
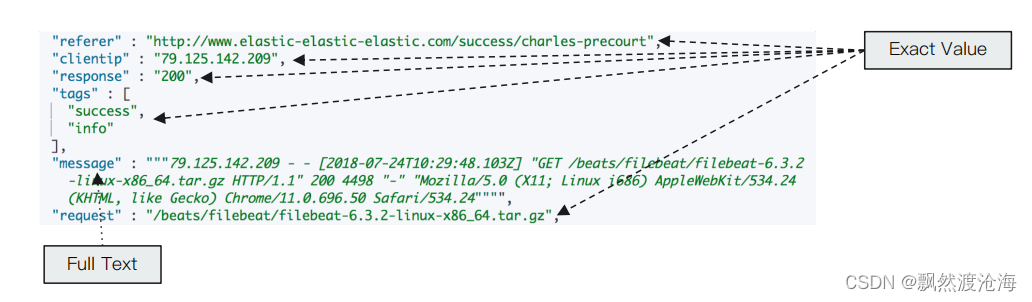
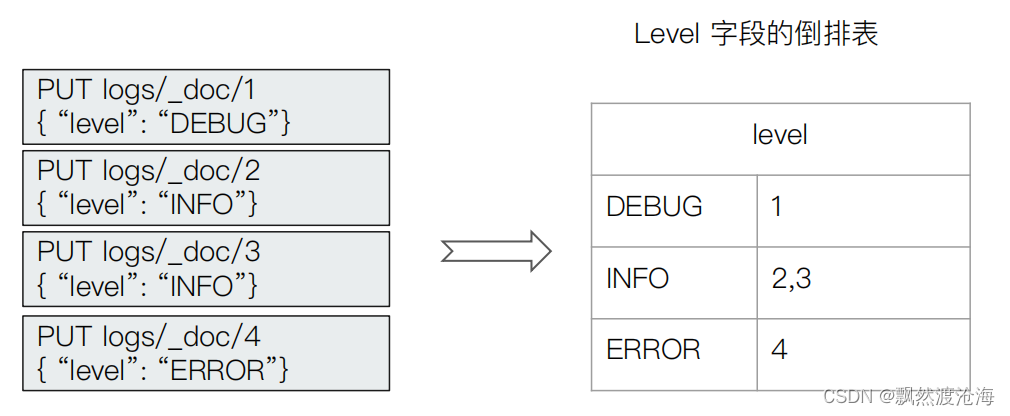
将原始的文本按照一 定的规则,切分为词(term or token)
Elasticsearch 内置的Tokenizers
可以用Java开发插件,实现自己的Tokenizer

PUT logs/_doc/1
{"level":"DEBUG"}
GET /logs/_mapping
POST _analyze
{
"tokenizer":"keyword",
"char_filter":["html_strip"],
"text": "<b>hello world</b>"
}
POST _analyze
{
"tokenizer":"path_hierarchy",
"text":"/user/ymruan/a/b/c/d/e"
}
#使用char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ "- => _"]
}
],
"text": "123-456, I-test! test-990 650-555-1234"
}
//char filter 替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "mapping",
"mappings" : [ ":) => happy", ":( => sad"]
}
],
"text": ["I am felling :)", "Feeling :( today"]
}
// white space and snowball
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
// whitespace与stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop","snowball"],
"text": ["The rain in Spain falls mainly on the plain."]
}
//remove 加入lowercase后,The被当成 stopword删除
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase","stop","snowball"],
"text": ["The gilrs in China are playing this game!"]
}
//正则表达式
GET _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type" : "pattern_replace",
"pattern" : "http://(.*)",
"replacement" : "$1"
}
],
"text" : "http://www.elastic.co"
}

根据Elasticsearch识别的数据类型,结合字段名称,来动态设定字段类型
+ 所有的字符串类型都设定成Keyword, 或者关闭keyword字段
+ is开头的字段都设置成boolean
+ long_ 开头的都设置成long类型


#数字字符串被映射成text,日期字符串被映射成日期
PUT ttemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET ttemplate/_mapping
#Create a default template
PUT _template/template_default
{
"index_patterns": ["*"],
"order" : 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas":1
}
}
PUT /_template/template_test
{
"index_patterns" : ["test*"],
"order" : 1,
"settings" : {
"number_of_shards": 1,
"number_of_replicas" : 2
},
"mappings" : {
"date_detection": false,
"numeric_detection": true
}
}
#查看template信息
GET /_template/template_default
GET /_template/temp*
#写入新的数据,index以test开头
PUT testtemplate/_doc/1
{
"someNumber":"1",
"someDate":"2019/01/01"
}
GET testtemplate/_mapping
get testtemplate/_settings
PUT testmy
{
"settings":{
"number_of_replicas":5
}
}
put testmy/_doc/1
{
"key":"value"
}
get testmy/_settings
DELETE testmy
DELETE /_template/template_default
DELETE /_template/template_test
#Dynaminc Mapping 根据类型和字段名
DELETE my_index
PUT my_index/_doc/1
{
"firstName":"Ruan",
"isVIP":"true"
}
GET my_index/_mapping
DELETE my_index
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match":"is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
DELETE my_index
#结合路径
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
PUT my_index/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
GET my_index/_search?q=full_name:John
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c