Flink 命令行参数介绍
参考文档:
1、https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/cli/
2、Flink 三种模式 | 不同的执行命令的差异
Flink 提供了一个命令行界面 (CLI) bin/flink 来运行为 JAR 文件的程序并控制它们的执行
命令行格式,一定要理解命令行的格式,每个 ACTION 都用自己对应的 OPTION(很重要,不然很容易搞混)
# ACTION 必选
# OPTION 可选
# ARGUMENTS 可选
.bin/flink <ACTION> [OPTIONS] [ARGUMENTS]
flink 中的 Action 有这些:
| Action | Purpose |
|---|---|
| run | 这个操作用于执行flink中的应用, 该命令至少需要包含作业的 jar, 可以传递与 Flink 或作业相关的参数, 一般用于执行 yarn-session 和 yarn-per-job 模式 |
| run-application | 这个操作用于执行 Application Mode 模式的应用 |
| info | 这个操作可用于打印作业的优化执行图, 需要传递包含作业的 jar |
| list | 此操作列出所有正在运行或计划的作业 |
| savepoint | 此操作可用于为给定作业创建或处置检查点, 如果 conf/flink-conf.yaml 中未指定 state.savepoints.dir 参数,则需要指定 JobID 之外的保存点目录 |
| cancel | 此操作可用于根据 JobID 取消正在运行的作业 |
| stop | 此操作结合了取消和保存点操作以停止正在运行的作业, 但也创建一个保存点以重新开始 |
① ./bin flink run
② ./bin flink run-application
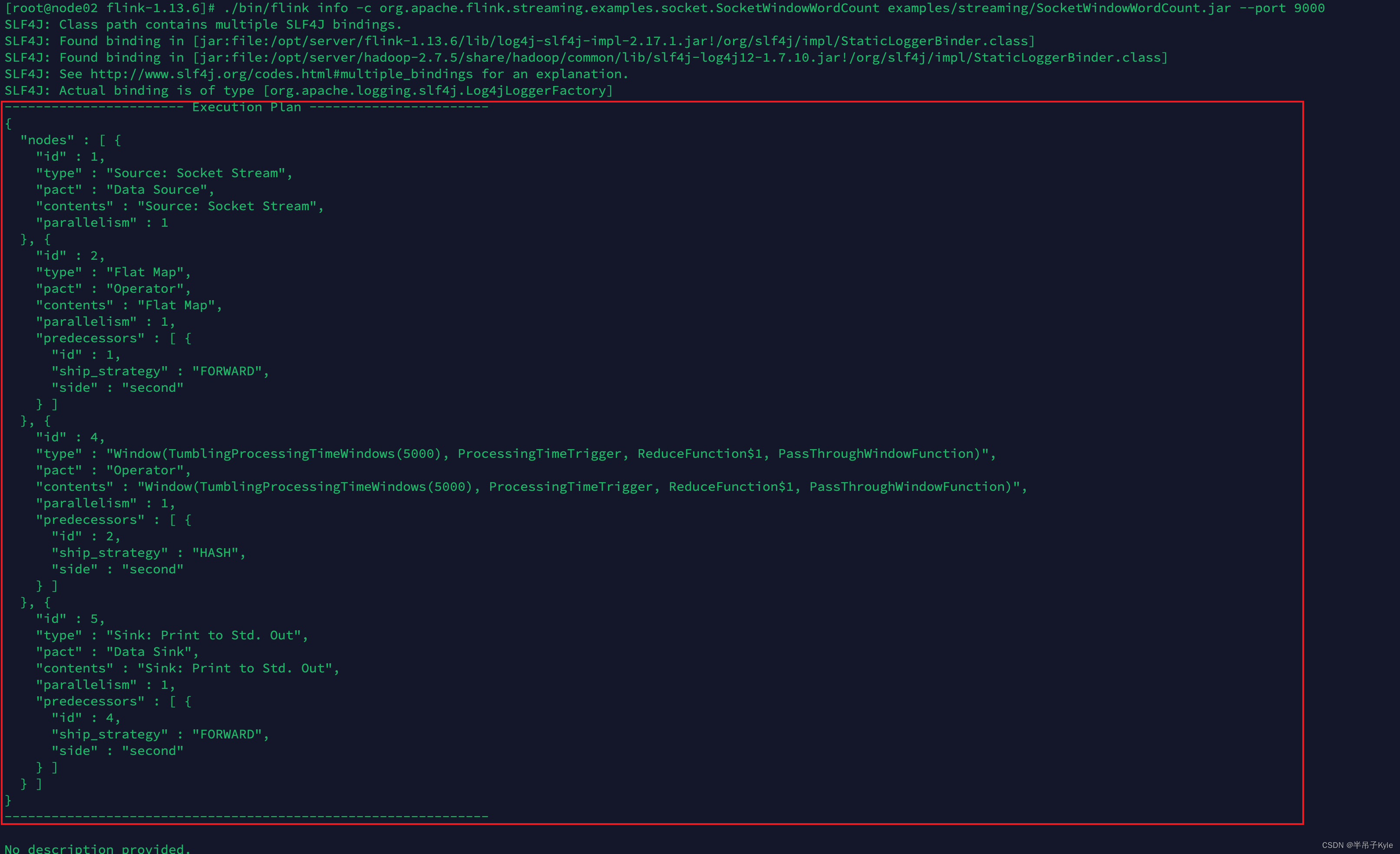
示例 3 :查看作业的执行计划
# 进入 FLINK 安装目录, 执行如下命令
./bin/flink info \
-c org.apache.flink.streaming.examples.socket.SocketWindowWordCount \
examples/streaming/SocketWindowWordCount.jar \
--port 9000
示例 4 :查看执行的作业列表
# 查看该命令的帮助
./bin/flink list -h
# 查看正在执行作业列表(如果你的程序运行在yarn集群上,这个命令可能会报错)
# flink on yarn 时,使用该命令一定要指定 cluster_id ,即可以理解为 jobId
./bin/flink list
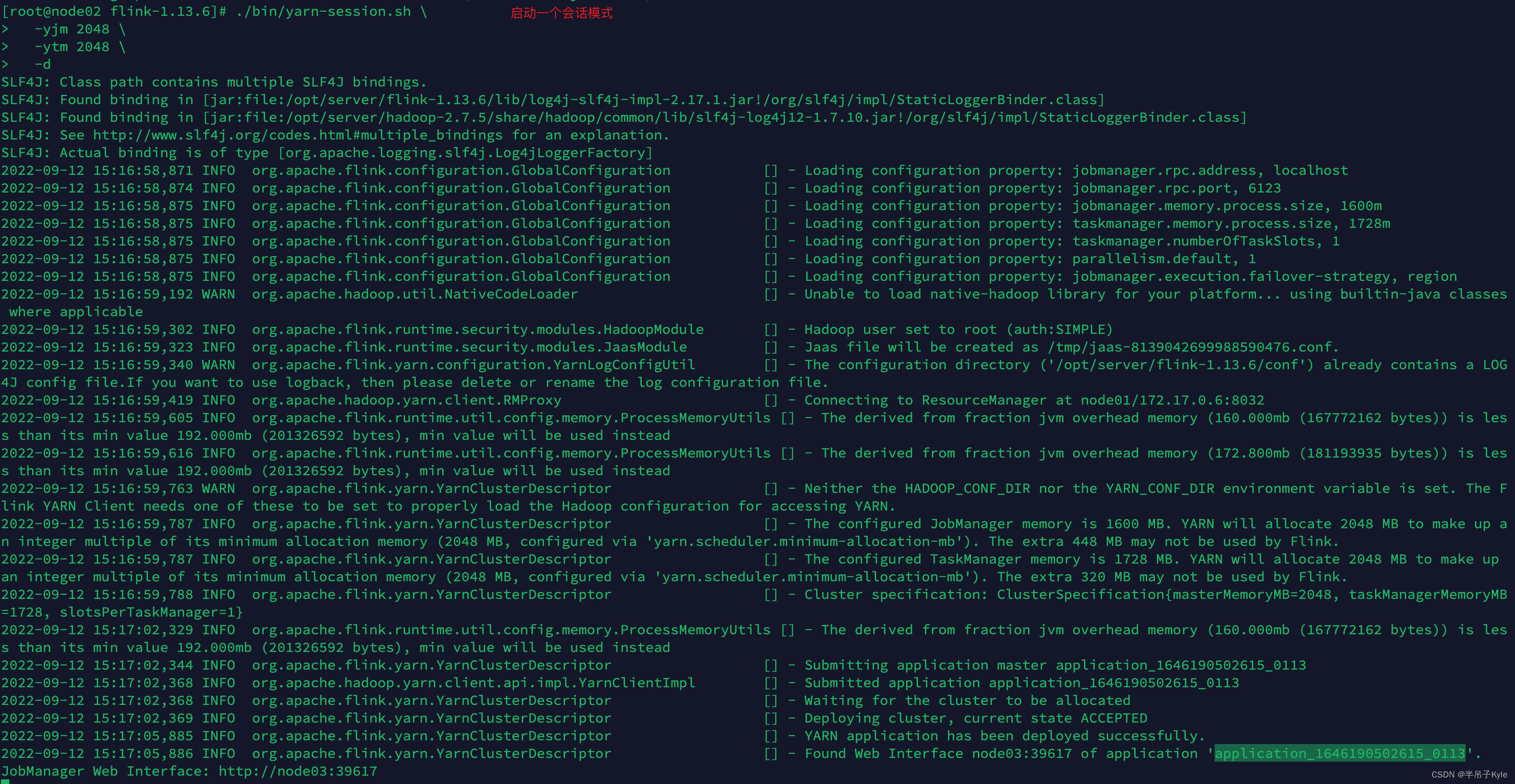
为了测试该命令,我们需要启动一个 flink 作业,我们先启动一个会话模式,然后在会话中提交一个作业 (参考该博客启动作业)
https://blog.csdn.net/hell_oword/article/details/120116908
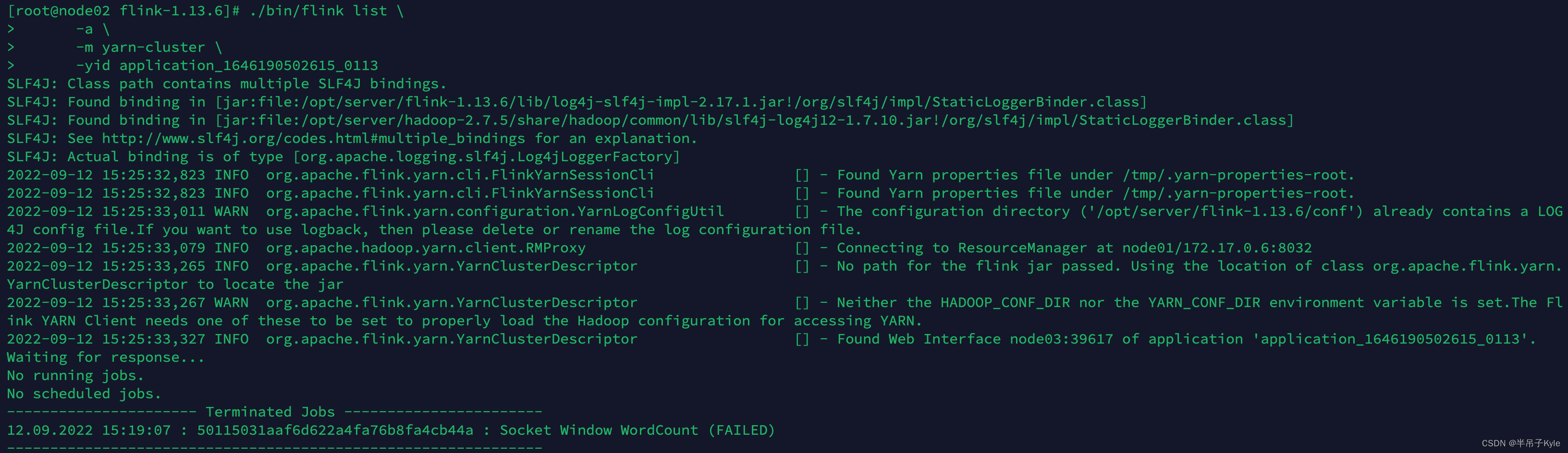
# 查看该会话下的所有运行作业列表
./bin/flink list \
-a \
-m yarn-cluster \
-yid application_1646190502615_0113
示例 4 :取消一个作业
https://blog.csdn.net/hell_oword/article/details/120116908
flink run 命令用于编译和执行一个程序
查看命令参数选项
# 命令格式
run [OPTIONS] <jar-file> <arguments>
# 查看命令帮助
./bin/flink run -h

命令参数分为 4 部分,分别为
$ ./bin/flink run -h
Syntax: run [OPTIONS] <jar-file> <arguments>
"run" action options:
...
Options for Generic CLI mode:
...
Options for yarn-cluster mode:
...
Options for default mode:
① run action options(主要用于设置执行的主类)
| Options | Purpose |
|---|---|
-c,--class <classname> | 具有程序入口的类, 即该类下有 main() 方法, 只需要指定类名即可 |
-C,--classpath <url> | 具有程序入口的类, 即该类下有 main() 方法, 需要指定类的全路径, 使用较多 |
| -d,–detached | 分离模式执行作业, 程序提交完就退出客户端, 不再打印作业进度等信息, 可以理解为异步提交, 使用较多 |
| -n,–allowNonRestoredState | 允许跳过无法恢复的保存点状态, 如果从程序中删除了一个operator,该operator在savepotint中是程序的一部分时, 不使用该操作会报错 |
-p,--parallelism <parallelism> | 指定作业的并行度, 注意并行度设置的优先级 |
-py,--python <pythonFile> | 带有程序入口点的 Python 脚本, 可以使用 --pyFiles 选项配置依赖资源, 和 -c 是一个意思, 这个是通过 python 提交作业而已 |
-pyxx | py 相关的 options 不在此处介绍, 后续补充, 目前主要以 -c 提交作业为主 |
② Options for Generic CLI mode
| Options | Purpose |
|---|---|
| -D <property=value> | 允许指定多个通用配置选项, 配置可以参考 https://nightlies.apache.org/flink/flink-docs-stable/ops/config.html |
-e,--executor <arg> | 已弃用, 不再赘述 |
-t,--target <arg> | 设置应用程序的部署目标,相当于 execution.target 配置选项run action 可以使用: “remote”, “local”, “kubernetes-session”, “yarn-per-job”, “yarn-session”run-application action 可以使用: “kubernetes-application”, “yarn-application”. |
③ Options for yarn-cluster mode(yarn-cluster 模式下的 Options)
| Options | Purpose |
|---|---|
| -d,–detached | 分离模式执行作业, 程序提交完就退出客户端, 不再打印作业进度等信息, 可以理解为异步提交, 使用较多 |
-m,--jobmanager <arg> | 将该 option 的值设置为 yarn-cluster, 以此使用 yarn 集群模式 |
-yat,--yarnapplicationType <arg> | 为 YARN 上的应用程序设置自定义应用程序类型 |
-yD <property=value> | 设置传递参数的键值对 |
-yh,--yarnhelp | 查看 yarn 提交命令 |
-yid,--yarnapplicationId <arg> | 向会话模式中提交应用 |
-yj,--yarnjar <arg> | 指定 Flink jar 文件的路径 |
-yjm,--yarnjobManagerMemory <arg> | 指定 JobManager 使用的内存大小, 使用较多, 单位(MB) |
-ynl,--yarnnodeLabel <arg> | 为 YARN 应用程序指定 YARN 节点标签 |
-ynm,--yarnname <arg> | 设置作业在 Hadoop Applications 界面显示的名称, 使用较多 |
-yq,--yarnquery | 显示可用的 yarn 资源大小 (memoty, cores) |
-yqu,--yarnqueue <arg> | 指定作业使用的 yarn 队列, , 使用较多 |
-ys,--yarnslots <arg> | 指定每个 TaskManager 使用的 slots 的数量 |
-yt,--yarnship <arg> | 传送指定目录中的文件 |
-ytm,--yarntaskManagerMemory <arg> | 指定每个TaskManager使用的内存大小, 使用较多, 单位(MB) |
-yz,--yarnzookeeperNamespace <arg> | 为高可用性模式创建 Zookeeper 子路径的命名空间 |
-z,--zookeeperNamespace <arg> | 为高可用性模式创建 Zookeeper 子路径的命名空间 |
④ Options for default mode
| Options | Purpose |
|---|---|
| -D <property=value> | 允许指定多个通用配置选项, 配置可以参考 https://nightlies.apache.org/flink/flink-docs-stable/ops/config.html |
-m,--jobmanager <arg> | 将该 option 的值设置为 yarn-cluster, 以此使用 yarn 集群模式 |
-z,--zookeeperNamespace <arg> | 为高可用性模式创建 Zookeeper 子路径的命名空间 |
示例一:提交一个应用(job分离模式)
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些