Java提供了NIO操作的API,但真正处理NIO流,经常会出现如下代码:
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (channel.read(buffer)!=-1){
//复位,转化为读模式
buffer.flip();
while (buffer.hasRemaining()){
System.out.println("收到客户端"+channel.socket().getPort()+"的信息:"+ StandardCharsets.UTF_8.decode(buffer).toString());
}
//清空缓存区,转化为写模式
buffer.clear();
}可以看出读写经常会出现flip()和clear()等方法,这究极有什么作用?为什么要这么写?
所有IO都有缓冲区,需要将客户端数据或文件数据读取到内存缓冲区,Java程序才能读取到内存里的客户端或文件内容数据。写入也是如此,Java需要先写入到缓冲区,内核才能把缓冲区数据传输给客户端或文件。
首先看看Buffer的属性:
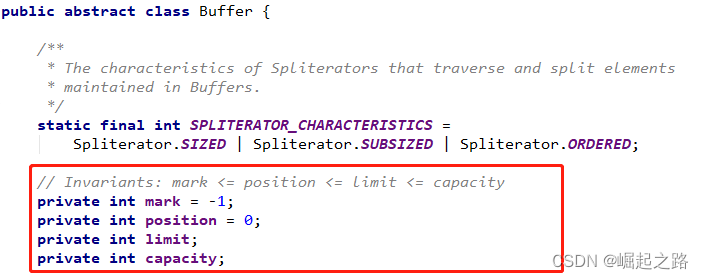
容量(Capacity):缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能被改变。
上界(Limit):缓冲区的能被写入或读取的最大个数(索引值为该值-1),比如limit为5,capacity为10,则put(5,6)会报错,因为5的代表第6个值,而limit最大只有5,即索引0~4内可写。limit限制了buffer内可写的范围。而capacity限制了buffer的范围。
位置(Position):下一个要被读或写的元素的索引。位置会自动由相应的put( )、get()、flip()、clear()函数更新。
标记(Mark):一个备忘位置。调用 mark( )来设定 mark = postion。调用 reset( )设定 position = mark。mark默认值为-1(JDK8下)。
这些属性在通过实例化或get()和put()等函数操作Buffer时会更新,无论上面怎么变,会向源码里解释的那样:mark <= position <= limit <= capacity。
具体测试代码如下:
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(100);
System.out.println(buffer);
byte[] content = "123".getBytes(Charset.forName("UTF-8"));
System.out.println("添加的byte数组长度为:"+content.length);
buffer.put(content);
System.out.println(buffer);
// buffer.flip();
// System.out.println(buffer);
byte data = buffer.get();
System.out.println((char)data);
// System.out.println("buffer的数据为:"+StandardCharsets.UTF_8.decode(buffer).toString());
System.out.println(buffer);
}打印结果如下:
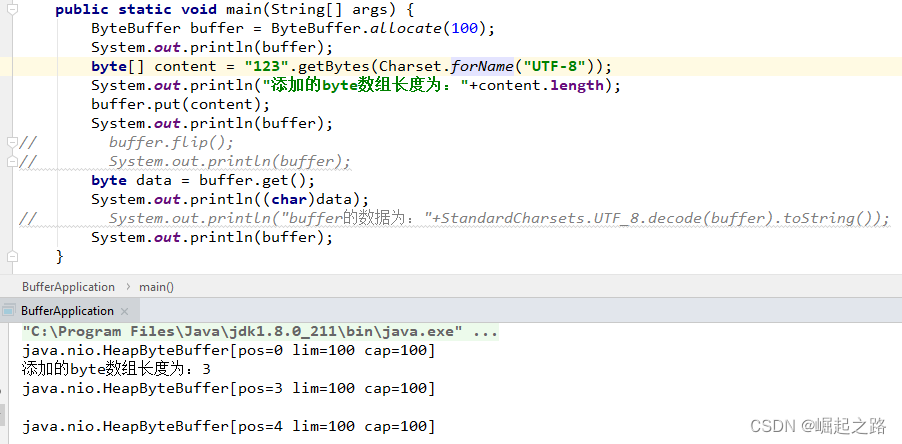
可以看到:
put():可以将内容添加到buffer中,并将更新position=position+内容长度。
get():是直接读取索引为position的元素,并更新position=position+1。
因此,直接put()添加完内容后用get()读取内容,是读取不到数据的!需要put()完,再调用flip()才能用get()读取到数据,具体如下:
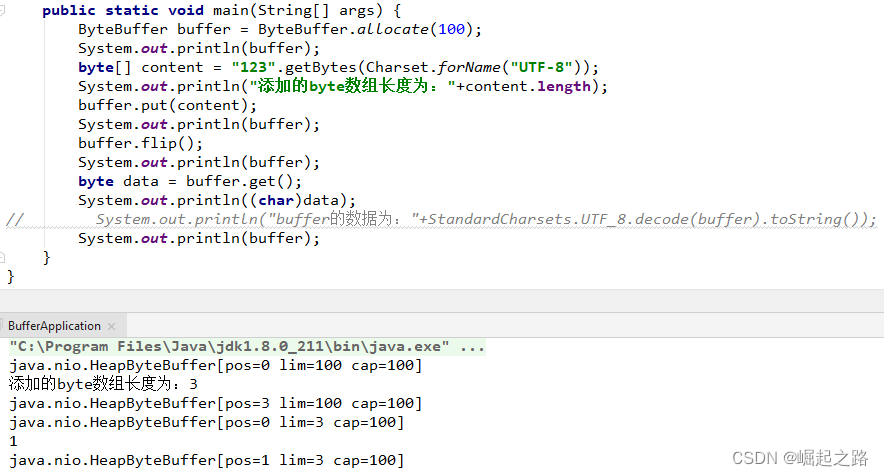
可以看到:
flip():将limit=position,position=0,mark=-1。这样由于limit=position,buffer是不能添加数据的,因此限制了buffer的写入,而position=0,可以让get()从第一个元素读取。mark=-1,也是给标记重置,虽然mark没啥作用,一般的读写我们也用不上这个mark。
所以,读取buffer数据前一定要调用flip(),否则读取不到数据!
那么读取数据怎么判断position是否超过了limit,可以用remaining()和hasRemaining()判断,具体如下:
所以读取数据需要用 flip()限制buffer写入并将position和mark复位,然后调用hasRemaining()对position的位置和limit进行判断,看是否还有数据读取。最后调用get()读取buffer的内容。当然,用其它API读取buffer可以可以的。
写入数据上面将了,直接调用put()即可。但问题来了,读取数据需要调用flip(),position会置为0,因此若buffer有历史数据的话,调用flip()再读,会造成历史数据重复读取!所以,Java的API给我们提供了clear()和mark()、reset()方法。
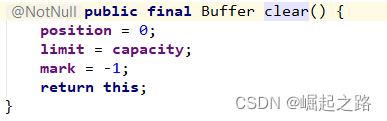
clear()方法会将limit改成capacity,即允许可写,且是整个buffer都可写。将position=0,即后写入的数据将历史数据覆盖。所以调用clear()方法前一定要读完所有数据。
所以一般的buffer读写操作是:
先clear(),再写入()。确保buffer的数据都是新写入的内容,避免使用flip()后读取会读取到历史数据。
当然,有时我们需要保留历史数据,然后再写入,不调用flip()直接读取新写入的数据,这也是可以的,这就需要用到mark了。具体方法如下:
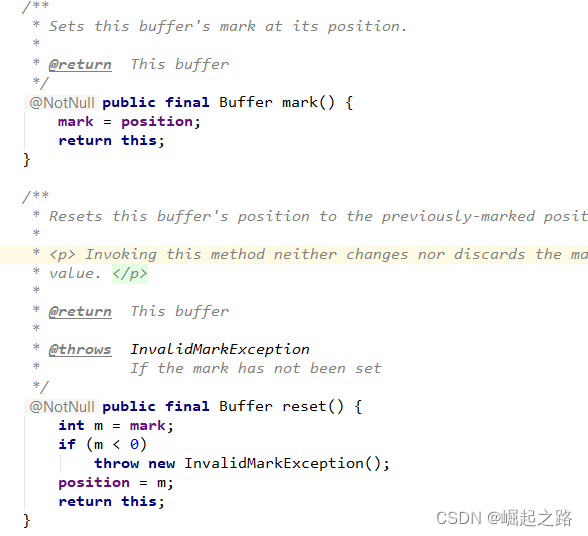
缓冲区内有历史数据,先mark(),让mark=position,然后直接put写入新内容,写完后,调用reset(),使postion回到新内容的起点,再直接调用get()读取数据。这样就只会读新内容,也无需清除历史内容了。
buffer若不需要追加读,则只需要 get()读取前调用flip()方法从头读取,put()方法前调用clear()重置position从头写入覆盖历史数据。
buffer需要追加读,则put()前需要调用mark()记录下写入的起始点,写完后直接调用reset()将position调整为新内容的起始点mark。接着再调用get()方法进行读取。
视频教程:https://www.bilibili.com/video/BV1WJ411778C/?spm_id_from=333.999.0.0&vd_source=4a4c35da6aef7094d5990c213c39aa09使用素材(推荐使用GitZipforgithub下载):https://github.com/zheyuanzhou/Youtube-Unity-Tutorial/tree/master/EP45_Health%20Bar/Sprites效果如下图所示:首先在场景中创建一个新的Canvas,并命名为HeathBar,并创建三个Image作为前者的子物体,分别命名为
请帮帮我。我尝试安装gemnio4r,但此日志有错误:ERROR:Errorinstallingnio4r:ERROR:Failedtobuildgemnativeextension.currentdirectory:/var/lib/gems/2.3.0/gems/nio4r-1.2.1/ext/nio4r/usr/bin/ruby2.3-r./siteconf20161020-13985-1c6zxok.rbextconf.rbmkmf.rbcan'tfindheaderfilesforrubyat/usr/lib/ruby/include/ruby.hextconffailed,
准确的错误是:Anerroroccurredwhileinstallingnio4r(1.2.1),andbundlercannotcontinue.Makesurethat'geminstallnio4r-v'1.2.1''succeedsbeforebundling.这是一条轨迹:Fetchinggemmetadatafromhttps://rubygems.org/Fetchingversionmetadatafromhttps://rubygems.org/Fetchingdependencymetadatafromhttps://rubygems.org/Usingrake1
我有一个RaspberryPiTFT7"触摸屏显示器,我想创建一个简单的应用程序来显示和输出系统数据(即CPU使用率、温度等)。我注意到目前常见的实现方法是使用pygame库输出到显示器连接到的帧缓冲区/dev/fb1。我想执行相同的操作,但使用Ruby,因为我更熟悉这门语言。有人可以为我指明正确的方向,让我知道如何开始吗?我查看了rubygame和gosu库,它们似乎能够做我想做的事情,即绘制屏幕,但我找不到任何关于如何将输出定向到的信息帧缓冲区本身。 最佳答案 rubycorelib有一个IO您应该能够使用该类将输出定向
这是日志:http://pastebin.com/CAgur9xdInstallingnio4r1.2.1withnativeextensionsGem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension.C:/RailsInstaller/Ruby2.2.0/bin/ruby.exe-r./siteconf20160720-8272-c88sgk.rbextconf.rb--with-cflags=-std=c99checkingforunistd.h...***extconf.rbfailed***Couldnotcreat
如何从缓冲区运行一段ruby代码,而不实际将缓冲区保存在文件中?一个场景是a)切换到暂存缓冲区b)M-xruby模式c)输入ruby代码d)“编译”缓冲区并在另一个缓冲区中打印结果。我不想将缓冲区内容保存在文件中,然后“编译”该文件2011年1月9日更新哪些是ruby-mode和inf-ruby的最新版本,我可以从哪里获得它们?我用的是ubuntunatty版的ruby模式和elpa版的emacs23.2的inf-ruby。在干净的emacs配置上,以下配置(见下文)失败:can'tconvertnilintoStringfrom(irb):1:in`eval'from(irb
我目前正在使用以下项目进行项目:rvm1.26.11ruby2.2.1p85我尝试运行bundleinstall但不断收到以下错误:Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension.并且,以下:Anerroroccurredwhileinstallingnio4r(1.0.0),andBundlercannotcontinue.Makesurethat`geminstallnio4r-v'1.0.0'`succeedsbeforebundling.当我尝试运行geminstallnio4r-v'1.0.0'时:Buil
IO缓冲在Ruby中是如何工作的?使用IO和File类时,数据刷新到底层流的频率如何?这与操作系统缓冲相比如何?在自信地读回数据进行处理之前,需要做什么来保证给定数据已写入磁盘? 最佳答案 RubyIO文档并未100%清楚地说明这种缓冲的工作原理,但您可以从文档中提取以下内容:RubyIO有自己的内部缓冲区除此之外,底层操作系统可能会或可能不会进一步缓冲数据。相关方法看:IO.flush:刷新IO。我还查看了Ruby源代码,对IO.flush的调用也调用了底层操作系统fflush().这应该足以让文件缓存,但不能保证物理数据到磁盘。
我正在处理需要与C++tcp/udp套接字通信的javascript/nodejs应用程序。好像我从旧的C++客户端那里得到了一个utf16缓冲区。我现在没有找到将其转换为可读字符串的解决方案,而另一个方向似乎也是同样的问题。这两个方向有没有简单的方法?亲切的问候 最佳答案 如果您有一个UTF-16编码的缓冲区,您可以像这样将它转换为UTF-8字符串:letstring=buffer.toString('utf16le');要从流中读取这些,最简单的方法是在最后使用转换为字符串:letchunks=[];stream.on('dat
假设我正在Node.js中构造一个可变长度的字符串或字节序列。buf.write的文档说:https://nodejs.org/api/buffer.html#buffer_buf_write_string_offset_length_encodingWritesstringtobufatoffsetaccordingtothecharacterencodinginencoding.Thelengthparameteristhenumberofbytestowrite.Ifbufdidnotcontainenoughspacetofittheentirestring,onlyapart