分布式的环境中会不会出现脏数据的情况呢?类似单机程序中线程安全的问题。观察下面的例子
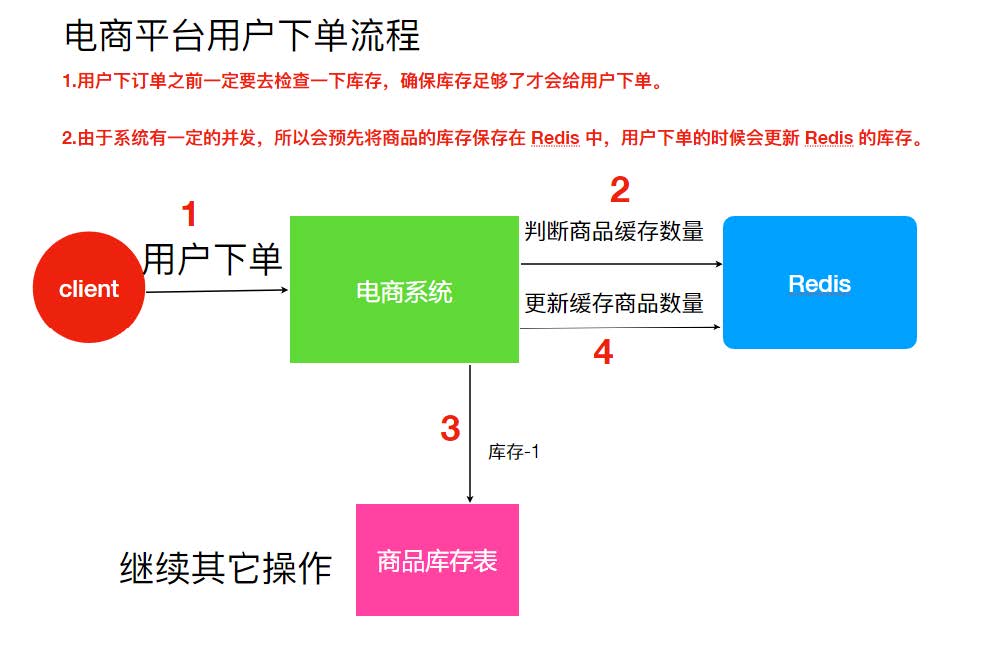
上面的设计是存在线程安全问题
问题
解决方法
用锁把 2、3、4 步锁住,让他们执行完之后,另一个线程才能进来执行。
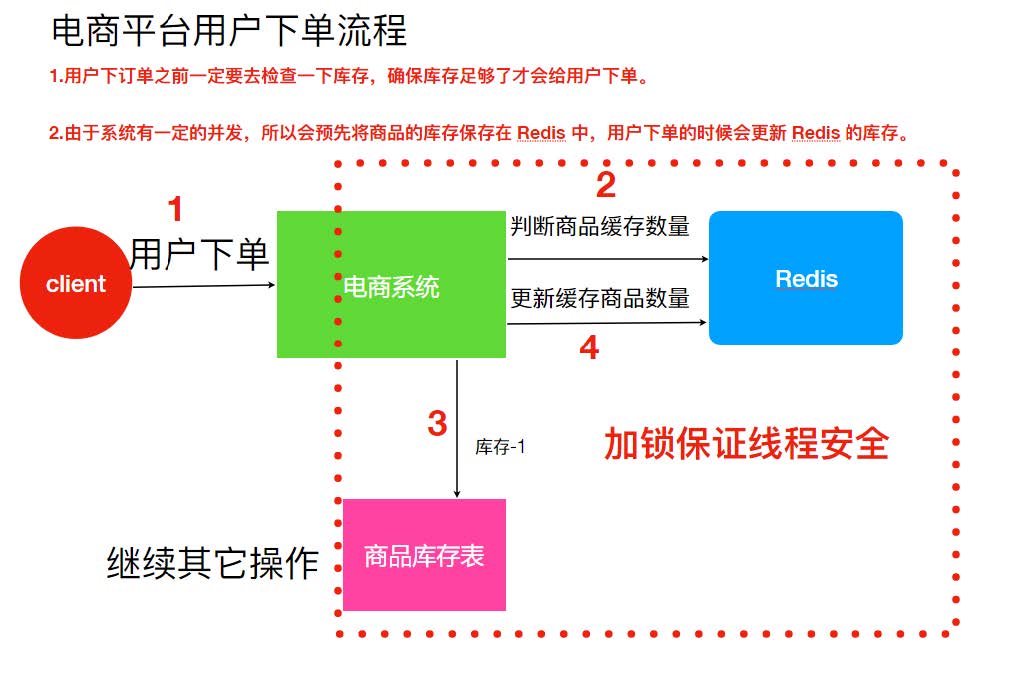
公司业务发展迅速,系统应对并发不断提高,解决方案是要增加一台机器,结果会出现更大的问题
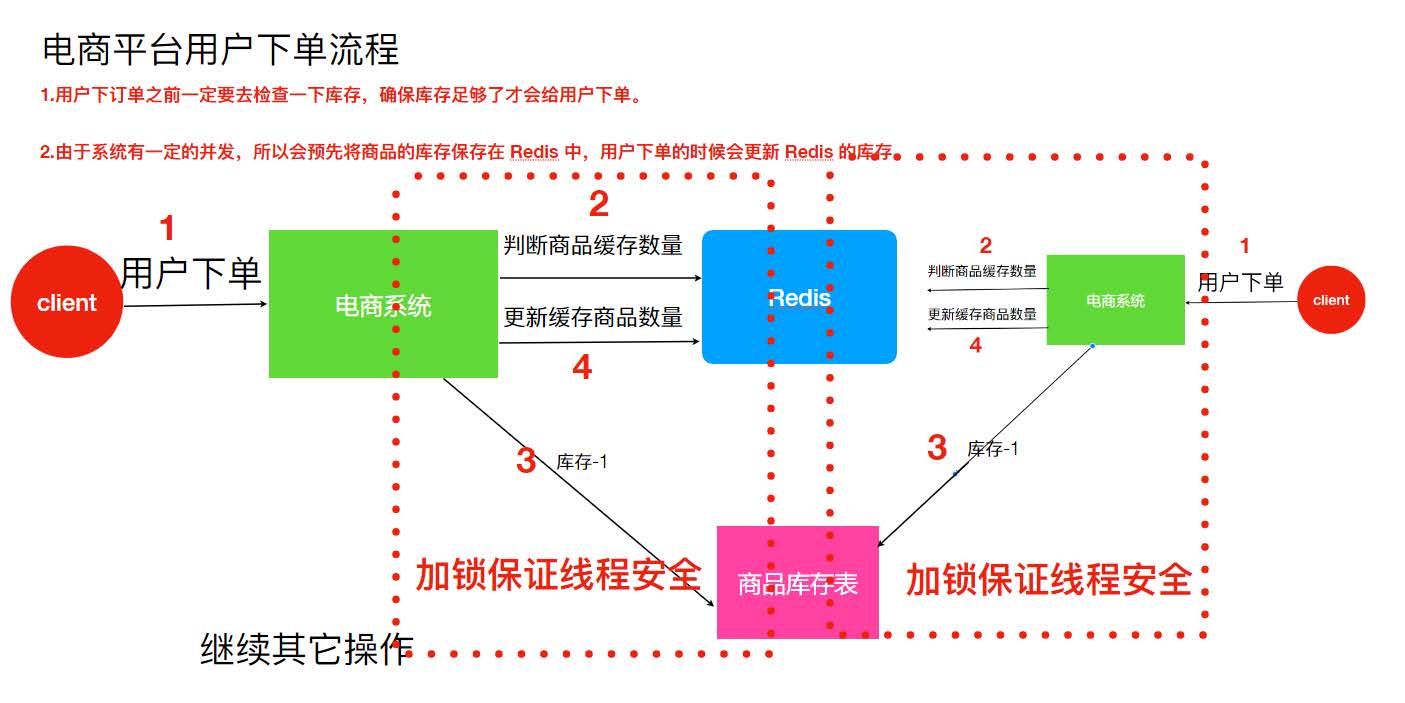
假设有两个下单请求同时到来,分别由两个机器执行,那么这两个请求是可以同时执行了,依然存在超卖的问题。
因为如图所示系统是运行在两个不同的 JVM 里面,不同的机器上,增加的锁只对自己当前 JVM 里面的线程有效,对于其他 JVM 的线程是无效的。所以现在已经不是线程安全问题。需要保证两台机器加的锁是同一个锁,此时分布式锁就能解决该问题。
分布式锁的作用:在整个系统提供一个全局、唯一的锁,在分布式系统中每个系统在进行相关操作的时候需要获取到该锁,才能执行相应操作。
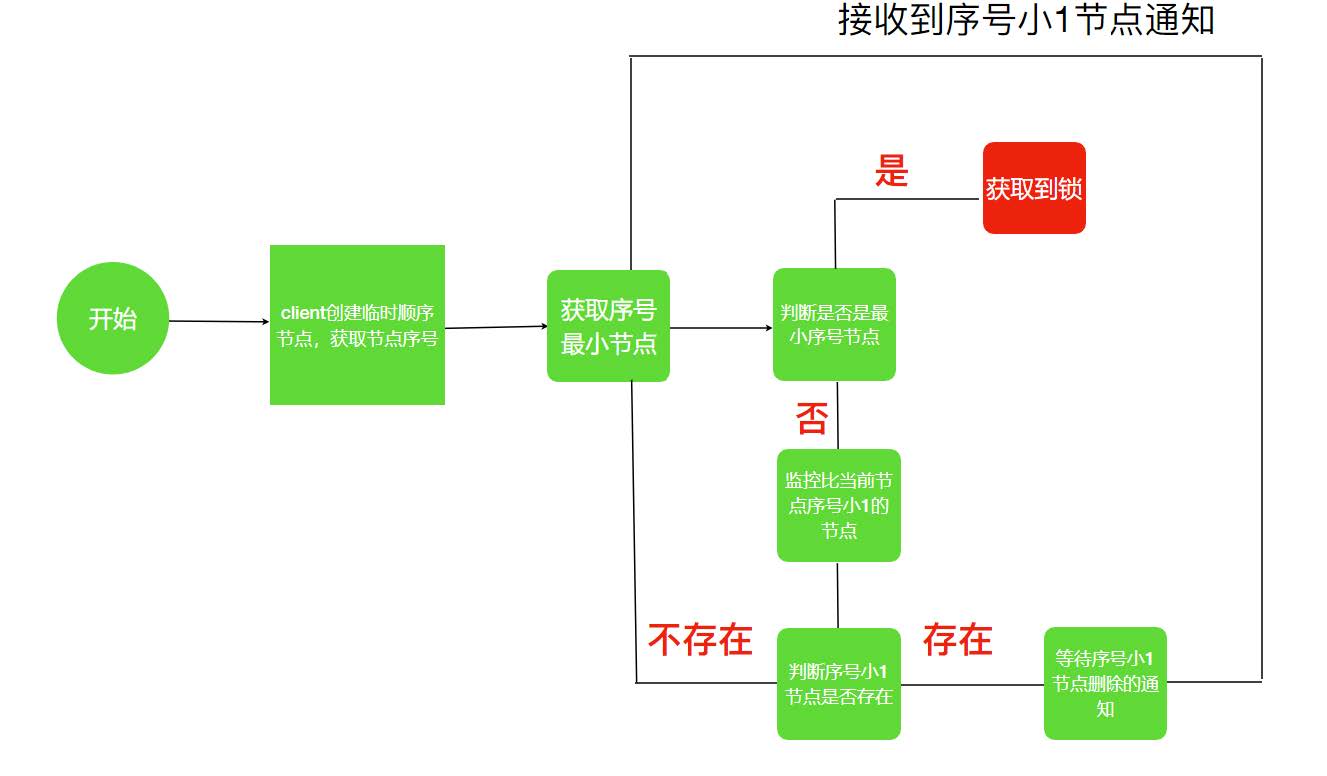
利用Zookeeper可以创建临时带序号节点的特性来实现一个分布式锁
实现思路
流程图
//zk实现分布式锁
public class DisLockTest {
public static void main(String[] args) {
//使用10个线程模拟分布式环境
for (int i = 0; i < 10; i++) {
new Thread(new DisLockRunnable()).start();//启动线程
}
}
static class DisLockRunnable implements Runnable {
public void run() {
//每个线程具体的任务,每个线程就是抢锁,
final DisClient client = new DisClient();
client.getDisLock();
//模拟获取锁之后的其它动作
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//释放锁
client.deleteLock();
}
}
}
import org.I0Itec.zkclient.IZkDataListener;
import org.I0Itec.zkclient.ZkClient;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
//抢锁
//1. 去zk创建临时序列节点,并获取到序号
//2. 判断自己创建节点序号是否是当前节点最小序号,如果是则获取锁
//执行相关操作,最后要释放锁
//3. 不是最小节点,当前线程需要等待,等待你的前一个序号的节点
//被删除,然后再次判断自己是否是最小节点。。。
public class DisClient {
public DisClient() {
//初始化zk的/distrilocl节点,会出现线程安全问题
synchronized (DisClient.class) {
if (!zkClient.exists("/distrilock")) {
zkClient.createPersistent("/distrilock");
}
}
}
//前一个节点
String beforNodePath;
String currentNoePath;
//获取到zkClient
private ZkClient zkClient = new ZkClient("linux121:2181,linux122:2181");
//把抢锁过程为量部分,一部分是创建节点,比较序号,另一部分是等待锁
//完整获取锁方法
public void getDisLock() {
//获取到当前线程名称
final String threadName = Thread.currentThread().getName();
//首先调用tryGetLock
if (tryGetLock()) {
//说明获取到锁
System.out.println(threadName + ":获取到了锁");
} else {
// 没有获取到锁,
System.out.println(threadName + ":获取锁失败,进入等待状态");
waitForLock();
//递归获取锁
getDisLock();
}
}
CountDownLatch countDownLatch = null;
//尝试获取锁
public boolean tryGetLock() {
//创建临时顺序节点,/distrilock/序号
if (null == currentNoePath || "".equals(currentNoePath)) {
currentNoePath = zkClient.createEphemeralSequential("/distrilock/", "lock");
}
//获取到/distrilock下所有的子节点
final List<String> childs = zkClient.getChildren("/distrilock");
//对节点信息进行排序
Collections.sort(childs); //默认是升序
final String minNode = childs.get(0);
//判断自己创建节点是否与最小序号一致
if (currentNoePath.equals("/distrilock/" + minNode)) {
//说明当前线程创建的就是序号最小节点
return true;
} else {
//说明最小节点不是自己创建,要监控自己当前节点序号前一个的节点
final int i = Collections.binarySearch(childs, currentNoePath.substring("/distrilock/".length()));
//前一个(lastNodeChild是不包括父节点)
String lastNodeChild = childs.get(i - 1);
beforNodePath = "/distrilock/" + lastNodeChild;
}
return false;
}
//等待之前节点释放锁,如何判断锁被释放,需要唤醒线程继续尝试tryGetLock
public void waitForLock() {
//准备一个监听器
final IZkDataListener iZkDataListener = new IZkDataListener() {
public void handleDataChange(String s, Object o) throws Exception {
}
//删除
public void handleDataDeleted(String s) throws Exception {
//提醒当前线程再次获取锁
countDownLatch.countDown();//把值减1变为0,唤醒之前await线程
}
};
//监控前一个节点
zkClient.subscribeDataChanges(beforNodePath, iZkDataListener);
//在监听的通知没来之前,该线程应该是等待状态,先判断一次上一个节点是否还存在
if (zkClient.exists(beforNodePath)) {
//开始等待,CountDownLatch:线程同步计数器
countDownLatch = new CountDownLatch(1);
try {
countDownLatch.await();//阻塞,countDownLatch值变为0
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//解除监听
zkClient.unsubscribeDataChanges(beforNodePath, iZkDataListener);
}
//释放锁
public void deleteLock() {
if (zkClient != null) {
zkClient.delete(currentNoePath);
zkClient.close();
}
}
}
注意:
分布式锁的实现可以是 Redis、Zookeeper,相对来说生产环境如果使用分布式锁可以考虑使用Redis实现而非Zk。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)