推荐:前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。。 点击跳转到网站
最近一周都在学习ElasticSearch,之前也零零散散的学过一点,这次下定决心花一周的时间将之前学的知识总结一下,顺便接着再往下学习,所以写篇博客总结一下最近一周的成果,本篇属于ElasticSearch的基础篇,后面会继续深入学习。也希望这篇拙作可以帮助到诸位大佬,如有不足之处,还望诸佬不吝赐教,倾囊相授。

ElasticSearch学习总结
ElasticSearch、简称ES,ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据,ES也使用Java开发使用Lucene作为其核心来实现所有索引和搜索的功能,但是他的目的是通过简单的RestFul API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch是一个实时分布式搜索和分析引擎,它让你以前所未有的速度处理大数据成为可能
它用于全文搜索、结构化、分析以及将这三者混合使用
维基百科使用ElasticSearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错等搜索建议功能……
ElasticSearch是一个基于Apache Lucene的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进,性能最好的,功能最全的搜索引擎库
但是,Lucene只是一个库,想要使用它,你必须使用java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的
ElasticSearch也使用java开发并使用Lucene作为其核心来实现所有索引和搜索功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单!
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器,Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展、并对索引、搜索性能进行了优化!
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr索引的实现方法很简单,==用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据xml文档添加,删除,更新索引,==Solr搜索只需要发送HTTP GET请求,然后对Solr返回xml、json等格式的查询结果进行解析,组织页面布局,Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr是基于Lucene开发企业级搜索服务器,实际上就是封装Lucene
Solr是一个独立的企业级搜索应用服务器,它对外提供类似与web-service的API接口,用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引,也可以通过提交查找请求,并得到返回结果!
ElasticSearch 和 Solr

ElasticSearch vs Solr
6.Solr比较成熟,有一个更大,更成熟的用户,开发和贡献者社区,而ElasticSearch相对开发维护者少,更新太快,学习成本较高
Java开发,ElasticSearch的版本和我们之后对应的java的核心jar包,版本对应,java环境正常!
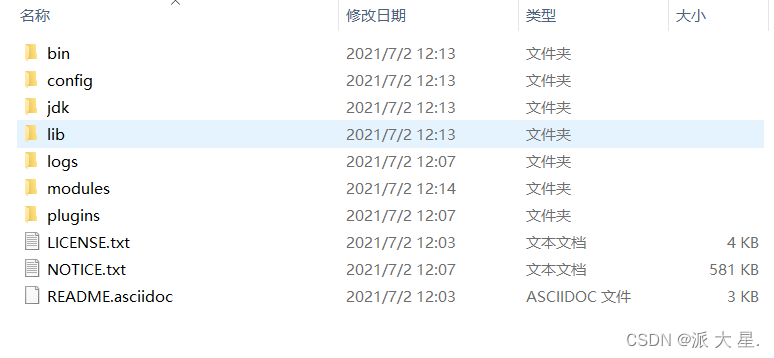
2、熟悉目录
bin 启动文件
config 配置文件
log4j2 日志配置文件
jvm.options java虚拟机相关的配置
ElasticSearch ElasticSearch配置文件 默认端口9200 !跨域
lib 相关jar包
modules 功能模块
plugins 插件
3、启动 ,访问9200 elasticsearch.bat

4、访问测试
安装可视化界面 es head的插件
1、下载地址https://github.com/mobz/elasticsearch-head
2、启动
npm install 安装依赖
npm run start 启动
3、连接测试发现,存在跨域问题:配置es
http.cors.enabled: true
http.cors.allow-origin: "*"
4、重启es ,再次连接

初学,可以把es当做一个数据库!(可以建立索引(库),文档(库中的数据))
这个head我们就把它当做数据展示工具!我们后面所有的查询,Kibana

安装Kibana
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索,查看交互存储在ElasticSearch索引中的数据,使用Kibana,可以通过各种图表进行高级数据分析及展示,Kibana让海量数据更容易理解,基于浏览器的用户界面可以快速创建仪表板实时显示ElasticSearch查询动态,设置Kibana非常简单,无序编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动ElasticSearch索引检测。
官网:https://www.elastic.co/cn/kibana
Kibana版本要和ES版本一致
启动测试
1、目录结构
2、启动
3、开发工具!(POST、curl、head、谷歌浏览器插件)
之后的所有的操作都在这里编写
4、汉化!自己修改Kibana.yml ! zh-CN

概述
集群、节点、索引、类型、文档、分片、映射是什么?
elasticSearch是面向文档,关系型数据库 和 ElasticSearch 客观的对比!一切都是JSON
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档重女又包含多个字段(列)
物理设计:
ElasticSearch在后台把每个索引划分为多个分片,每分分片可以在集群中的不同服务器间迁移
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2,当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引–>类型–>文档ID。通过这个组合我们就能索引到某个具体的文档,注意:ID不必是整数,实际上它是个字符串
文档
之前说ElasticSearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,ElasticSearch,文档有几个重要属性:
类型

索引(就是一个数据库)


倒排索引

什么是IK分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们把搜索时会把自己的信息进行分词,会把数据库中或索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词。比如:“我爱狂神”会被分为:”我“,”爱“,”狂“,”神“,这显然是不符合要求的,所以我们需要安装中文分词器IK来解决这个问题
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
下载安装
1、https://github.com/medcl/elasticsearch-analysis-ik
2、下载完毕之后,直接放在ElasticSearch插件中即可!
3、重启ElasticSearch
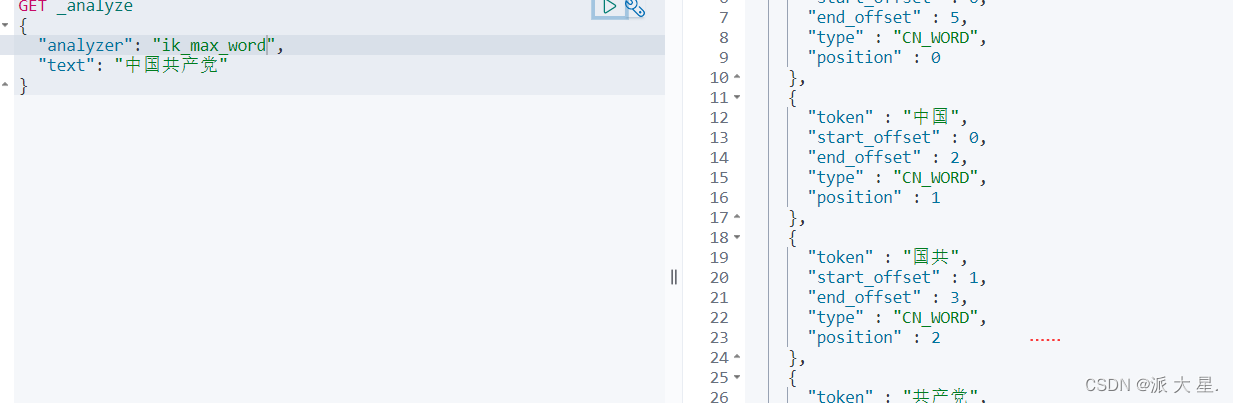
测试分词器效果
ik__smart
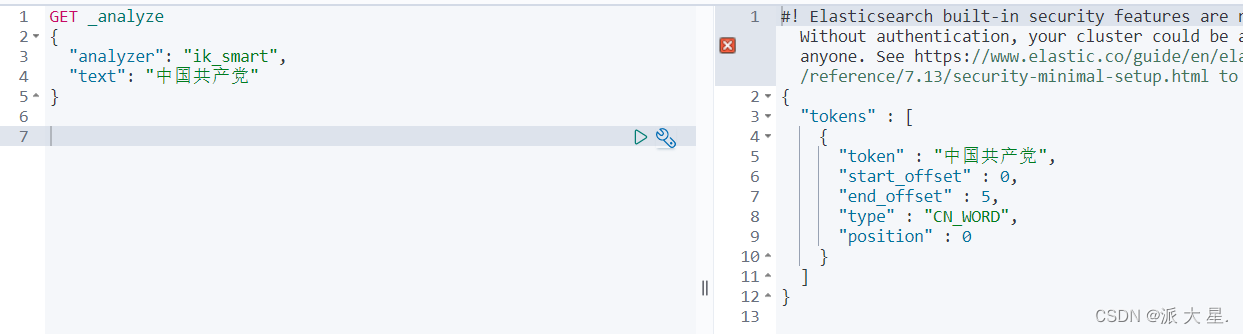
ik_max_word
ik分词器增加自己的配置!
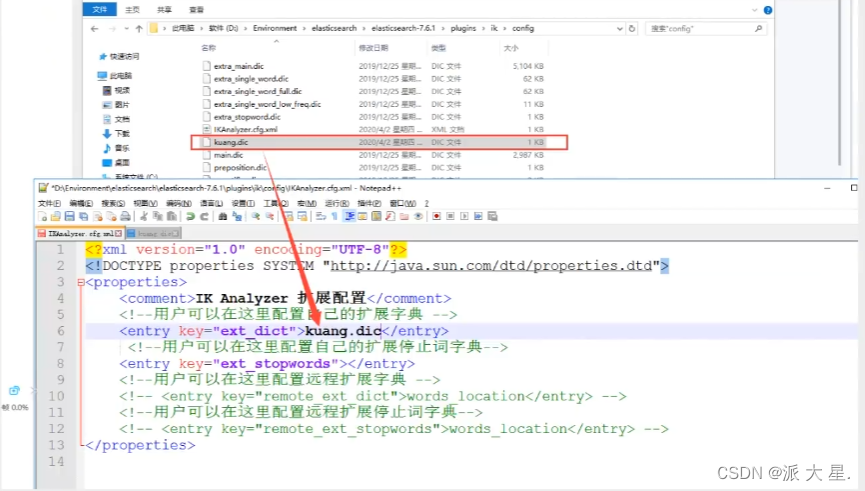
保存后重启ES!

一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件,它主要用于客户端和服务端交互类的软件,基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本的Rest命令说明:
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
基础测试
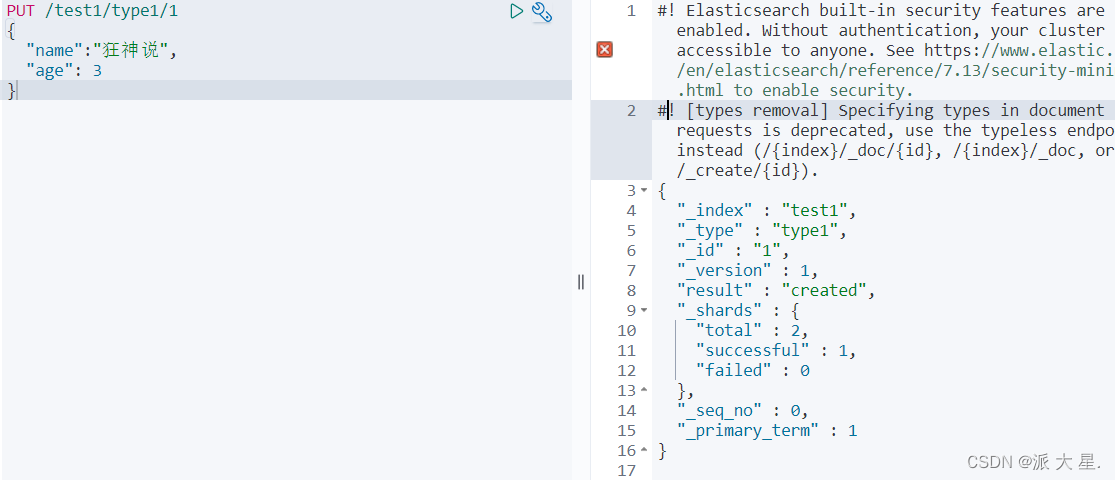
1、创建一个索引
PUT /索引名/类型名/文档id
{请求体}
2、向索引中PUT值
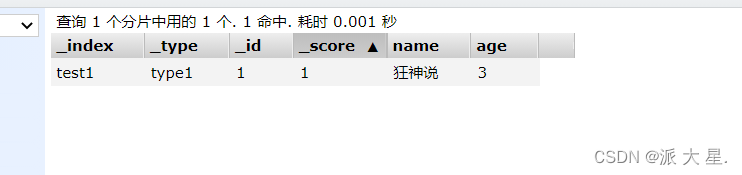
3、name这个字段用不用指定类型呢,毕竟我们关系型数据库,是需要指定类型的
字符串类型
text 、keyword
数值类型
long、integer、short、byte、double、float、half、float、scaled
日期类型
date
te布尔值类型
boolean
二进制类型
binary
等等……
4、指定字段的类型(创建规则)
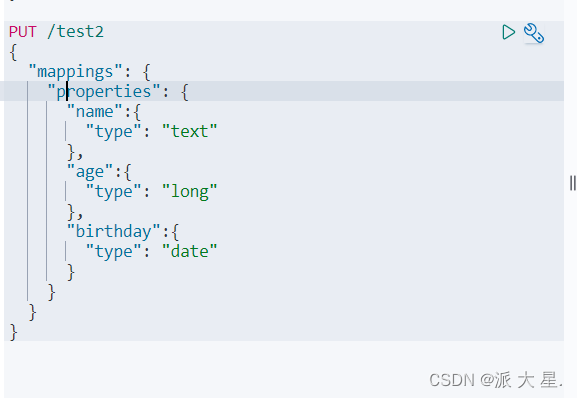
获取规则,可以通过get请求获取具体的信息
GET test2
测试
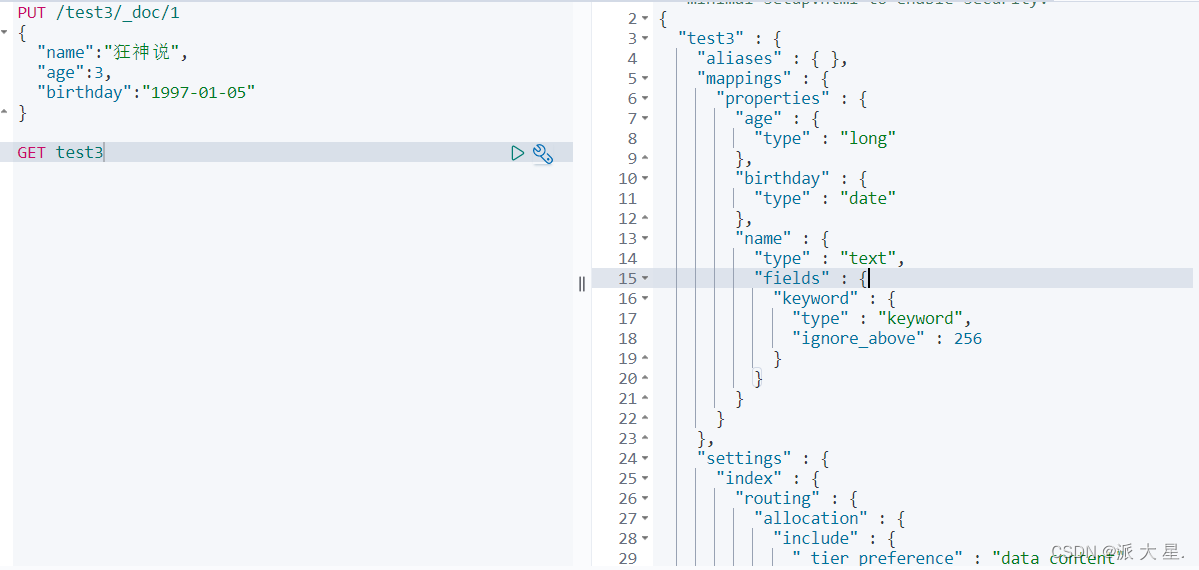
如果自己的文档字段没有自定,那么es会给我们配置默认字段类型!
扩展:通过命令ElasticSearch索引情况! 通过get _cat/ 可以获得ElasticSearch的很多信息

修改索引 提交还是使用PUT
曾经的方法:
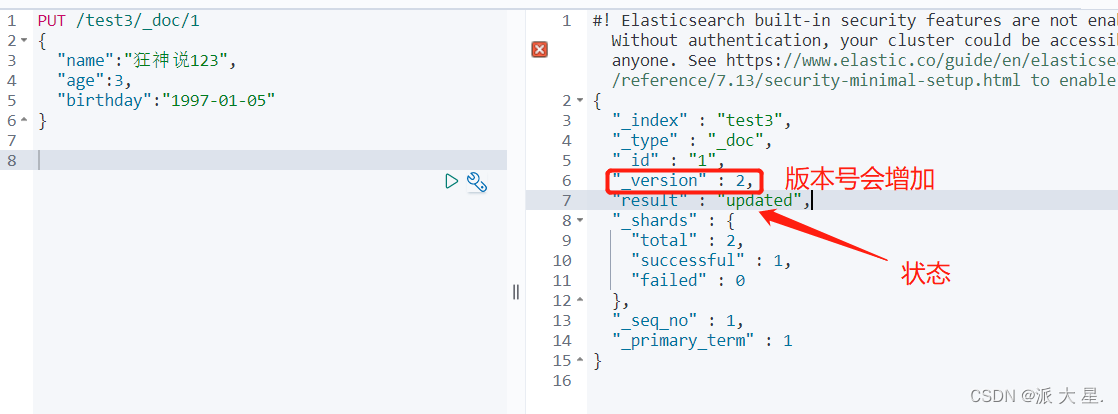
最新办法
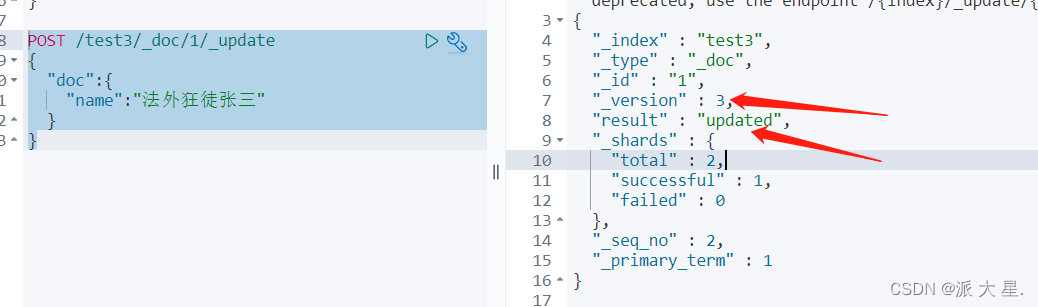
删除索引 通过DELETE命令实现删除,根据你的请求来判断是删除索引还是删除文档记录!
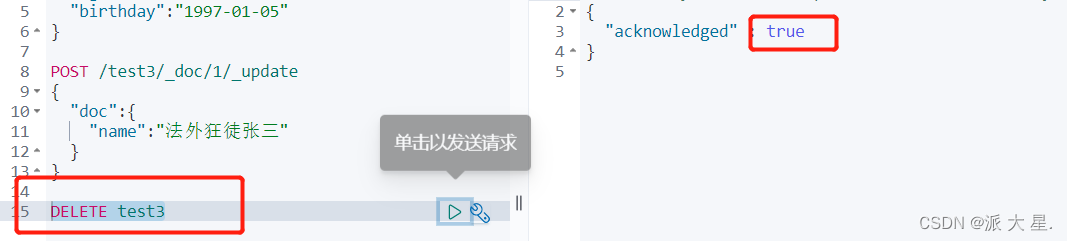

基本操作
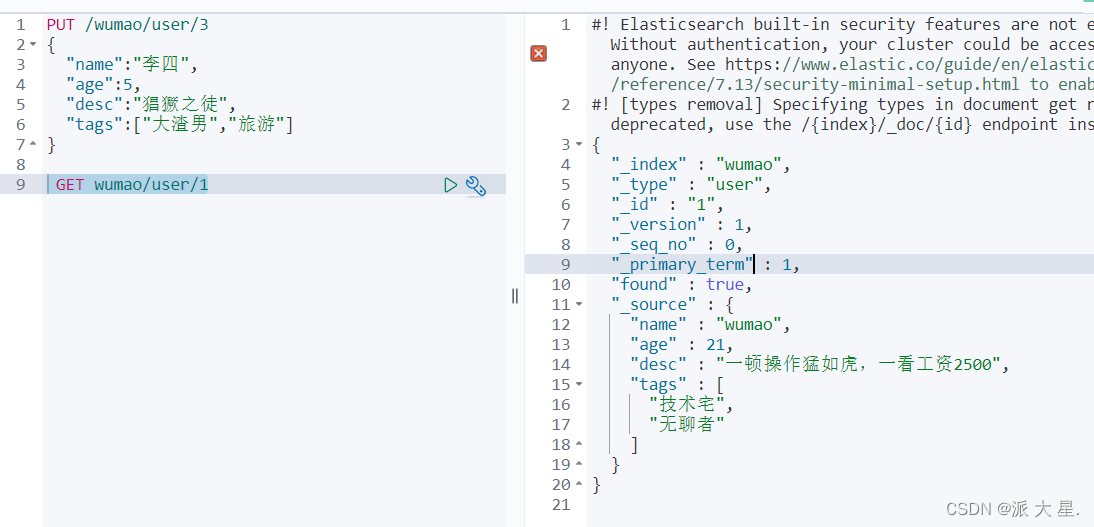
1、添加一条数据
PUT /wumao/user/1
{
"name":"wumao",
"age":21,
"desc":"一顿操作猛如虎,一看工资2500",
"tags":["技术宅","无聊者"]
}

2、获取数据 GET
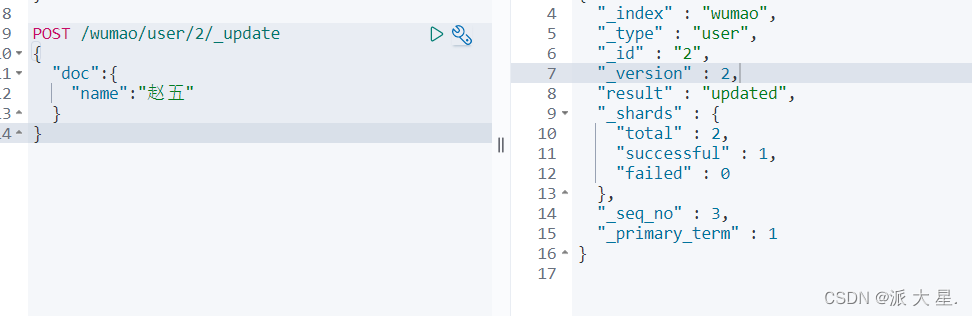
3、更新操作 POST _update推荐使用这种更新方式
简单的搜索
GET wumao/user/1
简单的条件查询 ,可以根据默认的映射规则,产生基本的查询!
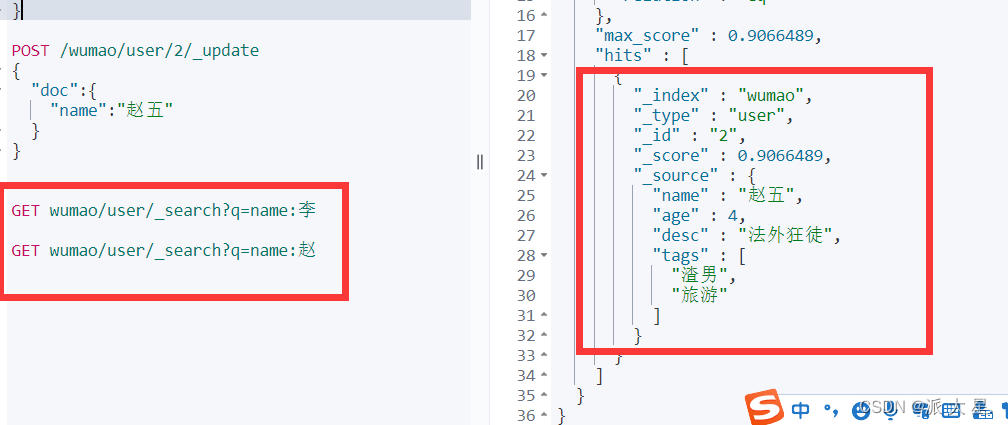
复杂操作 搜索 select(排序、分页、高亮、精准查询!)
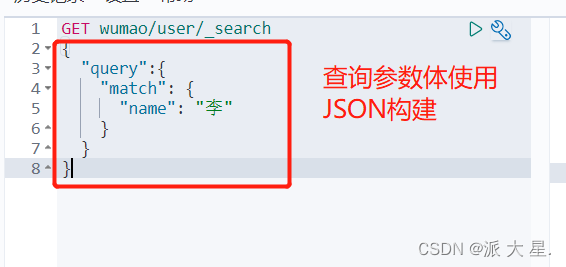
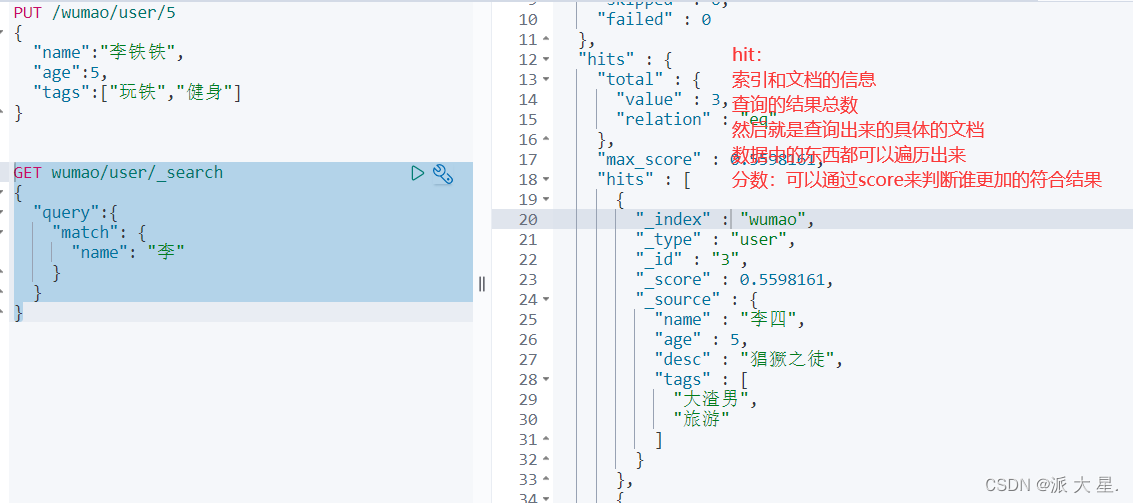
输出结果,不想要那么多结果!select name,desc . . . .
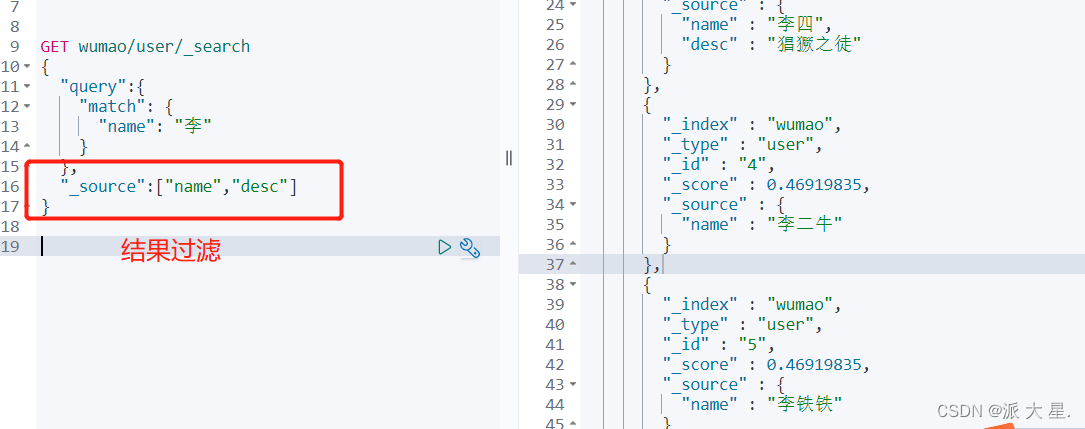
之后使用Java操作es,所有的方法和对象就是这里面的key!
排序
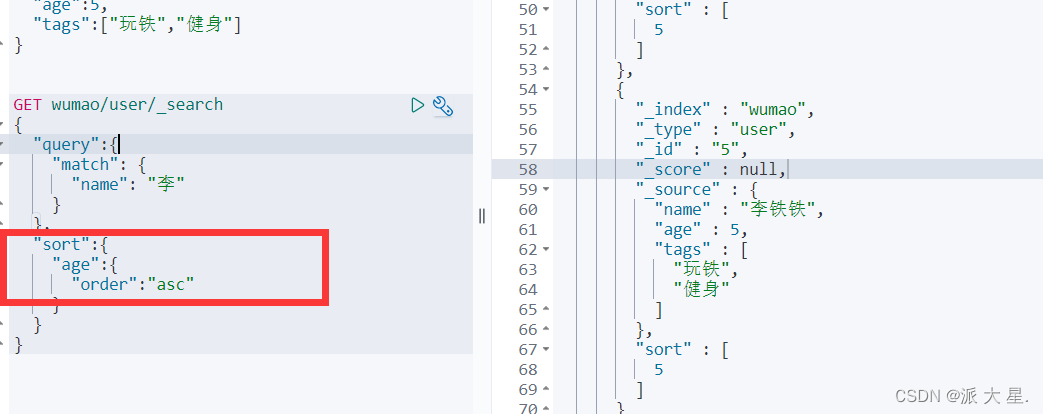
分页
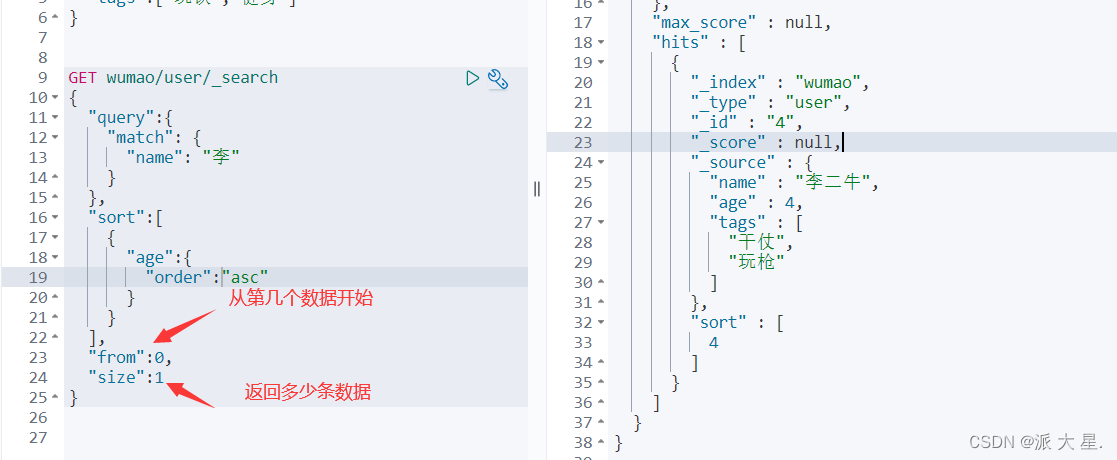
数据下标还是从0开始的,和学的所有数据结构是一样的!
/search/{current}/{pageSize}
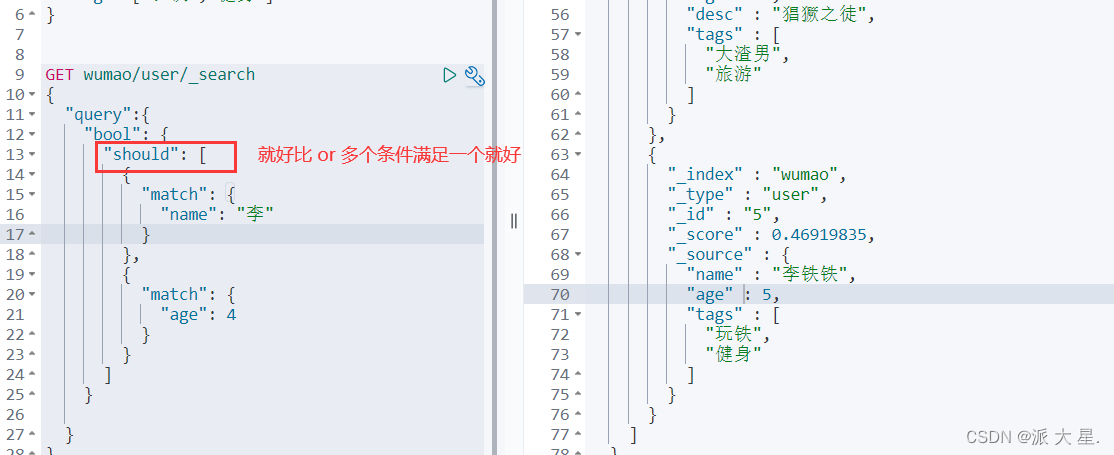
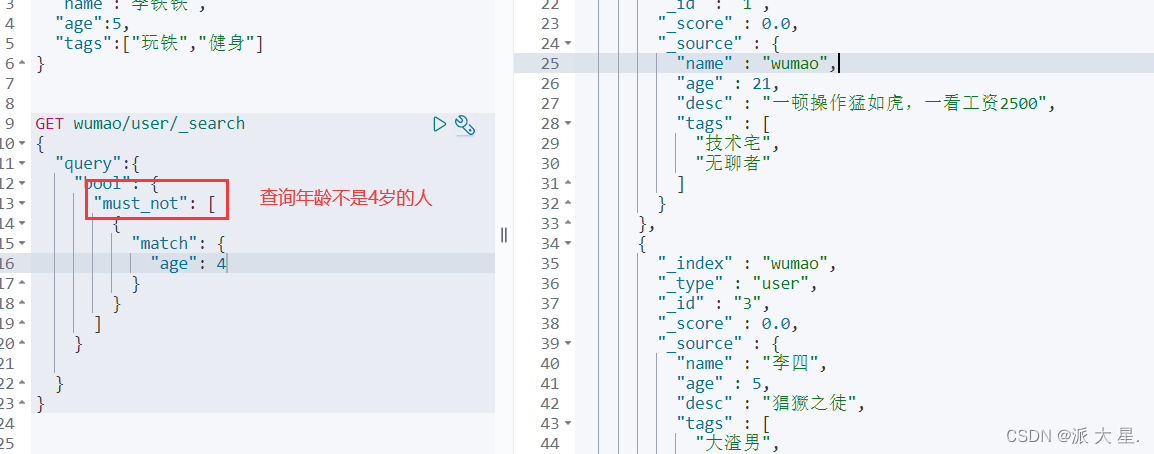
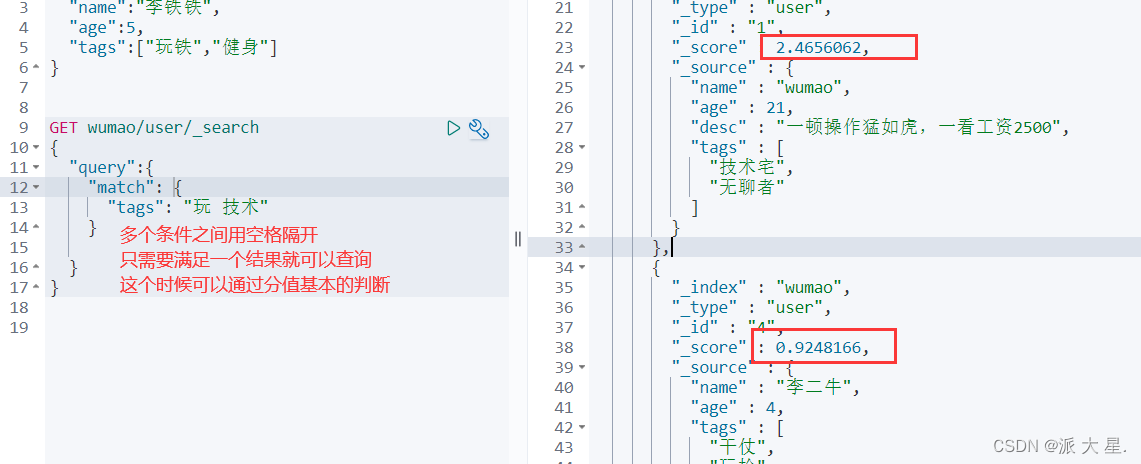
布尔值查询
must (and),所有的条件都要符合 where id = 1 and name =xxx
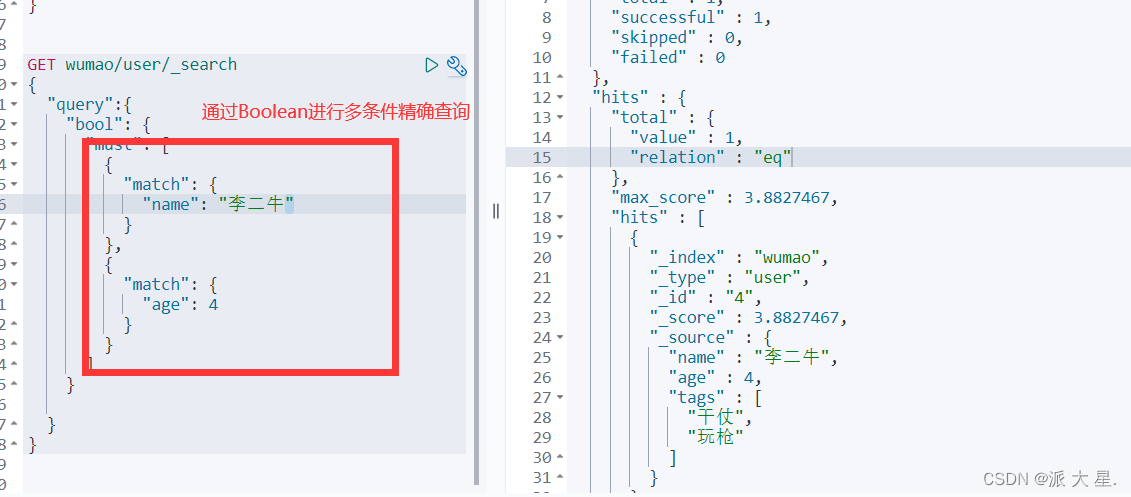
should( or ),所有的条件都要符合 where id = 1 orname =xxx
must_not(not)
过滤器filter
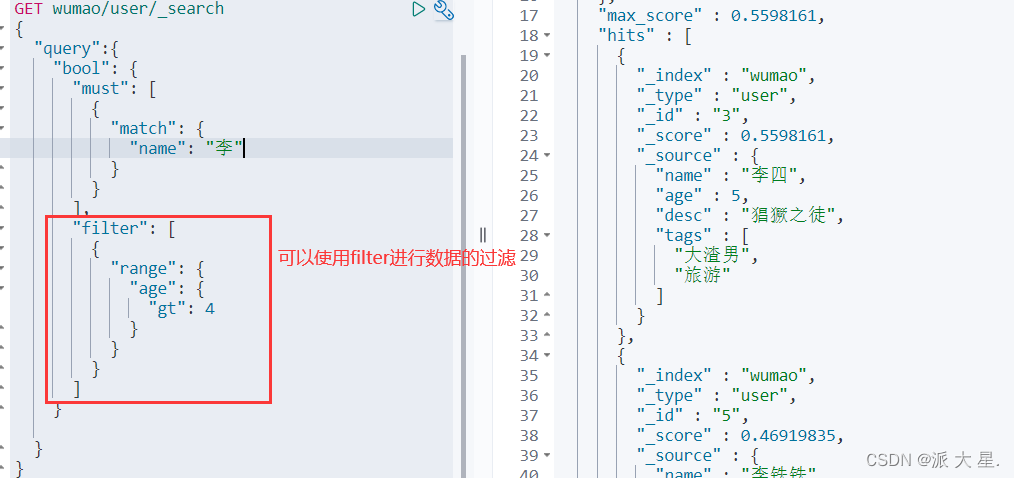
gt > 大于
gte >= 大于等于
lt < 小于
lte <= 小于等于
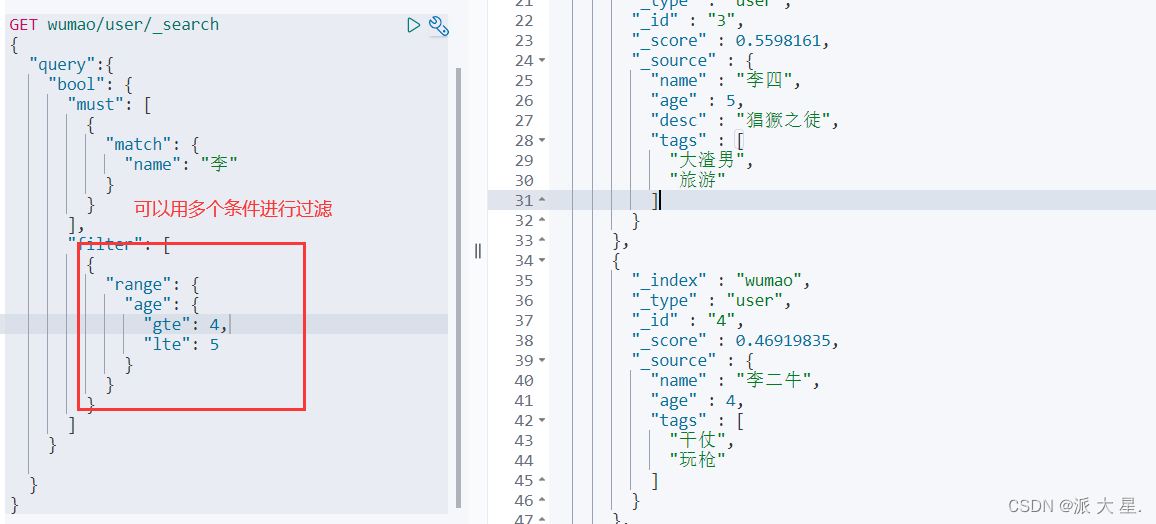
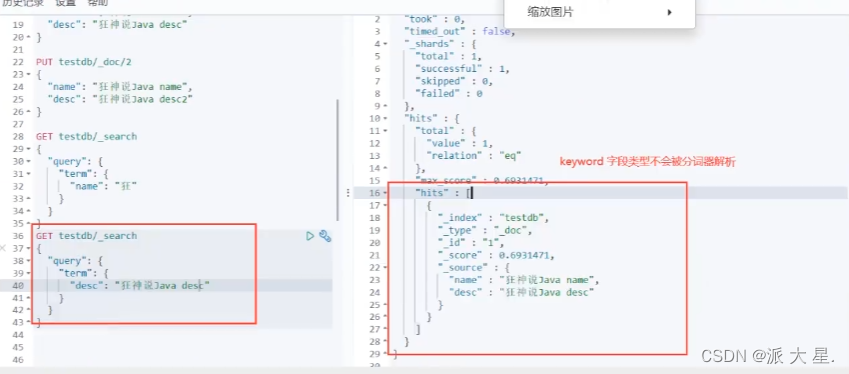
匹配多个条件
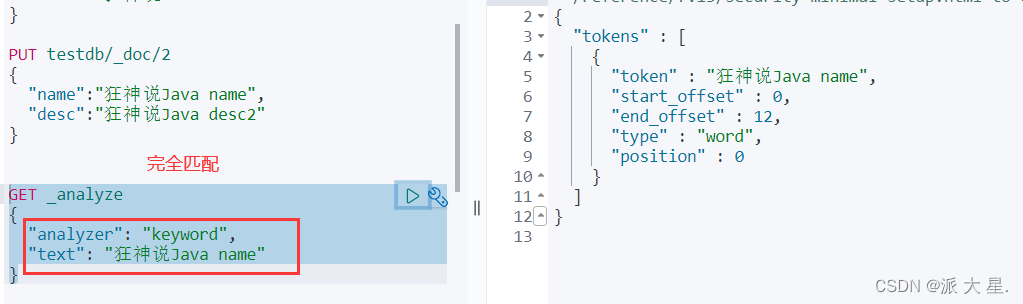
精确查询!
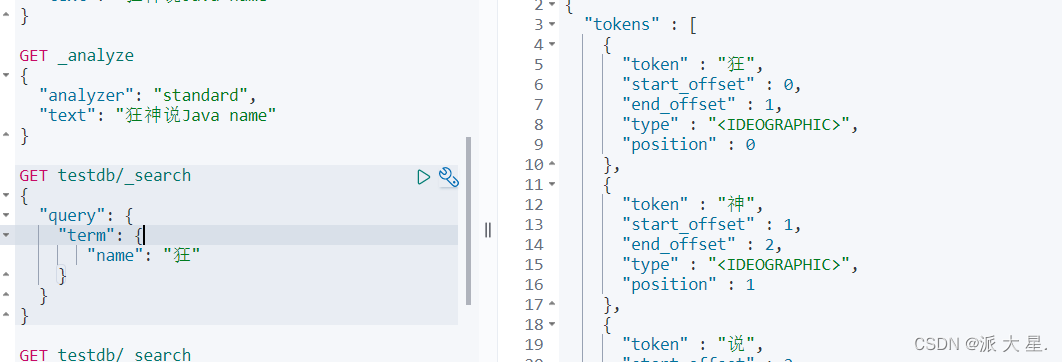
trem 查询是直接通过倒排索引指定的词条进行精确的查找的!
关于分词:
term,直接查询精确地
match,会使用分词器解析(先分析文档,通过分析的文档进行查询)
两个类型 text keyword
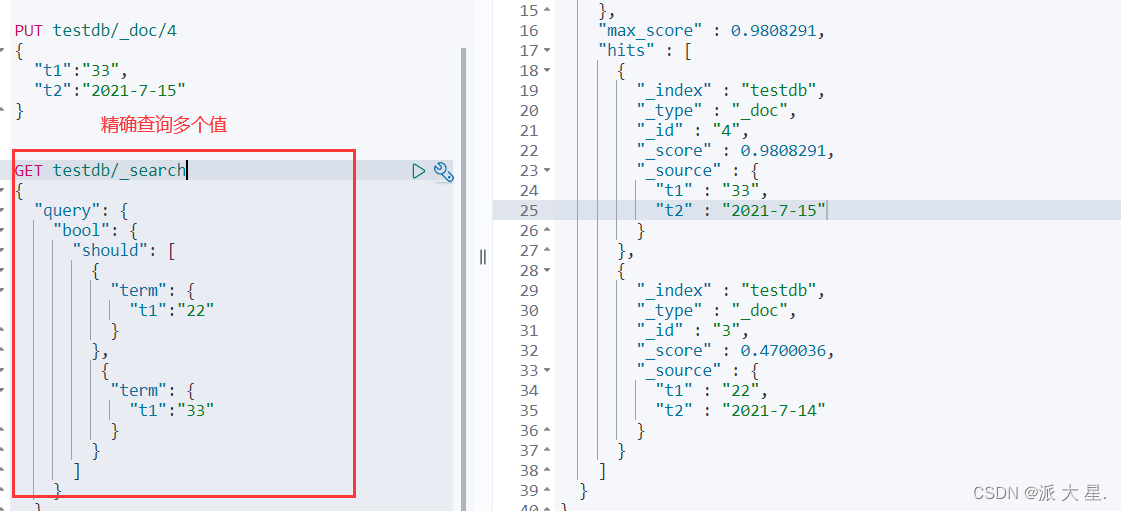
多个值精确匹配
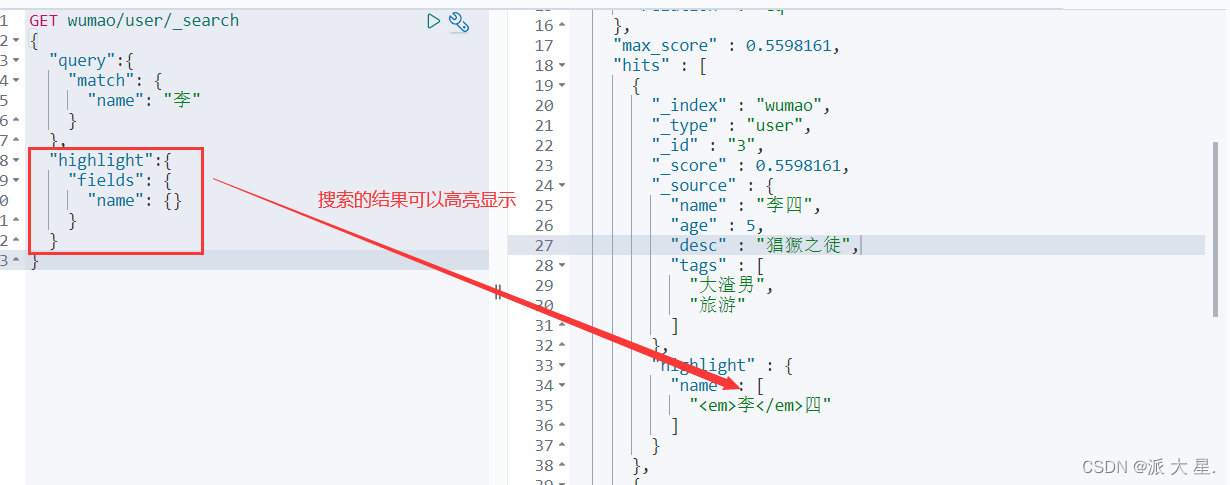
高亮查询!
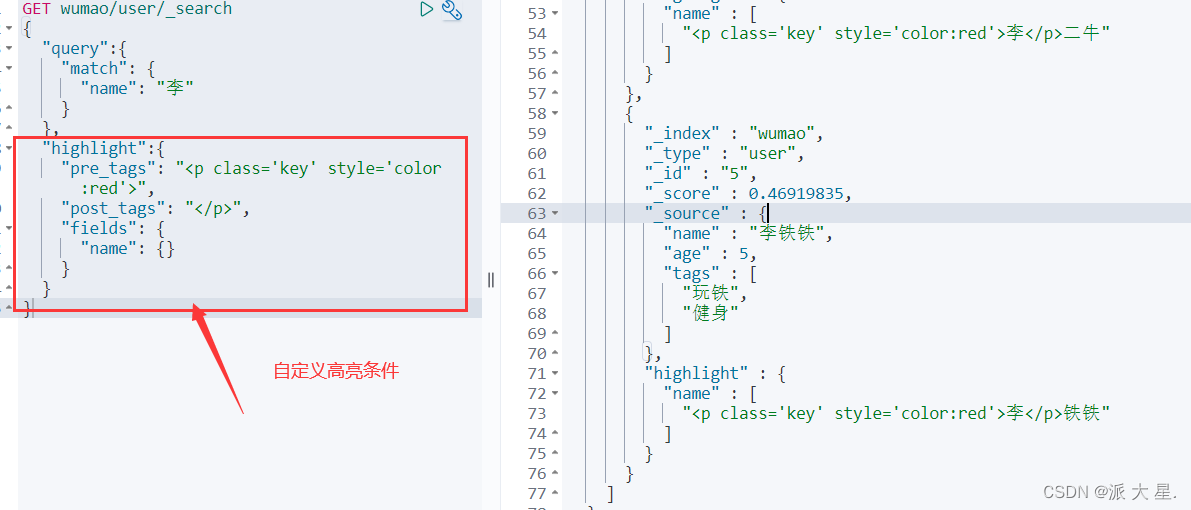

找官方文档!

https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.12/index.html
1、找到原生的依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.13.2</version>
</dependency>
2、找对象
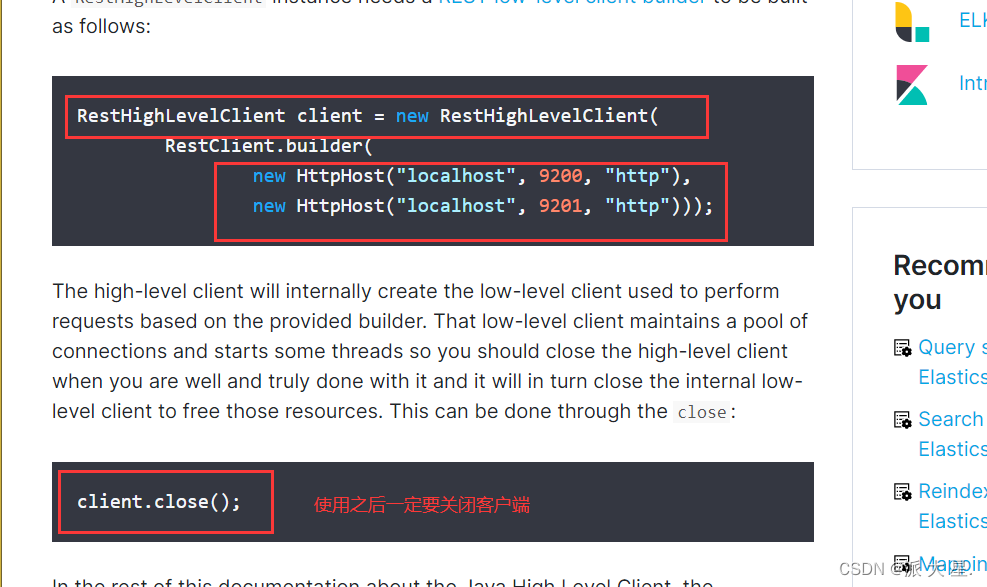
3、分析这个类中的方法
配置基本的项目
问题:创建项目默认的elasticsearch的默认版本是7.12.1,版本和本地不一致!
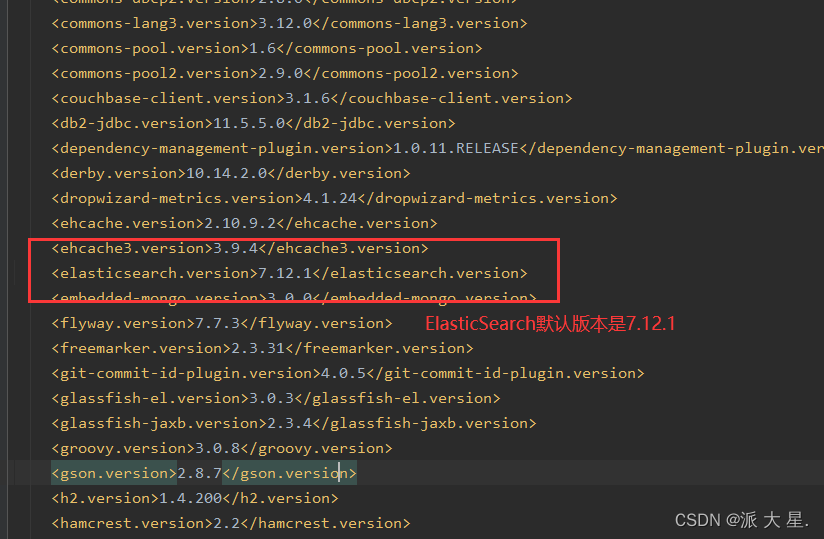
需要自己定义版本的依赖
分析源码
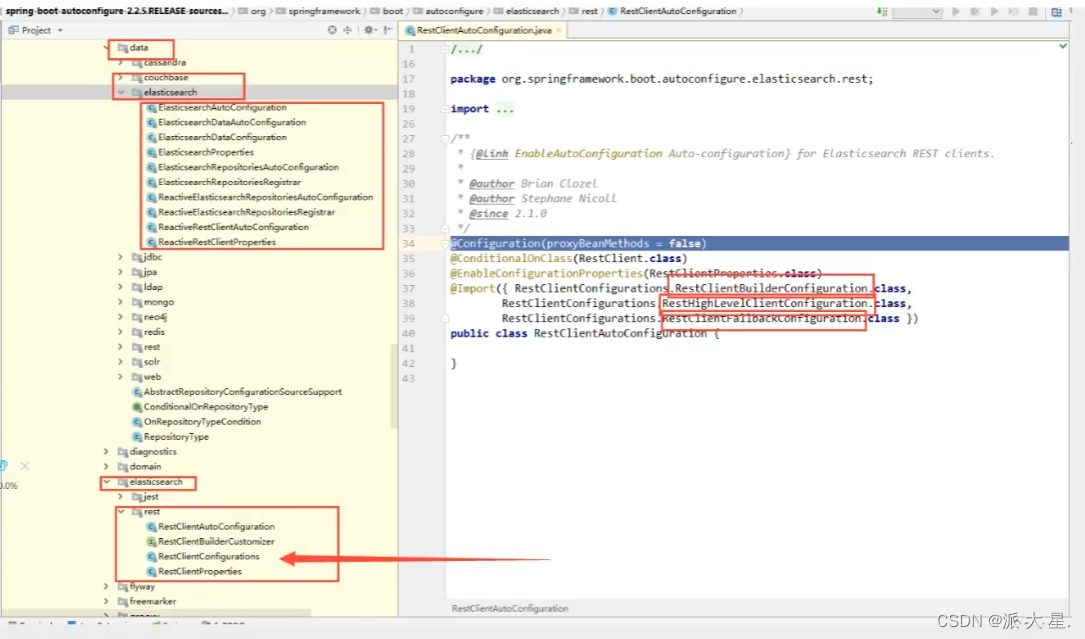
虽然导入了三个类,静态内部类,核心类只有一个
/**
* Elasticsearch rest client configurations.
*
* @author Stephane Nicoll
*/
class ElasticsearchRestClientConfigurations {
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(RestClientBuilder.class)
static class RestClientBuilderConfiguration {
@Bean
RestClientBuilderCustomizer defaultRestClientBuilderCustomizer(ElasticsearchRestClientProperties properties) {
return new DefaultRestClientBuilderCustomizer(properties);
}
//第一个bean RestClientBuilder
@Bean
RestClientBuilder elasticsearchRestClientBuilder(ElasticsearchRestClientProperties properties,
ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) {
HttpHost[] hosts = properties.getUris().stream().map(this::createHttpHost).toArray(HttpHost[]::new);
RestClientBuilder builder = RestClient.builder(hosts);
builder.setHttpClientConfigCallback((httpClientBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(httpClientBuilder));
return httpClientBuilder;
});
builder.setRequestConfigCallback((requestConfigBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(requestConfigBuilder));
return requestConfigBuilder;
});
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(builder));
return builder;
}
private HttpHost createHttpHost(String uri) {
try {
return createHttpHost(URI.create(uri));
}
catch (IllegalArgumentException ex) {
return HttpHost.create(uri);
}
}
private HttpHost createHttpHost(URI uri) {
if (!StringUtils.hasLength(uri.getUserInfo())) {
return HttpHost.create(uri.toString());
}
try {
return HttpHost.create(new URI(uri.getScheme(), null, uri.getHost(), uri.getPort(), uri.getPath(),
uri.getQuery(), uri.getFragment()).toString());
}
catch (URISyntaxException ex) {
throw new IllegalStateException(ex);
}
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(RestHighLevelClient.class)
static class RestHighLevelClientConfiguration {
//第二个bean RestHighLevelClient 高级客户端,后面项目会用到!
@Bean
RestHighLevelClient elasticsearchRestHighLevelClient(RestClientBuilder restClientBuilder) {
return new RestHighLevelClient(restClientBuilder);
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(Sniffer.class)
@ConditionalOnSingleCandidate(RestHighLevelClient.class)
static class RestClientSnifferConfiguration {
@Bean
@ConditionalOnMissingBean
Sniffer elasticsearchSniffer(RestHighLevelClient client, ElasticsearchRestClientProperties properties) {
SnifferBuilder builder = Sniffer.builder(client.getLowLevelClient());
PropertyMapper map = PropertyMapper.get().alwaysApplyingWhenNonNull();
map.from(properties.getSniffer().getInterval()).asInt(Duration::toMillis)
.to(builder::setSniffIntervalMillis);
map.from(properties.getSniffer().getDelayAfterFailure()).asInt(Duration::toMillis)
.to(builder::setSniffAfterFailureDelayMillis);
return builder.build();
}
}
static class DefaultRestClientBuilderCustomizer implements RestClientBuilderCustomizer {
private static final PropertyMapper map = PropertyMapper.get();
private final ElasticsearchRestClientProperties properties;
DefaultRestClientBuilderCustomizer(ElasticsearchRestClientProperties properties) {
this.properties = properties;
}
@Override
public void customize(RestClientBuilder builder) {
}
@Override
public void customize(HttpAsyncClientBuilder builder) {
builder.setDefaultCredentialsProvider(new PropertiesCredentialsProvider(this.properties));
}
@Override
public void customize(RequestConfig.Builder builder) {
map.from(this.properties::getConnectionTimeout).whenNonNull().asInt(Duration::toMillis)
.to(builder::setConnectTimeout);
map.from(this.properties::getReadTimeout).whenNonNull().asInt(Duration::toMillis)
.to(builder::setSocketTimeout);
}
}
private static class PropertiesCredentialsProvider extends BasicCredentialsProvider {
PropertiesCredentialsProvider(ElasticsearchRestClientProperties properties) {
if (StringUtils.hasText(properties.getUsername())) {
Credentials credentials = new UsernamePasswordCredentials(properties.getUsername(),
properties.getPassword());
setCredentials(AuthScope.ANY, credentials);
}
properties.getUris().stream().map(this::toUri).filter(this::hasUserInfo)
.forEach(this::addUserInfoCredentials);
}
private URI toUri(String uri) {
try {
return URI.create(uri);
}
catch (IllegalArgumentException ex) {
return null;
}
}
private boolean hasUserInfo(URI uri) {
return uri != null && StringUtils.hasLength(uri.getUserInfo());
}
private void addUserInfoCredentials(URI uri) {
AuthScope authScope = new AuthScope(uri.getHost(), uri.getPort());
Credentials credentials = createUserInfoCredentials(uri.getUserInfo());
setCredentials(authScope, credentials);
}
private Credentials createUserInfoCredentials(String userInfo) {
int delimiter = userInfo.indexOf(":");
if (delimiter == -1) {
return new UsernamePasswordCredentials(userInfo, null);
}
String username = userInfo.substring(0, delimiter);
String password = userInfo.substring(delimiter + 1);
return new UsernamePasswordCredentials(username, password);
}
}
}
具体的API测试
1、创建索引
2、判断文档是否存在
3、删除索引
4、创建文档
5、CRUD文档
@SpringBootTest
class WumaoEsApiApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//测试创建索引 在java中所有的请求都是用Request PUT wumao_index
@Test
public void testCreateIndex() throws IOException {
//1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("wumao_index");
//2、客户端执行请求 IndicesClient,请求后获取响应
CreateIndexResponse createIndexResponse = client.indices()
.create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
//测试获取索引
@Test
void testExistsIndex() throws IOException {
GetIndexRequest re = new GetIndexRequest("wumao_index");
boolean exists = client.indices().exists(re,RequestOptions.DEFAULT);
System.out.println(exists);
}
//测试删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("wumao_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete);
}
//添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("五毛",3);
//创建请求
IndexRequest request = new IndexRequest("wumao_index");
//设值一些规则 put /wumao_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//将我们的数据放入请求 json
String string = JSON.toJSONString(user);
request.source(string, XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse index = client.index(request, RequestOptions.DEFAULT);
System.out.println(index.toString());
System.out.println(index.status());//对应我们命令的返回状态
}
//获取文档
@Test
void testIsExists() throws IOException {
//获取文档,判断是否存在 get/index/doc/1
GetRequest index = new GetRequest("wumao_index", "1");
//不获取返回的_source的上下文了
index.fetchSourceContext(new FetchSourceContext(false));
index.storedFields("_none_");
boolean exists = client.exists(index, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获取文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest index = new GetRequest("wumao_index", "1");
GetResponse fields = client.get(index, RequestOptions.DEFAULT);
System.out.println(fields.getSourceAsString());
System.out.println(fields);
}
//更新文档记录
@Test
void testUpdateDocument() throws IOException {
UpdateRequest index = new UpdateRequest("wumao_index", "1");
//设置超时时间
index.timeout(TimeValue.timeValueSeconds(1));
User user = new User("法外狂徒张三", 12);
UpdateRequest doc = index.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse update = client.update(index, RequestOptions.DEFAULT);
System.out.println(update);
}
//删除文档记录
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("wumao_index", "1");
//设置请求过期时间
request.timeout("1s");
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
System.out.println(delete.status());
}
//特殊的,真的项目一般都是批量插入数据
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("wumao",3));
userList.add(new User("wumao1",23));
userList.add(new User("wumao2",21));
userList.add(new User("wumao3",12));
userList.add(new User("wumao4",13));
userList.add(new User("wumao5",23));
userList.add(new User("wumao6",33));
for (int i = 0; i < userList.size(); i++) {
bulkRequest.add(new IndexRequest("wumao_index")
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON)
);
}
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk.hasFailures());//是否失败!
}
//查询
// SearchRequest 搜索请求
// SearchSourceBuilder 条件构造
// HighlightBuilder 构建高亮
// TermQueryBuilder 精确查询
// MatchAllQueryBuilder 查询全部
// xxxxQueryBuilder 对应之前的那些命令
@Test
void testSearch() throws IOException {
SearchRequest request = new SearchRequest("wumao_index");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,我么可以使用QueryBuilders 工具类来实现
//QueryBuilders.termQuery 精确查询
//QueryBuilders.matchAllQuery(); 匹配所有
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
TermQueryBuilder termQuery = QueryBuilders.termQuery("name", "wumao");
//查询过期时间
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(sourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(search.getHits()));
for (SearchHit hit : search.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
//批量创建文档
@Test
void testBulkDocument() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
//设置过期时间
bulkRequest.timeout("60s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("qinfeng",3));
userList.add(new User("qinfeng1",3));
userList.add(new User("qinfeng2",3));
userList.add(new User("qinfeng3",3));
userList.add(new User("qinfeng4",3));
userList.add(new User("qinfeng5",3));
for (int i = 0; i < userList.size(); i++) {
bulkRequest.add(new IndexRequest("wumao_index")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulk.hasFailures());//判断是否失败
}
}

数据问题 数据库中获取,消息队列获取
爬取数据(获取请求返回的页面信息,筛选出我们所需要的)
<!--解析网页-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.2</version>
</dependency>
public List<Content> parseJD(String keyWords) throws Exception {
//获取请求 https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword="+keyWords;
//解析网页 (Jsoup返回的Document就是Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
//所有在js中使用的方法,在这里都可以使用
Element element = document.getElementById("J_goodsList");
ArrayList<Content> list = new ArrayList<>();
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
//这里的el就是每一个li标签
for (Element el : elements) {
//关于这种图片特别多的网站,都是延时加载的
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setTitle(title);
content.setPrice(price);
list.add(content);
}
return list;
}
前后端分离
搜索高亮
//解析数据放入到es中
public Boolean parseContent(String keyWords) throws Exception {
List<Content> contents = new HtmlParseUtil().parseJD(keyWords);
//把查询到的数据放入到es中
BulkRequest request = new BulkRequest();
request.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
System.out.println(JSON.toJSONString(contents.get(i)));
request.add(
new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}
//3.实现搜索高亮功能
public List<Map<String,Object>> searchHighlightPage(String keyword,int pageNO,int pageSize) throws IOException {
if (pageNO <=1){
pageNO =1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNO);
sourceBuilder.size(pageSize);
//精准匹配
QueryBuilders.termQuery("title",keyword);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false); //高亮显示一个title只显示一个高亮就可以
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits()) {
//解析高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果
//解析高亮字段,将原来的字段换为我们高亮的字段即可!
if (title!=null){
Text[] fragments = title.fragments();
String n_title="";
for (Text text : fragments) {
n_title += text;
}
sourceAsMap.put("title",n_title); //高亮字段替换掉原来的内容即可!
}
list.add(sourceAsMap);
}
return list;
}
本篇到这里就结束了!后续还会继续更新ElasticSearch调优、ElasticSearch集群以及面试题相关的内容,
感谢诸佬的点赞和支持。
如有不足之处,还希望诸佬指出不足之处,加以修正。
再见了各位小伙伴!

matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/