BitMap的问题在于,不管业务中实际的元素基数有多少,它占用的内存空间都恒定不变。
如果BitMap中的位的取值范围是1到100亿之间,那么BitMap就会开辟出100亿Bit的存储空间。
但是如果实际上值只有100个的话,100亿Bit的存储空间只有100Bit为1,其余全部为0,数据存储空间浪费严重,数据越稀疏,空间浪费越严重。
为了解决位图稀疏存储浪费空间的问题,出现了很多稀疏位图的压缩算法,RoaringBitmap就是其中的优秀代表。
Roaring Bitmap是高效压缩位图,简称RBM
RBM的历史并不长,它于2016年由S. Chambi、D. Lemire、O. Kaser等人在论文《Better bitmap performance with Roaring bitmaps》与《Consistently faster and smaller compressed bitmaps with Roaring》中提出.
假设数据的取值范围为int(无符号)
注意:下面所有的讲解均是按照int的取值范围讲,实际上目前RoaringBitMap采用的默认取值范围就是这个,其实也提供对long取值范围的支持,不多讲
232=4294967295,即取值范围为0~43亿左右。
如果用BitMap来实现对应的功能,需要准备需要232 bit的存储空间(0.5G),但是如果只用来存储少量数据的话,显然造成了严重的储存空间浪费
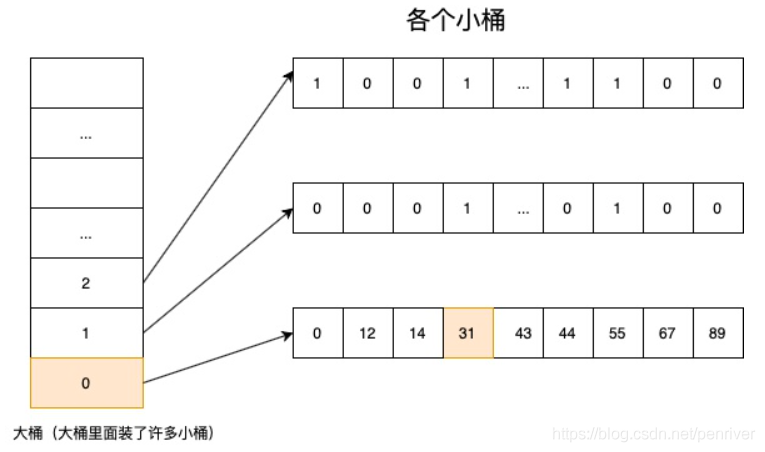
将数据的前半部分,即216(这里为高16位)部分作为桶的编号,将分为216=65536个桶,RBM中将这些小桶称之为Contriner(容器)
注意:此时Contriner并没有创建
存储数据时,按照数据的高16位做为Contriner的编号去找对应的Contriner(找不到就创建对应的Contriner),再将低16位放入该Contriner中
所以一个RBM是很多Contriner的集合
示例:如下图所示
将31这个值存储进RBM时
首先获取高位部分得到值为0,所以对应的桶(Container)编号为0
根据桶编号获取到对应的Container,然后将低位的31设置进对应的Container中
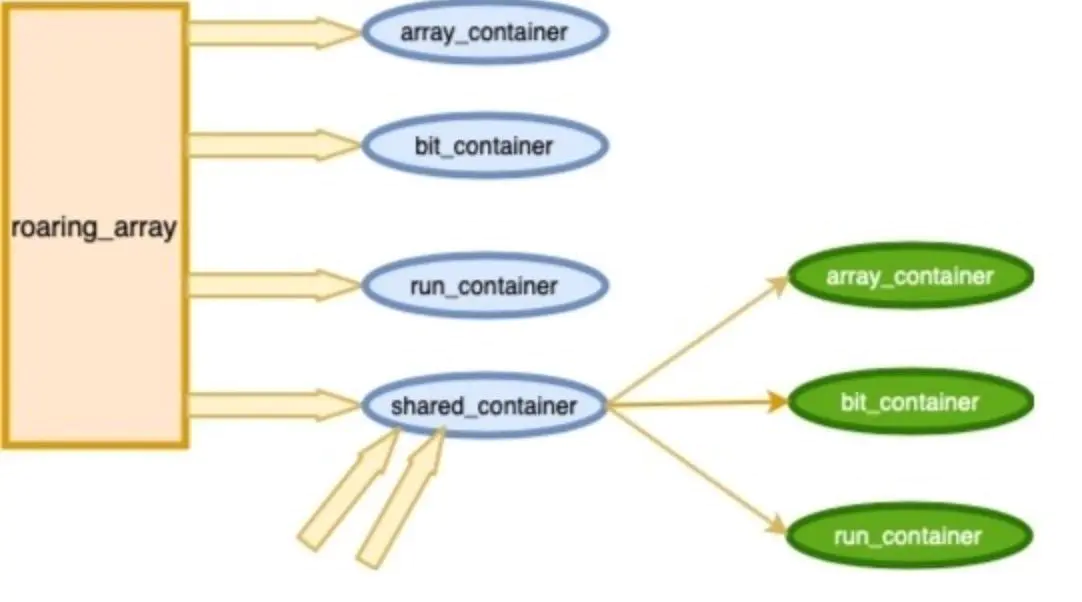
在roaringbitmap中共有4种Container:arraycontainer(数组容器),bitmapcontainer(位图容器),runcontainer(行程步长容器),sharedcontainer(共享容器)
在创建一个新Container时,如果只插入一个元素,RBM默认会用ArrayContainer来存储。其中每一个元素的类型为 short int 占两个字节。
当ArrayContainer的容量超过4096后,会自动转成BitmapContainer。
4096这个阈值很聪明,低于它时ArrayContainer比较省空间,高于它时BitmapContainer比较省空间。也就是说ArrayContainer存储稀疏数据BitmapContainer存储稠密数据,可以最大限度地避免内存浪费。
下面这个图可以很清楚的看懂这种关系

这个容器其实就是我们最开讲的位图,只不过这里位图的位数为2^16(65536)个,也就是2 ^ 16个bit,计算下来起所占内存就是8kb。然后每一位用0,1表示这个数不存在或者存在

这是一种利用步长来压缩空间的方法
比如连续的整数序列 11, 12, 13, 14, 15, 27, 28, 29 会被压缩为两个二元组 11, 4, 27, 2 表示:11后面紧跟着4个连续递增的值,27后面跟着2个连续递增的值,那么原先16个字节的空间,现在只需要8个字节,是不是节省了很多空间呢。不过这种容器不常用,所以在使用的时候需要我们自行调用相关的转换函数来判断是不是需要将arraycontiner,或bitmapcontainer转换为runcontainer
这种容器它本身是不存储数据的,只是用它来指向 arraycontainer,bitmapcontainer或runcontainer,就好比指针的作用一样,这个指针可以被多个对象拥有,但是指针所指针的实质东西是被这多个对象所共享的。在我们进行roaringbitmap之间的拷贝的时候,有时并不需要将一个container拷贝多份,那么我们就可以使用sharedcontainer来指向实际的container,然后把sharedcontainer赋给多个roaringbitmap对象持有,这个roaringbitmap对象就可以根据sharedcontainer找到真正存储数据的container,这可以省去不必要的空间浪费
这些container之间的关系可以用下面这幅图来表示:
BitmapContainer只涉及到位运算且可以根据下标直接寻址,显然为O(1)。
ArrayContainer和RunContainer都需要用二分查找在有序数组中定位元素,故为O(logN)。
BitmapContainer是恒定为8KB的
ArrayContainer的空间占用与基数(c)有关,为(2 + 2c)B;
RunContainer的则与它存储的连续序列数(r)有关,为(2 + 4r)B。
Roaring BitMap本质上是将大块的bitmap分成各个小块,其中每个小块在需要存储数据的时候才会存在。
所以当进行交集或并集运算的时候,roaringbitmap只需要去计算存在的一些块而不需要像bitmap那样对整个大的块进行计算。
如果块内非常稀疏,那么只需要对这些小整数列表进行集合的 AND、OR 运算,这样的话计算量还能继续减轻。
这里既不是用空间换时间,也没有用时间换空间,而是用逻辑的复杂度同时换取了空间和时间。
同时在RBM中32位长的数据,被分割成高 16 位和低 16 位,高 16 位表示块偏移,低16位表示块内位置,单个块可以表达 64k 的位长,也就是 8K 字节。这样可以保证单个块都可以全部放入 L1 Cache,可以显著提升性能
RoaringBitMap在很多产品中都有使用,如redis、lucene、spark等,参见 https://github.com/RoaringBitmap/RoaringBitmap
为了加速搜索,Lucene会将常用的查询过滤条件产生的结果集缓存到内存中,方便复用,称为filter cache。结果集其实就是文档ID(整形数)的集合。从Lucene 5开始,使用了RBM优化过的文档ID集合RoaringDocIdSet作为filter cache,详情可以参见《Frame of Reference and Roaring Bitmaps》。该文除了介绍RBM外,还介绍了压缩倒排索引的Frame of Reference(FOR)编码,值得一读。
在Spark Core的MapStatus组件(用来跟踪ShuffleMapTask的输出结果块)中,利用了RBM来存储块是否非空的状态。今后会在Spark连载里讲到它,所以现在看看该类的源码就可以了,不难理解。
GP配合RoaringBitmap非常适合做海量用户的近实时画像,每个RBM代表一维标签即可,根据标签圈选用户也很方便。GP原生并未支持RBM类型数据,需要安装一个扩展插件,见这里。关于GP与RBM的整合与使用,有两篇不错的参考文章:
我们在Redis里经常使用位图存储数据(Redis原生以字符串的形式支持位图),当然也就会遇到稀疏位图浪费存储空间的问题。但要让Redis支持RBM,需要引入专门的module,项目地址见这里。它的设计思想与Java版RBM几乎相同。
<dependency>
<groupId>org.roaringbitmap</groupId>
<artifactId>RoaringBitmap</artifactId>
<version>0.9.9</version>
</dependency>
/**
* @author GGBOOM
* @description Roaring BitMap(高效压缩位图)测试
* @createTime 2022/10/28 14:44
*/
public class RoaringBitMapTest {
/**
* 将值添加到容器中(将值设置为“true”),无论它是否已出现。
* Java缺少本机无符号整数,但x参数被认为是无符号的。
* 在位图中,数字按照Integer.compareUnsigned进行排序。我们订购的数字是0,1,…,2147483647,-2147483648,-2147473647,…,-1。
* add(final int x)
* 参数: x–整数值
*/
@Test
public void add() {
RoaringBitmap rbm = new RoaringBitmap();
rbm.add(1);
rbm.add(4);
rbm.add(100000000);
System.out.println(rbm);
}
/**
* 将值添加到容器中(将值设置为“true”),无论它是否已出现。
* checkedAdd(final int x)
* 参数: x–整数值
* return: 如果添加的int尚未包含在位图中,则为true。否则为False
*/
@Test
public void checkAndadd() {
RoaringBitmap rbm = RoaringBitmap.bitmapOf(1, 2, 3, 6, 1000, 100000000);
boolean checkedAdd1 = rbm.checkedAdd(3);
boolean checkedAdd2 = rbm.checkedAdd(4);
// 查询该位图中存储的第几个值,从小到大排序
System.out.println(checkedAdd1);
System.out.println(checkedAdd2);
System.out.println(rbm);
// false
// true
// {1,2,3,4,6,1000,100000000}
}
/**
* 检查是否包含该值,这相当于检查是否设置了相应的位(在BitSet类中获取)
* 参数: x–整数值
* return: 是否包括整数值。
*/
@Test
public void contains() {
RoaringBitmap rbm = RoaringBitmap.bitmapOf(1, 2, 3, 6, 1000, 100000000);
boolean contains1 = rbm.contains(3);
boolean contains2 = rbm.contains(4);
// 查询该位图中存储的第几个值,从小到大排序
System.out.println(contains1);
System.out.println(contains2);
}
/**
* 查询该位图中存储的第几个值,从小到大排序
* select(int j)方法中,
* 参数:j代表的是位图值的索引
* return:根据索引查到的值
*/
@Test
public void select() {
RoaringBitmap rbm = RoaringBitmap.bitmapOf(1, 3, 2, 1000, 100000000);
// 查询该位图中存储的第几个值,从小到大排序
int valueOfIndex0 = rbm.select(0);
int valueOfIndex1 = rbm.select(1);
int valueOfIndex2 = rbm.select(2);
int valueOfIndex3 = rbm.select(3);
System.out.println(valueOfIndex0);
System.out.println(valueOfIndex1);
System.out.println(valueOfIndex2);
System.out.println(valueOfIndex3);
// 1
// 2
// 3
// 1000
}
/**
* 统计排名
* rank(int x) ——> rankLong(int x)
* Rank返回小于或等于x的整数数(Rank(无穷大)将是GetCardinality())。如果提供最小值作为参数,此函数将返回1。如果提供小于最小值的值,则返回0。
*/
@Test
public void rank() {
RoaringBitmap rbm = RoaringBitmap.bitmapOf(1, 2, 3, 6, 1000, 100000000);
// 查询该位图中存储的第几个值,从小到大排序
System.out.println(rbm.rank(0));
System.out.println(rbm.rank(1));
System.out.println(rbm.rank(2));
System.out.println(rbm.rank(3));
System.out.println(rbm.rank(4));
System.out.println(rbm.rank(5));
System.out.println(rbm.rank(6));
System.out.println(rbm.rank(7));
System.out.println(rbm.rank(2000));
System.out.println(rbm.rank(3000));
System.out.println(rbm.rank(6000));
System.out.println(rbm.rank(111111111));
System.out.println(rbm.rank(1000000));
}
/**
* 检查范围是否与位图相交。
* intersects(long minimum, long supremum)
* 参数: minimum–范围的包含无符号下界 supermum–范围的唯一无符号上界
* 注意:[上闭,下开)
*/
@Test
public void intersects() {
RoaringBitmap rbm = RoaringBitmap.bitmapOf(1, 2, 3, 1000, 100000000);
// 查询该位图中存储的第几个值,从小到大排序
Boolean boolean1 = rbm.intersects(4L, 999L);
Boolean boolean2 = rbm.intersects(4L, 1000L);
Boolean boolean3 = rbm.intersects(4L, 1001L);
Boolean boolean4 = rbm.intersects(3L, 999L);
Boolean boolean5 = rbm.intersects(2000L, 100000000L);
Boolean boolean6 = rbm.intersects(100000000L, 100000001L);
System.out.println(boolean1);
System.out.println(boolean2);
System.out.println(boolean3);
System.out.println(boolean4);
System.out.println(boolean5);
System.out.println(boolean6);
// false
// false
// true
// true
// false
// true
}
/**
* 按位OR(联合)操作。参数中的位图不会被修改,只要提供的位图保持不变,此操作是线程安全的。
* 如果您有2个以上的位图,请考虑使用FastAggregation类。
* 参数: x1–第一个位图 x2–其他位图
* return: 操作结果
*
* @see FastAggregation#or(RoaringBitmap...)
* @see FastAggregation#horizontal_or(RoaringBitmap...)
*/
@Test
public void or() {
RoaringBitmap rbm1 = RoaringBitmap.bitmapOf(1, 2, 3, 1000, 100000000);
RoaringBitmap rbm2 = RoaringBitmap.bitmapOf(1, 2, 3, 4, 2000, 5000);
RoaringBitmap or = RoaringBitmap.or(rbm1, rbm2);
System.out.println(or);
}
/**
* 按位AND(交叉)运算。参数中的位图不会被修改,只要提供的位图保持不变,此操作是线程安全的。
* 如果您有2个以上的位图,请考虑使用FastAggregation类。
* 参数: x1–第一个位图 x2–其他位图
* return:操作结果
*
* @see FastAggregation#and(RoaringBitmap...)
*/
@Test
public void and() {
RoaringBitmap rbm1 = RoaringBitmap.bitmapOf(1, 2, 3, 1000, 100000000);
RoaringBitmap rbm2 = RoaringBitmap.bitmapOf(1, 2, 3, 4, 1000, 5000);
RoaringBitmap and = RoaringBitmap.and(rbm1, rbm2);
System.out.println(and);
}
}
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
是否有任何可用于Ruby的开源压缩/解压库?有没有人实现过LZW?或者,是否有任何使用压缩组件的开源库可以提取出来独立使用?编辑——感谢您的回答!我应该提到我必须压缩的是只驻留在数据库中的长字符串(我不会压缩文件)。此外,如果可以执行此操作的任何库都具有用于客户端压缩/分解的等效JavaScript实现,那将是理想的,因为这将用于Web应用程序。 最佳答案 您会在rubystdlib下找到所有已交付的ruby库的一个很好的列表.我会使用zlib库,它是开放的,无处不在,您会发现几乎所有语言的库!
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
我有一个包含100多个zip文件的目录,我需要读取zip文件中的文件以进行一些数据处理,而无需解压缩存档。是否有一个Ruby库可以在不解压缩文件的情况下读取zip存档中的文件内容?使用rubyzip报错:require'zip'Zip::File.open('my_zip.zip')do|zip_file|#Handleentriesonebyonezip_file.eachdo|entry|#Extracttofile/directory/symlinkputs"Extracting#{entry.name}"entry.extract('here')#Readintomemoryc
我有一个正在HerokuCedar堆栈上部署的Rails3.2应用程序。这意味着应用程序本身负责为其静态Assets提供服务。我希望对这些Assets进行gzip压缩,所以我在production.rb的中间件堆栈中插入了Rack::Deflater:middleware.insert_after('Rack::Cache',Rack::Deflater)...curl告诉我这与宣传的一样有效。但是,由于Heroku将全力运行rakeassets:precompile,生成一堆预gzipAssets,我很想使用它们(而不是让Rack::Deflater再次完成所有工作)。我已经看到使用
我想知道与使用native操作系统库执行压缩相比,使用rubyzip压缩数据时的性能差异是什么。我正在从URL获取要压缩的数据,然后使用ZipOutputStream创建zip文件。对于native操作系统实用程序,我正在考虑使用zip工具。很高兴听到这两种方法的优缺点。 最佳答案 事实证明,无论是运算时间还是CPU使用率,都没有太大差异。但是在内存使用方面存在显着差异。与使用ziputil相比,使用rubyzip的过程最终会使用更多的内存。在我们的用例中,内存使用是一个重要问题,因此我们最终使用了zip实用程序。
我知道如何使用rubyzip检索普通zip文件的内容。但是我在解压缩压缩文件夹的内容时遇到了问题,我希望你们中的任何人都能帮助我。这是我用来解压的代码:Zip::ZipFile::open(@file_location)do|zip|zip.eachdo|entry|nextifentry.name=~/__MACOSX/orentry.name=~/\.DS_Store/or!entry.file?logger.debug"#{entry.name}"@data=File.new("#{Rails.root.to_s}/tmp/#{entry.name}")endendentry
我想每周更新一个城市表以反射(reflect)世界各地城市的变化。为此,我正在创建一个Rake任务。如果可能,我希望在不添加其他gem依赖项的情况下执行此操作。压缩文件是在geonames.org/15000cities.zip上公开可用的压缩文件.我的尝试:require'net/http'require'zip'namespace:geocitiesdodesc"RaketasktofetchGeocitiescitylistevery3days"task:fetchdouri=URI('http://download.geonames.org/export/dump/cities
假设我有这个:[{:user_id=>1,:search_id=>a},{:user_id=>1,:search_id=>b},{:user_id=>2,:search_id=>c},{:user_id=>2,:search_id=>d}]我想结束:[{:user_id=>1,:search_id=>[a,b]},{:user_id=>2,:search_id=>[c,d]}]最好的方法是什么? 最佳答案 确实是非常奇怪的要求。无论如何[{:user_id=>1,:search_id=>"a"},{:user_id=>1,:sear
我已经写了一些csv文件并压缩它,使用这个代码:arr=(0...2**16).to_aFile.open('file.bz2','wb')do|f|writer=Bzip2::Writer.newfCSV(writer)do|csv|(2**16).times{csv我想阅读这个csvbzip2ed文件(用bzip2压缩的csv文件)。这些未压缩的文件如下所示:1,24,125,28,71,3...所以我尝试了这段代码:Bzip2::Reader.open(filename)do|bzip2|CSV.foreach(bzip2)do|row|putsrow.inspectendend