相信有很多小伙伴已经注意到了,目前市场上很多固态硬盘的价格相比去年又降低了不少。这是由于制造固态硬盘所需的NAND芯片降价导致的。
根据集邦咨询的数据显示,NAND Flash市场自2022年下半年以来面临需求逆风,供应链积极去化库存加以应对,此情况导致第四季NAND Flash合约价格下跌20-25%,其中Enterprise SSD(企业级固态硬盘)是下跌最剧烈的产品,跌幅约23-28%。
这对于NAND芯片厂商来说并不是什么好消息,但对于普通消费者来说,我们确实能买到更便宜的固态硬盘了。
那么降价后的固态硬盘可以取代机械硬盘了吗?
机械硬盘的优势:便宜
说起机械硬盘的最大优势应该就是便宜了。
由于不同店铺、不同渠道(OEM/零售版)、不同品相(全新/二手)的机械硬盘售价差异较大,因此以上价格信息全部搜集于“西部数据京东自营旗舰店”和“三星存储京东自营旗舰店”,仅作为价格方面的一个基准参考。
从这些数据中可以看出,1TB这个档位机械硬盘的价格优势其实不大。有些1TB固态硬盘(比如台电、梵想、飞利浦、七彩虹)已经可以在价格上和机械硬盘打的有来有回。但到了2TB及以上的档位,机械硬盘的价格优势就很大了。
在一些论坛上我们可能会看到一些人吐槽 “机械硬盘容易坏”。这个观点其实不是很严谨,严格来说应该是机械硬盘用在移动设备上很容易坏。
这是一张机械硬盘的内部结构图,当我们需要读写数据的时候,磁盘会在电机的驱动下高速旋转,磁头则会在磁盘上读写相应的数据。
这时候如果机械硬盘受到撞击,那么磁头很容易在冲击的影响下把磁盘划伤,从而造成硬盘的损坏。如果硬盘在非读写状态下受到撞击,情况会好一些。
因为在非读写状态下,磁头位于磁头停泊区,与磁盘还是有一定距离的。所以这时候硬盘受到一定的撞击产生晃动,往往不会造成磁盘损坏。当然,要是撞得太狠该坏还是会坏。
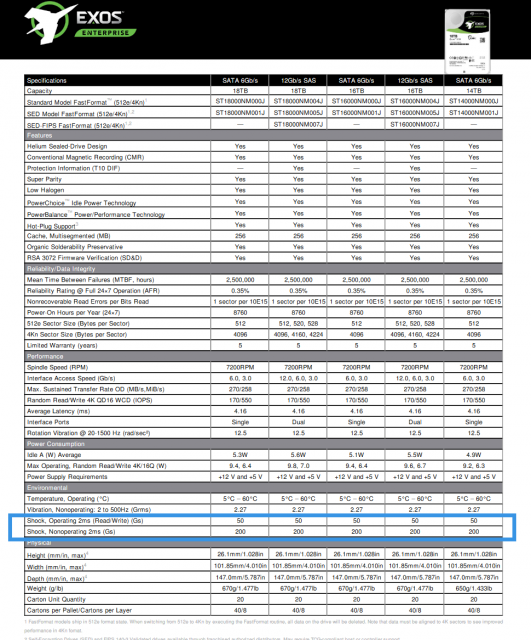
以希捷的这几款企业级机械硬盘为例,它们在工作状态(读/写)下,抗冲击强度仅为50Gs。而在非工作状态下,抗冲击强度为200Gs。这些数据也可以从侧面看出机械硬盘的读写状态下应对撞击是十分脆弱的。
因此对于机械硬盘来说,如果是通过螺丝、支架固定在家用电脑或者服务器上,其实不容易坏。但如果是用在移动硬盘、笔记本电脑等移动设备上,并且恰好在读写数据时“碰撞了一下”,那么机械硬盘就很容易坏了。而固态硬盘因为读写过程中不依赖这种机械结构,所以不用担心这方面的问题。
硬盘的读写速度可以大致分成顺序读写速度和随机读写速度。顺序读写主要是用于集中且连续的大文件读写,比如一个占用空间大小为2G的电影文件。
在我们播放或者复制这个电影文件的时候使用的就是顺序读写。而随机读写则是用于读取细碎的小文件,比如我们在启动电脑系统、打开程序、多个程序同时运行的时候就会用到随机读写。
所以对于普通用户来说,硬盘的随机读写性能更重要。而固态硬盘由于数据存储原理与机械硬盘不同,其随机读写性能是要远高于机械硬盘的。
为什么固态硬盘厂商喜欢宣传顺序读写速度?
对于硬盘厂商来说,硬盘的顺序读写速度更重要。因为顺序读写速度比随机读写速度更大,且更有利于宣传。而且厂商如果想要提高硬盘的顺序读写性能,往往只需要在缓存上下一些功夫就可以了。
举个例子来说,现在我们手里有一块硬盘。就像其它固态硬盘评测文章一样,我们在电脑上使用CrystalDiskMark对它的读写性能进行一个测试。
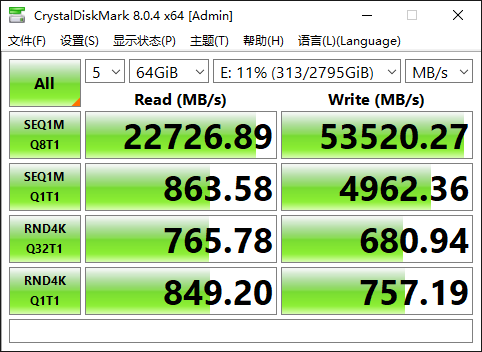
为了使测试数据尽可能准确,我们进行了5次测试,测试的数据包大小为64GiB。测试结果显示:该硬盘的顺序读取速度为22726MB/s,顺序写入速度为53520 MB/s。
我们这里选取了市面上性能较强的固态硬盘——西部数据SN850X 4TB版作为对比。该硬盘顺序读取速度为7300MB/s,顺序写入速度为6600MB/s。也就是说我们这次测试硬盘的顺序读写速度是西部数据SN850X 4TB版的大约3.11倍,顺序写入速度是西部数据SN850X 4TB版的大约8.11倍。
相信有些“关注细节”的小伙伴已经发现了,我们这次测试的硬盘在软件上显示容量为2795 GiB。因此可以推测这块硬盘的标称容量(印在包装上的容量)应该是“3TB”。而3TB这个档位在固态硬盘中很少见,但在机械硬盘中很常见。所以可能有些小伙伴已经猜到了,我们测试的是一块机械硬盘。
但如果只有机械硬盘是测不到这个数据的,所以我们通过软件的方式给这块机械硬盘加了大概100GB的DDR4内存作为缓存。这样即使我们测试64GiB的数据包,这些数据其实也都是在缓存里跑。而目前市面上大多数消费级固态硬盘的最大读写速度其实都是在“缓存状态”下跑出来的成绩。
目前市面上主流的缓存方案可以分为两种:独立缓存与“模拟SLC缓存”。
以三星的980 PRO为例,在官网的宣传图上我们可以看到980 PRO上的“大芯片”可以分成3类。最左侧银白色的芯片是主控芯片,是固态硬盘的控制器。
中间的是DRAM芯片也就是内存芯片,作为固态硬盘的缓存使用。这里的原理其实和我们直接拉电脑的内存过来当缓存相似,只不过它是通过“硬件”的方式实现。
而最右侧的是NAND芯片,这个是数据实际存放的地方。像三星980 PRO这种有一个独立的芯片用于缓存的就是独立缓存方案了。
另一种缓存方案则是“模拟SLC缓存”,也就是将MLC、TLC、QLC等NAND颗粒模拟成SLC的工作模式,这样可以在一定范围内获得读写性能提升。
对于消费级固态硬盘来说使用缓存其实也是一种无奈之举,毕竟对于普通消费者来说,比起读写性能、寿命这些参数,硬盘的价格往往更加重要。
为了使固态硬盘更加便宜,从SLC发展到MLC、TLC、QLC甚至未来的PLC都是必要的,因为只有这样才能使固态硬盘的价格爆降。但与此同时,固态硬盘的读写性能也不能太差,所以像“缓存”这种“花小钱办大事”的方案就逐渐多了起来。
1、目前机械硬盘在大容量存储方面价格优势还是十分明显的。而对于小容量存储,固态硬盘与机械硬盘价格差异不大,且固态硬盘有性能优势。因此对于小容量存储,固态硬盘更加合适。
2、由于目前大多数消费级固态硬盘顺序读写速度是在“缓存模式”下测试的,因此在选购硬盘时可以不将“顺序读写速度”作为关键参数进行对比。
3、机械硬盘+缓存>固态硬盘,在技术上很容易实现,但在商业上很尴尬。因为机械硬盘如果要加缓存就只能依靠独立缓存,也就是说要加一个独立的“缓存芯片”,那么多一个芯片就多一份成本。
如果要追求更好的性能,那这个“缓存芯片”就需要性能强、容量大,那这样成本就上去了。反之,如果用性能不强、容量不大的“缓存芯片”,那么最终整个硬盘的性能提升也不大。
目前业界大多数机械硬盘选择的“缓存芯片”最终妥协在了几十至几百MB的水平上。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
当谈到运行时自省(introspection)和动态代码生成时,我认为ruby没有任何竞争对手,可能除了一些lisp方言。前几天,我正在做一些代码练习来探索ruby的动态功能,我开始想知道如何向现有对象添加方法。以下是我能想到的3种方法:obj=Object.new#addamethoddirectlydefobj.new_method...end#addamethodindirectlywiththesingletonclassclass这只是冰山一角,因为我还没有探索instance_eval、module_eval和define_method的各种组合。是否有在线/离线资
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/