SQL 语句解析是一个重要且复杂的技术,数据库流量相关的 SQL 审计、读写分离、分片等功能都依赖于 SQL 解析,而 Pisa-Proxy 作为 Database Mesh 理念的一个实践,对数据库流量的治理是其核心,因此实现 SQL 解析是一项很重要的工作。本文将以 Pisa-Proxy 实践为例,为大家展现 Pisa-Proxy 中的 SQL 解析实现,遇到的问题及优化。
语法分析一般通过词法分析器,如 Flex,生成相应的 token,语法分析器通过分析 token,来判断是否满足定义的语法规则。
语法分析器一般会通过解析生成器生成。
语法分析算法常用的有以下:
与上下文无关文法,从左到右扫描,从最左推导语法树,相比 LR 更容易理解,错误处理更友好。
与上下文无关文法,从左到右扫描,从最右节点推导语法树,相比 LL 速度快。
与 LR 类似,在解析时比 LR 生成的状态更少,从而减少 Shift/Reduce 或者 Reduce/Reduce 冲突,被业界广泛使用的 bison/yacc 生成的就是基于 LALR 解析器。
在开发 SQL 解析之初,我们从性能、维护性、开发效率、完成度四方面分别调研了 antlr_rust,sqlparser-rs,nom-sql 项目,但都存在一些问题。
ShardingSphere 实现了基于 Antlr 的不同的 SQL 方言解析,为了使用它的 Grammar,我们调研了 antlr_rust 项目,此项目不够活跃,成熟度不够高。
在 Rust 社区里,sqlparser-rs 项目是一个较为成熟的库,兼容各种 SQL 方言,Pisa-Proxy 在未来也会支持多种数据源,但是由于其词法和语法解析都是纯手工打造的,对我们来说会不易维护。
nom-sql 是基于 nom 库实现的 SQL 解析器,但是未实现完整,性能测试不如预期。
Grmtools 是在寻找 Rust 相关的 Yacc 实现时发现的库,该库实现了兼容绝大部分 Yacc 功能,这样就可以复用 MySQL 官方的语法文件,但是需要手写 Lex 词法解析,经过对开发效率及完成度权衡后,我们决定做难且正确的事,实现自己的 SQL 解析器,快速实现一个 Demo 进行测试。
编码完成后,测试效果还不错。
总结如下:
| 工具 | antlr_rust | sqlparser-rs | nom-sql | grmtools |
|---|---|---|---|---|
| 完成度 | ✅ | ✅ | ||
| 性能 | ✅ | ✅ | ||
| 维护性 | ✅ | |||
| 开发效率 | ✅ | ✅ |
最终我们选择了 Grmtools 来开发 Pisa-Proxy 中的 SQL 解析。
使用 Grmtools 解析库大致分为两个步骤,下面以实现计算器为例。
Lex:创建 calc.l,内容如下:
/%%
[0-9]+ "INT"
\+ "+"
\* "*"
\( "("
\) ")"
[\t ]+ ;
Grammar:创建 calc.y 内容如下:
%start Expr
%avoid_insert "INT"
%%
Expr -> Result<u64, ()>:
Expr '+' Term { Ok($1? + $3?) }
| Term { $1 }
;
Term -> Result<u64, ()>:
Term '*' Factor { Ok($1? * $3?) }
| Factor { $1 }
;
Factor -> Result<u64, ()>:
'(' Expr ')' { $2 }
| 'INT'
{
let v = $1.map_err(|_| ())?;
parse_int($lexer.span_str(v.span()))
}
;
%%
Grmtools 需要在编译时生成词法和语法解析器,因此需要创建 build.rs,其内容如下:
use cfgrammar::yacc::YaccKind;
use lrlex::CTLexerBuilder;
fn main() -> Result<(), Box<dyn std::error::Error>> {
CTLexerBuilder::new()
.lrpar_config(|ctp| {
ctp.yacckind(YaccKind::Grmtools)
.grammar_in_src_dir("calc.y")
.unwrap()
})
.lexer_in_src_dir("calc.l")?
.build()?;
Ok(())
}
use std::env;
use lrlex::lrlex_mod;
use lrpar::lrpar_mod;
// Using `lrlex_mod!` brings the lexer for `calc.l` into scope. By default the
// module name will be `calc_l` (i.e. the file name, minus any extensions,
// with a suffix of `_l`).
lrlex_mod!("calc.l");
// Using `lrpar_mod!` brings the parser for `calc.y` into scope. By default the
// module name will be `calc_y` (i.e. the file name, minus any extensions,
// with a suffix of `_y`).
lrpar_mod!("calc.y");
fn main() {
// Get the `LexerDef` for the `calc` language.
let lexerdef = calc_l::lexerdef();
let args: Vec<String> = env::args().collect();
// Now we create a lexer with the `lexer` method with which we can lex an
// input.
let lexer = lexerdef.lexer(&args[1]);
// Pass the lexer to the parser and lex and parse the input.
let (res, errs) = calc_y::parse(&lexer);
for e in errs {
println!("{}", e.pp(&lexer, &calc_y::token_epp));
}
match res {
Some(r) => println!("Result: {:?}", r),
_ => eprintln!("Unable to evaluate expression.")
}
}
上文已经提到,我们需要手写词法解析,是因为在原生的 Grmtools 中,词法解析是用正则匹配的,对于灵活复杂的 SQL 语句来说,不足以满足,因此需要手工打造词法解析,在 Grmtools 中实现自定义词法解析需要我们实现以下 Trait:
lrpar::NonStreamingLexer
另外也提供了一个方便的方法去实例化:
lrlex::LRNonStreamingLexer::new()
基于以上,我们开发了 SQL 词法解析,复用了 MySQL 官方的 sql_yacc 文件,在开发过程中,也遇到了以下问题。
Shift/Reduce conflicts:
State 619: Shift("TEXT_STRING") / Reduce(literal: "text_literal")
这是使用 LALR 算法经常出现的错误,错误成因一般通过分析相关规则解决,例如常见的 If-Else 语句,规则如下:
%nonassoc LOWER_THEN_ELSE
%nonassoc ELSE
stmt:
IF expr stmt %prec LOWER_THEN_ELSE
| IF expr stmt ELSE stmt
当 ELSE 被扫描入栈时,此时会有两种情况。
1)按第二条规则继续 Shift
2)按第一条规则进行 Reduce
这就是经典的 Shift/Reduce 错误。
回到我们的问题,有如以下规则:
literal -> String:
text_literal
{ }
| NUM_literal
{ }
...
text_literal -> String:
'TEXT_STRING' {}
| 'NCHAR_STRING' {}
| text_literal 'TEXT_STRING' {}
...
分析:
| stack | Input token | action |
|---|---|---|
| test | Shift test | |
| test | $ | Reduce: text_literal/Shift: TEXT_STRING |
方案:
需要设置优先级解决,给 text_literal 设置更低的优先级,如以下:
%nonassoc 'LOWER_THEN_TEXT_STRING'
%nonassoc 'TEXT_STRING'
literal -> String:
text_literal %prec 'LOWER_THEN_TEXT_STRING'
{ }
| NUM_literal
{ }
...
text_literal -> String:
'TEXT_STRING' {}
| 'NCHAR_STRING' {}
| text_literal 'TEXT_STRING' {}
...
在使用词法解析时,.chars() 生成字符串数组会出现数组长度和字符长度不一致的情况,导致解析出错,要更改为 .as_bytes() 方法。
[mworks@fedora examples]$ time ./parser
real 0m4.788s
user 0m4.781s
sys 0m0.002s
尝试优化,以下是火焰图:

通过火焰图发现,大部分 CPU 耗时在序列化和反序列化,以下是定位到的代码:
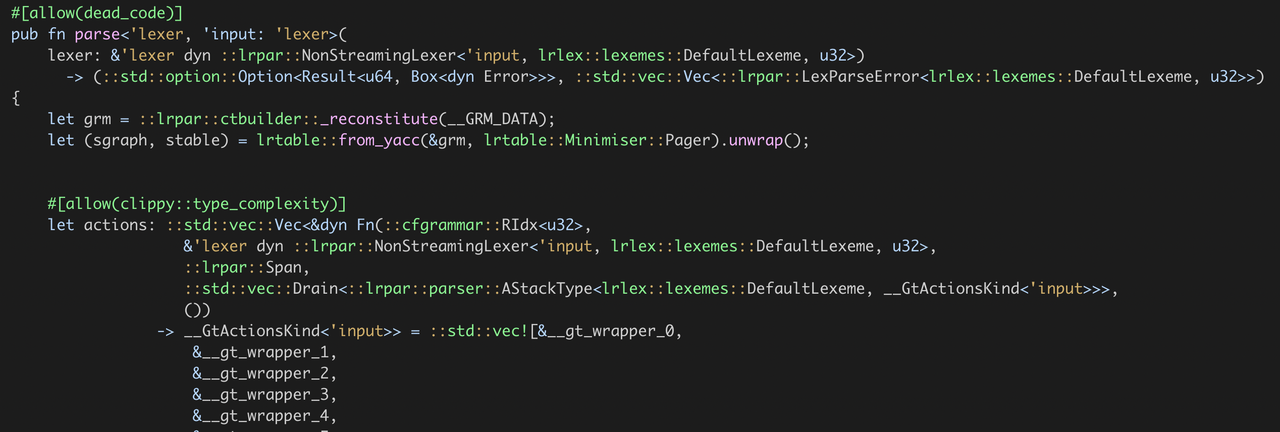
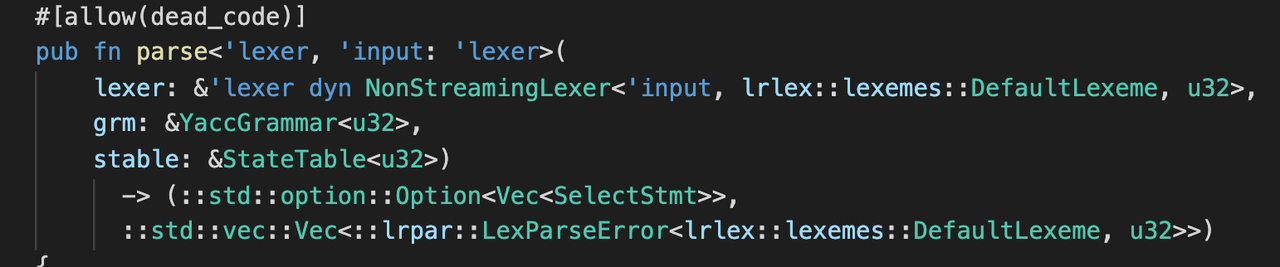
可以看出在每次解析的时候都需要反序列化数据,在编译完之后,__GRM_DATA 和 __STABLE_DATA 是固定不变的, 因此 grm,stable 这两个参数可以作为函数参数传递,更改为如下:
再看代码,发现 actions 数组是有规律的,如以下:
::std::vec![&__gt_wrapper_0,
&__gt_wrapper_1,
&__gt_wrapper_2,
...
]
因此我们可以手动构造函数,以下是伪代码:
match idx {
0 => __gt_wrapper_0(),
1 => __gt_wrapper_1(),
2 => __gt_wrapper_2(),
....
}
通过 gobolt 查看汇编,发现差异还是很大,省去了数组的相关开销,也能极大地减少内存使用。

详见:https://rust.godbolt.org/z/zTjW479f6
但是随着 actions 数组的不断增大,会有大量的 je,jmp 指令,不清楚是否会影响 CPU 的分支预测,如影响是否可以通过 likely/unlikely 方式优化,目前还没有进行测试。
最终火焰图对比
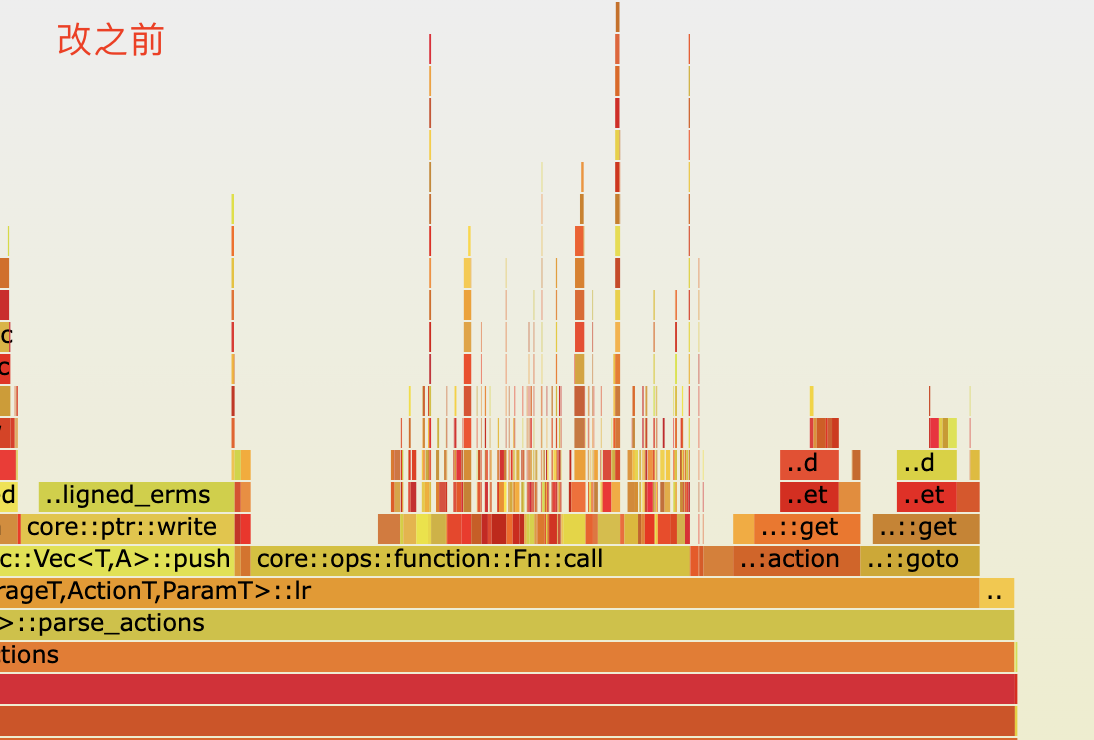
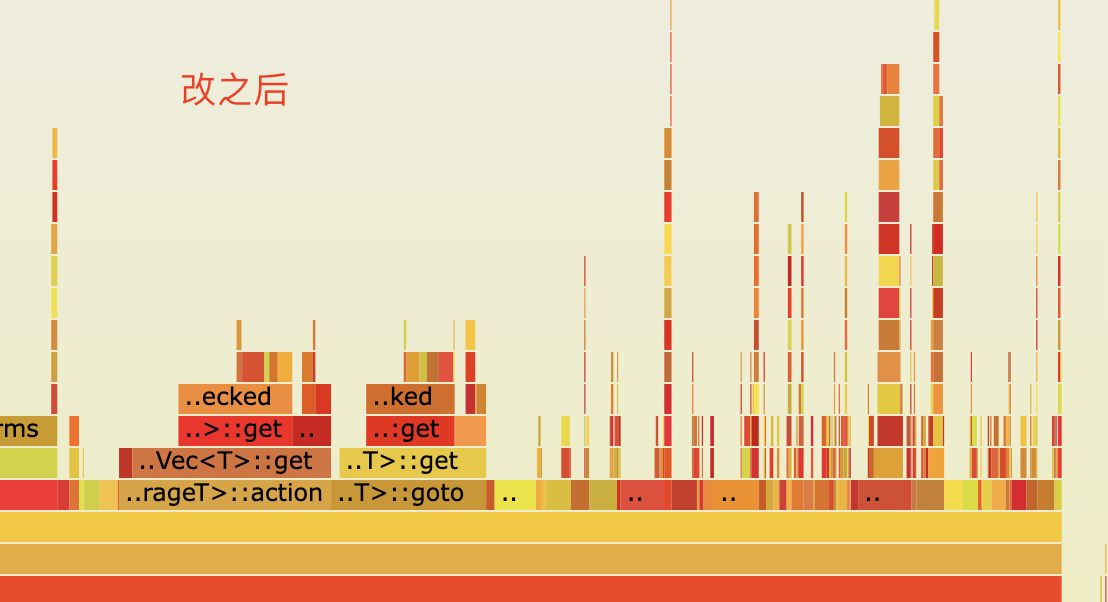
最终测试结果
[mworks@fedora examples]$ time ./parser
real 0m2.677s
user 0m2.667s
sys 0m0.007s
本文为 Pisa-Proxy SQL 解析解读系列第一篇,介绍了在 Pisa-Proxy 中开发 SQL 解析背后的故事,后续我们会陆续为大家详细介绍 Yacc 语法规则的编写,Grmtools 中组件及实用工具等内容,敬请期待。
Pisa-Proxy 的 SQL 解析代码:
pisanix/pisa-proxy/parser/mysql at master · database-mesh/pisan
测试代码
let input = "select id, name from t where id = ?;"
let p = parser::Parser::new();
for _ in 0..1_000_000
{
let _ = p.parse(input);
}
Pisanix
项目地址:https://github.com/database-mesh/pisanix
Database Mesh:https://www.database-mesh.io/
SphereEx 官网:https://www.sphere-ex.com
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来