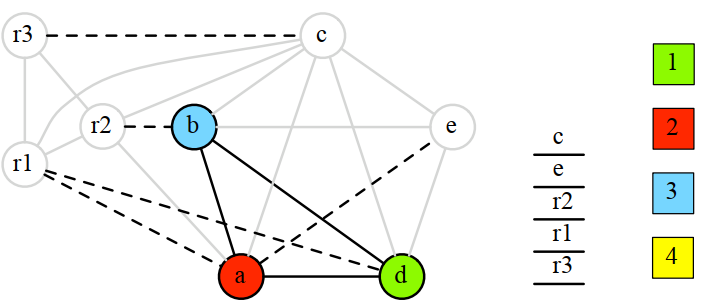
使用肯普算法删除非move相关节点:
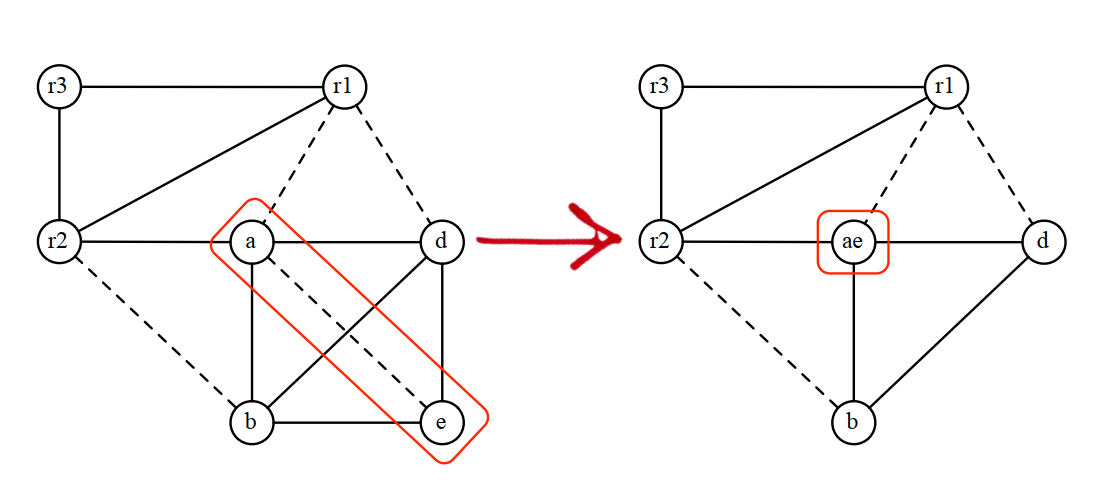
合并过程是将move关联节点合并成一个:
保守合并算法:
Briggs:节点a和b能合并当且仅当ab有更少的高阶(≥k)邻接节点
George:节点a和b能合并,当且仅当,所有a的邻接节点要么和b相互干涉,要么是一个低阶节点
如果前面的的简化和合并都没有影响干涉图,尝试删除一条move干涉关系。
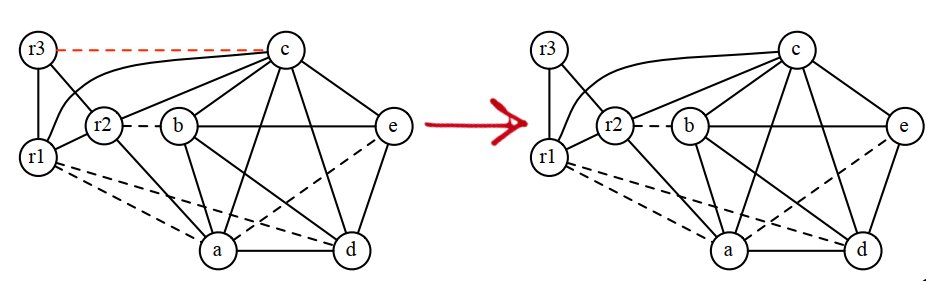
如果找不到低阶节点,就要选择一个节点作为潜在的溢出节点,并将它加入到简化节点栈中。
现在还没有确定会溢出,有可能着色时,发现很多标记了溢出的节点,能够有效着色。
溢出算法的核心是找到一个溢出代价最小的节点,我们给循环内的节点一个更高的代价因子:
1 SPILLCOST(v)
2 cost = 0
3 foreach definition at block B, or use at block B
4 cost += 10^N/D, where
5 N is B's loop nesting factor
6 D is v's degree in the interference graph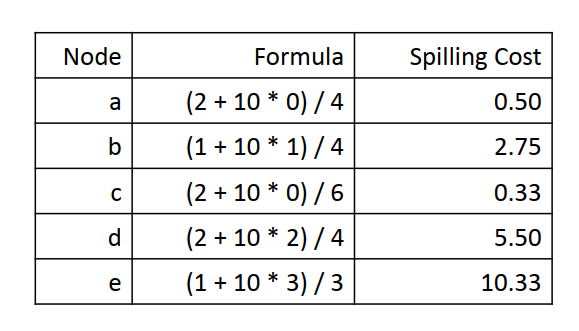
将栈中的节点出栈,并尝试用贪婪着色算法进行着色
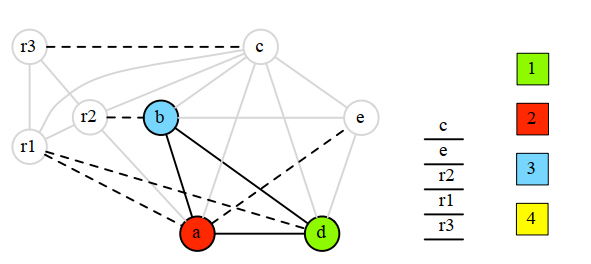
如果确定需要溢出,在变量前后增加load和store指令,并重新走一遍从build开始的整个迭代过程。
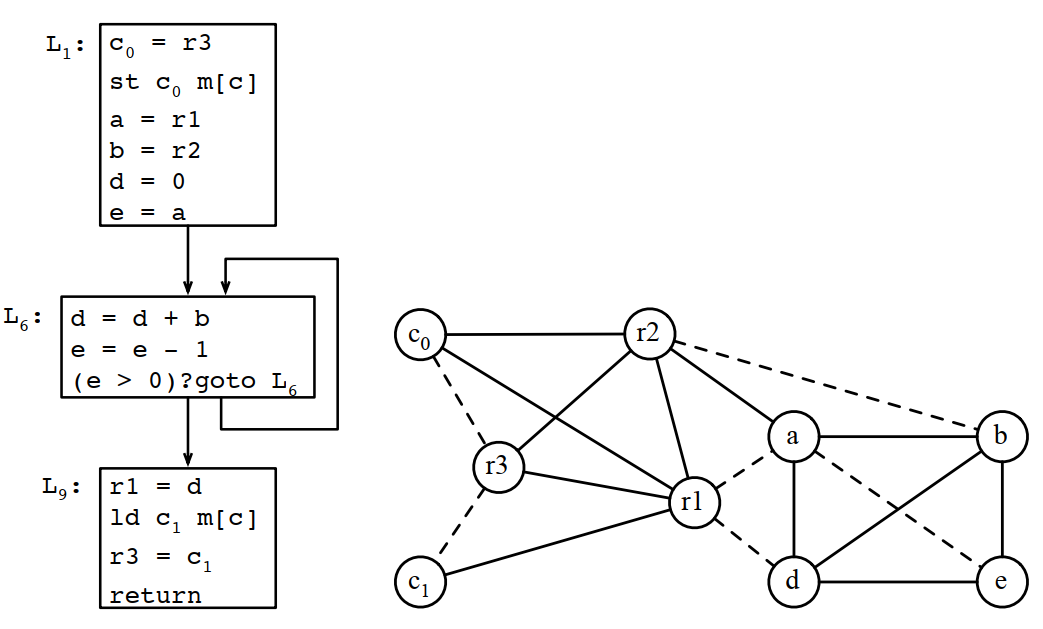
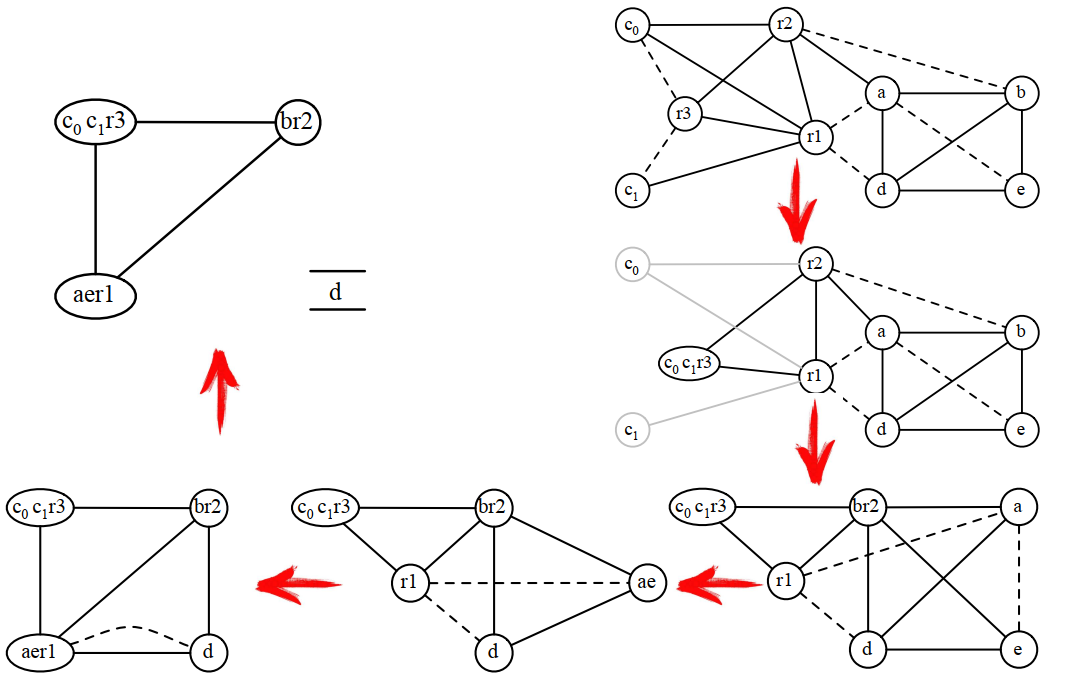
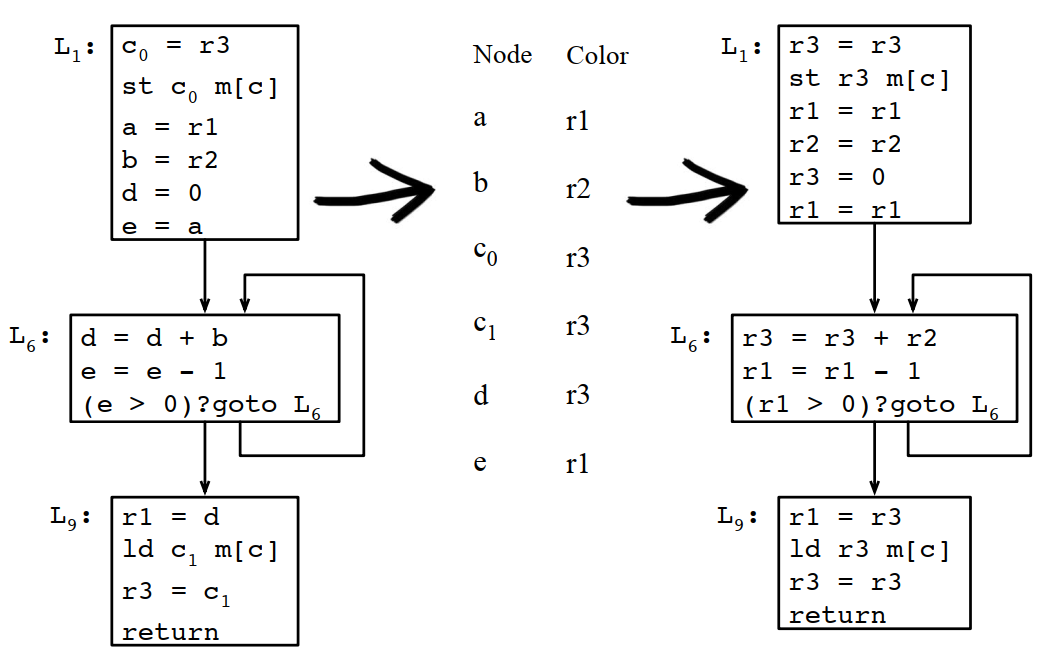
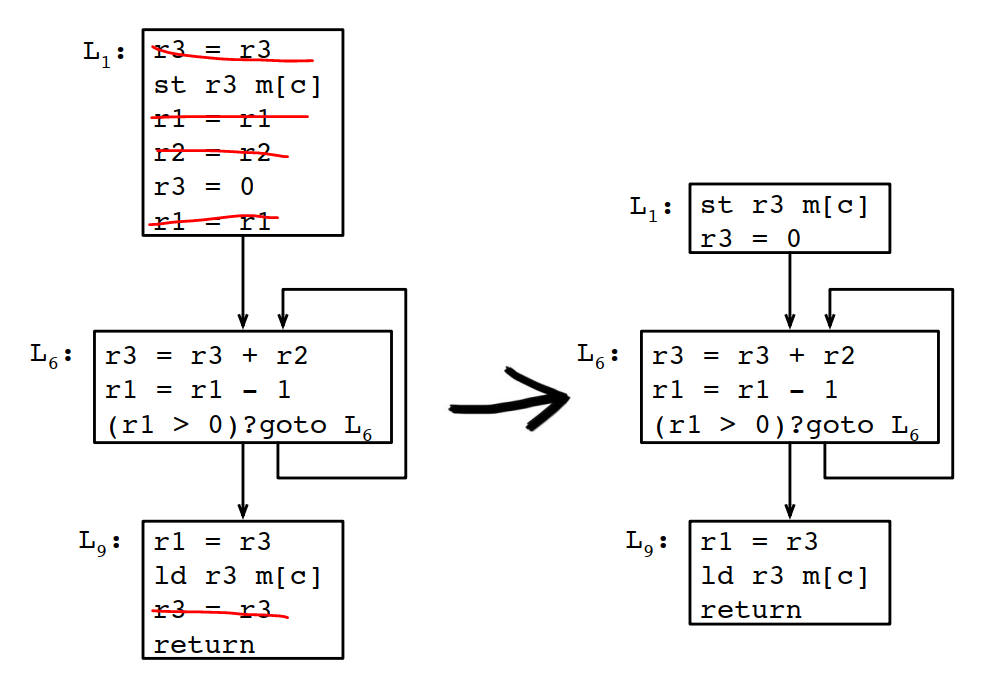
在只有3个寄存器的情况下,通过上面的计算,应该溢出c,将两次c的使用改成c0和c1,重新进行计算:
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
通过rubykoans.com,我在about_array_assignment.rb中遇到了这两段代码你怎么知道第一个是非并行赋值,第二个是一个变量的并行赋值?在我看来,除了命名差异之外,代码几乎完全相同。4deftest_non_parallel_assignment5names=["John","Smith"]6assert_equal["John","Smith"],names7end45deftest_parallel_assignment_with_one_variable46first_name,=["John","Smith"]47assert_equal'John
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否