目录
协同过滤(Collaborative Filtering,简写CF)是推荐系统最重要得思想之一,其思想是根据用户之前得喜好以及其他兴趣相近得用户得选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐),一般仅仅基于用户的行为数据(评价,购买,下载等),而不依赖于物品的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄,性别等)。其思想总的来说就是:人以类聚,物以群分。目前应用比较广泛的协同过滤算法是基于邻域的方法,而这种方法主要有两种算法:基于用户的协同过滤算法(给用户推荐和他兴趣相似的其他用户喜欢的产品)和基于物品的协同过滤算法(给用户推荐和他之前喜欢的物品相似的物品)。
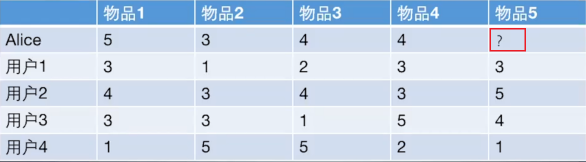
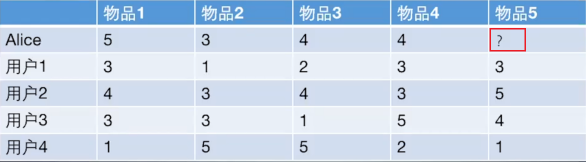
如上图所示,其实给用户推荐物品的过程就可以认为是一个猜测用户对商品进行打分的任务。我们的目的就是判断该不该把物品5推荐给Alice,即预测Alice会对这件商品打多少分。基于用户的协同过滤就是计算Alice和其他用户1,2,3,4之间的相似度,找出与Alice最相似的用户,根据他对商品5的喜好来判断Alice对商品5的喜好。而基于物品的协同过滤则是计算商品5与商品!,2,3,4的相似度,用Alice对与商品5相似度最高的那个样品的喜好来判断其对商品5的喜好。我们可以看出,无论是基于用户的协同过滤还是基于物品的协同过滤,都需要计算相似度,那我们来看一下相似度是如何计算的把。
这是衡量两个集合的相似度的一种指标。两个集合A和B的交集元素在A,B的
并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{|A∩B|}{|A∪B|} J(A,B)=∣A∪B∣∣A∩B∣
杰卡德相似系数越大,说明相似度越高,当A和B都为空时,J(A,B)=1.
与杰卡德相似系数相反的概念时杰卡德距离,杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。距离越大,区分度越高,距离越小,区分度越低。
J δ = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ J_{\delta}=1-J(A,B)=\frac{|A∪B|-|A∩B|}{|A∪B|} Jδ=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣
余弦相似度衡量了向量i和j之间的向量夹角的大小,夹角越小,说明相似度越大,两个用户越相似。
s i m ( i , j ) = c o s ( i , j ) = i ⋅ j ∣ ∣ i ∣ ∣ ⋅ ∣ ∣ j ∣ ∣ sim(i,j)=cos(i,j)=\frac{i·j}{||i||·||j||} sim(i,j)=cos(i,j)=∣∣i∣∣⋅∣∣j∣∣i⋅j
这是向量表示的用具体数值表示:
c o s ( θ ) = ∑ k = 1 n x 1 k x 2 k ∑ k = 1 n x 1 k 2 ∑ 2 k n x 2 k 2 cos(\theta)=\frac{\sum_{k=1}^{n}{x_{1k}x_{2k}}}{\sqrt{\sum_{k=1}^{n}{x_{1k}^{2}}}\sqrt{\sum_{2k}^{n}{x_{2k}^{2}}}} cos(θ)=∑k=1nx1k2∑2knx2k2∑k=1nx1kx2k
其中 x 1 = ( x 11 , x 12 , . . . , x 1 n ) , x 2 = ( x 21 , x 22 , . . . , x 2 n ) x_{1}=(x_{11},x_{12},...,x_{1n}),x_{2}=(x_{21},x_{22},...,x_{2n}) x1=(x11,x12,...,x1n),x2=(x21,x22,...,x2n)
API:
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
i=np.array([[1,0,0,0]])
j=np.array([[1,0.5,0.5,0]])
cosine_similarity(i,j)
array([[0.81649658]])
余弦相似度比较常用,一般效果也不会太差,但是对于评分数据不规范的时候,例如存在有的用户喜欢打高分,有的用户喜欢打低分,有的用户喜欢乱打分的情况,这时候计算出来的余弦相似度就不太准确了,比如下面这种情况:
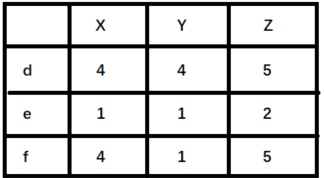
这时候计算余弦相似度cos<d,e>=0.973,cos<d,f>=0.919,则d和f比较相似,而实际上,我们观察数据,从对商品的喜好的趋势来看,d和e是比较接近的,只不过e比较喜欢打低分,d比较喜好打高分,所以对于这种情况,余弦相似度就不是那么好了,可以考虑使用皮尔逊相关系数。
相比余弦相似度,皮尔逊相关系数通过用户平均分对每个独立评分进行修正,减少了用户评分偏置的影响,即将每个向量都减去他们的平均值后在计算余弦相似度。
s i m ( i , j ) = ∑ p ∈ P ( R i , p − R i ‾ ) ( R j , p − R j ‾ ) ∑ p ∈ P ( R i , p − R i ‾ ) 2 ∑ p ∈ P ( R j , p − R j ‾ ) 2 sim(i,j)=\frac{\sum_{p∈P}(R_{i,p}-\overline{R_{i}})(R_{j,p}-\overline{R_{j}})}{\sqrt{\sum_{p∈P}(R_{i,p}-\overline{R_{i}})^{2}}\sqrt{\sum_{p∈P}(R_{j,p}-\overline{R_{j}})^{2}}} sim(i,j)=∑p∈P(Ri,p−Ri)2∑p∈P(Rj,p−Rj)2∑p∈P(Ri,p−Ri)(Rj,p−Rj)
其中 R i , p 表 示 用 户 i 对 物 品 p 的 平 方 , R i ‾ 表 示 用 户 对 i 对 所 有 物 品 的 平 均 分 R_{i,p}表示用户i对物品p的平方,\overline{R_{i}}表示用户对i对所有物品的平均分 Ri,p表示用户i对物品p的平方,Ri表示用户对i对所有物品的平均分,P代表所有物品的集合。 R i = ( R i 1 , R i 2 , . . . R i n ) , R j = ( R j 1 , R j 2 , . . . , R j n ) R_{i}=(R_{i1},R_{i2},...R_{in}),R_{j}=(R_{j1},R_{j2},...,R_{jn}) Ri=(Ri1,Ri2,...Rin),Rj=(Rj1,Rj2,...,Rjn)
①欧式距离
②曼哈顿距离
③马氏距离

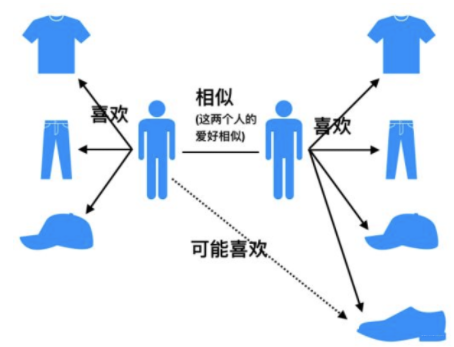
上图很好的说明了UserCF的思想,即当一个用户A需要个性化推荐的时候,我们可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的,而用户A没有听说过的物品推荐给A。
所有基于用户的协同过滤算法步骤为:
①找到和目标用户兴趣相似的其他用户集合
②找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户
仍以这个问题为例子
用户向量Alice(5,3,4,4),user1(3,1,2,3),user2(4,3,4,3),user3(3,3,1,5),user4(1,5,5,2)
Alice与user1的余弦相似度为:
s i m ( A l i c e , u s e r 1 ) = c o s ( A l i c e , u s e r 1 ) = 5 ∗ 3 + 3 ∗ 1 + 4 ∗ 2 + 4 ∗ 3 5 ∗ 5 + 3 ∗ 3 + 4 ∗ 4 + 4 ∗ 4 3 ∗ 3 + 1 ∗ 1 + 2 ∗ 2 + 3 ∗ 3 = 0.975 sim(Alice,user1)=cos(Alice,user1)=\frac{5*3+3*1+4*2+4*3}{\sqrt{5*5+3*3+4*4+4*4}\sqrt{3*3+1*1+2*2+3*3}}=0.975 sim(Alice,user1)=cos(Alice,user1)=5∗5+3∗3+4∗4+4∗43∗3+1∗1+2∗2+3∗35∗3+3∗1+4∗2+4∗3=0.975
同理计算出Alice与其他用户的余弦相似度。
用程序计算出的用户相似度矩阵为:
[[1. , 0.9753213 , 0.99224264, 0.89072354, 0.79668736],
[0.9753213 , 1. , 0.94362852, 0.91160719, 0.67478587],
[0.99224264, 0.94362852, 1. , 0.85280287, 0.85811633],
[0.89072354, 0.91160719, 0.85280287, 1. , 0.67082039],
[0.79668736, 0.67478587, 0.85811633, 0.67082039, 1. ]]
可以看出Alice与User1和User2最为相似
评分预测方式:
①利用用户相似度和相似用户的平均,加权平均获得用户的平均预测
R u , p = ∑ s ∈ S ( w u , s ⋅ R s , p ) ∑ s ∈ S w u , s R_{u,p}=\frac{\sum_{s∈S}(w_{u,s}·R_{s,p})}{\sum_{s∈S}w_{u,s}} Ru,p=∑s∈Swu,s∑s∈S(wu,s⋅Rs,p)
其中权重 w u , s w_{u,s} wu,s是用户u和用户s的相似度, R s , p R_{s,p} Rs,p是用户s 对物品p的评分
R A l i c e , 物 品 5 = w A l i c e , 用 户 1 ∗ R 用 户 1 , 物 品 5 + w A l i c e , 用 户 2 ∗ R 用 户 2 , 物 品 5 w A l i c e , 用 户 1 + w A l i c e , 用 户 2 R_{Alice,物品5}=\frac{w_{Alice,用户1}*R_{用户1,物品5}+w_{Alice,用户2}*R_{用户2,物品5}}{w_{Alice,用户1}+w_{Alice,用户2}} RAlice,物品5=wAlice,用户1+wAlice,用户2wAlice,用户1∗R用户1,物品5+wAlice,用户2∗R用户2,物品5
②由于有的用户内心的评分标准不一样,有的用户喜欢打高分,有的用户喜欢打低分,所以用该用户的评分与此用户的所有评分的差值进行加权
P i , j = R i ‾ + ∑ k = 1 n ( S i , k ( R k , j − R k ‾ ) ) ∑ k = 1 n S j , k P_{i,j}=\overline{R_{i}}+\frac{\sum_{k=1}^{n}(S_{i,k}(R_{k,j}-\overline{R_{k}}))}{\sum_{k=1}^{n}S_{j,k}} Pi,j=Ri+∑k=1nSj,k∑k=1n(Si,k(Rk,j−Rk))
其中 S i , k S_{i,k} Si,k仍然是相似度,与上边的w是一个意思
P A l i c e , 物 品 5 = R A l i c e ‾ + S A l i c e , 用 户 1 ∗ ( R 用 户 1 , 物 品 5 − R 用 户 1 ‾ ) + S A L i c e , 用 户 1 ∗ ( R 用 户 2 , 物 品 5 − R 用 户 2 ‾ ) S A l i c e , 用 户 1 + S A L i c e , 用 户 1 P_{Alice,物品5}=\overline{R_{Alice}}+\frac{S_{Alice,用户1}*(R_{用户1,物品5}-\overline{R_{用户1}})+S_{ALice,用户1}*(R_{用户2,物品5}-\overline{R_{用户2}})}{S_{Alice,用户1}+S_{ALice,用户1}} PAlice,物品5=RAlice+SAlice,用户1+SALice,用户1SAlice,用户1∗(R用户1,物品5−R用户1)+SALice,用户1∗(R用户2,物品5−R用户2)
定一个阈值,预测评分超过阈值,即可推荐给用户
一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间购买的物品重叠性较低,导致算法无法找到一个用户的偏好相似的用户。这导致UserCF不适用与那些正反馈获取较困难的应用场景(如酒店预订,大件商品购买等低频应用)
UserCF需要维护用户相似度矩阵以便快速的找出Topn相似用户,该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加,不适合用户数据量大的情况使用。
在互联网应用场景中,绝大多数产品的用户数都要远大于物品数,因此维护用户相似度矩阵的难度要大很多。
其适用于用户少,物品多,时效性较强的场合如新闻推荐场景。
import numpy as np
Users=np.array([[5,3,4,4,0],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1]])
cosine_similarity(Users)#调用sklearn库API计算
array([[1. , 0.82686887, 0.81016272, 0.76277007, 0.78954203],
[0.82686887, 1. , 0.95938348, 0.9356927 , 0.63781505],
[0.81016272, 0.95938348, 1. , 0.89442719, 0.77151675],
[0.76277007, 0.9356927 , 0.89442719, 1. , 0.63831064],
[0.78954203, 0.63781505, 0.77151675, 0.63831064, 1. ]])
def cosine(vec1,vec2):#计算两个向量之间的余弦值
m=vec1.shape[0]
fenzi=0
fenmu=0
abs1=0
abs2=0
for i in range(m):
if vec1[i]==0 or vec2[i]==0:
continue
fenzi+=vec1[i]*vec2[i]
abs1+=vec1[i]**2
abs2+=vec2[i]**2
fenmu=np.sqrt(abs1)*np.sqrt(abs2)
return fenzi/fenmu
def cosine_sim(users):#计算用户相似矩阵
m,n=users.shape
sim=np.zeros((m,m))#初始化为0
print(m,n)
for i in range(m):
for j in range(m):
if(i!=j):
sim[i][j]=cosine(users[i,:],users[j,:])
return sim
sim=cosine_sim(Users)
print(sim)
5 5
[[0. 0.9753213 0.99224264 0.89072354 0.79668736]
[0.9753213 0. 0.95938348 0.9356927 0.63781505]
[0.99224264 0.95938348 0. 0.89442719 0.77151675]
[0.89072354 0.9356927 0.89442719 0. 0.63831064]
[0.79668736 0.63781505 0.77151675 0.63831064 0. ]]
k=2#选择两个相似用户
#lis = [1,2,3,0,1,9,8]
print(sim[0])
#对相似度从大到小排序
simusers=sorted(range(len(sim[0])),key=lambda k:sim[0][k],reverse=True)[:k]
print(simusers)
[0. 0.9753213 0.99224264 0.89072354 0.79668736]
[2, 1]
def mean(users,i):#计算用户的平均打分
array=[]
for i in users[i]:
if(i!=0):
array.append(i)
return np.mean(array)
base_score=mean(Users,0)#R (Alice)的平均值
print(base_score)
4.0
wegiht_scores=0#分子
corr_valuse_sum=0#分母
for user in simusers:#预测打分
corr_valuse=sim[0][user]#w
mean_user_scores=mean(Users,user)#用户user的打分平均值
wegiht_scores+=corr_valuse*(Users[user][4]-mean_user_scores)#
corr_valuse_sum+=corr_valuse
final_scores=base_score+wegiht_scores/corr_valuse_sum
print('Alice对物品5打分:',final_scores)
Alice对物品5打分: 4.902580043392168
由于UserCF的缺陷,导致很多电商平台并没有采用这种算法,而是采用了ItemCF算法实现推荐系统。基于物品的协同过滤基本思想是预先根据所以用户的历史偏好数据计算物品之间的相似度,然后把与用户喜欢的物品相类似的物品推荐给用户。ItemCF算法并不利用物品的内容属性计算物品间的相似度,主要通过分析用户的行为记录计算物品之间的相似度。
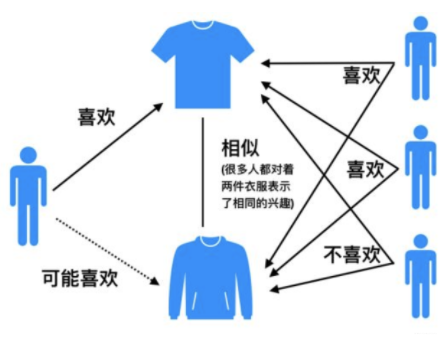
基于物品的协同过滤算法步骤:
①计算物品之间的相似度
②根据物品的相似度和用户的历史行为给用户生成推荐列表(购买了该商品的用户也经常购买的其他商品)
还是那原来的问题举例。
首先计算物品5和物品1,2,3,4之间的相似性,即计算每一列之间的余弦相似度。
物品向量:
物品1(3,4,3,1)物品2(1,3,3,5),物品3,物品4(3,3,5,2),物品5(3,5,4,1)
物品5和物品1之间的余弦相似度为:
s i m ( 物 品 1 , 物 品 5 ) = s o d i n e ( 物 品 1 , 物 品 5 ) = 3 ∗ 3 + 4 ∗ 5 + 3 ∗ 4 + 1 ∗ 1 3 ∗ 3 + 4 ∗ 4 + 3 ∗ 3 + 1 ∗ 1 ∗ 3 ∗ 3 + 5 ∗ 5 + 4 ∗ 4 + 1 ∗ 1 sim(物品1,物品5)=sodine(物品1,物品5)=\frac{3*3+4*5+3*4+1*1}{\sqrt{3*3+4*4+3*3+1*1}*\sqrt{3*3+5*5+4*4+1*1}} sim(物品1,物品5)=sodine(物品1,物品5)=3∗3+4∗4+3∗3+1∗1∗3∗3+5∗5+4∗4+1∗13∗3+4∗5+3∗4+1∗1
最终计算出的物品相似度矩阵:
[[1. , 0.73898843, 0.74766718, 0.93691598, 0.99410024],
[0.73898843, 1. , 0.93356387, 0.81362907, 0.73885058],
[0.74766718, 0.93356387, 1. , 0.70971845, 0.72261012],
[0.93691598, 0.81362907, 0.70971845, 1. , 0.93955848],
[0.99410024, 0.73885058, 0.72261012, 0.93955848, 1. ]]
根据物品相似度矩阵可以看出与物品5最相似的物品为物品1和物品4
仍然采用上边的预测公式二:
P i , j = R i ‾ + ∑ k = 1 n ( S i , k ( R k , j − R k ‾ ) ) ∑ k = 1 n S j , k P_{i,j}=\overline{R_{i}}+\frac{\sum_{k=1}^{n}(S_{i,k}(R_{k,j}-\overline{R_{k}}))}{\sum_{k=1}^{n}S_{j,k}} Pi,j=Ri+∑k=1nSj,k∑k=1n(Si,k(Rk,j−Rk))
P A l i c e , 物 品 5 = R 物 品 5 ‾ + S 物 品 1 , 物 品 5 ∗ ( R A l i c e , 物 品 1 − R 物 品 1 ‾ ) + S 物 品 4 , 物 品 5 ∗ ( R A l i c e , 物 品 4 − R 物 品 4 ‾ ) S 物 品 1 , 物 品 5 + S 物 品 4 , 物 品 5 P_{Alice,物品5}=\overline{R_{物品5}}+\frac{S_{物品1,物品5}*(R_{Alice,物品1}-\overline{R_{物品1}})+S_{物品4,物品5}*(R_{Alice,物品4}-\overline{R_{物品4}})}{S_{物品1,物品5}+S_{物品4,物品5}} PAlice,物品5=R物品5+S物品1,物品5+S物品4,物品5S物品1,物品5∗(RAlice,物品1−R物品1)+S物品4,物品5∗(RAlice,物品4−R物品4)
①ItemCF算法的预测结果比UserCF算法的质量要高一点
②由于ItemCF可以预先计算好物品的相似度,所以预测性能要比UserCF算法的高。
①数据的稀疏性
| item1 | item2 | item3 | item4 | item5 | item6 | |
|---|---|---|---|---|---|---|
| user1 | 1 | 1 | 1 | 0 | 1 | 0 |
| user2 | 0 | 0 | 0 | 0 | 0 | 0 |
| user3 | 0 | 0 | 0 | 1 | 0 | 0 |
| user4 | 0 | 0 | 0 | 0 | 0 | 0 |
| user5 | 0 | 0 | 0 | 0 | 1 | 1 |
| user6 | 1 | 1 | 1 | 1 | 1 | 0 |
表中数据0代表用户没有商品打分,1代表用户对商品打分了
想要计算物品相似度矩阵,则两个物品的向量需要满足至少同一行有2个1才能计算,即使有,如果行数过少,得出来得数据就不可靠。
因而ItemCF算法使用与电商平台等User数量远大于Item数量得应用场景
对于有m个用户,n个物品,m>>n
则user相似度矩阵维度为:m*m
item相似度矩阵维度为:n*n
在user数量远远高于item数量时,维护item相似度矩阵要比user相似度矩阵容易。
所以ItemCF适用于兴趣变化较为稳定,更接近与个性化的推荐。适合物品少
,用户多,用户兴趣固定持久,物品更新速度不是太快的场合。如推荐艺术品,音乐电影等
import numpy as np
items=np.array([[5,3,4,4,0],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1]])
def cosine(vec1,vec2):#计算两个向量之间的余弦值
m=vec1.shape[0]
fenzi=0
fenmu=0
abs1=0
abs2=0
for i in range(m):
if vec1[i]==0 or vec2[i]==0:
continue
fenzi+=vec1[i]*vec2[i]
abs1+=vec1[i]**2
abs2+=vec2[i]**2
fenmu=np.sqrt(abs1)*np.sqrt(abs2)
return fenzi/fenmu
def cosine_sim(items):#计算物品相似矩阵
n=items.shape[1]
sim=np.zeros((n,n))#初始化为0
# print(m,n)
for i in range(n):
for j in range(n):
if(i!=j):
sim[i][j]=cosine(items[:,i],items[:,j])
return sim
similay_matrix=cosine_sim(items)
print(similay_matrix)
[[0. 0.78025959 0.81978229 0.94337007 0.99410024]
[0.78025959 0. 0.94201969 0.84798442 0.73885058]
[0.81978229 0.94201969 0. 0.78402509 0.72261012]
[0.94337007 0.84798442 0.78402509 0. 0.93955848]
[0.99410024 0.73885058 0.72261012 0.93955848 0. ]]
k=2#选择两个相似物品
i=4
#lis = [1,2,3,0,1,9,8]
print(similay_matrix[i])
#对相似度从大到小排序
similay_items=sorted(range(len(similay_matrix[i])),key=lambda k:similay_matrix[i][k],reverse=True)[0:k]
print(similay_items)
[0.99410024 0.73885058 0.72261012 0.93955848 0. ]
[0, 3]
def mean(users,i):#计算物品的平均打分
array=[]
for i in users[:,i]:
if(i!=0):
array.append(i)
return np.mean(array)
base_score=mean(items,i)#物品5的平均值
print(base_score)
3.25
wegiht_scores=0#分子
corr_valuse_sum=0#分母
for item in similay_items:#预测打分
corr_valuse=similay_matrix[i][item]#w
mean_user_scores=mean(items,item)#用户user的打分平均值
wegiht_scores+=corr_valuse*(items[0][item]-mean_user_scores)#
corr_valuse_sum+=corr_valuse
final_scores=base_score+wegiht_scores/corr_valuse_sum
print('Alice对物品5打分:',final_scores)
Alice对物品5打分: 4.466923907166172
| UserCF | ItemCf | |
|---|---|---|
| 性能 | 适用于用户较少的场合,如果用户很多,计算用户相似度矩阵代价很大 | 适用于物品数量明显少于用户数的场合,如果物品很多,计算物品相似度矩阵难度很大 |
| 领域 | 时效性较强,用户个性化兴趣不太明显的领域,强调人与人之间的共性(微博热搜) | 长尾物品(小众物品)丰富,用户个性化需求强烈的领域,强调人的个性 |
| 实时性 | 在用户有新行为,不一定造成推荐结果的立即变化 | 用户有新行为,一定会导致推荐结果的实时变化 |
| 冷启动 | 在新用户对很少的物品产生行为后,不能立即对他进行个性化推荐,因为用户相似度表是每隔一段时间离线计算的(只要用户有新行为,那么相似用户就很有可能发生变化,需要更新相似用户,才能做出准确的推荐) | 新用户只要对一个物品产生行为,就可以给他推荐和该物品相关的其他物品 |
| 新物品 | 新物品上线一段时间后,一旦有用户对物品产生行为,就可以将新物品推荐给和对它产生行为的用户兴趣相似的其他用户 | 没有办法再不离线更新物品相似度表的情况下将新物品推荐给用户,因为新物品跟其他物品的相似度还没有计算,不能从相似性矩阵中找到对于的相似物品 |
| 推荐理由 | 很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户做推荐解释,可以令用户比较信服 |
共同的缺点:
①不能彻底解决数据稀疏性问题
②泛化能力弱
协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。导致的问题是热门物品具有很强的头部效应,容易跟大量的物品产生相似,而尾部物品由于特征向量系数,导致很少被推荐。
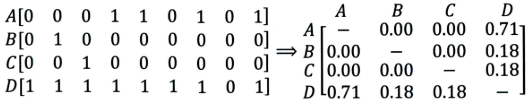
A,B,C,D都是商品,右边是物品相似度矩阵,可以发现D跟A,B,C的相似度都比较大,但是物品D与其他物品相似度大的原因是D是一件热门商品,系统无法找出A,B,C之间的相似性的原因是其特征太稀疏(购买的用户较少)。所以协同过滤推荐系统的头部效应太过明显,出来稀疏向量的能力弱。所以随后提出了矩阵分解。
③无法利用更多的信息
一般仅基于用户的行为数据(评价,购买,下载等),而不依赖任何附加的信息或者用户的任何附加信息,比如不依赖物品自身特征,用户年龄,性别等。
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
我仍然收到标题中的“错误”消息,但不知道如何解决。在ApplicationController中,classApplicationController在routes.rb#match'set_activity_account/:id/:value'=>'users#account_activity',:as=>:set_activity_account--thisdoesn'tworkaswell..resources:usersdomemberdoget:action_a,:action_bendcollectiondoget'account_activity'endend和User
对于用户模型,我有一个过滤器来检查用户的预订状态,该状态由整数值(0、1或2)表示。UserActiveAdmin索引页上的过滤器是通过以下代码实现的:filter:booking_status,as::select然而,这会导致下拉选项为0、1或2。当管理员用户从下拉列表中选择它们时,我更愿意自己将它们命名为“未完成”、“待定”和“已确认”之类的名称。有没有办法在不改变booking_status在模型中的表示方式的情况下做到这一点? 最佳答案 假设booking_status是模型中的枚举字段,您可以使用:过滤器:booking
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
以下模型通过belongs_to链接:require'mongoid'classSensorincludeMongoid::Documentfield:sensor_id,type:Stringvalidates_uniqueness_of:sensor_idend...require'mongoid'require_relative'sensor.rb'classSensorDataincludeMongoid::Documentbelongs_to:sensorfield:date,type:Datefield:ozonMax1h,type:Floatfield:ozonMax8h