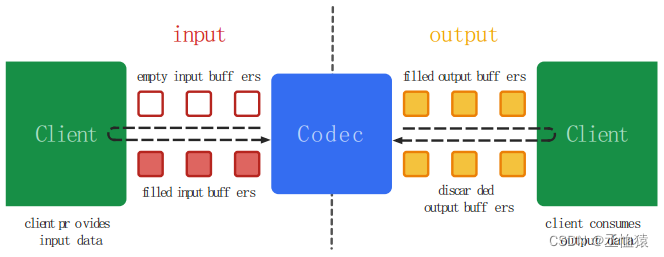
1.把原始数据放入输入缓冲区队列中一个空缓冲区上; 2.编/解码器从输入缓冲队列中获取缓冲区上数据,进行编码处理,结果存放到输出缓冲区上一个空缓冲区上, 处理完毕后,释放该输入缓冲区,它会被重新放回输入缓冲区队列,以便下次重复使用; 3.对输出缓冲区上数据做自己需要的业务处理处理,处理完毕后,释放该输出缓冲区, 它会被重新放回输出缓冲区队列,以便下次重复使用。
##.当对视频帧进行编/解码时,一般会用编码器创建一个输入Surface或为编码器设置一个输出Surface,在这里Surface充当着数据缓冲区的角色。 使用Surface可以提高编/解码器的性能,Surface直接使用native视频数据缓存,没有映射或复制它们到ByteBuffers,这种方式会更加高效。

1.停止态(Stopped): 1.1 未初始化状态(Uninitialized) 1.2 配置状态(Configured) 1.3 错误状态(Error) 2.执行态(Executing): 2.1 刷新状态(Flushed) 2.2 运行状态( Running) 2.3 流结束状态(End-of-Stream) 3.释放态(Released)
1.一般流程为创建编/解码器,此时处于未初始化状态(Uninitialized); 2.调用configure(…)方法对编解码器进行配置,使编解码器转入配置状态(Configured); 3.调用start()方法,使其转入执行刷新状态(Flushed); 4.此时编解码器已经拥有其输入/输出缓存,当第一个输入缓存区被移出队列,编解码器转入运行状态( Running); 5.在运行状态( Running)中,编解码器不断对输入缓冲区中数据做编解码操作,结果存到输出缓冲区; 6.当一个带有end-of-stream标记的输入缓存入队列时,编解码器将转入流结束状态(End-of-Stream)。 在这种状态下,编解码器不再接收新的输入缓存,但它仍然产生输出缓存。直到 7.当输入缓存中所有数据都被处理完,带有end-of-stream标记的数据帧到达输出缓存后,转入释放态(Released)。 当我们处理完输出数据后,在此状态下可以用release()进行相关资源的释放。
1.在执行状态(Executing)下的任何时候,通过调用flush()方法使编解码器重新返回到刷新子状态(Flushed); 2.通过调用stop()方法使编解码器返回到未初始化状态(Uninitialized),此时这个编解码器可以再次重新配置; 3.编解码器遇到错误时会进入错误状态(Error),此时应调用reset()方法使编解码器再次可用。 4.任何状态下调用reset()方法使编解码器返回到未初始化状态(Uninitialized)
createDecoderByType:获取解码器对象 createEncoderBytype:获取编码器对象 configure:对编解码器进行配置,使编解码器转入配置状态 start:使编码器转入执行刷新状态 stop:结束并返回到未初始化状态 release:释放实例资源 createInputSurface:创建输入缓冲Surface setOutputSurface:设置输出缓冲Surface getInputBuffers:获取需要编码数据的输入流队列,返回的是一个ByteBuffer数组 queueInputBuffer:输入流入队列 dequeueInputBuffer:从输入流队列中取数据进行编码操作 getOutputBuffers:获取编解码之后的数据输出流队列,返回的是一个ByteBuffer数组 dequeueOutputBuffer:从输出队列中取出编码操作之后的数据 releaseOutputBuffer:处理完成,释放ByteBuffer数据
1.同步方式:数据输入和数据输出依次进行。 要等待上一次数据输入后,才能数据输出; 等待上一次数据输出后,才能再次进行数据输入。 2.异步方式:数据输入和数据输出操作顺序相互独立。 是底层服务来判断何时输入/输出可以进行,然后进行相应回调, 开发者在回调中进行数据输入/输出处理。
//异步处理方式时,需要设置回调接口。
//在回调中进行数据处理
mEncoder.setCallback(new MediaCodec.Callback() {
//有可用的输入缓冲区时回调
@Override
public void onInputBufferAvailable(@NonNull MediaCodec codec, int index) {
}
//有可用的输出缓冲区时回调
@Override
public void onOutputBufferAvailable(@NonNull MediaCodec codec, int index, @NonNull MediaCodec.BufferInfo info) {
}
//输出格式变化时回调
@Override
public void onOutputFormatChanged(@NonNull MediaCodec codec, @NonNull MediaFormat format) {
}
//出错时回调
@Override
public void onError(@NonNull MediaCodec codec, @NonNull MediaCodec.CodecException e) {
}
});有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
在前面两节的例子中,主界面窗口的尺寸和标签控件显示的矩形区域等,都是用C++代码编写的。窗口和控件的尺寸都是预估的,控件如果多起来,那就不好估计每个控件合适的位置和大小了。用C++代码编写图形界面的问题就是不直观,因此Qt项目开发了专门的可视化图形界面编辑器——QtDesigner(Qt设计师)。通过QtDesigner就可以很方便地创建图形界面文件*.ui,然后将ui文件应用到源代码里面,做到“所见即所得”,大大方便了图形界面的设计。本节就演示一下QtDesigner的简单使用,学习拖拽控件和设置控件属性,并将ui文件应用到Qt程序代码里。使用QtDesigner设计界面在开始菜单中找到「Q
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我正在编写一个简单的日志嗅探器,它将在日志中搜索表明我支持的软件存在问题的特定错误。它允许用户指定日志路径并指定他们想要搜索多少天前。如果用户关闭日志滚动,日志文件有时会变得非常大。目前我正在做以下事情(虽然还没有完成):File.open(@log_file,"r")do|file_handle|file_handle.eachdo|line|ifline.match(/\d+++-\d+-\d+/)etc...line.match显然会查找我们在日志中使用的日期格式,其余逻辑将在下面。但是,有没有更好的方法来搜索没有.each_line的文件?如果没有,我完全同意。我只是想确保我使
我有一个这样的哈希{55=>{:value=>61,:rating=>-147},89=>{:value=>72,:rating=>-175},78=>{:value=>64,:rating=>-155},84=>{:value=>90,:rating=>-220},95=>{:value=>39,:rating=>-92},46=>{:value=>97,:rating=>-237},52=>{:value=>73,:rating=>-177},64=>{:value=>69,:rating=>-167},86=>{:value=>68,:rating=>-165},53=>{:va