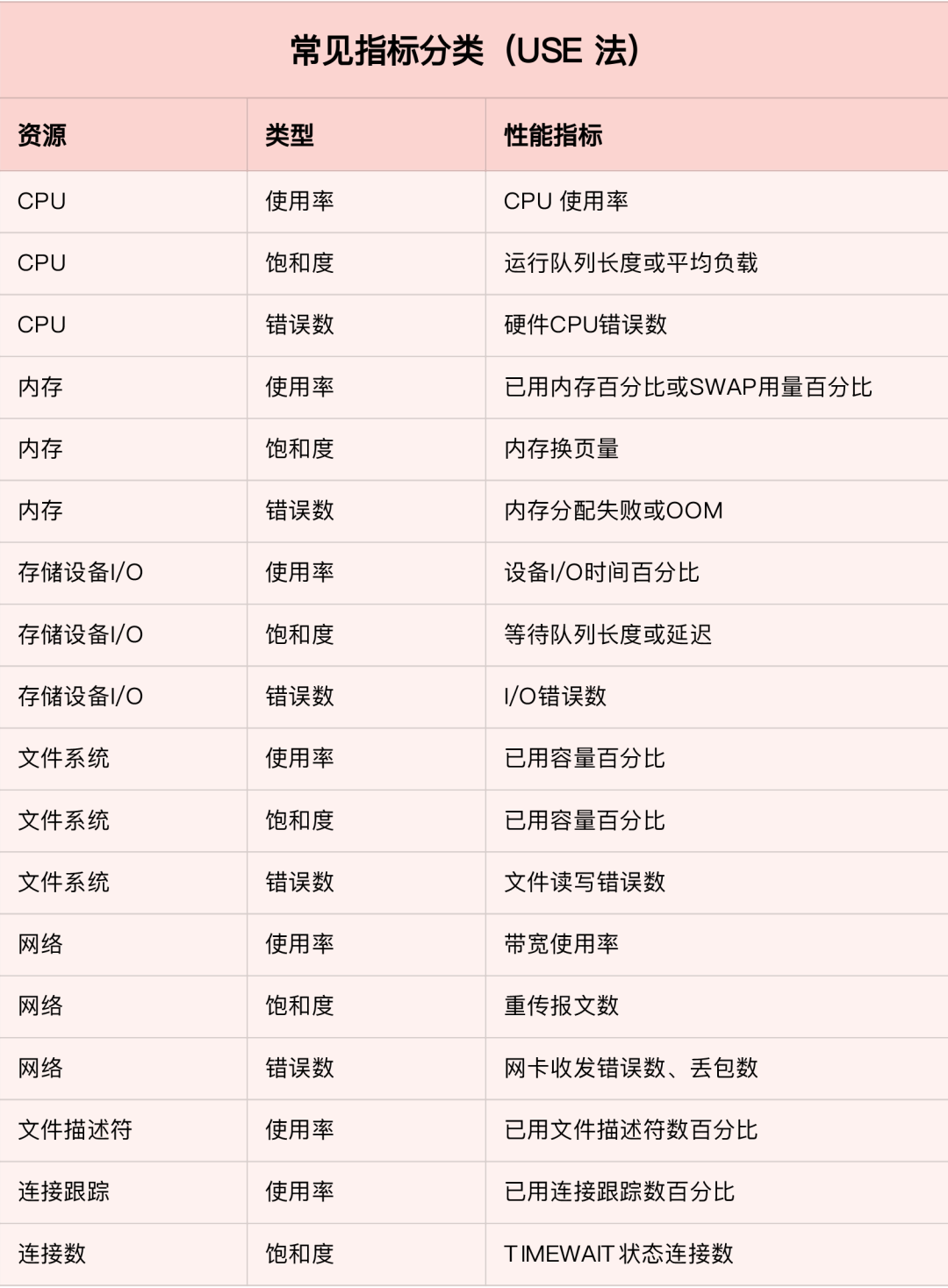
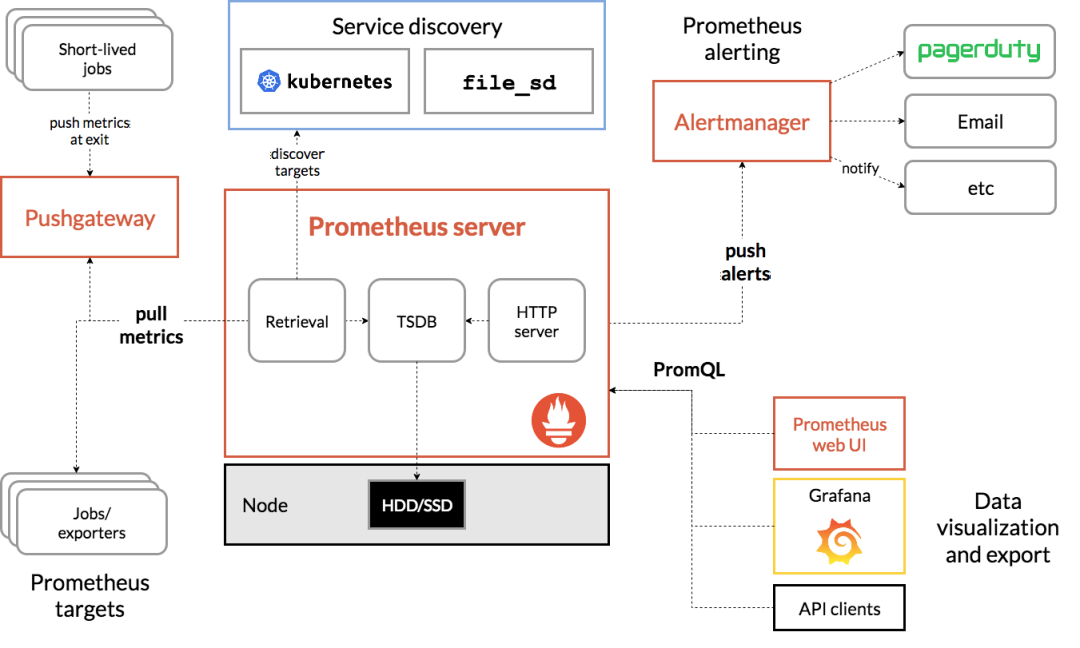
 先看数据采集模块。最左边的 Prometheus targets 就是数据采集的对象,而 Retrieval 则负责采集这些数据。从图中你也可以看到,Prometheus 同时支持 Push 和 Pull 两种数据采集模式。Pull 模式,由服务器端的采集模块来触发采集。只要采集目标提供了 HTTP 接口,就可以自由接入(这也是最常用的采集模式)。Push 模式,则是由各个采集目标主动向 Push Gateway(用于防止数据丢失)推送指标,再由服务器端从 Gateway 中拉取过去(这是移动应用中最常用的采集模式)。第二个是数据存储模块。为了保持监控数据的持久化,图中的 TSDB(Time series database)模块,负责将采集到的数据持久化到 SSD 等磁盘设备中。TSDB 是专门为时间序列数据设计的一种数据库,特点是以时间为索引、数据量大并且以追加的方式写入。第三个是数据查询和处理模块。刚才提到的 TSDB,在存储数据的同时,其实还提供了数据查询和基本的数据处理功能,而这也就是 PromQL 语言。PromQL 提供了简洁的查询、过滤功能,并且支持基本的数据处理方法,是告警系统和可视化展示的基础。第四个是告警模块。右上角的 AlertManager 提供了告警的功能,包括基于 PromQL 语言的触发条件、告警规则的配置管理以及告警的发送等。不过,虽然告警是必要的,但过于频繁的告警显然也不可取。所以,AlertManager 还支持通过分组、抑制或者静默等多种方式来聚合同类告警,并减少告警数量。最后一个是可视化展示模块。Prometheus 的 web UI 提供了简单的可视化界面,用于执行 PromQL 查询语句,但结果的展示比较单调。不过,一旦配合 Grafana,就可以构建非常强大的图形界面了。介绍完了这些组件,想必你对每个模块都有了比较清晰的认识。接下来,我们再来继续深入了解这些组件结合起来的整体功能。比如,以刚才提到的 USE 方法为例,我使用 Prometheus,可以收集 Linux 服务器的 CPU、内存、磁盘、网络等各类资源的使用率、饱和度和错误数指标。然后,通过 Grafana 以及 PromQL 查询语句,就可以把它们以图形界面的方式直观展示出来。
先看数据采集模块。最左边的 Prometheus targets 就是数据采集的对象,而 Retrieval 则负责采集这些数据。从图中你也可以看到,Prometheus 同时支持 Push 和 Pull 两种数据采集模式。Pull 模式,由服务器端的采集模块来触发采集。只要采集目标提供了 HTTP 接口,就可以自由接入(这也是最常用的采集模式)。Push 模式,则是由各个采集目标主动向 Push Gateway(用于防止数据丢失)推送指标,再由服务器端从 Gateway 中拉取过去(这是移动应用中最常用的采集模式)。第二个是数据存储模块。为了保持监控数据的持久化,图中的 TSDB(Time series database)模块,负责将采集到的数据持久化到 SSD 等磁盘设备中。TSDB 是专门为时间序列数据设计的一种数据库,特点是以时间为索引、数据量大并且以追加的方式写入。第三个是数据查询和处理模块。刚才提到的 TSDB,在存储数据的同时,其实还提供了数据查询和基本的数据处理功能,而这也就是 PromQL 语言。PromQL 提供了简洁的查询、过滤功能,并且支持基本的数据处理方法,是告警系统和可视化展示的基础。第四个是告警模块。右上角的 AlertManager 提供了告警的功能,包括基于 PromQL 语言的触发条件、告警规则的配置管理以及告警的发送等。不过,虽然告警是必要的,但过于频繁的告警显然也不可取。所以,AlertManager 还支持通过分组、抑制或者静默等多种方式来聚合同类告警,并减少告警数量。最后一个是可视化展示模块。Prometheus 的 web UI 提供了简单的可视化界面,用于执行 PromQL 查询语句,但结果的展示比较单调。不过,一旦配合 Grafana,就可以构建非常强大的图形界面了。介绍完了这些组件,想必你对每个模块都有了比较清晰的认识。接下来,我们再来继续深入了解这些组件结合起来的整体功能。比如,以刚才提到的 USE 方法为例,我使用 Prometheus,可以收集 Linux 服务器的 CPU、内存、磁盘、网络等各类资源的使用率、饱和度和错误数指标。然后,通过 Grafana 以及 PromQL 查询语句,就可以把它们以图形界面的方式直观展示出来。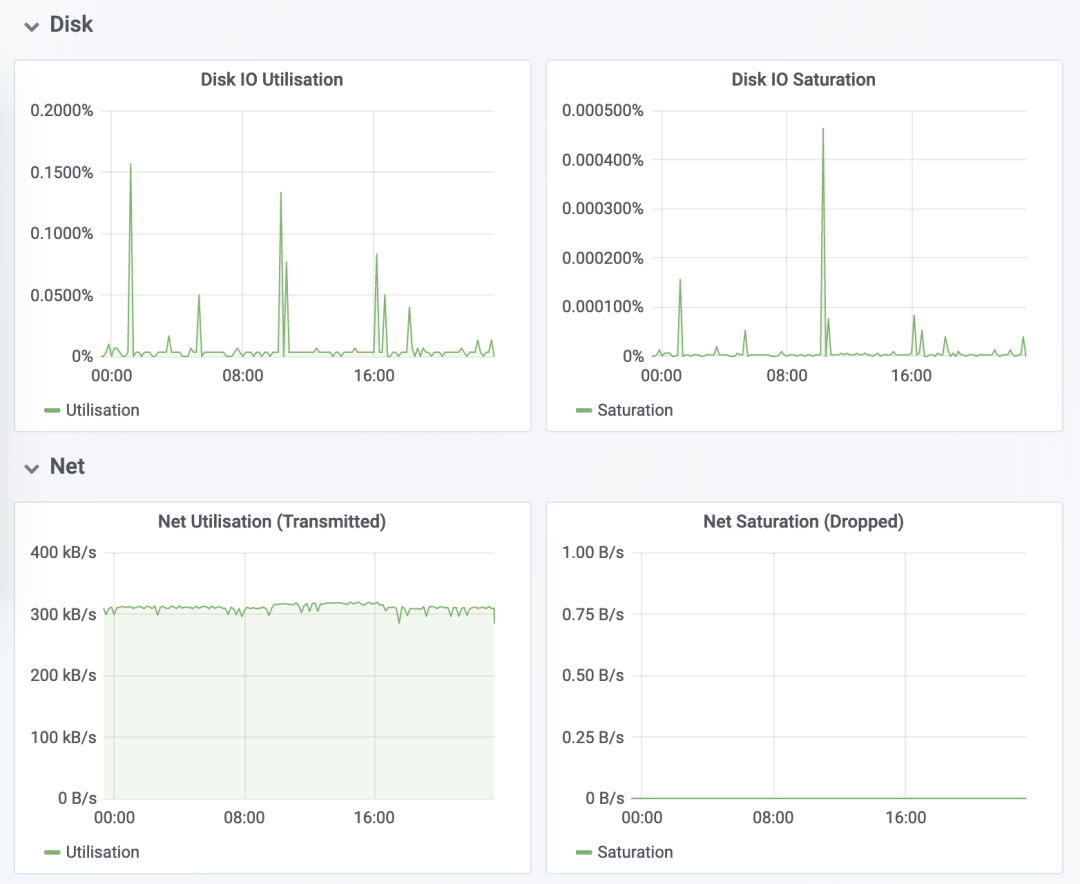
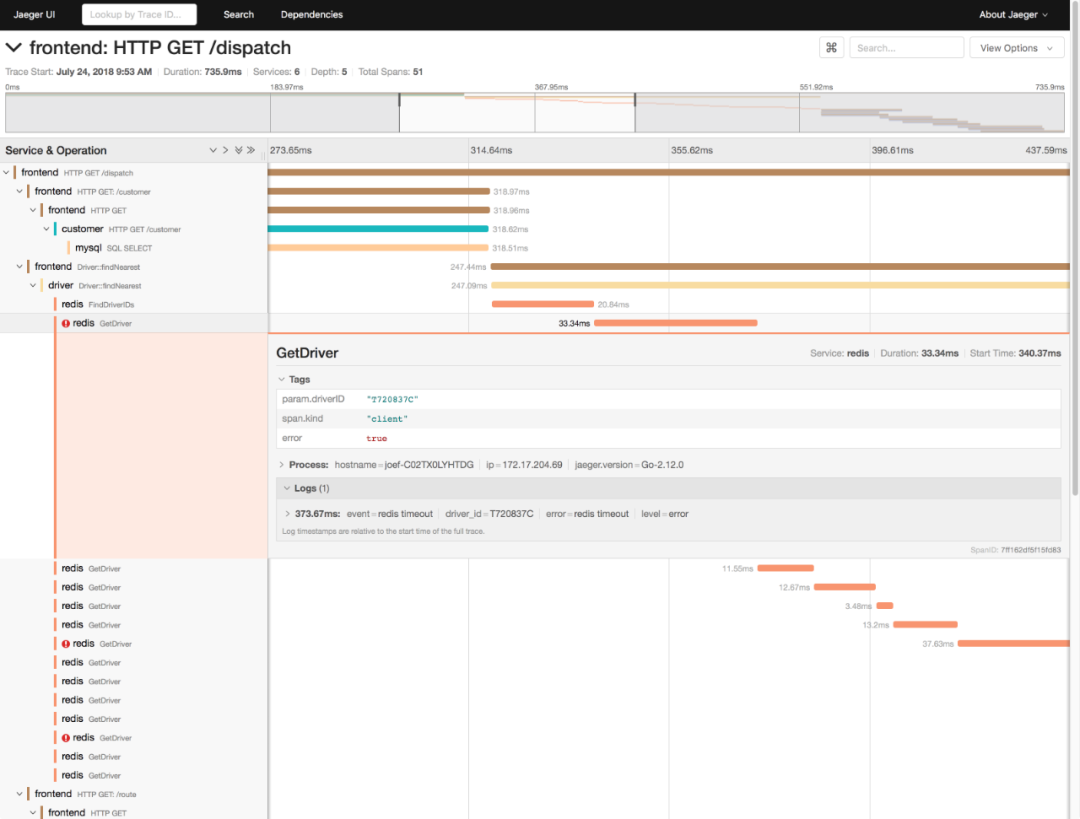 全链路跟踪可以帮你迅速定位出,在一个请求处理过程中,哪个环节才是问题根源。比如,从上图中,你就可以很容易看到,这是 Redis 超时导致的问题。全链路跟踪除了可以帮你快速定位跨应用的性能问题外,还可以帮你生成线上系统的调用拓扑图。这些直观的拓扑图,在分析复杂系统(比如微服务)时尤其有效。
全链路跟踪可以帮你迅速定位出,在一个请求处理过程中,哪个环节才是问题根源。比如,从上图中,你就可以很容易看到,这是 Redis 超时导致的问题。全链路跟踪除了可以帮你快速定位跨应用的性能问题外,还可以帮你生成线上系统的调用拓扑图。这些直观的拓扑图,在分析复杂系统(比如微服务)时尤其有效。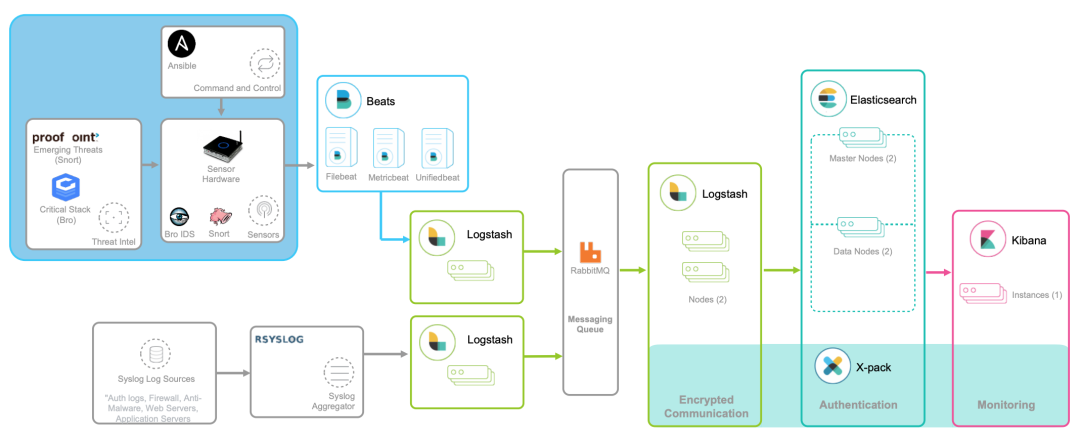 Logstash 负责对从各个日志源采集日志,然后进行预处理,最后再把初步处理过的日志,发送给 Elasticsearch 进行索引。Elasticsearch 负责对日志进行索引,并提供了一个完整的全文搜索引擎,这样就可以方便你从日志中检索需要的数据。Kibana 则负责对日志进行可视化分析,包括日志搜索、处理以及绚丽的仪表板展示等。下面这张图,就是一个 Kibana 仪表板的示例,它直观展示了 Apache 的访问概况。
Logstash 负责对从各个日志源采集日志,然后进行预处理,最后再把初步处理过的日志,发送给 Elasticsearch 进行索引。Elasticsearch 负责对日志进行索引,并提供了一个完整的全文搜索引擎,这样就可以方便你从日志中检索需要的数据。Kibana 则负责对日志进行可视化分析,包括日志搜索、处理以及绚丽的仪表板展示等。下面这张图,就是一个 Kibana 仪表板的示例,它直观展示了 Apache 的访问概况。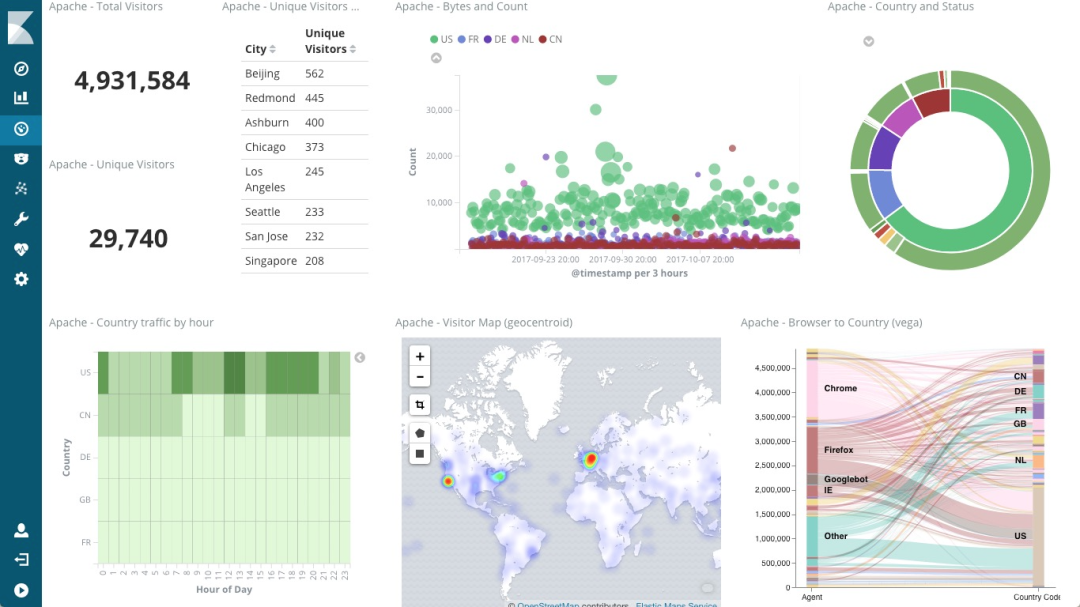 值得注意的是,ELK 技术栈中的 Logstash 资源消耗比较大。所以,在资源紧张的环境中,我们往往使用资源消耗更低的 Fluentd,来替代 Logstash(也就是所谓的 EFK 技术栈)。
值得注意的是,ELK 技术栈中的 Logstash 资源消耗比较大。所以,在资源紧张的环境中,我们往往使用资源消耗更低的 Fluentd,来替代 Logstash(也就是所谓的 EFK 技术栈)。这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
使用Ruby1.8.6/Rails2.3.2我注意到在我的任何ActiveRecord模型类上调用的任何方法都返回nil而不是NoMethodError。除了烦人之外,这还破坏了动态查找器(find_by_name、find_by_id等),因为即使存在记录,它们也总是返回nil。不从ActiveRecord::Base派生的标准类不受影响。有没有办法追踪在ActiveRecord::Base之前拦截method_missing的是什么?更新:切换到1.8.7后,我发现(感谢@MichaelKohl)will_paginate插件首先处理method_missing。但是will_pa
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
我有一个大数组,我需要知道它的所有元素是否都能被2整除。我是这样做的,但是有点丑:_true=truearr.each{|e|(e%2).zero?||_true=false}if_true==true#...end如何在没有额外循环/赋值的情况下做到这一点? 最佳答案 这样就可以了。arr.all?(&:even?) 关于ruby-如何找出所有数组元素是否都符合某个条件?,我们在StackOverflow上找到一个类似的问题: https://stackov
是否存在GC.disable会降低性能的情况?只要我使用的是真正的RAM而不是交换内存,就可以这样做吗?我正在使用MRIRuby2.0,据我所知,它是64位的,并且使用的是64位的Ubuntu:ruby2.0.0p0(2013-02-24revision39474)[x86_64-linux]Linux[redacted]3.2.0-43-generic#68-UbuntuSMPWedMay1503:33:33UTC2013x86_64x86_64x86_64GNU/Linux 最佳答案 GC.disable将禁用垃圾回收。像rub
我尝试在Internet上搜索有关使用angularJS进入RubyonRails项目与RubyonRailspure的View性能的信息。我的问题是因为2个月前我开始使用纯AngularJS,现在我需要将AngularJS集成到一个新项目中,但需要展示使用带有RubyonRails的AngularJS呈现View的性能如何,并消除对RubyonRails的负担.例如:带Rails的Angular:使用RubyonRails获取数据(从数据库或GET请求),将信息发送到file.js.erb并使用AngularJS操作数据并显示带有解析数据的View。纯粹的Rails:(自然流程)使用