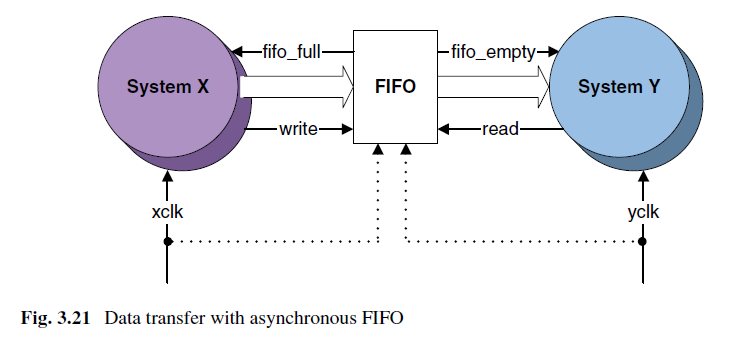
如上图,X通过xclk将数据写入FIFO,Y通过yclk将数据读出。注意这里写满标志信号在写时钟域,空信号在读时钟域。
对比握手信号,异步FIFO用于对性能要求较高的设计中,尤其是时钟延迟比系统资源更重要的环境中。
异步FIFO主要需要注意信号亚稳态的问题。
如果使用二进制计数,一次可能变换多位,这时就需要将多位数据同步到另一个时钟域,很容易造成错误。
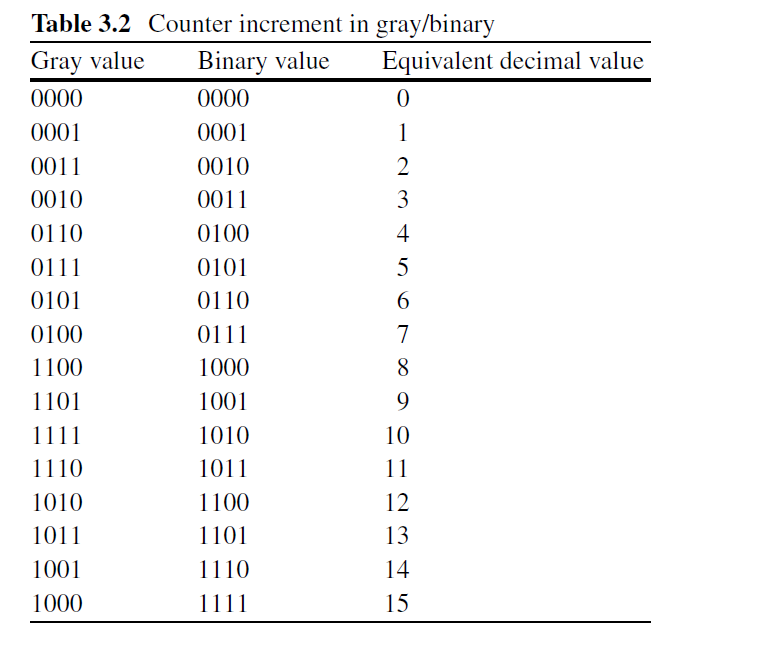
格雷码优势是在一个数变成另一个数时,只有一位出现变化。所以其在转换中最多只会一位错误,读取时要么读到旧值,要么读到新值,但是不会读到其他值。
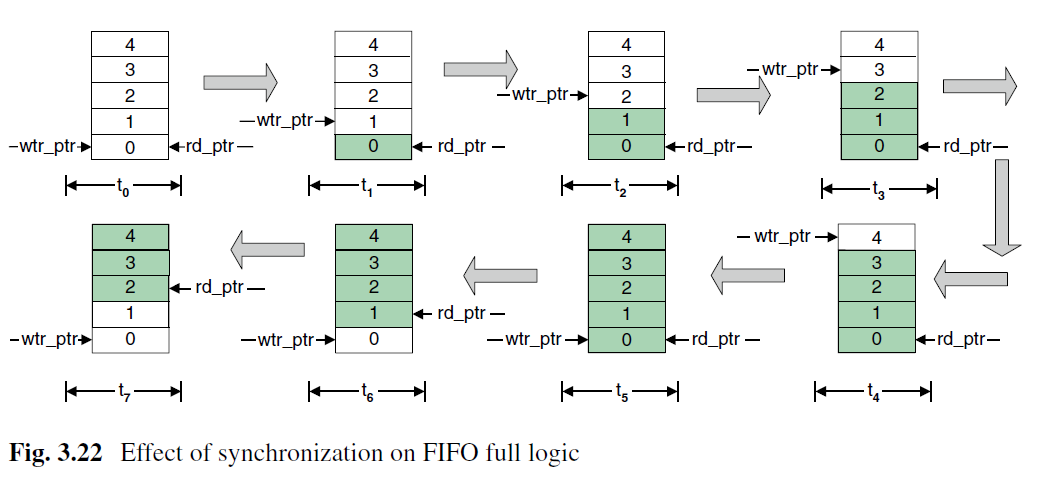
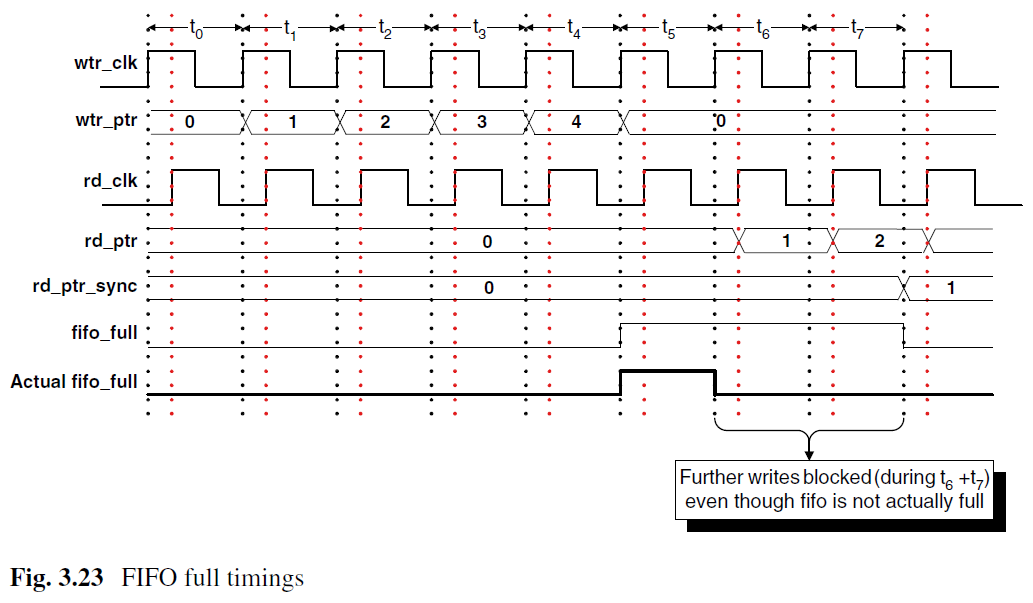
需要注意的是在t6、t7的时候,由于同步电路需要两个时钟周期,所以fifo_full会多拉高两个周期,这样阻止了两个周期的数据写入,但是对数据的准确性是无害的。
同样,空也会多两个周期阻止FIFO读访问。
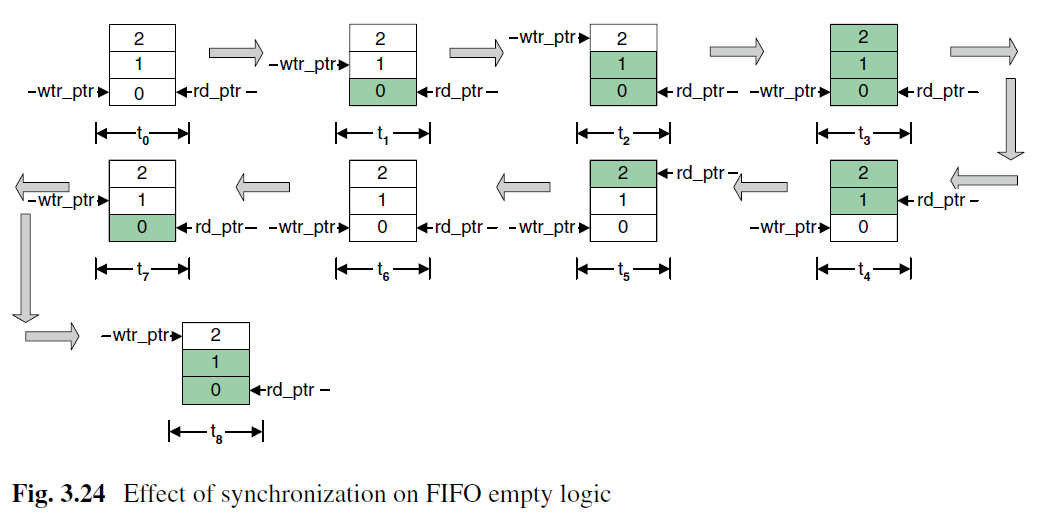
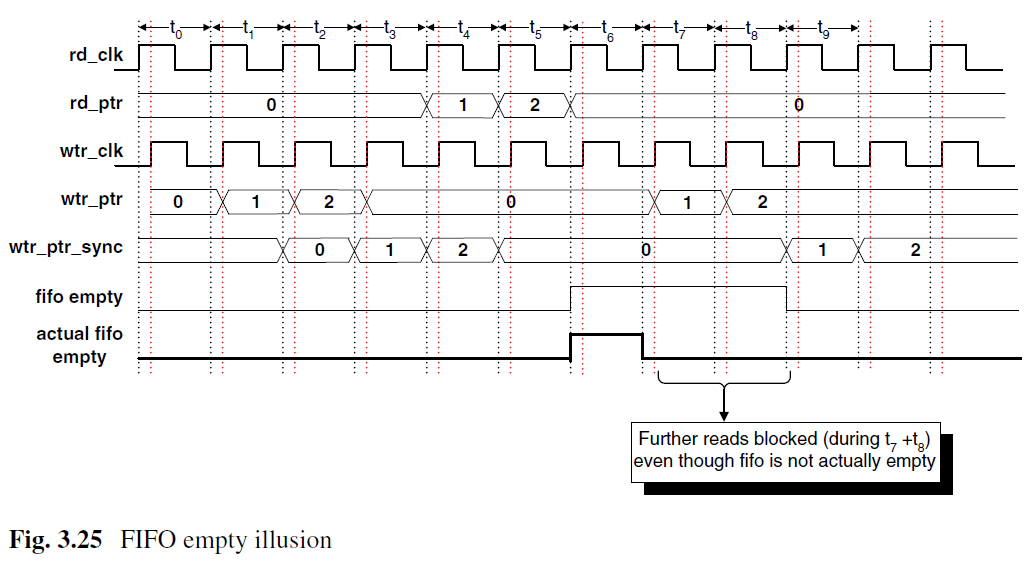
空判断是将写指针同步到读时钟域,在读空后写入FIFO,需要两个周期读时钟域才能得到写指针增加的信息,所以空信号也会多延两个周期。同样这里组织了对FIFO的读操作,也是无害的。
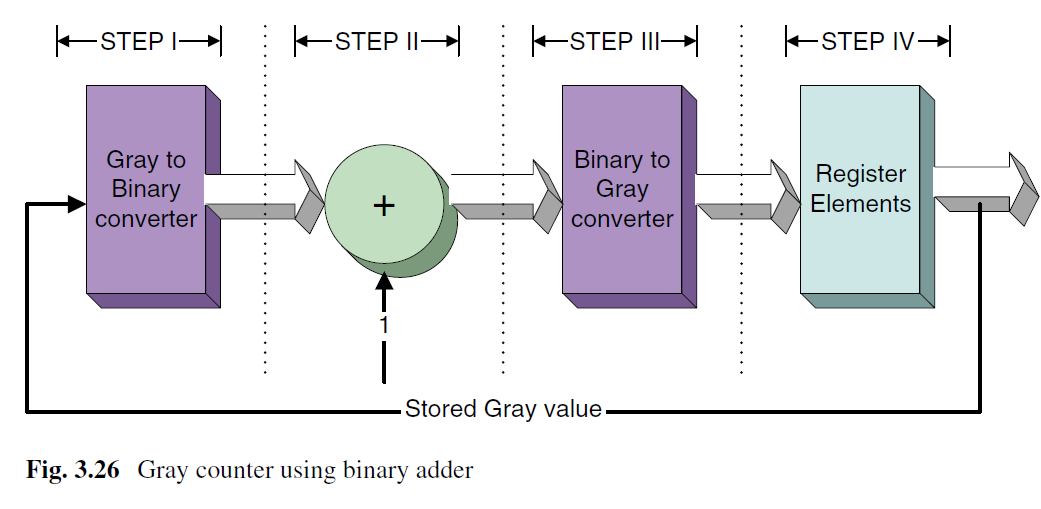
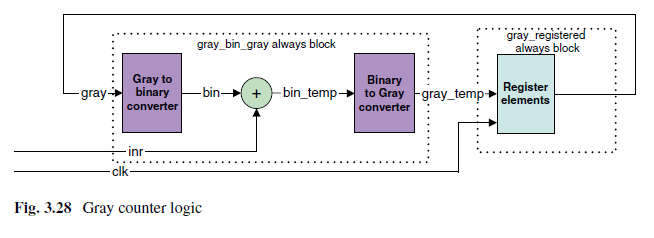
1、将格雷码转换成二进制码。
2、根据条件递增二进制值。
3、二进制转格雷码。
4、保存到寄存器。
转换公式:

所以可以将格雷码右移再按位异或得到二进制码
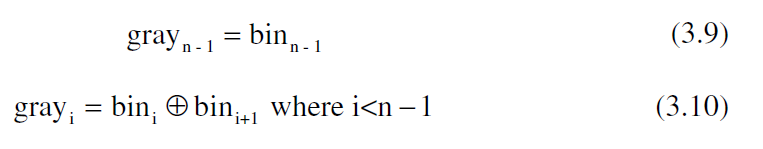
可以看出可以直接将二进制码右移后于自身异或操作,计算出格雷码。
将四个步骤结合起来,就可以实现一个格雷码计数器。
为了判断空满,还需要额外一位对两种情况进行区分。
最高位不同,其他位相同,FIFO满。
所有位相同,FIFO为空。
由于存在XOR链路,最大操作频率取决于格雷码计数器速度。
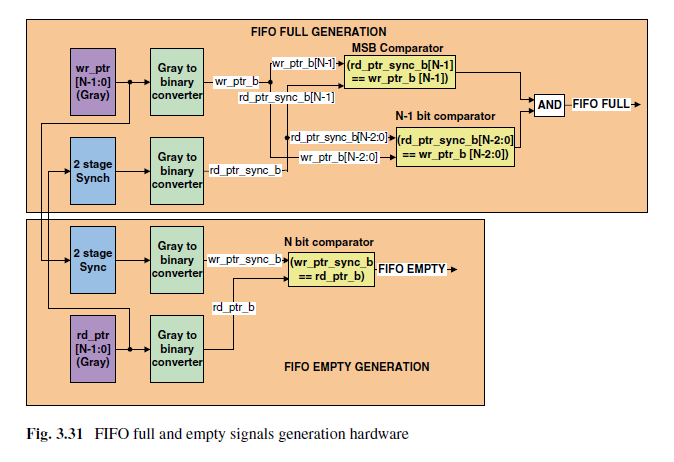
图里感觉又有点错误,满判断时,应该是最高位不同。
如图,一共用了四个转换器,如果直接使用格雷码实现空满操作就可以省掉这些转换器,但是这会增加复杂度并需要额外的逻辑。
该方法创建两个格雷码计数器,一个n位,另一个n-1位。通过n位格雷码的最高两位异或,来产生一个n-1位格雷码的MSB。其余n-2位与n位格雷码的n-2位保持一致。
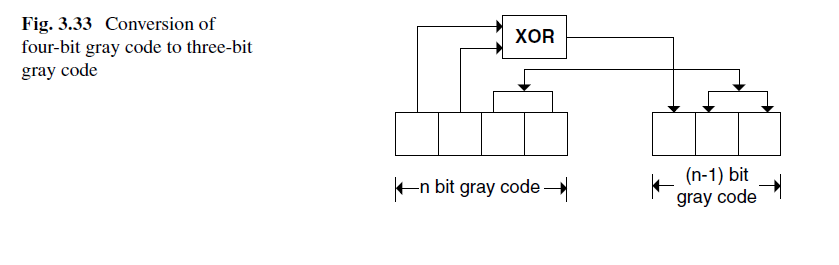
使用这两个格雷码计数器,就可以进行FIFO空满判断。
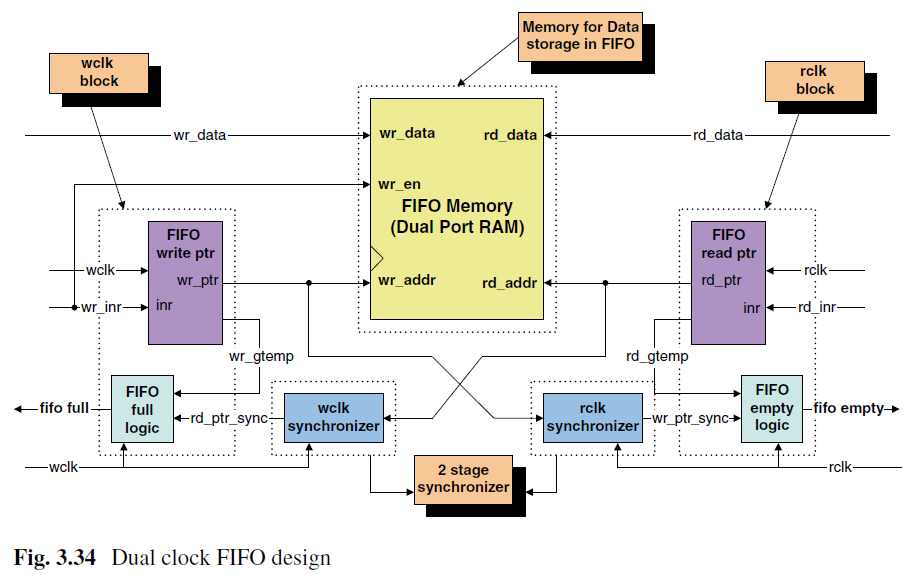
这里直接比较读写指针格雷码,相比先将格雷码转化成二进制码,直接对比格雷码可以节省4个转换器。
同步后的写指针wr_ptr_sync和rd_gtemp(下一个将要寄存进入rd_ptr的格雷码)。(这里没太搞懂为什么要用下一个rd_ptr的格雷码,是为了提前一个周期输出full和empty信号吗?)(调代码的时候发现确实应该使用下一个rd_ptr的格雷码,不然产生空满信号需要一个周期,空满信号被采样到用于控制FIFO读写又需要一个周期,会造成FIFO满了还向FIFO中写入的现象。)
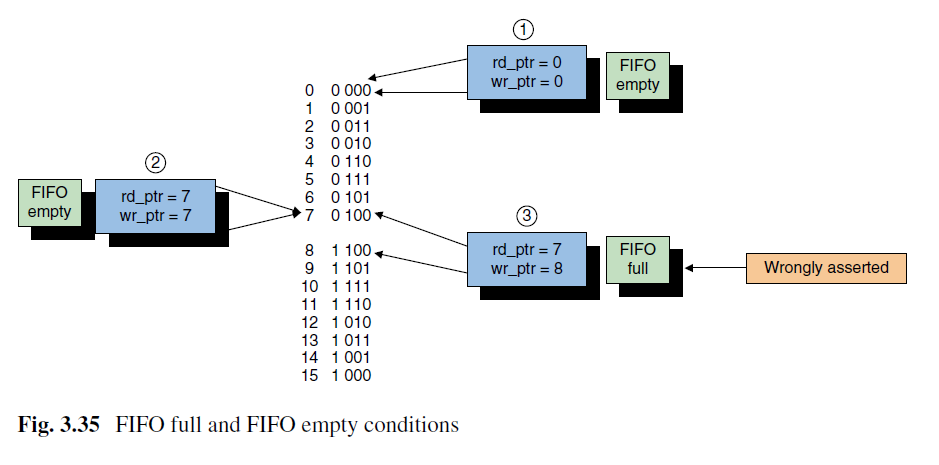
如图,rd_ptr=7,wr_ptr=8时,会出现FIFO满的错误声明。使用二元n位格雷码计数器可以轻松避免该情况。
以下三个条件为真时,满标志拉高。
1)同步后的读指针rd_ptr_sync的MSB应该与下一个写指针的格雷码wr_gtemp的MSB应该不同。
2)写时钟域两位MSB异或应与读指针一样。
3)剩下的LSB都应该一样。
(其实总结一下就是高两位要正好相反,剩下的低位应该完全相等)
异步FIFO代码
module Dual_Clock_FIFO#(
parameter WIDTH=16,
parameter DEPTH=8
)
(
input wclk,
input rclk,
input reset_n,
input [WIDTH-1:0]wr_data,
input wr_en,
input rd_en,
output reg[WIDTH-1:0]rd_data,
output fifo_full,
output fifo_empty
);
localparam RAM_SIZE=(1<<DEPTH);
reg [WIDTH-1:0]DPRAM[RAM_SIZE-1:0];
wire [DEPTH:0]wr_ptr,rd_ptr;
reg [DEPTH:0]wr_ptr_bin,rd_ptr_bin;
reg [DEPTH:0]wr_ptr_r,rd_ptr_r;
reg [DEPTH:0]wr_ptr_sync,rd_ptr_sync;
assign wr_ptr = (wr_ptr_bin >> 1) ^ wr_ptr_bin;
assign rd_ptr = (rd_ptr_bin >> 1) ^ rd_ptr_bin;
always @(posedge rclk or negedge reset_n) begin
if(~reset_n)
rd_data <= 'd0;
else begin
if(rd_en && ~fifo_empty)
rd_data <= DPRAM[rd_ptr_bin];
end
end
always @(posedge wclk) begin
if(wr_en && ~fifo_full)
DPRAM[wr_ptr_bin] <= wr_data;
end
always @(posedge rclk or negedge reset_n) //two stages synchronizer
begin: wr_ptr_sync_gen
if(~reset_n)begin
wr_ptr_r <= 'b0;
wr_ptr_sync <= 'b0;
end
else begin
wr_ptr_r <= wr_ptr;
wr_ptr_sync <= wr_ptr_r;
end
end
// always @ (posedge rclk or negedge reset_n)
// begin: fifo_empty_gen
// if (~reset_n)
// fifo_empty <= 1'b1;
// else
// fifo_empty <= (rd_ptr == wr_ptr_sync);
// end
assign fifo_empty = (rd_ptr == wr_ptr_sync);
always @(posedge wclk or negedge reset_n) //two stages synchronizer
begin: rd_ptr_sync_gen
if(~reset_n)begin
rd_ptr_r <= 'b0;
rd_ptr_sync <= 'b0;
end
else begin
rd_ptr_r <= rd_ptr;
rd_ptr_sync <= rd_ptr_r;
end
end
wire rd_2nd_msb = rd_ptr_sync [DEPTH] ^ rd_ptr_sync [DEPTH - 1];
wire wr_2nd_msb = wr_ptr [DEPTH] ^ wr_ptr [DEPTH-1];
// always @ (posedge wclk or negedge reset_n)
// begin: fifo_full_gen
// if (~reset_n)
// fifo_full <= 1'b0;
// else
// fifo_full <= ((wr_ptr [DEPTH] != rd_ptr_sync[DEPTH]) &&
// (rd_2nd_msb == wr_2nd_msb) &&
// (wr_ptr[DEPTH -2:0] == rd_ptr_sync[DEPTH-2:0]));
// end
assign fifo_full = ((wr_ptr [DEPTH] != rd_ptr_sync[DEPTH]) &&
(rd_2nd_msb == wr_2nd_msb) &&
(wr_ptr[DEPTH -2:0] == rd_ptr_sync[DEPTH-2:0]));
always @(posedge rclk or negedge reset_n)
begin:rd_ptr_gen
if(~reset_n)
rd_ptr_bin <= 'd0;
else if(rd_en && ~fifo_empty)
rd_ptr_bin <= rd_ptr_bin +1'b1;
end
always @(posedge wclk or negedge reset_n)
begin:wr_ptr_gen
if(~reset_n)
wr_ptr_bin <= 'd0;
else if(wr_en && ~fifo_full)
wr_ptr_bin <= wr_ptr_bin +1'b1;
end
endmoduletestbench
`timescale 1ns / 1ps
module tb_dual_clock_fifo();
reg wclk,rclk,rst_n,wr_en,rd_en;
wire full,empty;
reg [15:0]wr_data;
wire [15:0]rd_data;
initial begin
wclk = 0;
rclk = 0;
rst_n = 0;
wr_en = 0;
rd_en = 0;
wr_data = 0;
#100 rst_n = 1;
while(~full) begin
#20
wr_en <= 1'b1;
wr_data <= wr_data + 1'b1;
end
repeat(100)
begin
@(posedge wclk)begin
wr_en = {$random} %2;
end
@(posedge rclk)begin
rd_en = {$random} %2;
end
end
while(~empty) begin
#24
wr_en <= 1'b0;
rd_en <= 1'b1;
end
$finish;
end
always #10 wclk = ~wclk;
always #12 rclk = ~rclk;
Dual_Clock_FIFO my_fifo(
.wclk(wclk),
.rclk(rclk),
.reset_n(rst_n),
.wr_data(wr_data),
.wr_en(wr_en),
.rd_en(rd_en),
.rd_data(rd_data),
.fifo_full(full),
.fifo_empty(empty)
);
endmodule波形
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。