最近在做微服务的迁移改造工作,其中有一个服务需要订阅多个Kafka,如果使用spring kafka自动配置的话只能配置一个Kafka,不符合需求,该文总结了如何配置多个Kafka,希望对您有帮助。
文章目录
3.2.1,支持2.12-3.2.1 范围的版本,覆盖了Spring Boot 2.0x-Spring Boot 3.0.x。https://kafka.apache.org/downloads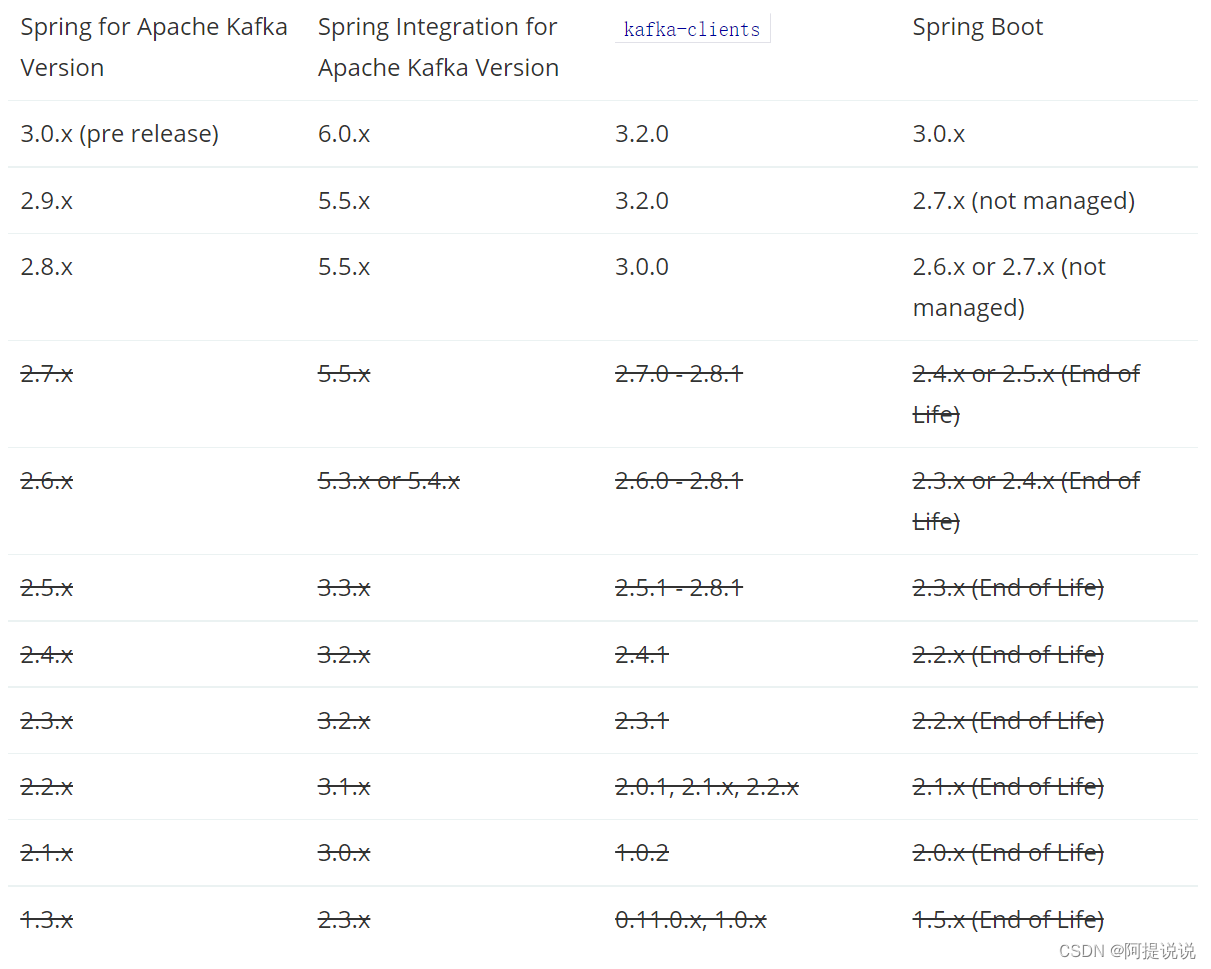
bin目录,执行如下命令,按照如下顺序启动# 配置文件选择自己对应的目录
zookeeper-server-start.sh ../config/zookeeper.properties
Windows
windows/zookeeper-server-start.bat ../config/zookeeper.properties
打开另外一个终端,启动KafkaServer
Linux
kafka-server-start.sh ../config/server.properties
Windows
windows/kafka-server-start.bat ../config/server.properties
如下是最小化配置Kafka
pom.xml 引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
application.properties
server.port=8090
spring.application.name=single-kafka-server
#kafka 服务器地址
spring.kafka.bootstrap-servers=localhost:9092
#消费者分组,配置后,自动创建
spring.kafka.consumer.group-id=default_group
KafkaProducer 生产者
@Slf4j
@Component
@EnableScheduling
public class KafkaProducer {
@Resource
private KafkaTemplate kafkaTemplate;
private void sendTest() {
//topic 会自动创建
kafkaTemplate.send("topic1", "hello kafka");
}
@Scheduled(fixedRate = 1000 * 10)
public void testKafka() {
log.info("send message...");
sendTest();
}
}
KafkaConsumer 消费者
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = {"topic1"})
public void processMessage(String spuId) {
log.warn("process spuId ={}", spuId);
}
}
运行效果:

配置稍微复杂了一点,灵魂就是手动创建,同样引入依赖
pom.xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
application.properties
server.port=8090
spring.application.name=kafka-server
#kafka1
#服务器地址
spring.kafka.one.bootstrap-servers=localhost:9092
spring.kafka.one.consumer.group-id=default_group
#kafka2
spring.kafka.two.bootstrap-servers=localhost:9092
spring.kafka.two.consumer.group-id=default_group2
第一个Kafka配置,需要区分各Bean的名称
KafkaOneConfig
@Configuration
public class KafkaOneConfig {
@Value("${spring.kafka.one.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.one.consumer.group-id}")
private String groupId;
@Bean
public KafkaTemplate<String, String> kafkaOneTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean(name = "kafkaOneContainerFactory")
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaOneContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
private ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
private ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
private Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
private Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
}
kafkaOneTemplate 定义第一个Kafka的高级模板,用来发送消息
kafkaOneContainerFactory 消费监听容器,配置在@KafkaListener中,
producerFactory 生产者工厂
consumerFactory 消费者工厂
producerConfigs 生产者配置
consumerConfigs 消费者配置
同样创建第二个Kafka,配置含义,同第一个Kafka
KafkaTwoConfig
@Configuration
public class KafkaTwoConfig {
@Value("${spring.kafka.two.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.two.consumer.group-id}")
private String groupId;
@Bean
public KafkaTemplate<String, String> kafkaTwoTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean(name = "kafkaTwoContainerFactory")
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaTwoContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
private ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
public ConsumerFactory<Integer, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
private Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
private Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
}
创建一个测试的消费者,注意配置不同的监听容器containerFactory
KafkaConsumer
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = {"topic1"}, containerFactory = "kafkaOneContainerFactory")
public void oneProcessItemcenterSpuMessage(String spuId) {
log.warn("one process spuId ={}", spuId);
}
@KafkaListener(topics = {"topic2"},containerFactory = "kafkaTwoContainerFactory")
public void twoProcessItemcenterSpuMessage(String spuId) {
log.warn("two process spuId ={}", spuId);
}
}
创建一个测试的生产者,定时往两个topic中发送消息
KafkaProducer
@Slf4j
@Component
public class KafkaProducer {
@Resource
private KafkaTemplate kafkaOneTemplate;
@Resource
private KafkaTemplate kafkaTwoTemplate;
private void sendTest() {
kafkaOneTemplate.send("topic1", "hello kafka one");
kafkaTwoTemplate.send("topic2", "hello kafka two");
}
@Scheduled(fixedRate = 1000 * 10)
public void testKafka() {
log.info("send message...");
sendTest();
}
}
最后运行效果:

其他kafka文章:
【从面试题看源码】-看完Kafka性能优化-让你吊打面试官
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下