近段时间来,你可能在不少地方都看到了非常多这样的好看的画。
比如这样的赛博朋克风
prompt: Cyberpunk, 8k resolution, castle, the rose sea, dream

水墨画风格
prompt: a watercolor ink painting of a fallen angel with a broken halo wielding a jagged broken blade standing on top of a skyscraper in the style of anti - art trending on artstation deviantart pinterest detailed realistic hd 8 k high resolution

油画
prompt: portrait of bob barker playing twister with scarlett johansson, an oil painting by ross tran and thomas kincade

水彩画
prompt: a girl with lavender hair and black skirt, fairy tale style background, a beautiful half body illustration, top lighting, perfect shadow, soft painting, reduce saturation, leaning towards watercolor, art by hidari and krenz cushart and wenjun lin and akihiko yoshida

并且在各种平台我们也是随处可见,以下分别为小红书、闲鱼、twitter
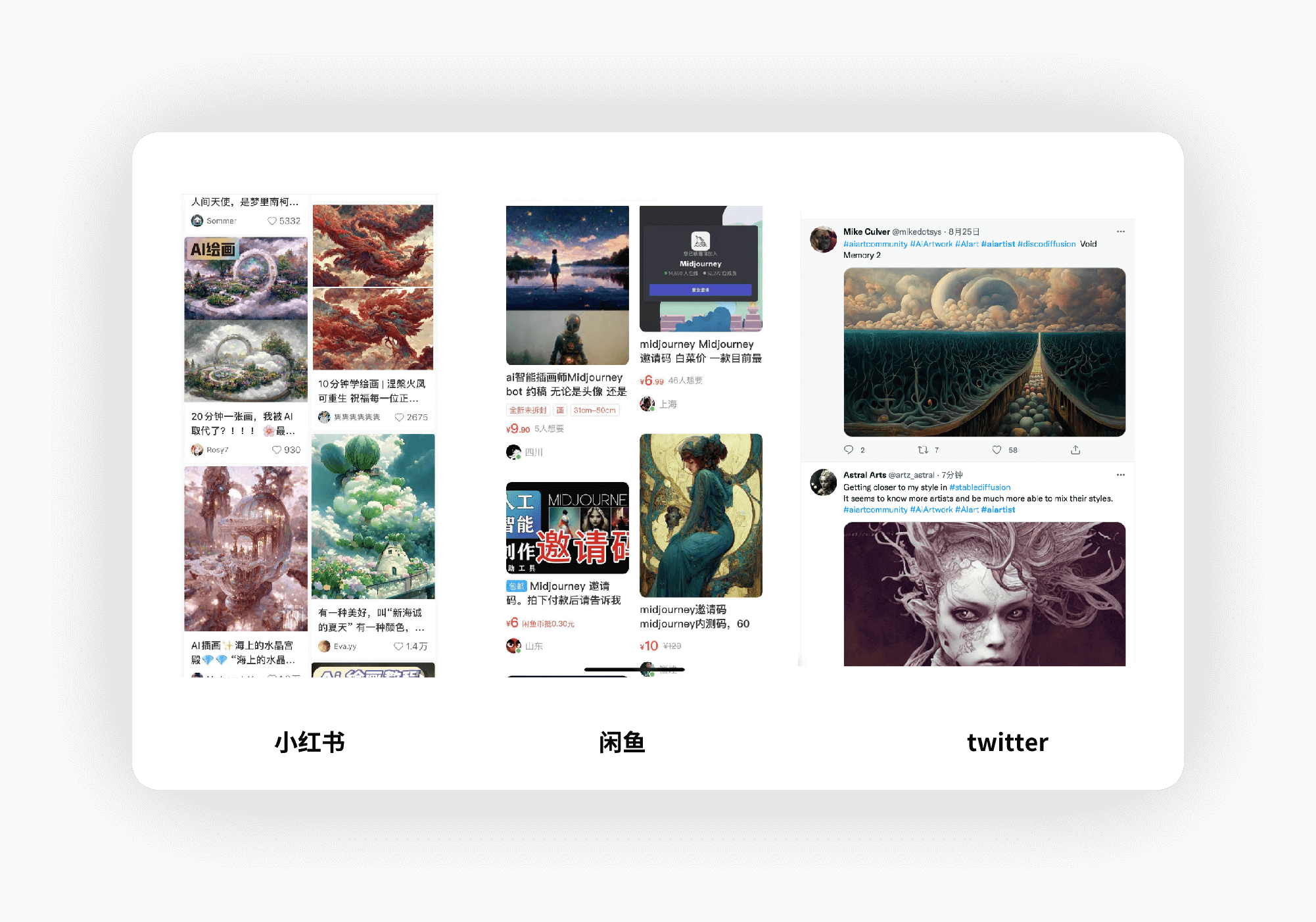
这些图都很像是艺术家画的一样,但是他们却不是出自真正的的艺术家之手,而是 AI艺术家。AI 就像 16 年打败李世石进军 围棋行业一样,开始进军艺术届了。
我们来看看 AI绘画 发展的比较关键的时间线
Disco Diffusion 有一个弊端,就是速度非常慢,动辄 半个小时起步。
Midjourney 对 Disco Diffusion 进行了改进,平均1分钟能出图。
目前还没有按到 DALL·E 2 的体验资格。
一经推出就受到广大网友的喜爱,操作简单,出图快,平均10-20秒。
Stable-Diffusion 免费、生成速度又快,每一次生成的效果图就像是开盲盒一样,需要不断尝试打磨,所以大家都疯狂似的开始玩耍,甚至连特斯拉的前人工智能和自动驾驶视觉总监 Andrej Karpathy 都沉迷于此。
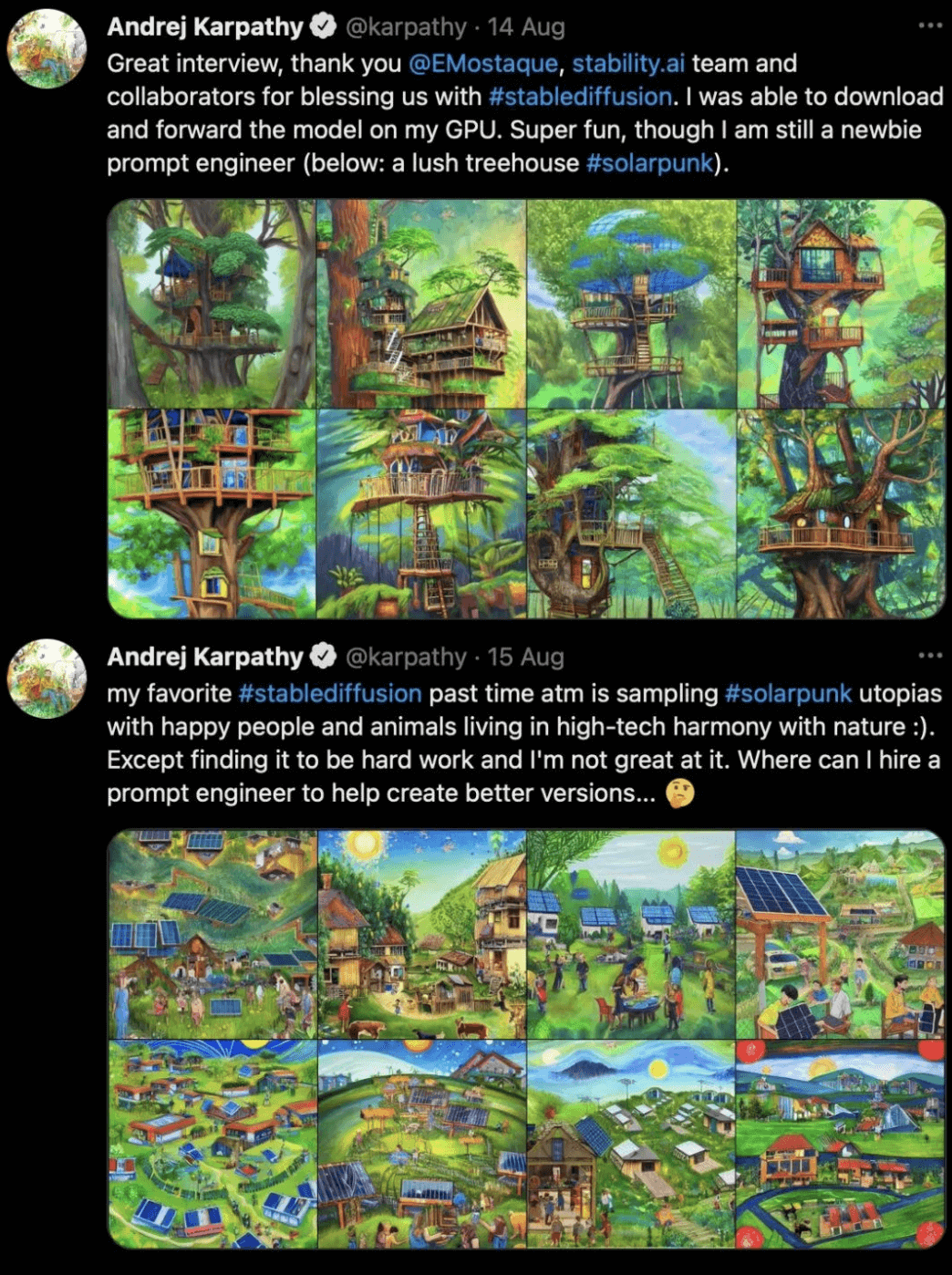
而 stability.ai 却是一个年轻的英国团队

他们的宗旨为 “****AI by the people, for the people” ,****中文翻译的大意为,人们创造AI,并且AI服务于人,除了 stable-diffusion 他们还参与了众多的 AI 项目

今天主要介绍的就是 stable-diffusion 的玩法,官方利用 stable-diffusion 搭建的平台主要是 dreamstudio.ai 听这个名字就感觉很牛,梦幻编辑器(自己取得,勿喷,因为生成的图都很梦幻),你也可以自己使用 colab 来本地运行,下面就来详解介绍这两种方式
打开 https://beta.dreamstudio.ai/ 选择一种注册方式,我这里使用了 Google 账号登录(后面也有相关的教程来教你如何来注册一个Google账号),你也可以选择自己的方式。
注册好后,就可以进入到这个界面。
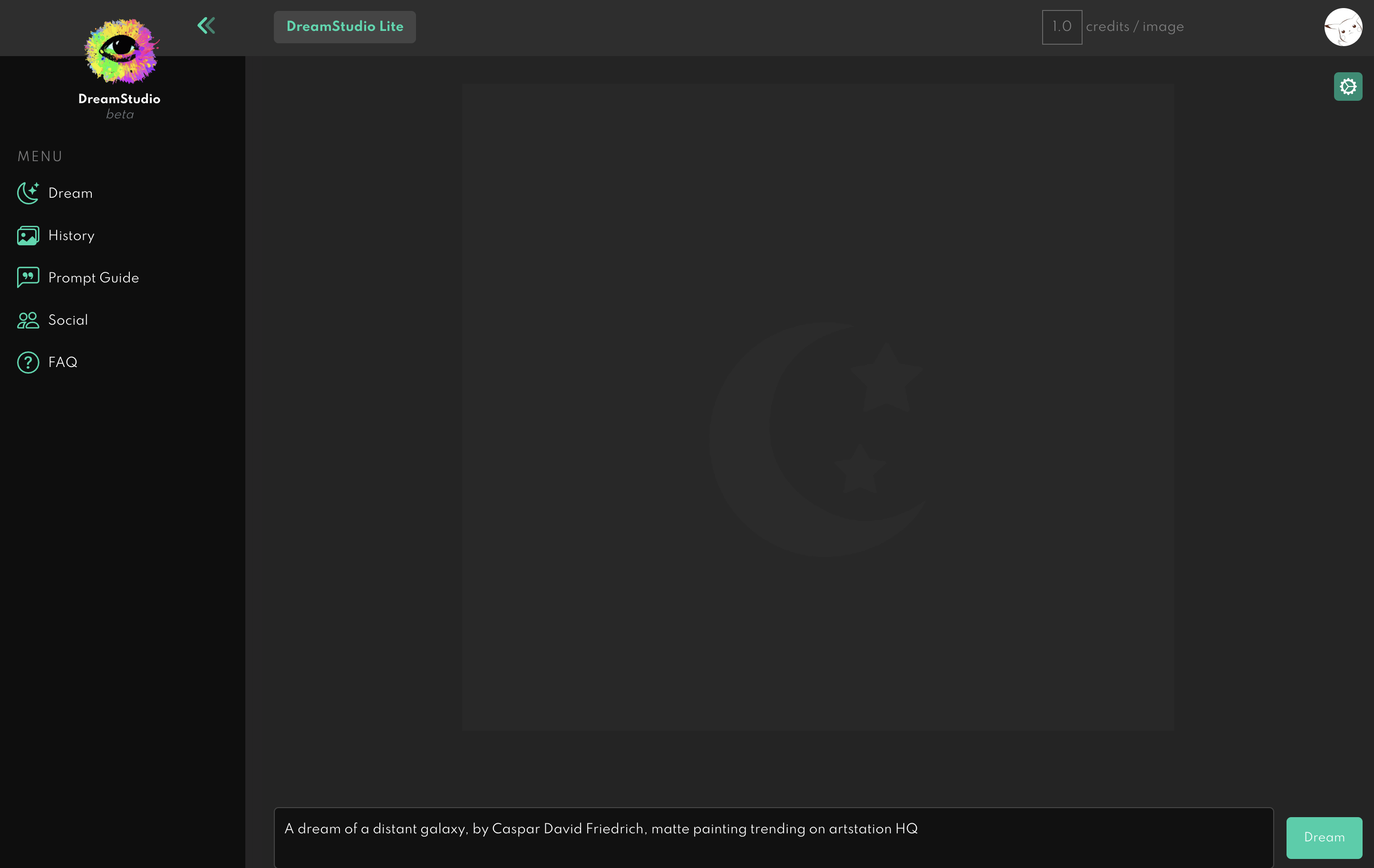
你可以直接在下方输入名词,也可以在打开右侧的设置按钮,里面会更详细的配置。
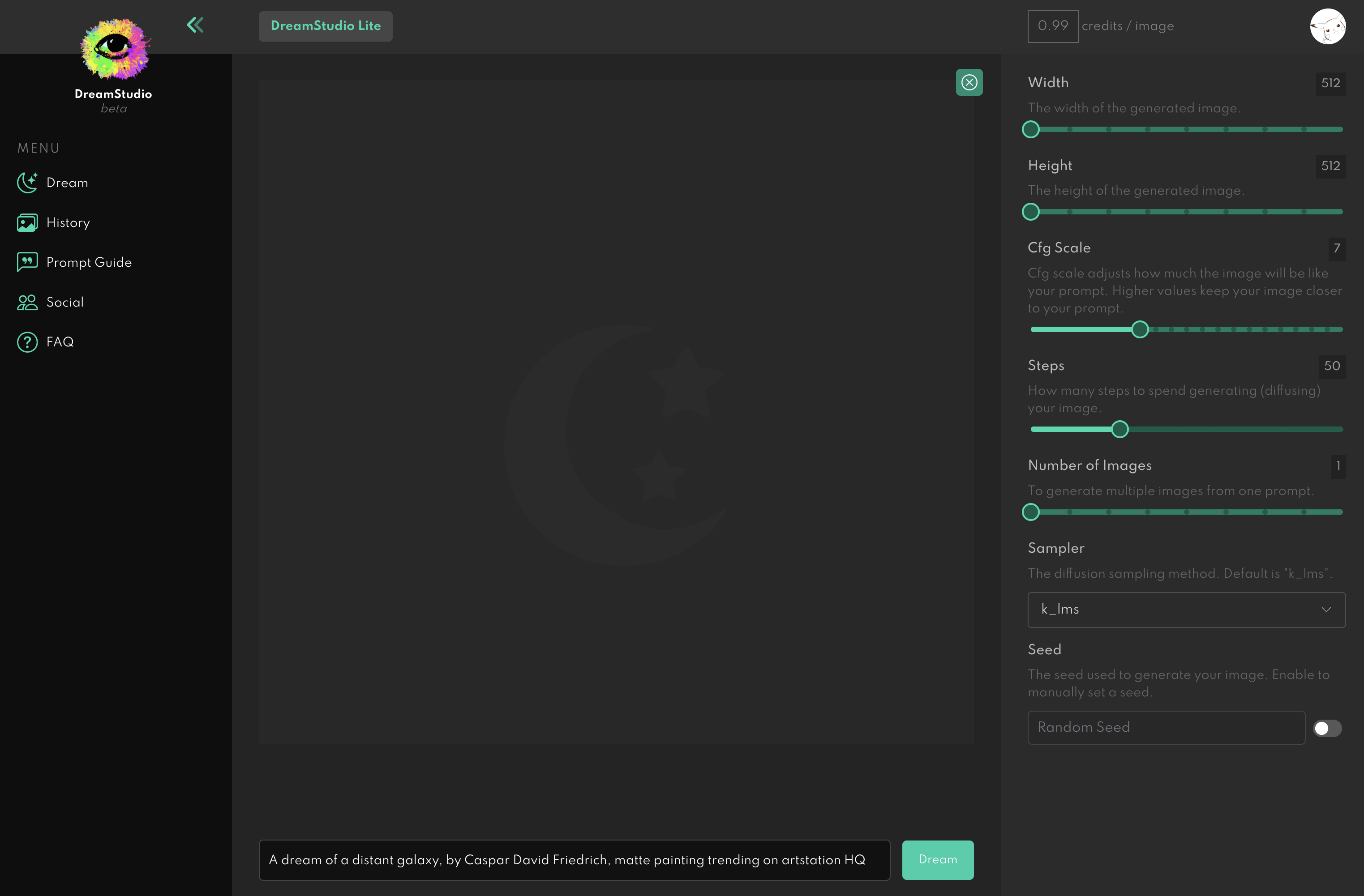
输入好关键词后,直接点 Dream 按钮,等待10秒左右就可以生成图片。
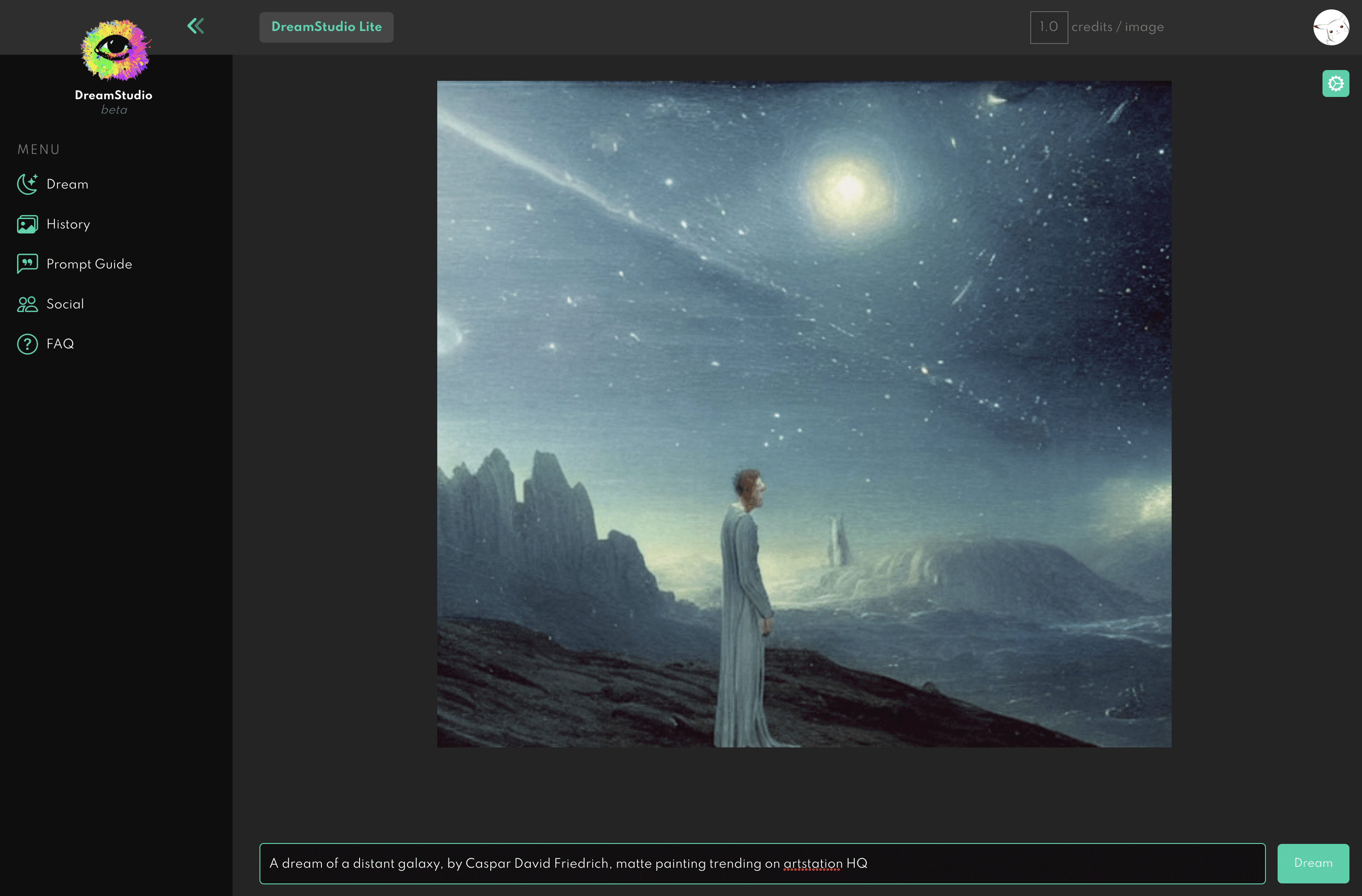
当然这样的生成方式非常的方便,但是是有次数限制的。
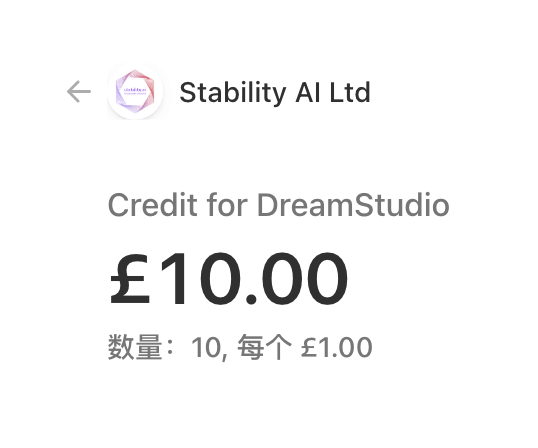
可以看到右上角的点数,默认你注册账号会有200点点数,每次生成一张默认设置的图片就会消耗一个点数,如果你要生成更多的方式就需要付费了, 10 英镑 1000 点数。
如果你想获得更高精细程度的图片,单次则需要消耗更多的点数。以下是官方给出的价格表:
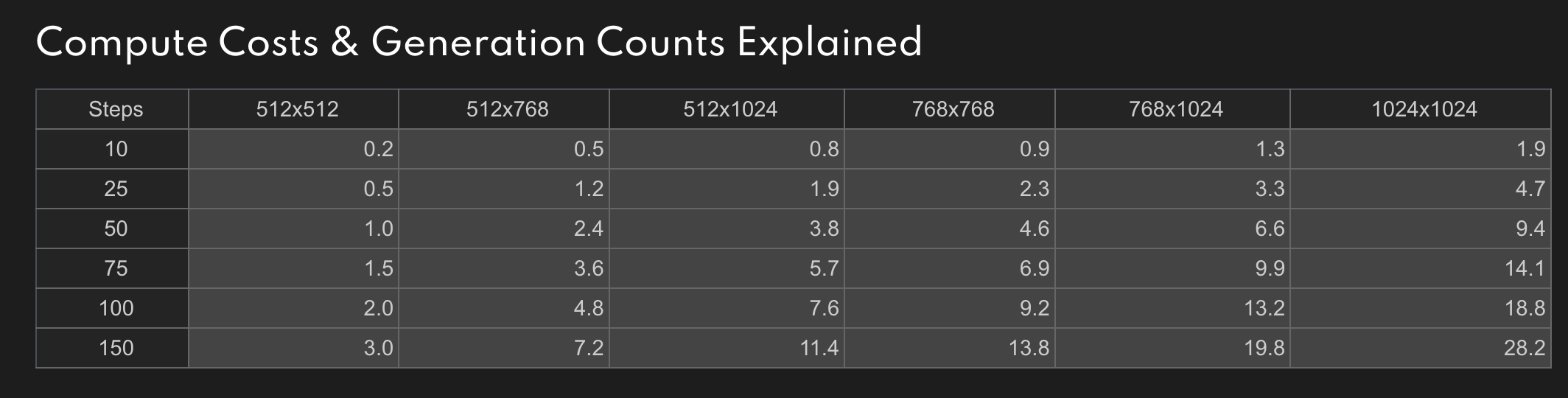
而且使用这种方式,你生成图片的版权是自动转为为 CC0 1.0,你可以商用或者非商用你生成的图片,但是也会默认成为公共领域的资源。

这一种是我比较推荐的方式,因为这种方式你可以几乎无限地使用 Stable Diffusion,并且由于这种方式是你自己跑模型的方式生成的图片,版权归属于你自己。
Colab 是什么呢?
Colaboratory 简称“Colab”,是 Google Research 团队开发的一款产品。在 Colab 中,任何人都可以通过浏览器编写和执行任意 Python 代码。它尤其适合机器学习、数据分析和教育目的。从技术上来说,Colab 是一种托管式 Jupyter 笔记本服务。用户无需设置,就可以直接使用,同时还能获得 GPU 等计算资源的免费使用权限。 —— https://research.google.com/colaboratory/faq.html?hl=zh-CN
由于 Colab 是Google 的产品,因此你使用前必须要拥有一个 Google 账户,如果不知道怎么注册的划到最底下的 Google 账号注册教程。
而我们目前默认使用的是 Hugging face 开源的 colab 示例。
Hugging face 是一家总部位于纽约的聊天机器人初创服务商,开发的应用在青少年中颇受欢迎,在上面存储了大量的模型,而 Stability.ai 的 Stable ****Diffusion 也是开源在上面。
打开后,点击右上角的连接。
点击确定

等连接上后我们运行第一段脚本,就是查看当前使用的机器。一般是从 K80、T4、P100、V100 中随机分配一个。
我拿到的是一个 Tesla T4 GPU 的机器,这里比较看人品。如果你拿到一个 V100 的一定要发一波炫耀一下。

然后继续跑下面的命令,安装必要的依赖,每次安装完成后,都会显示运行时间以及运行状态。


运行到这一步,会要求你填写一个 huggingface_hub 的 token 链接
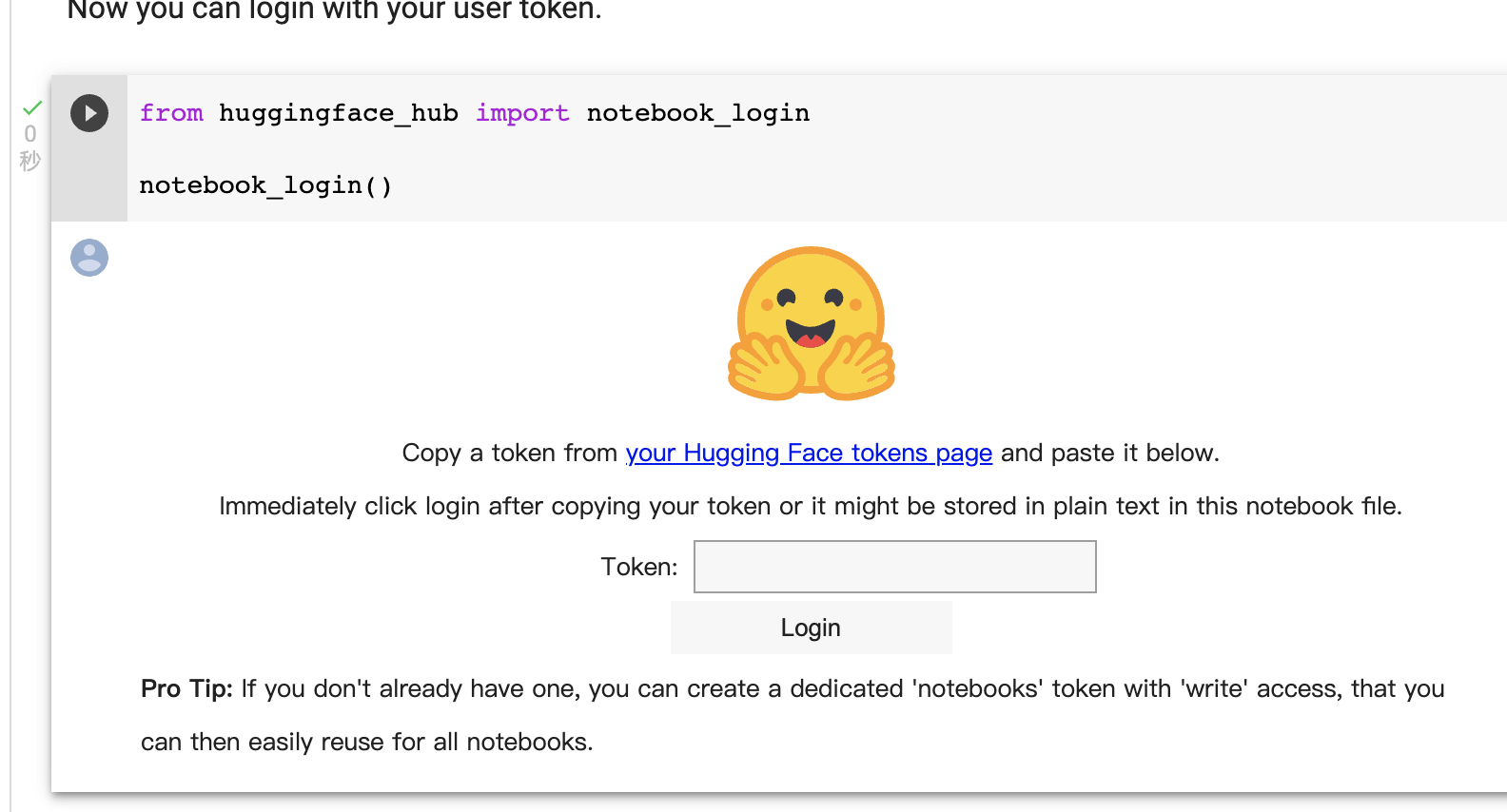
来到 https://huggingface.co/settings/tokens 这个页面,如果没有登录默认会调到登录页
注册一个账号后,复制这个 Token 到 Colab 页面
然后会提示你登录成功了,如果提示异常应该是你复制错了,这个时候你得点开秘钥,手动复制一下。

然后接下来我们就开始拉取模型
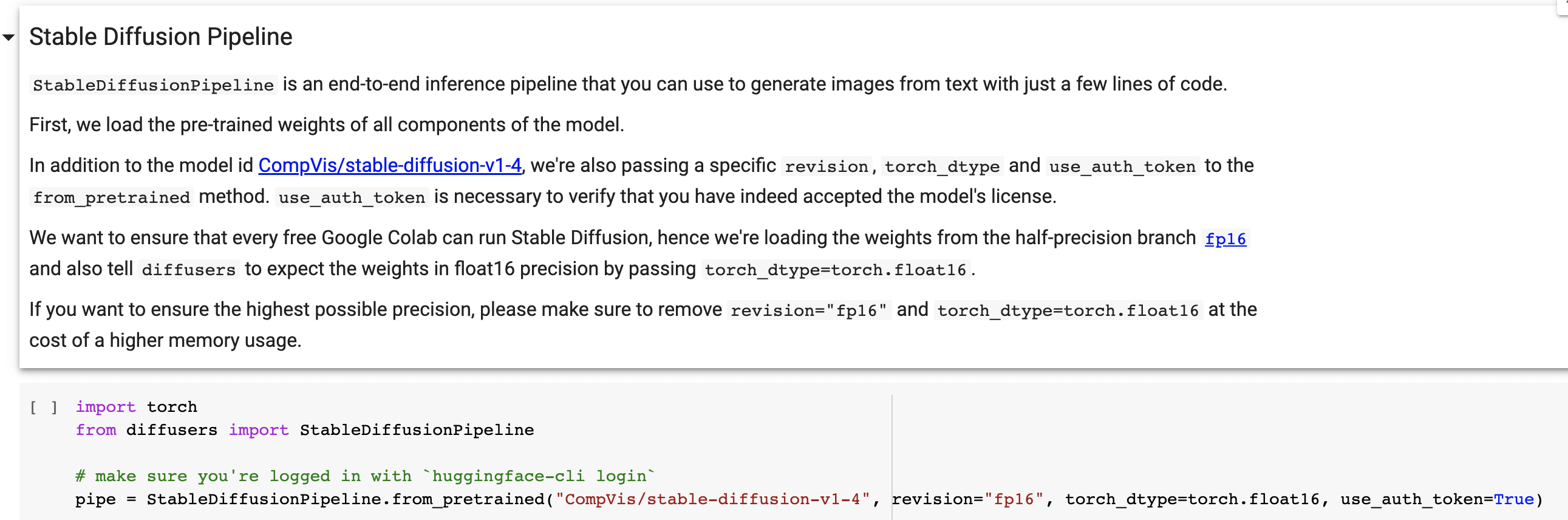
注意,这里你直接先运行,是会报错了,会显示 403
{"error":"Access to model CompVis/stable-diffusion-v1-4 is restricted and you are not in the authorized list. Visit https://huggingface.co/CompVis/stable-diffusion-v1-4 to ask for access."}
这是因为你没有去 huggingface 授权访问。
打开 https://huggingface.co/CompVis/stable-diffusion-v1-4
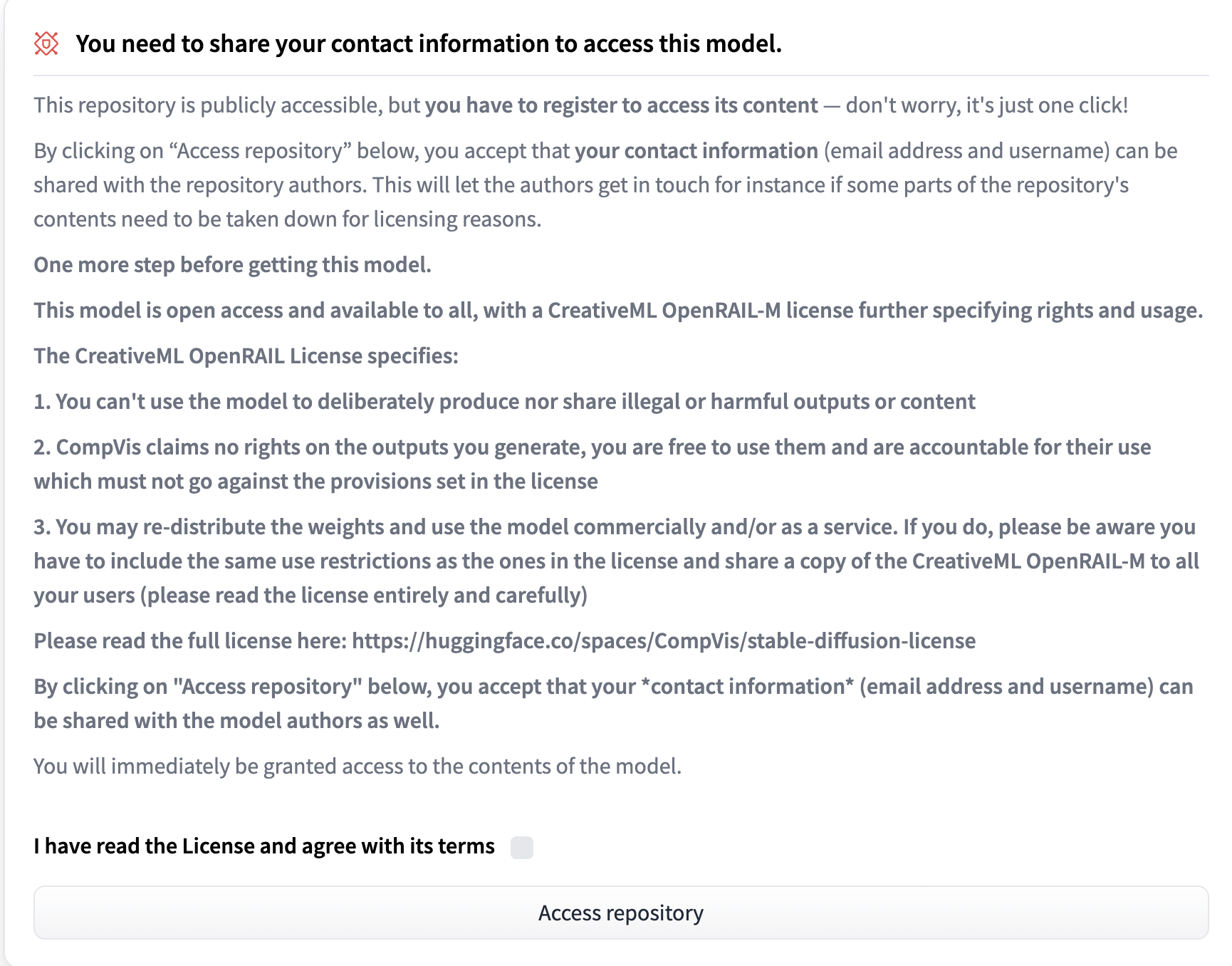
点击 运行这个仓库,然后再回到 Colab 就可以正常拉取模型了。
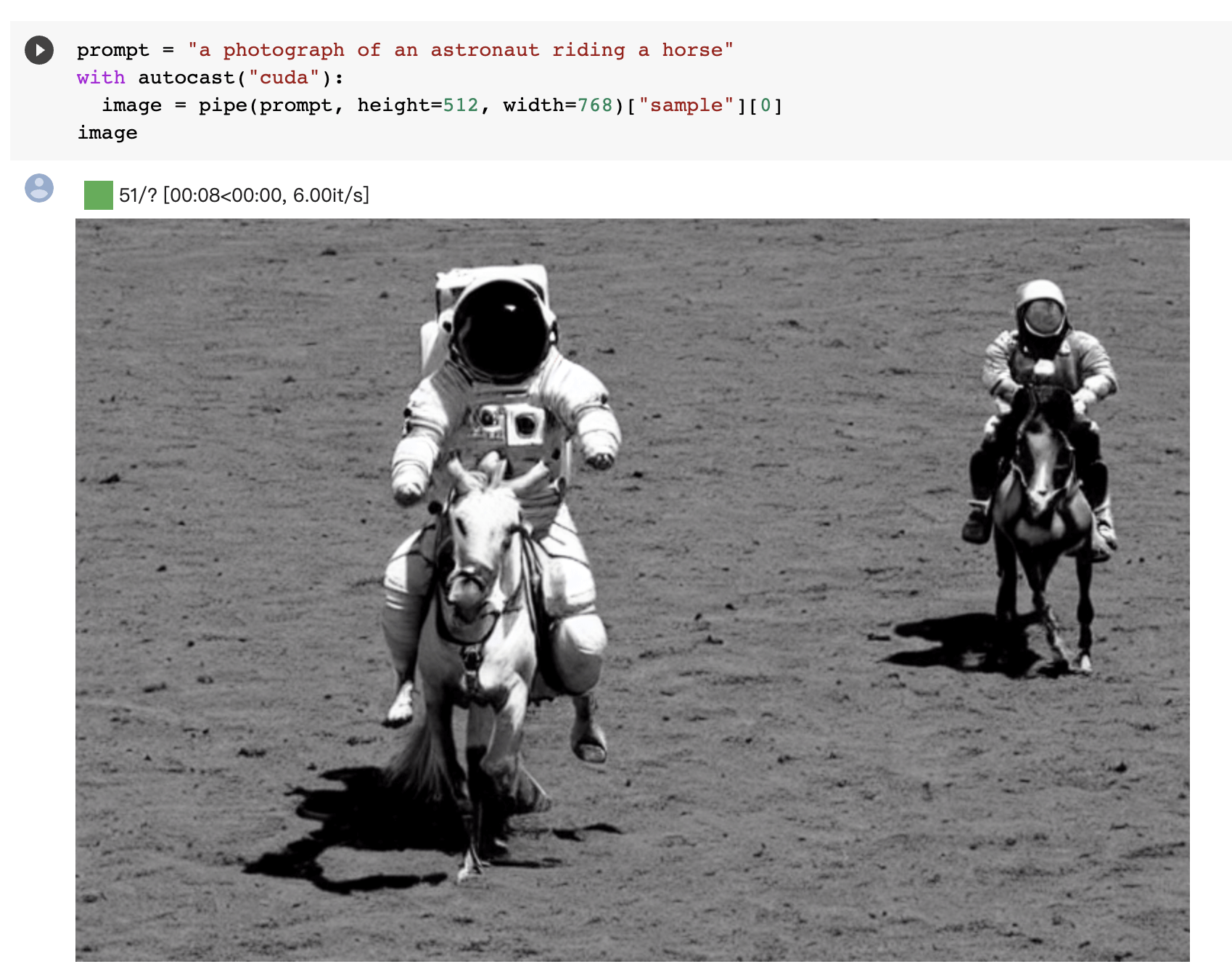
最后就到了激动人心的时候了,开始生成图片,运行以下两个步骤,prompt 就是描述,你可以输入任何你想输入的话语。

用官方默认的 prompt 点击运行就会生成一张宇航员骑马的照片(大约20秒左右)

nice,这个就是我生成的图片。
以上基础的教程就完成了,后面还可以设置更多丰富的参数。
设置随机种子(先快速生成低质量图片看看效果,然后再调高画质)

调整迭代次数

多列图片

设置宽高
总的来说我个人更加偏好这种方式,因为可以自己 diy,而且可以近乎无限地使用。
最后如果你想不好 prompt 的话,可以参考这个网站 https://lexica.art/ ,含有大量别人试验好的样子。

3.本地运行
如果你自己有高级显卡,可以自己尝试。
确实总的来说,stable-diffusion 并没有特别限制,但是使用图片必须要遵守以下规则:

1.如果你是使用第三方平台,需要遵守第三方平台的一些规定,例如官方的 dreamstudio.ai 你可以自己商业或者非商用,但是默认你得也遵循 CC0 1.0 条约。
2.如果你使用自己本地部署,那么版权归属你自己。
首先emmm,科学xx,懂得都懂
点击创建账号 —— 个人用途
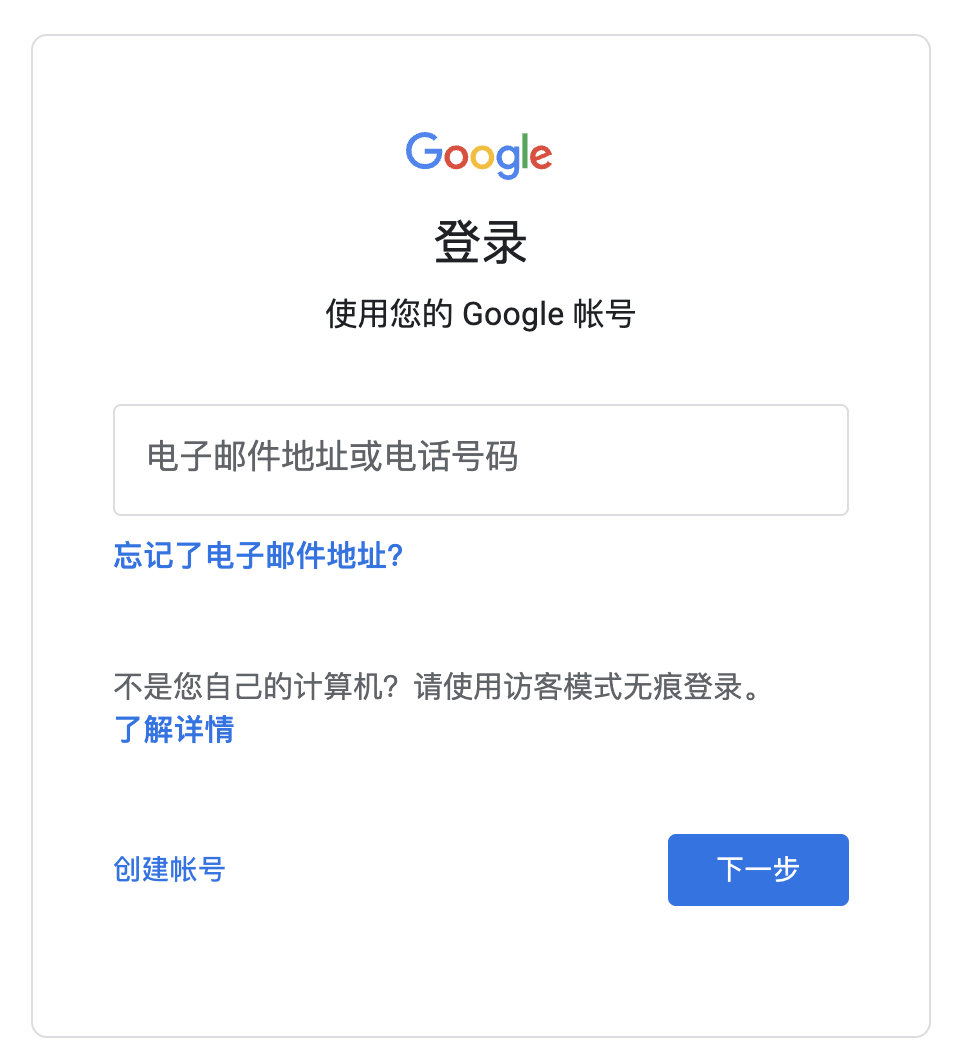
填写基本的个人信息
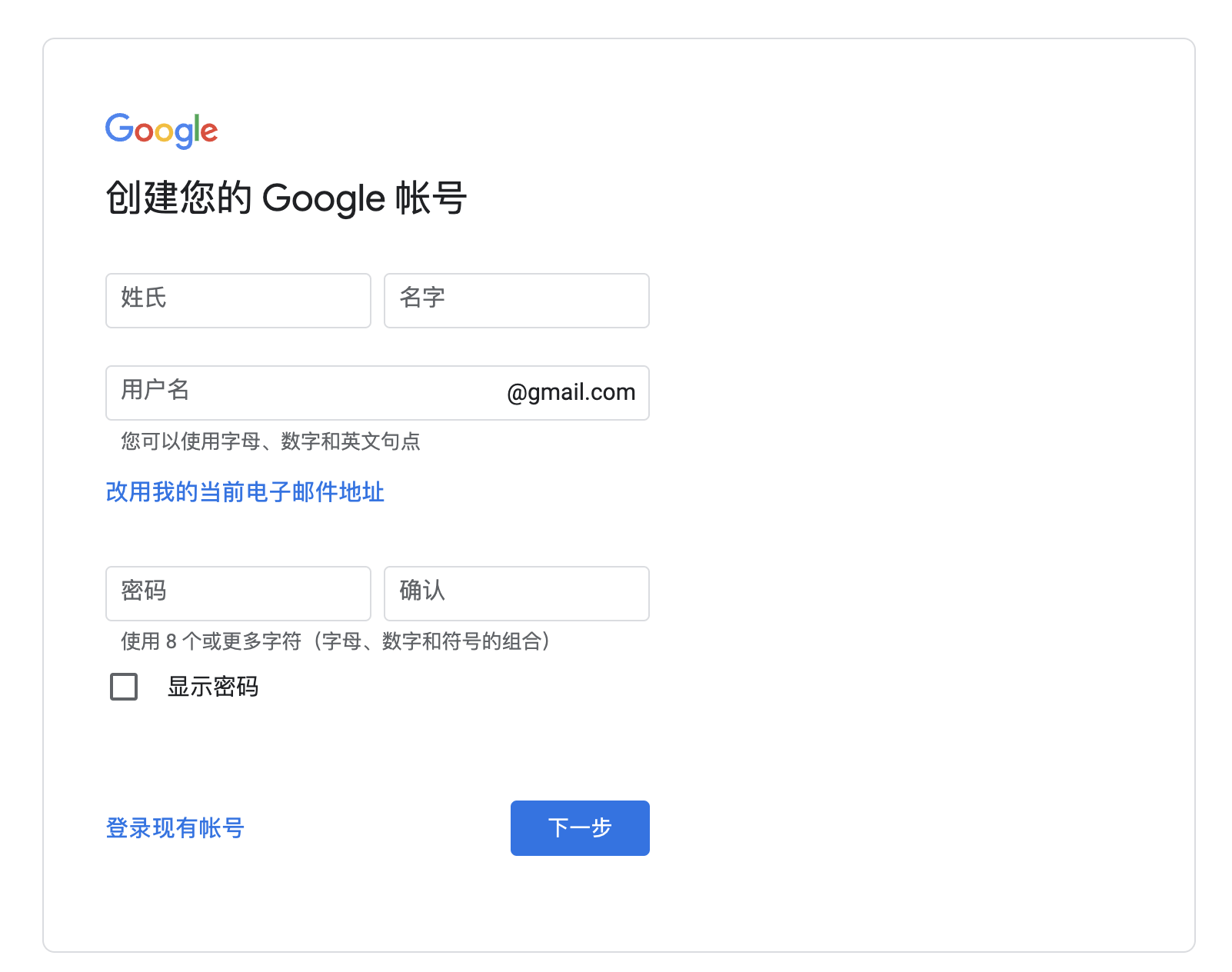
填写手机号和年月信息
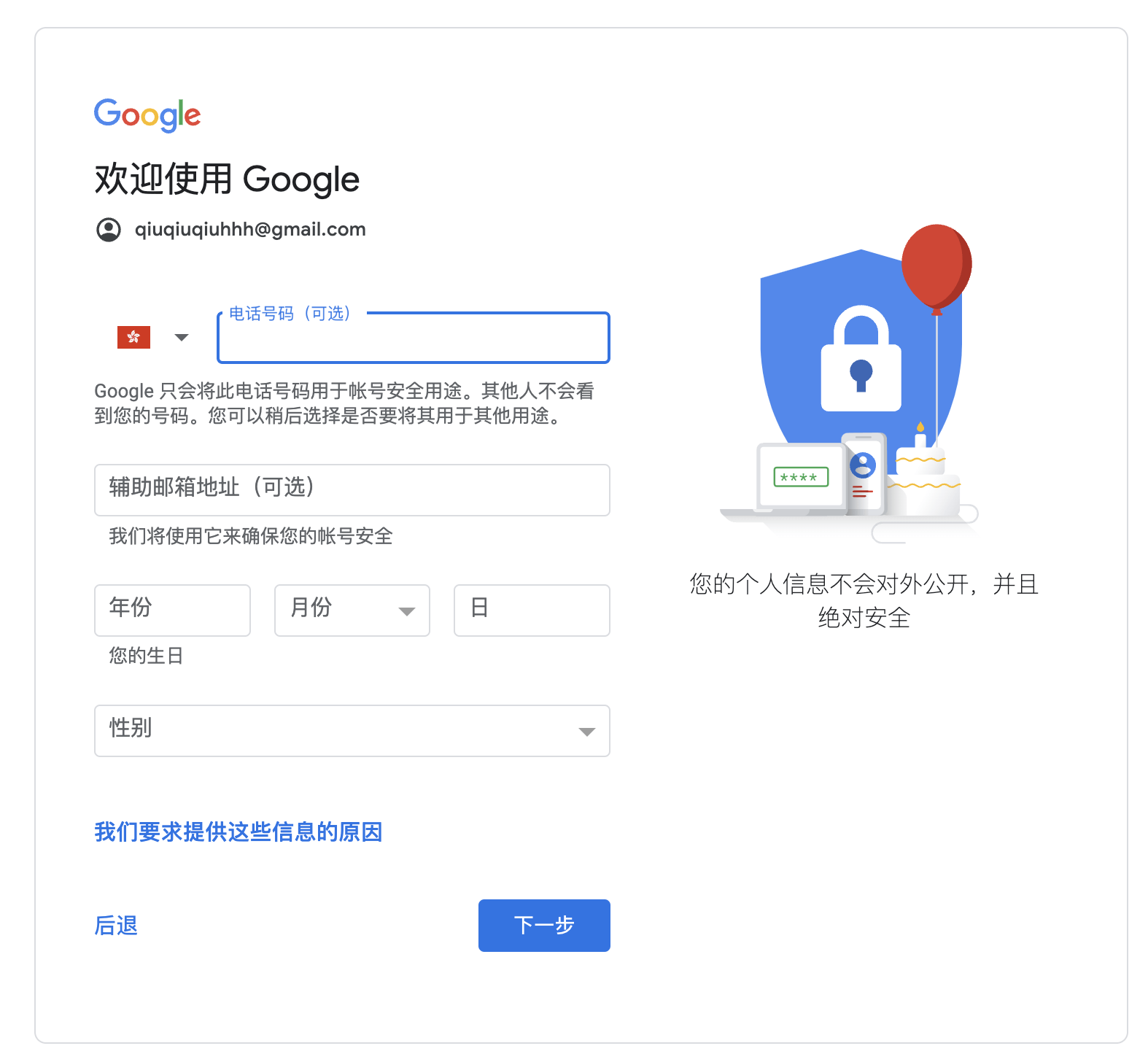
然后手机收到一个验证码,点击验证,打工搞成
然后点击跳过
同意协议,大功告成!
放一波我最近生成的图,春夏秋冬的亭子

如果你有不明白或者是数字绘画爱好者欢迎交流呀。(严禁打广告、发不相关的内容!码过期的话加 qiufengblue)
最新更新,将所有其他的资料放入了 notion
https://qiufeng.notion.site/06fab45ec290447ba41c3fd0f6e78fac

我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我想为名字验证编写一个正则表达式。正则表达式应包括所有字母(拉丁/法语/德语字符等)。但是我想从中排除数字并允许-。所以基本上它是\w(减)数(加)-。请帮忙。 最佳答案 ^[\p{L}-]+$\p{L}匹配anykindofletterfromanylanguage. 关于ruby-on-rails-rails中的正则表达式匹配[\w]和"-"但不匹配数字,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
在我的应用程序中,我有一个文本字段,用户可以在其中输入类似这样的内容"1,2,3,4"存储到数据库中。现在,当我想使用内部数字时,我有两个选择:"1,2,3,4".split(',')或string.scan(/\d+/)do|x|a两种方式我都得到一个像这样的数组["1","2","3","4"]然后我可以通过在每个数字上调用to_i来使用这些数字。有没有更好的方法可以转换"1,2,3"to[1,2,3]andnot["1","2","3"] 最佳答案 str.split(",").map{|i|i.to_i}但是这个想法对你来说