什么是自动补全(autocomplete)功能呢?我们举一个很常见的例子。 每当你去谷歌并开始打字时,就会出现一个下拉列表,其中列出了建议。 这些建议与查询相关并帮助用户完成查询。
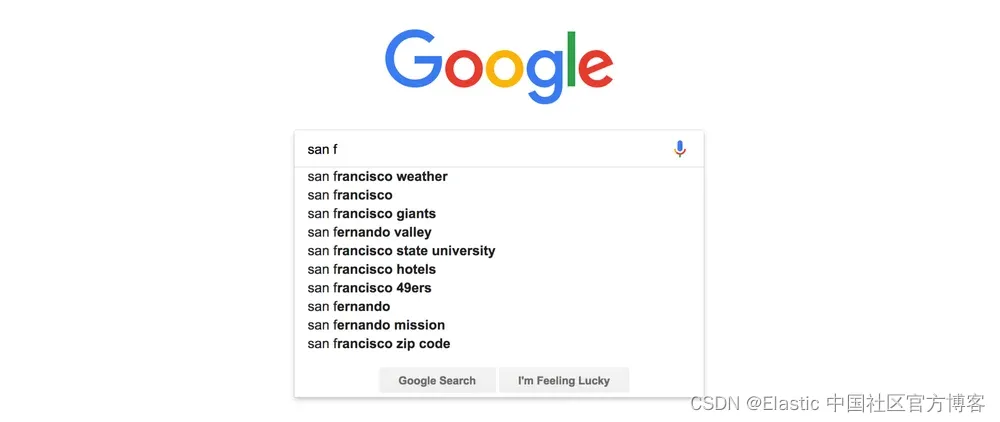
Autocomplete 正如维基百科所说的:
Autocomplete 或单词完成是一个功能,应用程序预测使用的其余单词正在键入
它也知道你键入或键入前方搜索。 它通过提示用户在键入文本的可能性和替代方案来帮助他们导航或指导用户。 它减少用户在执行任何搜索操作之前需要输入的字符数量,从而增强用户的搜索体验。
可以通过使用任何数据库来实现 Autocomplete。 在这篇文章中,我们将使用 Elasticsearch 构建自动补全功能。
Elasticsearch 是免费及开发,分布式和基于JSON的搜索引擎,建立在Lucene的顶部。更多关于 Elasticsearch 的介绍,请阅读文章 “Elasticsearch 简介”。
在 Elasticsearch 中,可能有多种构建自动完成功能的方法。 我们将讨论以下方法。
这种方法涉及使用针对自定义字段的前缀查询(prefix query)。 该字段的值可以作为 keyword 存储,因此将多个 terms(单词)存储在一起作为一个术语。 可以使用关键字分词器(keyword tokenizer)来完成这一点。 这种方法遭受了缺点:
有关 edge ngrams 的介绍请参阅之前的文章 “Elasticsearch: Ngrams, edge ngrams, and shingles”。
这种方法涉及在索引和搜索时使用不同的分析器。 索引文档时,可以应用带有 edge n-gram 过滤器的自定义分析器。 在搜索时,可以应用标准分析器。 这可以防止查询被拆分。
Edge N-gram tokeniser 首先将文本分解为自定义字符(空格、特殊字符等)上的单词,然后仅从字符串的开头保留 n-gram。
这种方法也适用于匹配文本中间的查询。 这种方法通常查询速度很快,但可能会导致索引速度变慢和索引存储量变大。
Elasticsearch 附带一个名为 Completion Suggester 的内部解决方案。 它使用称为有限状态传感器 (Finite State Transducer - FST) 的内存数据结构。 Elasticsearch 以每个段为基础存储 FST,这意味着建议会随着更多新节点的添加而水平扩展。
实施 Completion Suggester 时要记住的一些事情
这种方法是实现自动完成功能的理想方法,但是,它也有一些缺点
Captain America: Civil War
America: Civil War
Civil War
War不支持突出(highlight)显示匹配的词。
没有可用的排序机制。 对建议进行排序的唯一方法是通过权重。 当需要任何自定义排序(如字母排序或按上下文排序)时,这会产生问题。
让我们在 Elasticsearch 中实现上述方法。 我们将使用 movies 数据来构建我们的示例索引。 为了便于参考,我们使用如下的命令来创建 movies 索引:
PUT movies
{
"settings": {
"index": {
"analysis": {
"filter": {},
"analyzer": {
"keyword_analyzer": {
"filter": [
"lowercase",
"asciifolding",
"trim"
],
"char_filter": [],
"type": "custom",
"tokenizer": "keyword"
},
"edge_ngram_analyzer": {
"filter": [
"lowercase"
],
"tokenizer": "edge_ngram_tokenizer"
},
"edge_ngram_search_analyzer": {
"tokenizer": "lowercase"
}
},
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 5,
"token_chars": [
"letter"
]
}
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"keywordstring": {
"type": "text",
"analyzer": "keyword_analyzer"
},
"edgengram": {
"type": "text",
"analyzer": "edge_ngram_analyzer",
"search_analyzer": "edge_ngram_search_analyzer"
},
"completion": {
"type": "completion"
}
},
"analyzer": "standard"
}
}
}
}如果我们看到映射,我们会发现 name 是一个 multi-fields 字段,其中包含多个字段,每个字段都以不同的方式进行分析。
我们使用如下命令索引所有的电影:
POST movies/_bulk
{ "index" : {"_id" : "1"} }
{ "name" : "Spider-Man: Homecoming" }
{ "index" : {"_id" : "2"} }
{ "name" : "Ant-man and the Wasp" }
{ "index" : {"_id" : "3"} }
{ "name" : "Avengers: Infinity War Part 2" }
{ "index" : {"_id" : "4"} }
{ "name" : "Captain Marvel" }
{ "index" : {"_id" : "5"} }
{ "name" : "Black Panther" }
{ "index" : {"_id" : "6"} }
{ "name" : "Avengers: Infinity War" }
{ "index" : {"_id" : "7"} }
{ "name" : "Thor: Ragnarok" }
{ "index" : {"_id" : "8"} }
{ "name" : "Guardians of the Galaxy Vol 2" }
{ "index" : {"_id" : "9"} }
{ "name" : "Doctor Strange" }
{ "index" : {"_id" : "10"} }
{ "name" : "Captain America: Civil War" }
{ "index" : {"_id" : "11"} }
{ "name" : "Ant-Man" }
{ "index" : {"_id" : "12"} }
{ "name" : "Avengers: Age of Ultron" }
{ "index" : {"_id" : "13"} }
{ "name" : "Guardians of the Galaxy" }
{ "index" : {"_id" : "14"} }
{ "name" : "Captain America: The Winter Soldier" }
{ "index" : {"_id" : "15"} }
{ "name" : "Thor: The Dark World" }
{ "index" : {"_id" : "16"} }
{ "name" : "Iron Man 3" }
{ "index" : {"_id" : "17"} }
{ "name" : "Marvel’s The Avengers" }
{ "index" : {"_id" : "18"} }
{ "name" : "Captain America: The First Avenger" }
{ "index" : {"_id" : "19"} }
{ "name" : "Thor" }
{ "index" : {"_id" : "20"} }
{ "name" : "Iron Man 2" }
{ "index" : {"_id" : "21"} }
{ "name" : "The Incredible Hulk" }
{ "index" : {"_id" : "22"} }
{ "name" : "Iron Man" }让我们从 prefix query 方法开始,尝试查找以 th 开头的电影。
查询将是:
GET movies/_search?filter_path=**.hits
{
"query": {
"prefix": {
"name.keywordstring": {
"value": "th"
}
}
}
}查询的结果是:
{
"hits": {
"hits": [
{
"_index": "movies",
"_id": "7",
"_score": 1,
"_source": {
"name": "Thor: Ragnarok"
}
},
{
"_index": "movies",
"_id": "15",
"_score": 1,
"_source": {
"name": "Thor: The Dark World"
}
},
{
"_index": "movies",
"_id": "19",
"_score": 1,
"_source": {
"name": "Thor"
}
},
{
"_index": "movies",
"_id": "21",
"_score": 1,
"_source": {
"name": "The Incredible Hulk"
}
}
]
}
}结果是公平的,但是像 Captain America: The Winter Soldier,Guardians of the Galaxy 这样的电影被遗漏了,因为前缀查询只匹配文本的开头而不是中间。
让我们尝试寻找另一部以 am 开头的电影。
GET movies/_search?filter_path=**.hits
{
"query": {
"prefix": {
"name.keywordstring": {
"value": "am"
}
}
}
}这里我们没有得到任何结果,尽管 Captain America 满足这个条件。 这就印证了Prefix query 不能用于正文中间匹配的一点。
让我们运行相同的搜索,但使用 Edge Ngram 方法。
GET movies/_search?filter_path=**.hits
{
"query": {
"match": {
"name.edgengram": "am"
}
}
}上面运行的结果是:
{
"hits": {
"hits": [
{
"_index": "movies",
"_id": "10",
"_score": 1.5922177,
"_source": {
"name": "Captain America: Civil War"
}
},
{
"_index": "movies",
"_id": "14",
"_score": 1.3930962,
"_source": {
"name": "Captain America: The Winter Soldier"
}
},
{
"_index": "movies",
"_id": "18",
"_score": 1.3930962,
"_source": {
"name": "Captain America: The First Avenger"
}
}
]
}
}让我们再次尝试寻找 Captain America,但这次使用更大的短语 captain america the:
GET movies/_search?filter_path=**.hits
{
"query": {
"match": {
"name.edgengram": "captain america the"
}
}
}使用 Edge N-gram 方法,我们得到以下电影:
{
"hits": {
"hits": [
{
"_index": "movies",
"_id": "21",
"_score": 1.0249562,
"_source": {
"name": "The Incredible Hulk"
}
},
{
"_index": "movies",
"_id": "17",
"_score": 0.9822227,
"_source": {
"name": "Marvel’s The Avengers"
}
},
{
"_index": "movies",
"_id": "2",
"_score": 0.94290996,
"_source": {
"name": "Ant-man and the Wasp"
}
},
{
"_index": "movies",
"_id": "13",
"_score": 0.94290996,
"_source": {
"name": "Guardians of the Galaxy"
}
},
{
"_index": "movies",
"_id": "15",
"_score": 0.906623,
"_source": {
"name": "Thor: The Dark World"
}
},
{
"_index": "movies",
"_id": "8",
"_score": 0.8730254,
"_source": {
"name": "Guardians of the Galaxy Vol 2"
}
},
{
"_index": "movies",
"_id": "14",
"_score": 0.7365507,
"_source": {
"name": "Captain America: The Winter Soldier"
}
},
{
"_index": "movies",
"_id": "18",
"_score": 0.7365507,
"_source": {
"name": "Captain America: The First Avenger"
}
}
]
}
}如果我们观察我们的短语,只有两个建议是有意义的。 匹配这么多术语的原因是 match 子句的功能。 匹配包括所有包含 captain OR america OR the 的文件。 由于该字段是使用 ngram 分析的,因此也会包含更多建议(如果存在)。
让我们尝试使用针对相同短语 captain america the 的 suggest 查询。 建议查询的编写方式略有不同。
GET movies/_search?filter_path=suggest
{
"suggest": {
"movie-suggest": {
"prefix": "captain america the",
"completion": {
"field": "name.completion"
}
}
}
}结果我们得到以下电影:
{
"suggest": {
"movie-suggest": [
{
"text": "captain america the",
"offset": 0,
"length": 19,
"options": [
{
"text": "Captain America: The First Avenger",
"_index": "movies",
"_id": "18",
"_score": 1,
"_source": {
"name": "Captain America: The First Avenger"
}
},
{
"text": "Captain America: The Winter Soldier",
"_index": "movies",
"_id": "14",
"_score": 1,
"_source": {
"name": "Captain America: The Winter Soldier"
}
}
]
}
]
}
}让我们尝试相同的查询,但这次使用了错别字 captain america the。
GET movies/_search?filter_path=suggest
{
"suggest": {
"movie-suggest": {
"prefix": "captain amrica the",
"completion": {
"field": "name.completion"
}
}
}
}上面的电影建议没有返回结果,因为不支持模糊性。 我们可以通过以下方式更新查询以包含对模糊性的支持:
GET movies/_search?filter_path=suggest
{
"suggest": {
"movie-suggest": {
"prefix": "captain amrica the",
"completion": {
"field": "name.completion",
"fuzzy": {
"fuzziness": 1
}
}
}
}
}以上查询返回以下结果:
{
"suggest": {
"movie-suggest": [
{
"text": "captain amrica the",
"offset": 0,
"length": 18,
"options": [
{
"text": "Captain America: The First Avenger",
"_index": "movies",
"_id": "18",
"_score": 10,
"_source": {
"name": "Captain America: The First Avenger"
}
},
{
"text": "Captain America: The Winter Soldier",
"_index": "movies",
"_id": "14",
"_score": 10,
"_source": {
"name": "Captain America: The Winter Soldier"
}
}
]
}
]
}
}
可以使用多种方法在 ElasticSearch 中实现自动完成功能。 Completion Suggester 涵盖了实现功能齐全且快速的自动完成所需的大多数情况。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
在编写Ruby(客户端脚本)时,我看到了三种构建更长字符串的方法,包括行尾,所有这些对我来说“闻起来”有点难看。有没有更干净、更好的方法?变量递增。ifrender_quote?quote="NowthatthereistheTec-9,acrappyspraygunfromSouthMiami."quote+="ThisgunisadvertisedasthemostpopularguninAmericancrime.Doyoubelievethatshit?"quote+="Itactuallysaysthatinthelittlebookthatcomeswithit:themo
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我正在尝试在配备ARMv7处理器的SynologyDS215j上安装ruby2.2.4或2.3.0。我用了optware-ng安装gcc、make、openssl、openssl-dev和zlib。我根据README中的说明安装了rbenv(版本1.0.0-19-g29b4da7)和ruby-build插件。.这些是随optware-ng安装的软件包及其版本binutils-2.25.1-1gcc-5.3.0-6gconv-modules-2.21-3glibc-opt-2.21-4libc-dev-2.21-1libgmp-6.0.0a-1libmpc-1.0.2-1libm
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和