首届数字人开发大会召开,虚拟数字人成为新热门词汇。
虚拟数字人,是存在于数字世界的“人”,通过动作捕捉、三维建模、语音合成等技术高度还原真实人类,再借助AR/MR/VR等终端呈现出来的立体“人”。在人工智能、虚拟现实等新技术浪潮的带动下,虚拟数字人制作过程得到有效简化、各方面性能获得飞跃式提升,开始从外观的数字化逐渐深入到行为的交互化、思想的智能化。以虚拟主播、虚拟员工等为代表的数字人成功进入大众视野,并以多元的姿态在影视、游戏、传媒、文旅、金融等众多领域大放异彩。

近日,首届数字人开发者大会在北京召开。首届数字人行业盛会由国家互联网信息办公室信息化发展局和中关村科技园区管理委员会作为指导单位,中国信息通信院、浦发银行以及中关村数智人工智能产业联盟主办,凌云光技术协办。
会上,中国人工智能产业发展联盟(简称“AIIA 联盟”)和中关村数智人工智能产业联盟(简称“ZAI 联盟”)数字人工作委员会首次发布了《2020 年虚拟数字人发展白皮书》,白皮书回顾了虚拟数字人发展历程,重点分析了虚拟数字人关键技术和产业发展现状,对虚拟数字人的未来发展趋势进行了展望,剖析了数字人发展中的制约因素。
01 .
什么是虚拟数字人
1、虚拟数字人研究范畴
“虚拟数字人”一词最早源于 1989 年美国国立医学图书馆发起的“可视人计划”(Visible Human Project, YHP)。2001年, 国内以“中国数字化虚拟人体的科技问题”为主题的香山科学会议第 174 次学术讨论会提出了“数字化虚拟人体”的概念。
这些“虚拟数字人”主要是指人体结构的可视化,以三维形式显示人体解剖结构的大小、形状、位置及器官间的相互空间关系,即利用人体信息,实现人体解剖结构的数字化。主要应用于医疗领域的人体解剖教学、临床诊疗等。
与上述医疗领域的数字化人体不同,本篇中所分析的虚拟数字人(以下简称“数字人”)是指具有数字化外形的虚拟人物。与具备实体的机器人不同,虚拟数字人依赖显示设备存在。虚拟数字人宜具备以下三方面特征:
一是拥有人的外观,具有特定的相貌、性别和性格等人物特征;
二是拥有人的行为,具有用语言、面部表情和肢体动作表达的能力;
2、虚拟数字人发展历程
虚拟数字人的发展与其制作技术的进步密不可分,从最早的手工绘制到现在的 CG(Computer Graphics,电脑绘图)、人工智能合成,虚拟数字人大致经历了萌芽、探索、初级和成长四个阶段,详见下图。
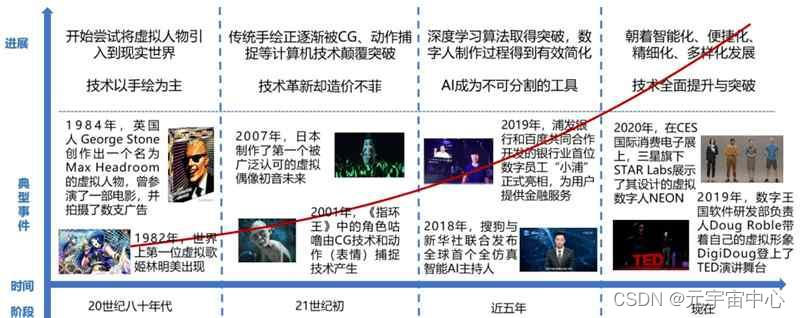
▲虚拟数字人发展历程
20 世纪 80 年代,人们开始尝试将虚拟人物引入到现实世界中,虚拟数字人步入萌芽阶段。该时期虚拟数字人的制作技术以手工绘制为主,应用极为有限。1982 年,日本动画《超时空要塞》播出后,制作方将女主角林明美包装成演唱动画插曲的歌手,并制作了音乐专辑,该专辑成功打入当时日本知名的音乐排行榜 Oricon,林明美也成为了世界上第一位虚拟歌姬。
1984 年,英国人 George Stone 创作出一个名为Max Headroom 的虚拟人物,MAX 拥有人类的样貌和表情动作,身穿西装,佩戴墨镜,曾参演了一部电影,拍摄了数支广告,一度成为英国家喻户晓的虚拟演员。由于技术的限制,其虚拟形象是由真人演员通过特效化妆和手绘实现。
21 世纪初,传统手绘逐渐被 CG、动作捕捉等技术取代,虚拟数字人步入探索阶段。该阶段的虚拟数字人开始达到实用水平,但造价不菲,主要出现在影视娱乐行业,如数字替身、虚拟偶像等。电影制作中的数字替身一般利用动作捕捉技术,真人演员穿着动作捕捉服装,脸上点上表情捕捉点,通过摄像机、动作捕捉设备将真人演员的动作、表情采集处理,经计算机处理后赋予给虚拟角色。
2001 年,《指环王》中的角色咕噜就是由 CG 技术和动作捕捉技术产生,这些技术后续还在《加勒比海盗》、《猩球崛起》等电影制作中使用。2007 年,日本制作了第一个被广泛认可的虚拟数字人“初音未来”,初音未来是二次元风格的少女偶像,早期的人物形象 主 要 利 用 CG 技 术合成 , 人物声音采用雅马哈的VOCALOID系列语音合成,呈现形式还相对粗糙。
近五年,得益于深度学习算法的突破,数字人的制作过程得到有效简化,虚拟数字人开始步入正轨,进入初级阶段。该时期人工智能成为虚拟数字人不可分割的工具,智能驱动的数字人开始崭露头角。
2018 年,新华社与搜狗联合发布的“AI合成主播”,可在用户输入新闻文本后,在屏幕展现虚拟数字人形象并进行新闻播报,且唇形动作能与播报声音实时同步。
当前,虚拟数字人正朝着智能化、便捷化、精细化、多样化发展,步入成长期。2019 年,美国影视特效公司数字王国软件研发部负责人 Doug Roble 在 TED 演讲时展示了自己的虚拟数字人“DigiDoug”,可在照片写实级逼真程度的前提下,进行实时的表情动作捕捉及展现。今年,三星旗下的STAR Labs在CES国际消费电子展上展出了其虚拟数字人项目 NEON,NEON 是一种由人工智能所驱动的虚拟人物,拥有近似真人的形象及逼真的表情动作,具备表达情感和沟通交流的能力。
3、当前虚拟数字人通用系统框架及运作流程
当前虚拟数字人作为新一代人机交互平台,仍处于发展期,还未有统一的通用系统框架。这份白皮书根据虚拟数字人的制作技术以及目前市场上提供的数字人服务和产品结构,总结出虚拟数字人通用系统框架,如下图所示。

虚拟数字人系统一般情况下由人物形象、语音生成、动画生成、音视频合成显示、交互等 5 个模块构成。
人物形象根据人物图形资源的维度,可分为 2D 和 3D 两大类,从外形上又可分为卡通、拟人、写实、超写实等风格;语音生成模块和 动画生成模块可分别基于文本生成对应的人物语音以及与之相匹配的人物动画;音视频合成显示模块将语音和动画合成视频,再显示给用户。

▲虚拟数字人通用系统框架
交互模块为扩展项,根据其有无,可将数字人分为交互型数字人和非交互型数字人。非交互型数字人体统的运作流程如下图非交互类虚拟数字人系统运作流程所示。系统依据目标文本生成对应的人物语音及动画,并合成音视频呈现给用户。

▲非交互类虚拟数字人系统运作流程
该人物模型是预先通过AI技术训练得到的,可通过文本驱动生成语音和对应动画,业内将此模型称为TTSA(Text To Speech & Animation)人物模型。真人驱动型数字人则是通过真人来驱动数字人,主要原理是真人根据视频监控系统传来的用户视频,与用户实时语音,同时通过动作捕捉采集系统将真人的表情、动作呈现在虚拟数字人形象上,从而与用户进行交互。
▲智能驱动型虚拟数字人运作流程

▲真人驱动型虚拟数字人运作流程
02 .
虚拟数字人关键技术趋势
1、虚拟数字人技术架构
当前,虚拟数字人的制作涉及众多技术领域,且制作方式尚未完全定型,通过对现有虚拟数字人制作中涉及的常用技术进行调研,本白皮书在虚拟数字人通用系统框架的基础上提炼出五横两纵的技术架构,如下图所示。

▲虚拟数字人技术架构
这份白皮书重点关注虚拟数字人制作过程涉及的建模、驱动、渲染三大关键技术。
2、建模 :静态扫描建模仍为主流
相机阵列扫描重建替代结构光扫描重建成为人物建模主流方式。早期的静态建模技术以结构光扫描重建为主。结构光扫描重建可以实现 0.1 毫米级的扫描重建精度,但其扫描时间长,一般在 1 秒以上,甚至达到分钟级,对于人体这类运动目标在友好度和适应性方面都差强人意,因此被更多的应用于工业生产、检测领域。
近年来,拍照式相机阵列扫描重建得到飞速发展,目前可实现毫秒级高速拍照扫描(高性能的相机阵列精度可达到亚毫米级),满足数字人扫描重建需求,成为当前人物建模主流方式。
国际上 IR、Ten24 等公司已经将静态重建技术完全商业化,服务于好莱坞大型影视数字人制作,国内凌云光等公司制作的拍照式人体扫描系统也已经在电影、游戏、虚拟主播项目中成功应用。
相比静态重建技术,动态光场重建不仅可以重建人物的几何模型,还可一次性获取动态的人物模型数据,并高品质重现不同视角下观看人体的光影效果,成为数字人建模重点发展方向。
动态光场重建是目前世界上最新的深度扫描技术,此技术可忽略材质,直接采集三维世界的光线,然后实时渲染出真实的动态表演者模型,它主要包含人体动态三维重建和光场成像两部分。
人体动态三维重建一直是计算机视觉、计算机图形学等领域研究的重点,主要采用摄像机阵列采集动态数据,可重建高低频几何、纹理、材质、三维运动信息。
光场成像是计算摄像学领域一项新兴技术,它不同于现有仅展示物体表面光照情况的 2D 光线地图,光场可以存储空间中所有光线的方向和角度,从而产出场景中所有表面的反射和阴影,这为人体三维重建提供了更加丰富的图像信息。
近年来 Mirosoft、Google、Intel、Facebook 等公司都在积极展开相关研究,其中 Microsoft 的 108 摄像机 MRstudio已经在全球各大洲均有建设;Google 的 Relightable 系统将结构光、动态建模、重光照技术集成到一起,在一套系统中包含模型重建、动作重建、光照重建的全部功能;国内清华大学、商汤科技、华为等也展开了相关研究,并取得国际水平的同步进展。
3、驱动 :智能合成 、 动作捕捉迁移
2D、3D 数字人均已实现嘴型动作的智能合成,其他身体部位的动作目前还只支持录播。2D、3D 数字人嘴型动作智能合成的底层逻辑是类似的,都是建立输入文本到输出音频与输出视觉信息的关联映射,主要是对已采集到的文本到语音和嘴型视频(2D)/嘴型动画(3D)的数据进行模型训练,得到一个输入任意文本都可以驱动嘴型的模型,再通过模型智能合成。
然而,2D 视频和 3D 嘴型动画底层的数学表达不一样,2D 视频是像素表达;3D 嘴型动画是 3D 模型对应的 BlendShape 的向量表达。除了嘴型之外的动作,包含眨眼、微点头、挑眉等动画目前都是通过采用一种随机策略或某个脚本策略将预录好的视频/3D 动作进行循环播放来实现。例如 3D 肢体动作目前就是通过在某个位置触发这个预录好的肢体动作数据得到。
触发策略是通过人手动配置得到的,未来希望通过智能分析文本,学习人类的表达,实现自动配置。截至目前,国内外科技企业在数字人动作智能合成方面都有一定进展,国际上如 Reallusion 公司研究的利用语音生成面部表情的 Craytalk 技术已在动画制作中被成功商用,国内搜狗、相芯科技等公司也有部分项目落地应用。
通过将捕捉采集的动作迁移至数字人是目前3D数字人动作生成的主要方式,核心技术是动作捕捉。动作捕捉技术按照实现方式的不同,可分为光学式、惯性式、电磁式及基于计算机视觉的动作捕捉等。现阶段,光学式和惯性式动作捕捉占据主导地位,基于计算机视觉的动作捕捉成为聚焦热点。光学动作捕捉通过对目标上特定光点的监视和跟踪来完成运动捕捉的任务。
最常用的是基于 Marker(马克点)的光学动作捕捉,即在演员身上粘贴能够反射红外光的马克点,通过摄像头对反光马克点的追踪,来对演员的动作进行捕捉。这种方式对动作的捕捉精度高,但对环境要求也高,并且造价高昂。光学式解决方案比较出名的企业有英国的Vicon,美国的 OptiTrack 和魔神(MotionAnalysis),国内的 Nokov、uSens、青瞳视觉等。
惯性动作捕捉主要是基于惯性测量单元(Inertial Measurement Unit,IMU)来完成对人体动作的捕捉,即把集成了加速度计、陀螺仪和磁力计的IMU 绑在人体的特定骨骼节点上,通过算法对测量数值进行计算,从而完成动作捕捉。这种惯性动作捕捉方案价格相对低廉,但精度较低,会随着连续使用时间的增加产生累积误差,发生位置漂移。
惯性式动捕方案的代表性企业有荷兰的 Xsens,以及国内的诺亦腾(Noitom)、幻境、国承万通等。基于计算机视觉的动作捕捉主要是通过采集及计算深度信息来完成对动作的捕捉,是近些年才兴起的技术。这种视觉动捕方式因其简单、易用、低价,已成为目前使用的频率较高的动作捕捉方案,代表性产品有 Leap Motion、微软Kinect 等。以上动捕方案的性能对比如下图所示。

▲主流动作捕捉方案性能对比
4、 渲染:真实性和实时性均大幅提升
PBR(Physically Based Rendering,基于物理的渲染技术)渲染技术的进步以及重光照等新型渲染技术的出现使数字人皮肤纹理变得真实,突破了恐怖谷效应。恐怖谷效应由日本机器人专家森政弘提出,认为人们对机器人的亲和度随着其仿真程度增加而增高,但当达到一个较高的临界点时,亲和度会突然跌入谷底,产生排斥、恐惧和困惑等负面心理。
数字人恐怖谷效应主要由数字人外表、表情动作上与真人的差异带来,其中外表真实感的关键就是皮肤材质的真实感,无论是塑料感还是蜡像感都会给人类带来不适。在 PBR 技术出现之前,限于相关软硬件的发展程度,所有的 3D 渲染引擎,更多的着重在于实现 3D 效果,在真实感体现方面差强人意。
PBR 是基于真实物理世界的成像规律模拟的一类渲染技术的集合,它的关键在于微表面模型和能量守恒计算,通过更真实的反映模型表面反射光线和折射光线的强弱,使得渲染效果突破了塑料感。目前常见的几款 3D 引擎,如UnrealEngine 4, CryEngine 3, Unity 3D 5,均有了各自的 PBR实现。
重光照技术通过采集模拟多种光照条件的图像数据,测算数字人表面光照反射特性,并合成出数字人模型在新的光照下的渲染结果,使计算机中的虚拟数字人在任意虚拟环境下都可以呈现近乎真实的效果,它彻底改变了传统渲染方式通过模拟皮肤复杂的透射反射来计算渲染总会带来误差的局面。

该技术在 2000 年初由南加州大学实验室创建LightStage 平台时提出,并开始了相关研究,目前已经经过 7代的迭代发展,已被成功应用到《阿凡达》、《复仇者联盟》等众多经典影片的角色制作中。国内清华大学、浙江大学也都建设了重光照系统,可以实现高精度人体光照采集与重建。
实时渲染技术的突破助力写实类数字人实现实时交互,应用范围快速扩大。实时渲染指图形数据的实时计算与输出,其每一帧都是针对当时实际的环境光源、相机位置和材质参数计算出来的图像。与离线渲染相比,实时渲染面临较大挑战。一是渲染时长短,实时渲染每秒至少要渲染 30 帧,即在 33 毫秒内完成一帧画面渲染,离线渲染则可以花费数小时甚至更长时间渲染一帧画面;二是计算资源有限,实时渲染受限于时效要求,计算资源一般是不能及时调整,而离线渲染受时效限制较低,可临时调配更多的计算资源。
早期的实时渲染只能选择高度抽象和简化过的渲染算法,牺牲了画面质量。随着硬件能力的提升和算法的突破,渲染速度、渲染效果的真实度、渲染画面的分辨率均大幅提升,在虚拟人物实时渲染方面,已经能做到以假乱真。

2016 年,EpicGames 联合 3Lateral、Cubic Motion、Ninja Theory 等公司联合开发的可实时驱动的虚拟人物在当年的 Siggraph(Special Interest Group for Computer GRAPHICS,计算机图形图像特别兴趣小组,致力于推广和发展计算机绘图和动画制作的软硬件技术)会议中做了演示,成功在消费级的硬件环境下实时渲染了高质量的虚拟角色。
2018 年 5 月,腾讯发布虚拟人 Siren,也一个支持实时渲染的虚拟人物。
现在,在AI+5G的加持下,“虚拟数字人”的蓬勃发展才刚刚开始,而这只是第三产业智能化趋势的一个缩影,随着我国产业转型升级的脚步逐渐加速,将会有各种形态的虚拟数字人出现在各行各业。
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我想为名字验证编写一个正则表达式。正则表达式应包括所有字母(拉丁/法语/德语字符等)。但是我想从中排除数字并允许-。所以基本上它是\w(减)数(加)-。请帮忙。 最佳答案 ^[\p{L}-]+$\p{L}匹配anykindofletterfromanylanguage. 关于ruby-on-rails-rails中的正则表达式匹配[\w]和"-"但不匹配数字,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
在我的应用程序中,我有一个文本字段,用户可以在其中输入类似这样的内容"1,2,3,4"存储到数据库中。现在,当我想使用内部数字时,我有两个选择:"1,2,3,4".split(',')或string.scan(/\d+/)do|x|a两种方式我都得到一个像这样的数组["1","2","3","4"]然后我可以通过在每个数字上调用to_i来使用这些数字。有没有更好的方法可以转换"1,2,3"to[1,2,3]andnot["1","2","3"] 最佳答案 str.split(",").map{|i|i.to_i}但是这个想法对你来说
我有一个随机大小的散列,它可能有类似"100"的值,我想将其转换为整数。我知道我可以使用value.to_iifvalue.to_i.to_s==value来做到这一点,但我不确定我将如何在我的散列中递归地做到这一点,考虑到一个值可以是一个字符串,或一个数组(哈希或字符串),或另一个哈希。 最佳答案 这是一个非常简单的递归实现(尽管必须同时处理数组和散列会增加一些技巧)。deffixnumifyobjifobj.respond_to?:to_i#IfwecancastittoaFixnum,doit.obj.to_ielsifobj
什么是测试格式验证的最佳方法让我们说一个用户名,使用字母数字的正则表达式,但不是纯数字?我一直在我的模型中使用以下验证validates:username,:format=>{:with=>/^[a-z0-9]+[-a-z0-9]*[a-z0-9]+$/i}数字用户名(例如“342”)通过了验证,这是我不想要的。 最佳答案 您想“向前看”一封信:/\A(?=.*[a-z])[a-z\d]+\Z/i 关于ruby-on-rails-Rails格式验证——字母数字,但不是纯数字,我们在Sta
如果至少有两个相邻的数字相同,格式为,我需要打包.这是我的输入:[2,2,2,3,4,3,3,2,4,4,5]以及预期的输出:"2:3,3,4,3:2,2,4:2,5"到目前为止我试过:a=[1,1,1,2,2,3,2,3,4,4,5]a.each_cons(2).any?do|s,t|ifs==t如果相等,也许可以尝试计数器,但那是行不通的。 最佳答案 您可以使用Enumerable#chunk_while(如果你使用的是Ruby>=2.3):a.chunk_while{|a,b|a==b}.flat_map{|chunk|chu