Replit(原来是https://repl.it)是一个基于浏览器的云端协同开发平台,可用于构建开发环境、实时协作、托管网络应用等。Replit提供可创建动态或者静态网站的容器,并会自动生成免费https域名(格式为:项目名.用户名.repl.co)。这代表着任何人都可以试用Replit的云服务器创建自己的网站,或者是其他的服务,例如v2ray,而且这一切,都是免费的。之前我用过很多的云平台,什么Azure啦,heroku啦,railway啦之类的,问题是这些平台有些太贵(Azure),有些改了免费策略已经不适合我们这些白嫖党使用(Heroku、Railway),我现在还在用的也就是Glitch(开多个账号,反正一个账号1000H/mo,就是配额太小了)
Replit官方文档:https://docs.replit.com/
Repl.it官网:https://repl.it 或者 https://replit.com
注册, 创建项目,部署服务,服务保活
可以选择google登陆,也可以选择github登陆等,或者自己注册,我为了方便,就google登陆了
然后就会进入主界面
在这里,我们可以点击左边的Create来创建一个实例,里面也有一些模板,可以根据自己的需要创建,我这里就选一个空项目(直接选到bash就行)了
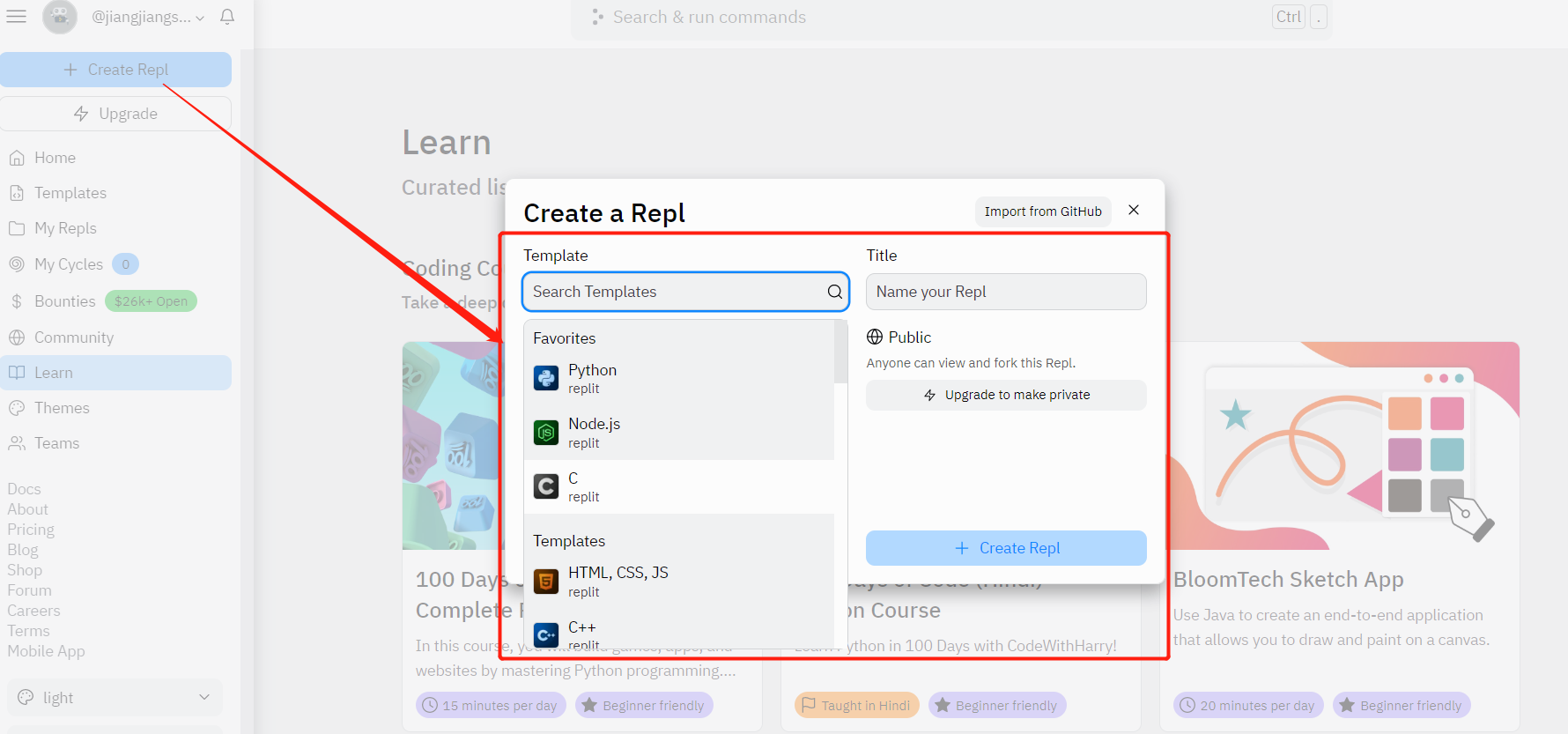
进入到项目的编辑界面,在左边有个Repl Resources可以看到配额,这个配额确实不能说很多:

我们点击左边Files右边的三个点,然后点击Show hidden files,把隐藏文件显示打开,肯定会用到的 下面会多出两个东西,一个是.replit,一个是replit.nix,其中,.replit里面存放的是项目的配置,包括启动命令啥的;而replit.nix里面存放的是nix包的信息,你可以在里面增添你想要的包.
下面会多出两个东西,一个是.replit,一个是replit.nix,其中,.replit里面存放的是项目的配置,包括启动命令啥的;而replit.nix里面存放的是nix包的信息,你可以在里面增添你想要的包.
因为replit是不能使用sudo命令的(特殊手段另说),所以说想要安装新的软件只能通过nix包管理器来加。
Replit获得root权限的方法,首先,我们在Replit创建一个Bash;然后我们在项目右侧Console窗口依次执行下列命令:
wget https://cdn.discordapp.com/attachments/853535040250970113/878590395611775016/yt.zip (需要回车一次)
unzip yt.zip (需要回车一次)
unzip root.zip
tar -xvf root.tar.xz
./dist/proot -S . /bin/bash以上的命令说明:首先下载yt.zip,然后解压文件,恢复文件,然后执行bash;
当我们执行完所有命令,你就会发现,已经是root啦~
以pip的安装为例,首先我们在shell里面输入pip的时候会提示未安装,让我们选择需要的pip版本,按需要选择就行
然后nix包就会帮我们自动安装,在replit.nix里面也可以看到加入了一行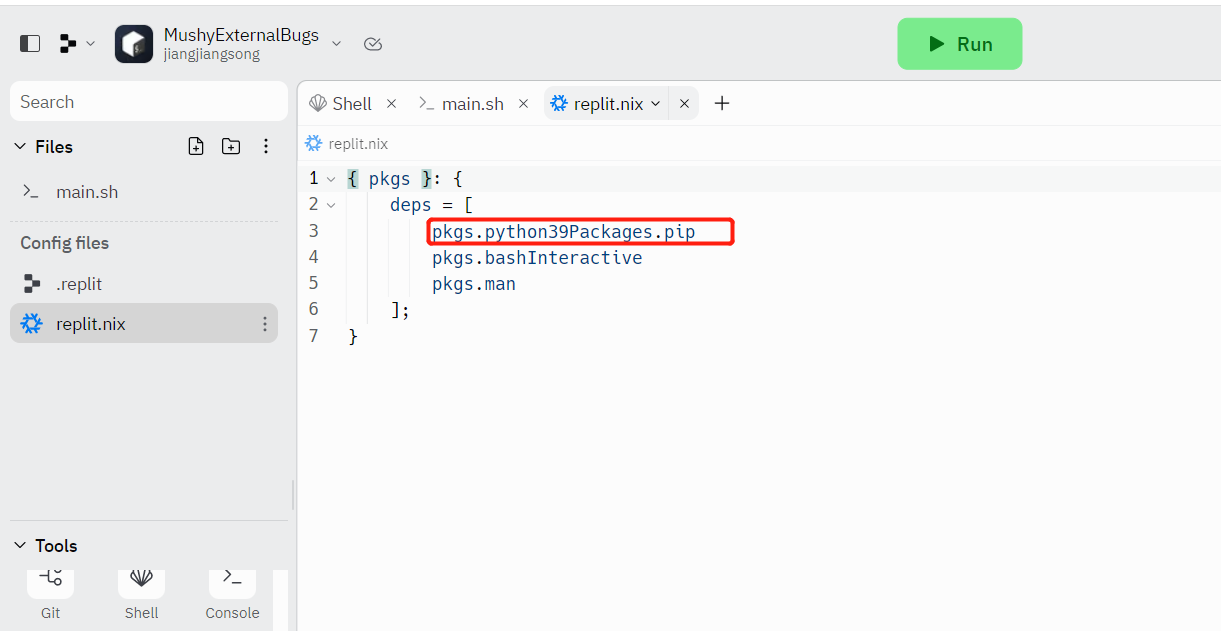
我这里上传一个biliCDN:哔哩CDN —— 用量查询 | GamerNoTitle的主页作为演示,需要注意的是,可能是因为replit的nix路径配置问题,直接用pip安装的时候会出现权限不够的问题,所以我们要加入--target=这一个参数来指定安装的目录,我这里直接安装到了当前目录,虽然右边还是报了错,但是左边的目录里面可以看到轮子已经安装完了:
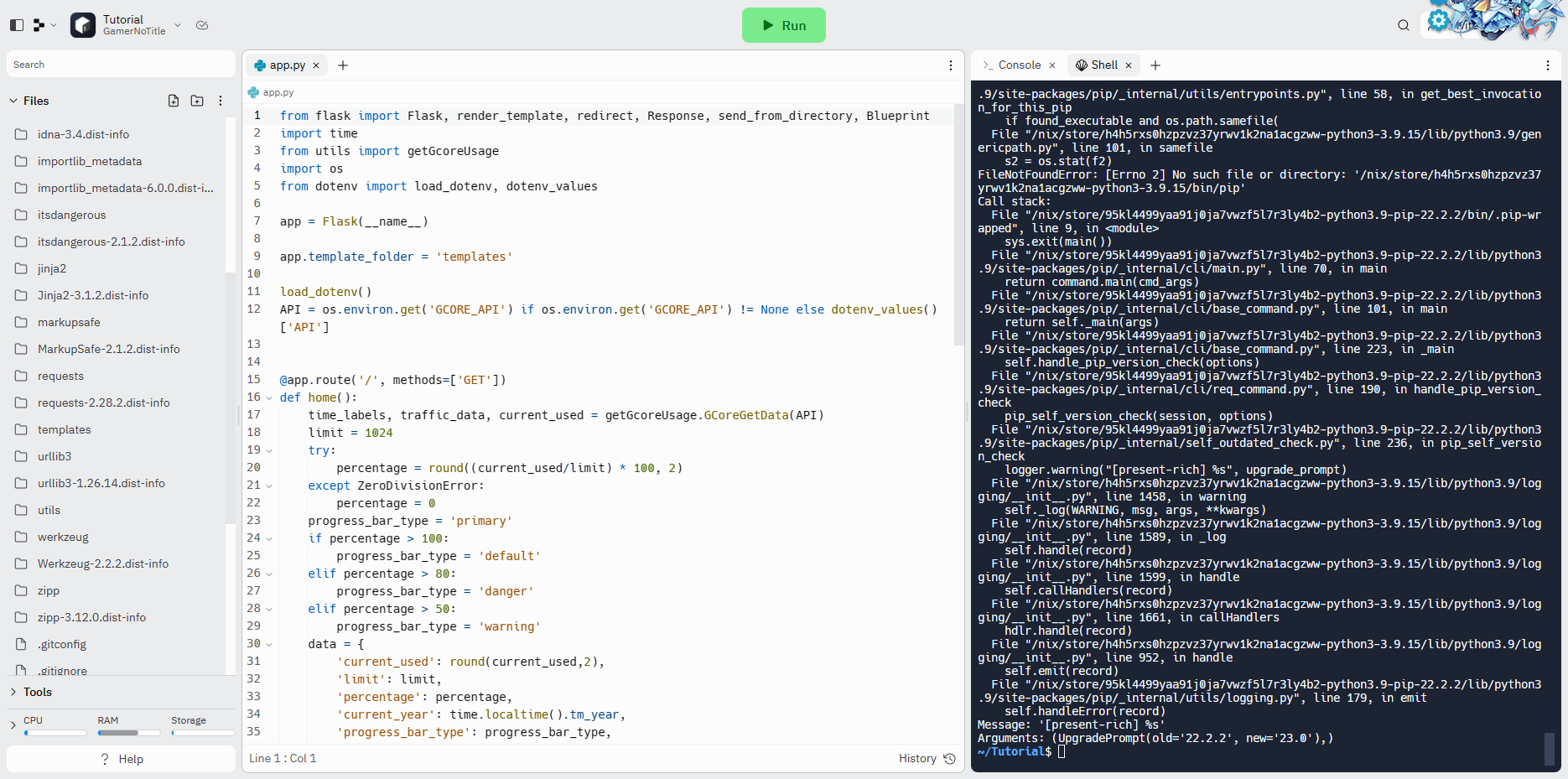
这时候,修改一下main.sh里面的内容,改成能启动我们的服务(不建议改.replit里面的内容,容易因为$PATH里面没有加入环境变量而无法启动)
$ python app.py启动完了以后,如果你的是HTTP服务的应用的话,会有一个webview窗口(如图),也会分配一个域名给你,不过可以绑定自定义域名,倒不如说建议绑定自定义域名,分配的repl.co实在是太慢了
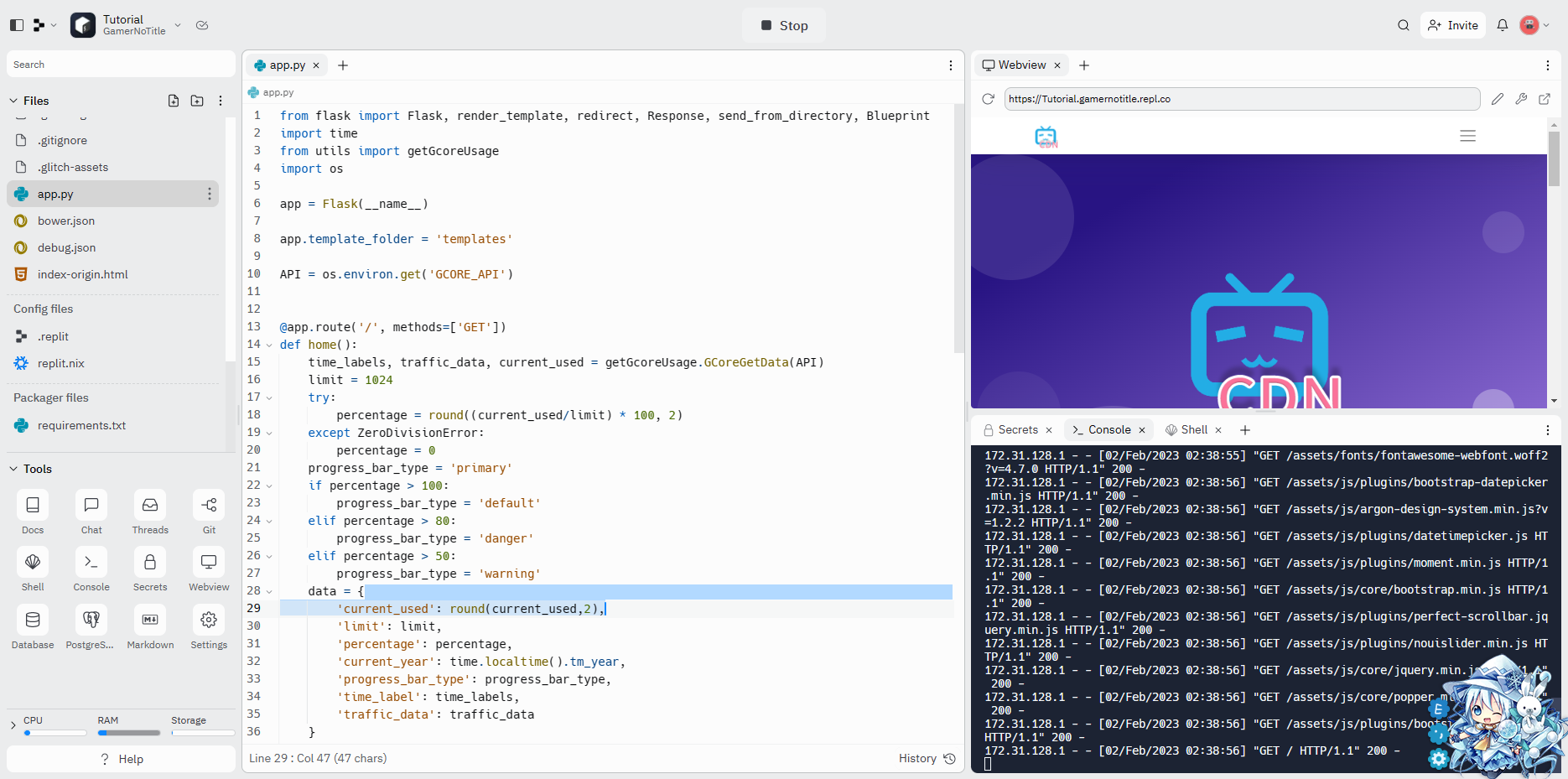
按照replit的规则,应用如果5分钟闲置就会被休眠(所以推荐在这上面部署HTTP服务,如果是TCP啥的容易活不了)
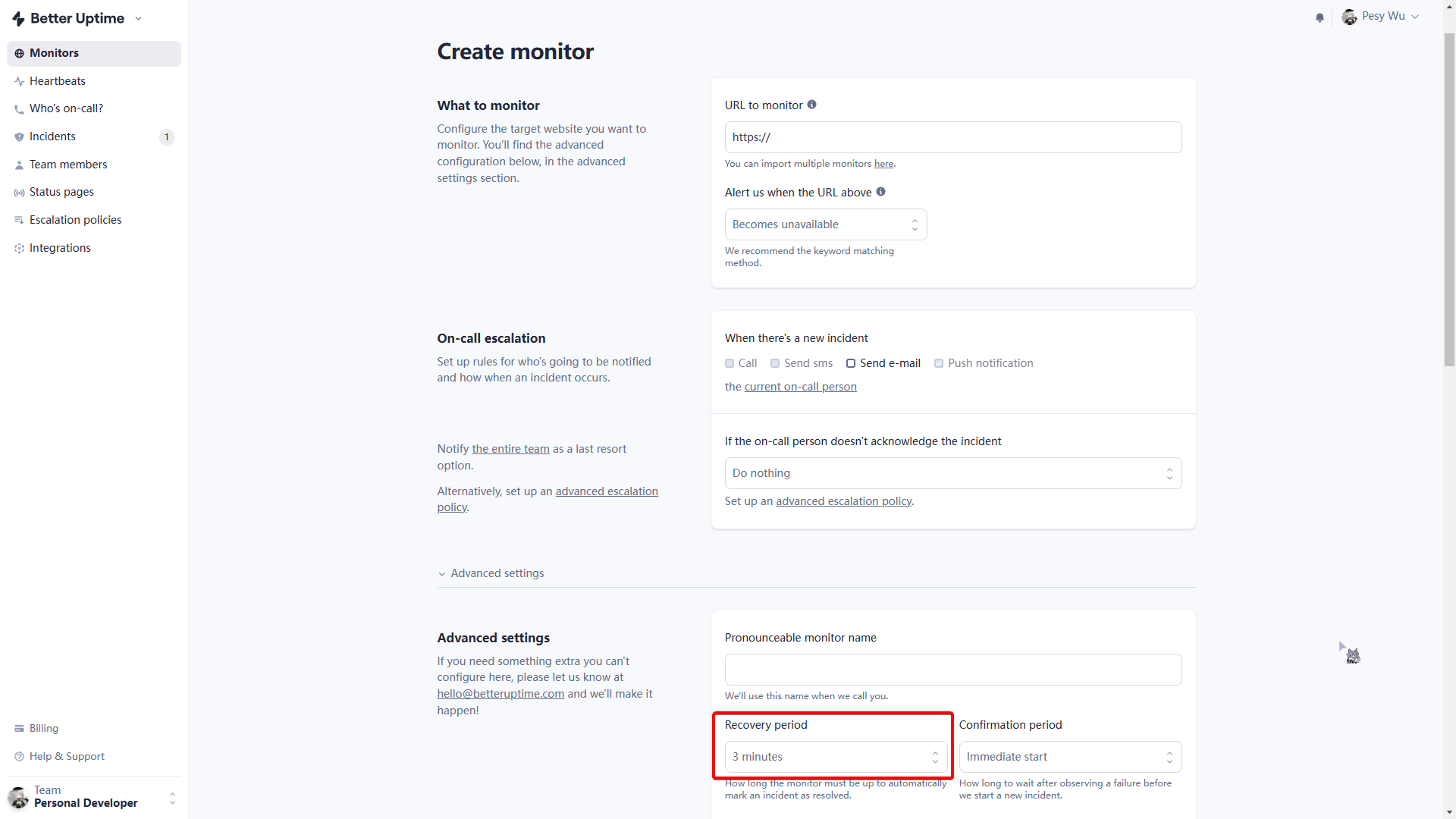
这里我用了网站监控平台BetterUptime,用法其实跟很多监控平台一样,就是加入自己的网站,然后定时监控。
或者使用updown.io实现监控: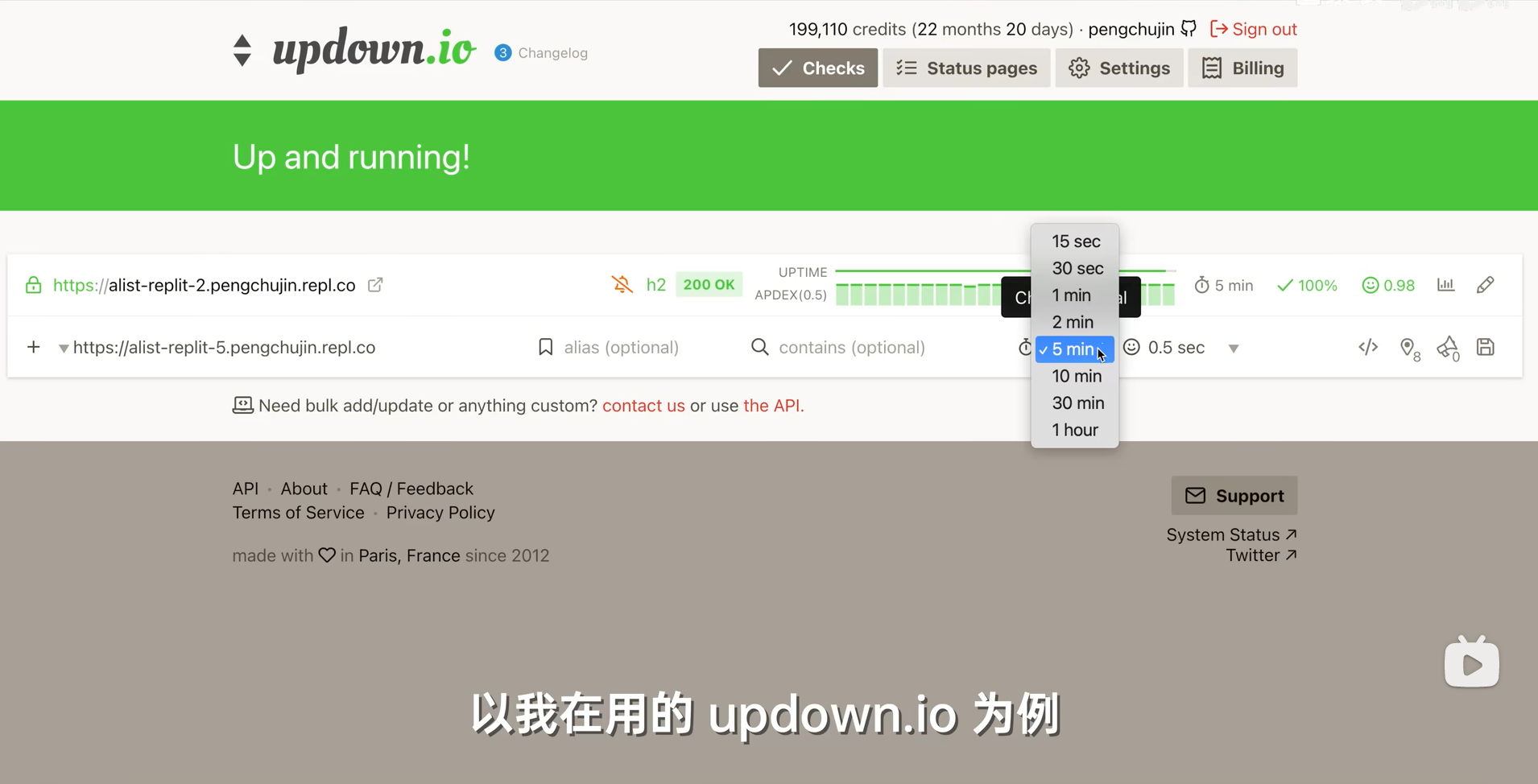
主要是监控的间隔时间要选择3分钟,要不然容易断掉
改完然后保存就行了,然后可以在Panel里面看到刚刚加进去的网站,然后放着不管就行了,只要没有报错的话就不会断掉的撒。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame