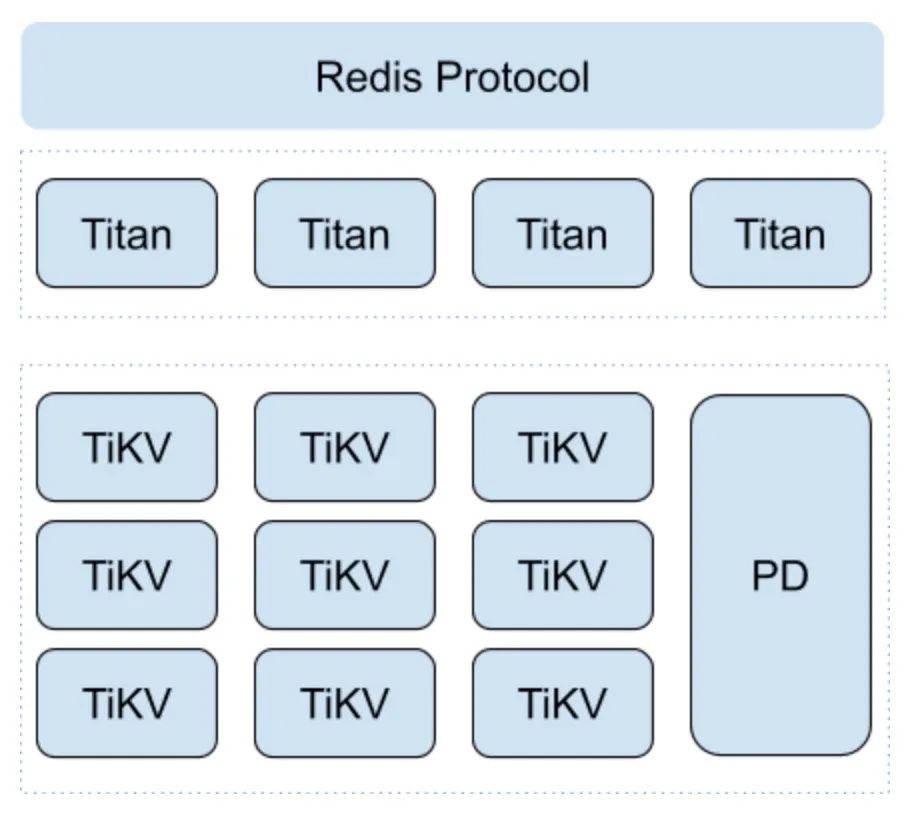
 站在巨人的肩膀上,titan 无需考滤数据 rebalance, 不关心数据存储副本同步,这也是为什么代码量如此少压测[3] 数据只有 2018 年的,性能一般,latency 也没区分 99 和 95 分位。如果基于最新版本的 tikv 集群测试效果可能更好
站在巨人的肩膀上,titan 无需考滤数据 rebalance, 不关心数据存储副本同步,这也是为什么代码量如此少压测[3] 数据只有 2018 年的,性能一般,latency 也没区分 99 和 95 分位。如果基于最新版本的 tikv 集群测试效果可能更好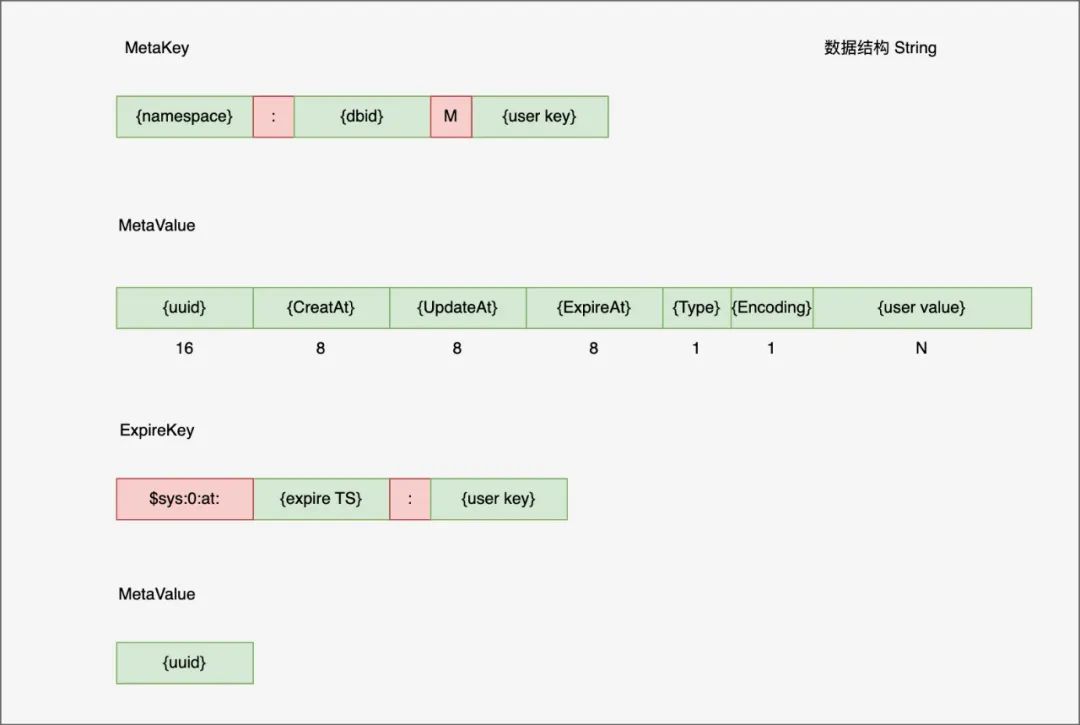 MetaKey 中 namespace 用于实现多租户隔离,但也只是逻辑上的,毕竟资源仍然是共用的,dbid 类似 redis db0, db1 ...ExpireKey 用于主动过期数据,后台任务定期扫。每个类型都有,后面省略不表MetaValue 前 42 字节为属性信息,后面才是真正的用户 value. 时间字段表示创建,更新,过期 timestamp, 被动过期时会检查 ExpireAt. uuid 用于唯一标识 key, titan 主动 GC 会用到Type 表示数据类型
MetaKey 中 namespace 用于实现多租户隔离,但也只是逻辑上的,毕竟资源仍然是共用的,dbid 类似 redis db0, db1 ...ExpireKey 用于主动过期数据,后台任务定期扫。每个类型都有,后面省略不表MetaValue 前 42 字节为属性信息,后面才是真正的用户 value. 时间字段表示创建,更新,过期 timestamp, 被动过期时会检查 ExpireAt. uuid 用于唯一标识 key, titan 主动 GC 会用到Type 表示数据类型const (
ObjectString = ObjectType(iota)
ObjectList
ObjectSet
ObjectZSet
ObjectHash
)const (
ObjectEncodingRaw = ObjectEncoding(iota)
ObjectEncodingInt
ObjectEncodingHT
ObjectEncodingZipmap
ObjectEncodingLinkedlist
ObjectEncodingZiplist
ObjectEncodingIntset
ObjectEncodingSkiplist
ObjectEncodingEmbstr
ObjectEncodingQuicklist
)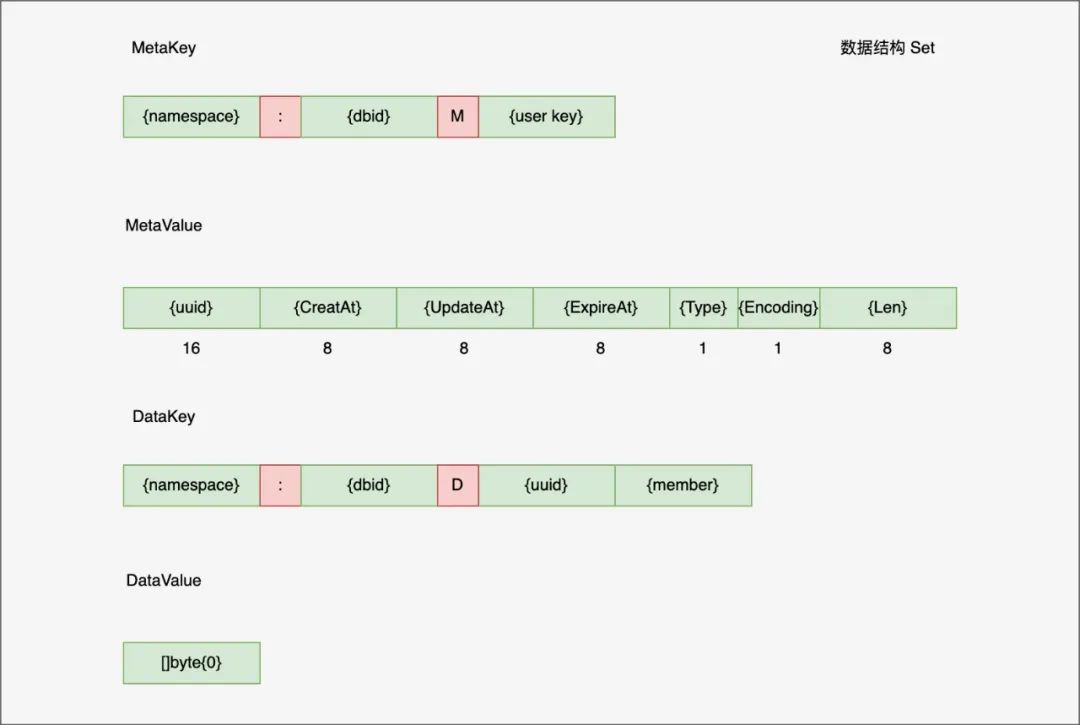 MetaKey 与 String 类型一样,MetaValue 一共 50 字节,前 42 字节一样,后 8 字节维护集合 Set 成员数量信息。也就是说后续的 SCARD 是 O(1),但同时删除增加都要修改 MetaValueDataKey 编码了 Set 唯一 uuid 与成员 member 信息,由于集合只需要成员 member, 所以 DatValue 是 []byte{0}
MetaKey 与 String 类型一样,MetaValue 一共 50 字节,前 42 字节一样,后 8 字节维护集合 Set 成员数量信息。也就是说后续的 SCARD 是 O(1),但同时删除增加都要修改 MetaValueDataKey 编码了 Set 唯一 uuid 与成员 member 信息,由于集合只需要成员 member, 所以 DatValue 是 []byte{0} 与集合一样,zset MetaKey/MetaValue 内容一样DataKey 内容基本一样,DataValue 是 score 值,同时也维护了 score -> member 映射的 ScoreKey, 用于空间换时间方便 zrangebyscore 查询
与集合一样,zset MetaKey/MetaValue 内容一样DataKey 内容基本一样,DataValue 是 score 值,同时也维护了 score -> member 映射的 ScoreKey, 用于空间换时间方便 zrangebyscore 查询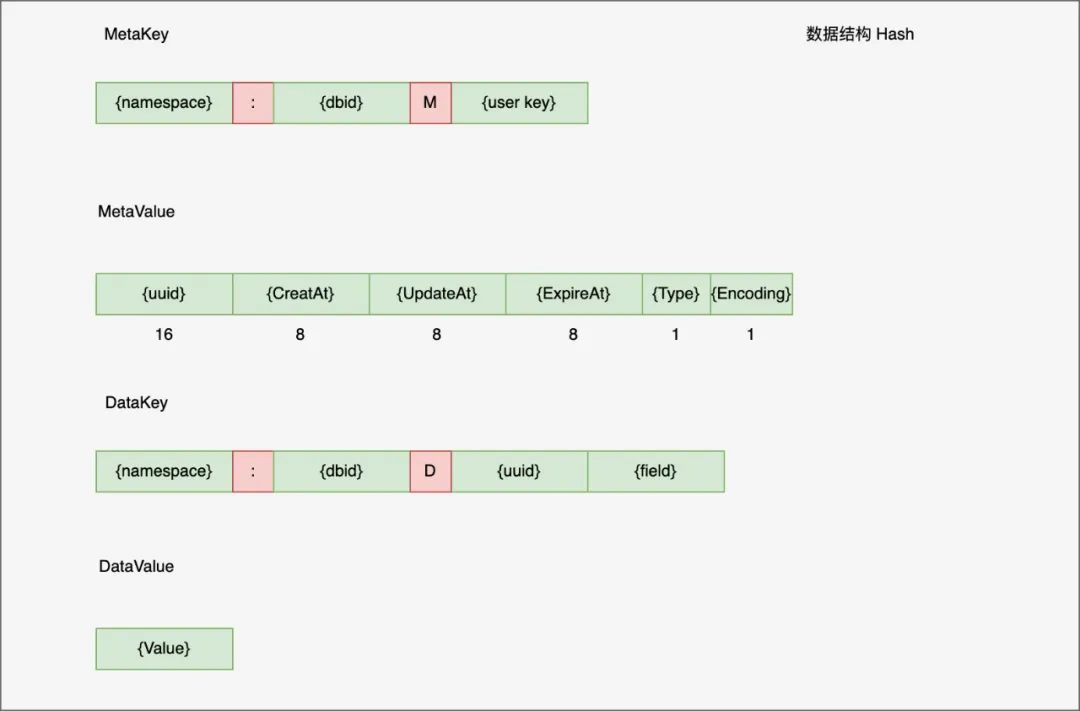 注意这里 hash 的 MetaValue 并没有维护成员 Len 信息,所以当 HLEN 时要遍历 range 整个 data key 空间,为什么这么做呢?titan 作者说 hash 写并发时会有大量的事务冲突,所以选择不维护。后来他们提出一个方案,对 MetaKey 拆分成多个 slot,尽可能减少冲突,同时还能提高 HELN 性能,不过后来也没实现
注意这里 hash 的 MetaValue 并没有维护成员 Len 信息,所以当 HLEN 时要遍历 range 整个 data key 空间,为什么这么做呢?titan 作者说 hash 写并发时会有大量的事务冲突,所以选择不维护。后来他们提出一个方案,对 MetaKey 拆分成多个 slot,尽可能减少冲突,同时还能提高 HELN 性能,不过后来也没实现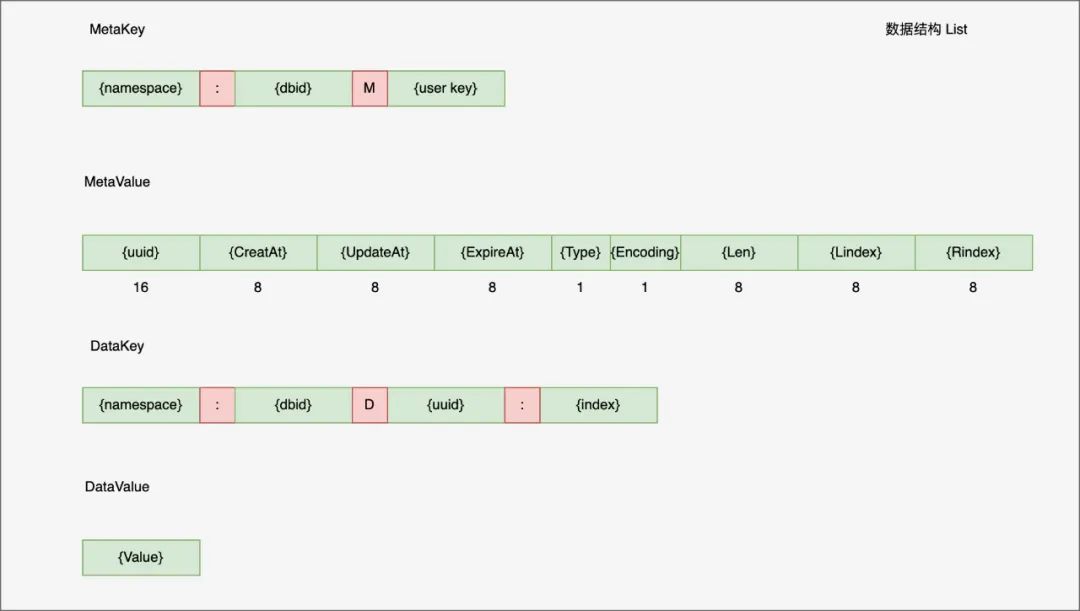 MetaValue 后 24 字节分别维护了 len, lindex 和 rindex, 其中 index 类型是 float64, 为什么不是 int64 类型呢?原因在于对于 Linsert 操作,如果插入 (2, 3) 之间,那么会失败,但是用 float64 大概率会成功,但是考滤 float64 也有精度问题,存在失败的概率
MetaValue 后 24 字节分别维护了 len, lindex 和 rindex, 其中 index 类型是 float64, 为什么不是 int64 类型呢?原因在于对于 Linsert 操作,如果插入 (2, 3) 之间,那么会失败,但是用 float64 大概率会成功,但是考滤 float64 也有精度问题,存在失败的概率// calculateIndex return the real index between left and right, return ErrPerc=
func calculateIndex(left, right float64) (float64, error) {
if f := (left + right) / 2; f != left && f != right {
return f, nil
}
return 0, ErrPrecision
}$sys{namespace}:{sysDatabaseID}:GC:{datakey}后台 doGC 调用 gcDeleteRange 慢慢删除,由于 DataKey 中存在 uuid, 基本不会重复,不影响用户重新创建相同 keyFlushdb 操作也非常重,理论上可以给所有 key 编码时带上 version, 这样可以快速 flush 快速回滚
 代码还有些书写瑕疵,想要用的同学,有能力二次开发的做好集群压测,故障注入,限流,千万不要急于上线,随时做好回滚的准备
代码还有些书写瑕疵,想要用的同学,有能力二次开发的做好集群压测,故障注入,限流,千万不要急于上线,随时做好回滚的准备 我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
有没有办法将RubyVM::InstructionSequence存储到文件中并稍后读取?我尝试了Marshal.dump但没有成功。我收到以下错误:`dump':no_dump_dataisdefinedforclassRubyVM::InstructionSequence(TypeError) 最佳答案 是的,有办法。首先,您需要使InstructionSequence的load方法可访问,默认情况下该方法是禁用的:require'fiddle'classRubyVM::InstructionSequence#RetrieveR
下面是我用来从应用程序中解析CSV的代码,但我想解析位于AmazonS3存储桶中的文件。当推送到Heroku时它也需要工作。namespace:csvimportdodesc"ImportCSVDatatoInventory."task:wiwt=>:environmentdorequire'csv'csv_file_path=Rails.root.join('public','wiwt.csv.txt')CSV.foreach(csv_file_path)do|row|p=Wiwt.create!({:user_id=>row[0],:date_worn=>row[1],:inven
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。