本篇将对 Yarn 调度器中的资源抢占方式进行探究。分析当集群资源不足时,占用量资源少的队列,是如何从其他队列中抢夺资源的。我们将深入源码,一步步分析抢夺资源的具体逻辑。
在资源调度器中,以 CapacityScheduler 为例(Fair 类似),每个队列可设置一个最小资源量和最大资源量。其中,最小资源量是资源紧缺情况下每个队列需保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量。
资源抢占发生的原因,是为了提高资源利用率,资源调度器(包括 Capacity Scheduler 和 Fair Scheduler)会将负载较轻的队列的资源暂时分配给负载重的队列。
仅当负载较轻队列突然收到新提交的应用程序时,调度器才进一步将本属于该队列的资源归还给它。
但由于此时资源可能正被其他队列使用,因此调度器必须等待其他队列释放资源后,才能将这些资源“物归原主”,为了防止应用程序等待时间过长,RM 在等待一段时间后强制回收。
开启容器抢占需要配置的参数 yarn-site.xml:
yarn.resourcemanager.scheduler.monitor.enable
yarn.resourcemanager.scheduler.monitor.policies
这里我们主要分析如何选出待抢占容器这一过程。
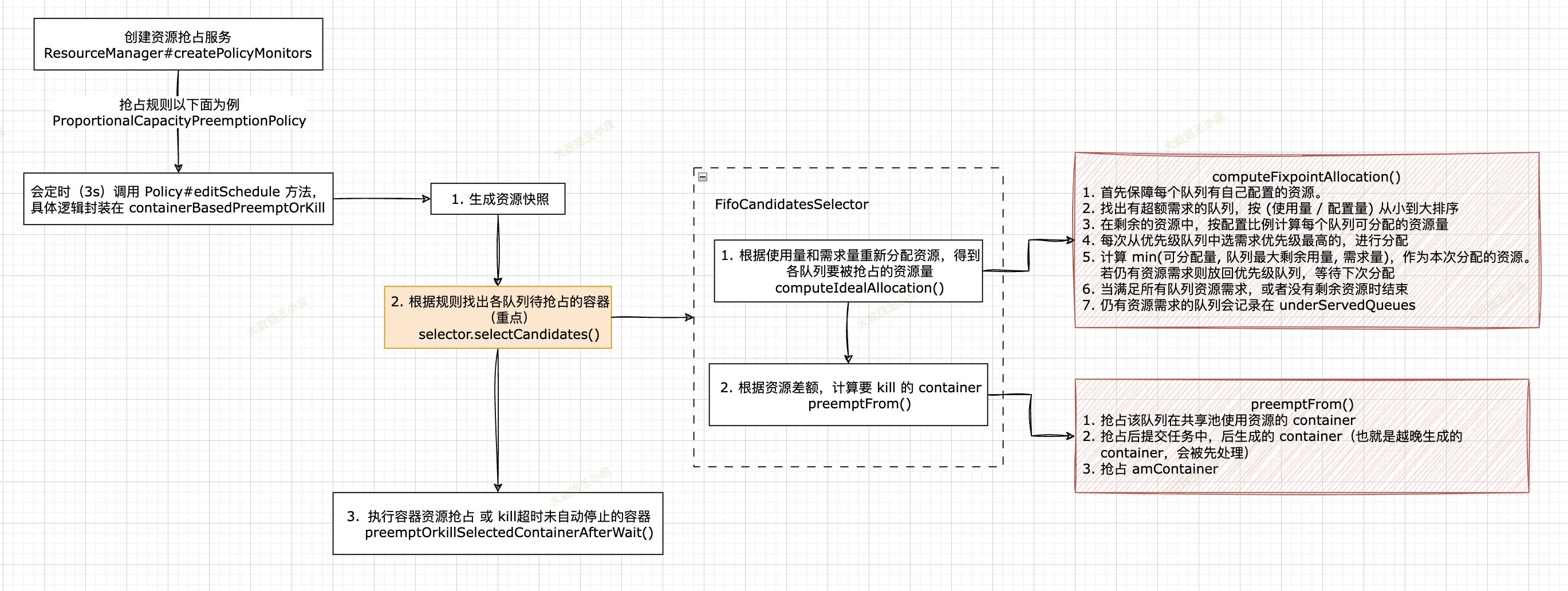
整理流程如下图所示:
接下来我们深入源码,看看具体的逻辑:
首先 ResourceManager 通过 ResourceManager#createPolicyMonitors 方法创建资源抢占服务:
protected void createPolicyMonitors() {
// 只有 capacity scheduler 实现了 PreemptableResourceScheduler 接口,fair 是如何实现资源抢占的?
if (scheduler instanceof PreemptableResourceScheduler
&& conf.getBoolean(YarnConfiguration.RM_SCHEDULER_ENABLE_MONITORS,
YarnConfiguration.DEFAULT_RM_SCHEDULER_ENABLE_MONITORS)) {
LOG.info("Loading policy monitors");
// 是否配置了 scheduler.monitor.policies
// 默认值是 ProportionalCapacityPreemptionPolicy? 代码中没看到默认值,但是 yarn-site.xml doc 中有默认值
List<SchedulingEditPolicy> policies = conf.getInstances(
YarnConfiguration.RM_SCHEDULER_MONITOR_POLICIES,
SchedulingEditPolicy.class);
if (policies.size() > 0) {
for (SchedulingEditPolicy policy : policies) {
LOG.info("LOADING SchedulingEditPolicy:" + policy.getPolicyName());
// periodically check whether we need to take action to guarantee
// constraints
// 此处创建了资源抢占服务类。
// 当此服务启动时,会启动一个线程每隔 PREEMPTION_MONITORING_INTERVAL(默认 3s)调用一次
// ProportionalCapacityPreemptionPolicy 类中的 editSchedule方法,
// 【重点】在此方法中实现了具体的资源抢占逻辑。
SchedulingMonitor mon = new SchedulingMonitor(rmContext, policy);
addService(mon);
}
资源抢占服务会启动一个线程每隔 3 秒钟调用配置的抢占规则,这里以 ProportionalCapacityPreemptionPolicy(比例容量抢占规则)为例介绍其中的抢占具体逻辑(editSchedule 方法):
// ProportionalCapacityPreemptionPolicy#editSchedule
public void editSchedule() {
updateConfigIfNeeded();
long startTs = clock.getTime();
CSQueue root = scheduler.getRootQueue();
// 获取集群当前资源快照
Resource clusterResources = Resources.clone(scheduler.getClusterResource());
// 具体的资源抢占逻辑
containerBasedPreemptOrKill(root, clusterResources);
if (LOG.isDebugEnabled()) {
LOG.debug("Total time used=" + (clock.getTime() - startTs) + " ms.");
}
}
editSchedule 方法很简单,逻辑都被封装到 containerBasedPreemptOrKill() 方法中,我们继续深入。
其中主要分三步:
// 仅保留重要逻辑
private void containerBasedPreemptOrKill(CSQueue root,
Resource clusterResources) {
// ------------ 第一步 ------------ (生成资源快照)
// extract a summary of the queues from scheduler
// 将所有队列信息拷贝到 queueToPartitions - Map<队列名, Map<资源池, 队列详情>>。生成快照,防止队列变化造成计算问题。
for (String partitionToLookAt : allPartitions) {
cloneQueues(root, Resources
.clone(nlm.getResourceByLabel(partitionToLookAt, clusterResources)), partitionToLookAt);
}
// ------------ 第二步 ------------ (找出待抢占的容器)
// compute total preemption allowed
// based on ideal allocation select containers to be preemptionCandidates from each queue and each application
// candidatesSelectionPolicies 默认会放入 FifoCandidatesSelector,
// 如果配置了 INTRAQUEUE_PREEMPTION_ENABLED,会增加 IntraQueueCandidatesSelector
for (PreemptionCandidatesSelector selector :
candidatesSelectionPolicies) {
// 【核心方法】 计算待抢占 Container 放到 preemptMap
toPreempt = selector.selectCandidates(toPreempt,
clusterResources, totalPreemptionAllowed);
}
// 这里有个类似 dryrun 的参数 yarn.resourcemanager.monitor.capacity.preemption.observe_only
if (observeOnly) {
return;
}
// ------------ 第三步 ------------ (执行容器资源抢占 或 kill超时未自动停止的容器)
// preempt (or kill) the selected containers
preemptOrkillSelectedContainerAfterWait(toPreempt);
// cleanup staled preemption candidates
cleanupStaledPreemptionCandidates();
}
第一步资源快照没什么好说的,直接进入到重点:第二步找出待抢占的容器。
即 selector.selectCandidates(),以默认的 FifoCandidatesSelector 实现为例讲解,其他的同理。
主要分两步:
// yarn/server/resourcemanager/monitor/capacity/FifoCandidatesSelector.java
public Map<ApplicationAttemptId, Set<RMContainer>> selectCandidates(
Map<ApplicationAttemptId, Set<RMContainer>> selectedCandidates,
Resource clusterResource, Resource totalPreemptionAllowed) {
// ------------ 第一步 ------------ (根据使用量和需求量重新分配资源)
// Calculate how much resources we need to preempt
// 计算出每个资源池每个队列当前资源分配量,和实际要 preempt 的量
preemptableAmountCalculator.computeIdealAllocation(clusterResource,
totalPreemptionAllowed);
// ------------ 第二步 ------------ (根据资源差额,计算要 kill 的 container)
// 选 container 是有优先级的: 使用共享池的资源 -> 队列中后提交的任务 -> amContainer
for (String queueName : preemptionContext.getLeafQueueNames()) {
synchronized (leafQueue) {
// 省略了大部分逻辑,在后面介绍
// 从 application 中选出要被抢占的容器
preemptFrom(fc, clusterResource, resToObtainByPartition,
skippedAMContainerlist, skippedAMSize, selectedCandidates,
totalPreemptionAllowed);
}
}
我们先来看「根据使用量和需求量重新分配资源」,即 PreemptableResourceCalculator#computeIdealAllocation()
// 计算每个队列实际要被 preempt 的量
public void computeIdealAllocation(Resource clusterResource,
Resource totalPreemptionAllowed) {
for (String partition : context.getAllPartitions()) {
TempQueuePerPartition tRoot = context.getQueueByPartition(
CapacitySchedulerConfiguration.ROOT, partition);
// 这里计算好每个队列超出资源配置的部分,存在 TempQueuePerPartition
// preemptableExtra 表示可以被抢占的
// untouchableExtra 表示不可被抢占的(队列配置了不可抢占)
// yarn.scheduler.capacity.<queue>.disable_preemption
updatePreemptableExtras(tRoot);
tRoot.idealAssigned = tRoot.getGuaranteed();
// 【重点】遍历队列树,重新计算资源分配,并计算出每个队列计划要 Preempt 的量
recursivelyComputeIdealAssignment(tRoot, totalPreemptionAllowed);
}
// 计算实际每个队列要被 Preempt 的量 actuallyToBePreempted(有个阻尼因子,不会一下把所有超量的都干掉)
calculateResToObtainByPartitionForLeafQueues(context.getLeafQueueNames(),
clusterResource);
}
}
我们直接深入到 recursivelyComputeIdealAssignment() 方法中的核心逻辑:重新计算各队列资源分配值 AbstractPreemptableResourceCalculator#computeFixpointAllocation()
主要逻辑如下:
// 按一定规则将资源分给各个队列
protected void computeFixpointAllocation(Resource totGuarant,
Collection<TempQueuePerPartition> qAlloc, Resource unassigned,
boolean ignoreGuarantee) {
// 传进来 unassigned = totGuarant
// 有序队列,(使用量 / 配置量) 从小到大排序
PriorityQueue<TempQueuePerPartition> orderedByNeed = new PriorityQueue<>(10,
tqComparator);
// idealAssigned = min(使用量,配置量)。 对于不可抢占队列,则再加上超出的部分,防止资源被再分配。
if (Resources.greaterThan(rc, totGuarant, used, q.getGuaranteed())) {
q.idealAssigned = Resources.add(q.getGuaranteed(), q.untouchableExtra);
} else {
q.idealAssigned = Resources.clone(used);
}
// 如果该队列有超出配置资源需求,就把这个队列放到 orderedByNeed 有序队列中(即这个队列有资源缺口)
if (Resources.lessThan(rc, totGuarant, q.idealAssigned, curPlusPend)) {
orderedByNeed.add(q);
}
}
// 此时 unassigned 是 整体可用资源 排除掉 所有已使用的资源(used)
// 把未分配的资源(unassigned)分配出去
// 方式就是从 orderedByNeed 中每次取出 most under-guaranteed 队列,按规则分配一块资源给他,如果仍不满足就按顺序再放回 orderedByNeed
// 直到满足所有队列资源,或者没有资源可分配
while (!orderedByNeed.isEmpty() && Resources.greaterThan(rc, totGuarant,
unassigned, Resources.none())) {
Resource wQassigned = Resource.newInstance(0, 0);
// 对于有资源缺口的队列,重新计算他们的资源保证比例:normalizedGuarantee。
// 即 (该队列保证量 / 所有资源缺口队列保证量)
resetCapacity(unassigned, orderedByNeed, ignoreGuarantee);
// 这里返回是个列表,是因为可能有需求度(优先级)相等的情况
Collection<TempQueuePerPartition> underserved = getMostUnderservedQueues(
orderedByNeed, tqComparator);
for (Iterator<TempQueuePerPartition> i = underserved.iterator(); i
.hasNext();) {
TempQueuePerPartition sub = i.next();
// 按照 normalizedGuarantee 比例能从剩余资源中分走多少。
Resource wQavail = Resources.multiplyAndNormalizeUp(rc, unassigned,
sub.normalizedGuarantee, Resource.newInstance(1, 1));
// 【重点】按一定规则将资源分配给队列,并返回剩下的资源。
Resource wQidle = sub.offer(wQavail, rc, totGuarant,
isReservedPreemptionCandidatesSelector);
// 分配给队列的资源
Resource wQdone = Resources.subtract(wQavail, wQidle);
// 这里 wQdone > 0 证明本次迭代分配出去了资源,那么还会放回到待分配资源的集合中(哪怕本次已满足资源请求),直到未再分配资源了才退出。
if (Resources.greaterThan(rc, totGuarant, wQdone, Resources.none())) {
orderedByNeed.add(sub);
}
Resources.addTo(wQassigned, wQdone);
}
Resources.subtractFrom(unassigned, wQassigned);
}
// 这里有可能整个资源都分配完了,还有队列资源不满足
while (!orderedByNeed.isEmpty()) {
TempQueuePerPartition q1 = orderedByNeed.remove();
context.addPartitionToUnderServedQueues(q1.queueName, q1.partition);
}
}
上面第 5 步是重点,也就是 sub.offer(),是计算给该队列在保证值之外,还能提供多少资源:
/**
* 计算队列 idealAssigned,在原有基础上增加新分配的资源。同时返回 avail 中未使用的资源。
* 参数说明:
* avail 按比例该队列能从剩余资源中分配到的
* clusterResource 整体资源量
* considersReservedResource ?
* idealAssigned = min(使用量,配置量)
*/
Resource offer(Resource avail, ResourceCalculator rc,
Resource clusterResource, boolean considersReservedResource) {
// 计算的是还有多少可分配资源的空间( maxCapacity - assigned )
Resource absMaxCapIdealAssignedDelta = Resources.componentwiseMax(
Resources.subtract(getMax(), idealAssigned),
Resource.newInstance(0, 0));
// remain = avail - min(avail, (max - assigned), (current + pending - assigned))
// 队列接受资源的计算方法:可提供的资源,队列最大资源-已分配资源,当前已使用资源+未满足的资源-min(使用量,配置量) 三者中的最小值。
Resource accepted = Resources.min(rc, clusterResource,
absMaxCapIdealAssignedDelta,
Resources.min(rc, clusterResource, avail, Resources
.subtract(
Resources.add((considersReservedResource
? getUsed()
: getUsedDeductReservd()), pending),
idealAssigned)));
Resource remain = Resources.subtract(avail, accepted);
Resources.addTo(idealAssigned, accepted);
return remain;
}
核心的资源重新分配算法逻辑已经计算完毕,剩下的就是:
根据重新计算的资源分配,得到各队列超用的资源,这部分就是要被抢占的资源。
这里不会一下把队列超用的资源都干掉,有个阻尼因子,用于平滑抢占处理。
回到 selector.selectCandidates(),上面已经介绍了各队列抢占量的计算逻辑,接下来介绍「如何选出各队列中的 container」
public Map<ApplicationAttemptId, Set<RMContainer>> selectCandidates(
Map<ApplicationAttemptId, Set<RMContainer>> selectedCandidates,
Resource clusterResource, Resource totalPreemptionAllowed) {
// ......
// ------------ 第二步 ------------ (根据资源差额,计算要 kill 的 container)
// 根据计算得到的要抢占的量,计算各资源池各队列要 kill 的 container
List<RMContainer> skippedAMContainerlist = new ArrayList<>();
// Loop all leaf queues
// 这里是有优先级的: 使用共享池的资源 -> 队列中后提交的任务 -> amContainer
for (String queueName : preemptionContext.getLeafQueueNames()) {
// 获取该队列在每个资源池要被抢占的量
Map<String, Resource> resToObtainByPartition =
CapacitySchedulerPreemptionUtils
.getResToObtainByPartitionForLeafQueue(preemptionContext,
queueName, clusterResource);
synchronized (leafQueue) {
// 使用共享池资源的,先处理
Map<String, TreeSet<RMContainer>> ignorePartitionExclusivityContainers =
leafQueue.getIgnoreExclusivityRMContainers();
for (String partition : resToObtainByPartition.keySet()) {
if (ignorePartitionExclusivityContainers.containsKey(partition)) {
TreeSet<RMContainer> rmContainers =
ignorePartitionExclusivityContainers.get(partition);
// 最后提交的任务,会被最先抢占
for (RMContainer c : rmContainers.descendingSet()) {
if (CapacitySchedulerPreemptionUtils.isContainerAlreadySelected(c,
selectedCandidates)) {
// Skip already selected containers
continue;
}
// 将 Container 放到待抢占集合 preemptMap 中
boolean preempted = CapacitySchedulerPreemptionUtils
.tryPreemptContainerAndDeductResToObtain(rc,
preemptionContext, resToObtainByPartition, c,
clusterResource, selectedCandidates,
totalPreemptionAllowed);
}
}
}
// preempt other containers
Resource skippedAMSize = Resource.newInstance(0, 0);
// 默认是 FifoOrderingPolicy,desc 也就是最后提交的在最前面
Iterator<FiCaSchedulerApp> desc =
leafQueue.getOrderingPolicy().getPreemptionIterator();
while (desc.hasNext()) {
FiCaSchedulerApp fc = desc.next();
if (resToObtainByPartition.isEmpty()) {
break;
}
// 从 application 中选出要被抢占的容器(后面介绍)
preemptFrom(fc, clusterResource, resToObtainByPartition,
skippedAMContainerlist, skippedAMSize, selectedCandidates,
totalPreemptionAllowed);
}
// Can try preempting AMContainers
Resource maxAMCapacityForThisQueue = Resources.multiply(
Resources.multiply(clusterResource,
leafQueue.getAbsoluteCapacity()),
leafQueue.getMaxAMResourcePerQueuePercent());
preemptAMContainers(clusterResource, selectedCandidates, skippedAMContainerlist,
resToObtainByPartition, skippedAMSize, maxAMCapacityForThisQueue,
totalPreemptionAllowed);
}
}
return selectedCandidates;
}
把要被抢占的 container 都选出来之后,就剩最后一步, kill 这些 container。
回到 containerBasedPreemptOrKill():
private void containerBasedPreemptOrKill(CSQueue root,
Resource clusterResources) {
// ......
// ------------ 第三步 ------------ (执行容器资源抢占 或 kill超时未自动停止的容器)
// preempt (or kill) the selected containers
preemptOrkillSelectedContainerAfterWait(toPreempt);
// cleanup staled preemption candidates
cleanupStaledPreemptionCandidates();
}
至此,分析完毕整个资源抢占的过程。
总结一下主要逻辑:
参考文章:
Yarn FairScheduler的抢占机制详解_小昌昌的博客的博客-CSDN博客
Yarn抢占最核心剖析_Geoffrey Turing的博客-CSDN博客 - 针对 fair
Yarn调度之CapacityScheduler源码分析资源抢占
Better SLAs via Resource-preemption in YARN's CapacityScheduler - Cloudera Blog
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序