文章目录
node1 192.168.28.5 主要软件:Elasticsearch kibana
node2 192.168.28.10 主要软件: Elasticsearch
web 192.168.28.100 主要软件: logstash apache
Elasticsearch包下载地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-5-5-0
更改主机名,,配置域名解析,查看java环境
[root@yzq ~]# hostnamectl set-hostname node1
[root@yzq ~]# su
[root@node1 ~]# systemctl stop firewalld
[root@node1 ~]# setenforce 0
[root@node1 ~]# vim /etc/hosts
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
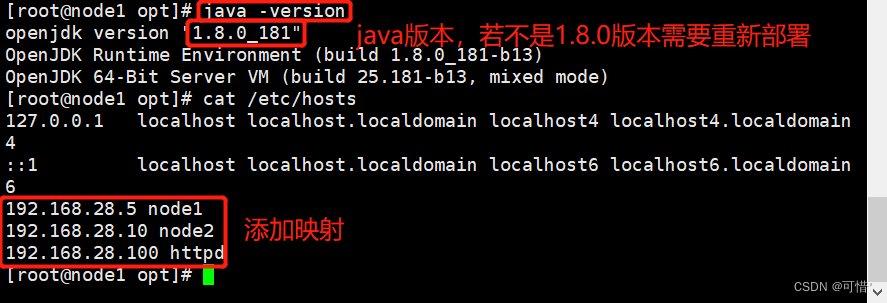
192.168.28.5 node1 #添加映射,配置域名解析
192.168.28.10 node2
192.168.28.100 httpd
[root@node1 ~]# java -version #查看java版本,部署1.8.0需要重新配置环境
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
[root@node1 opt]# rpm -ivh elasticsearch-5.5.0.rpm
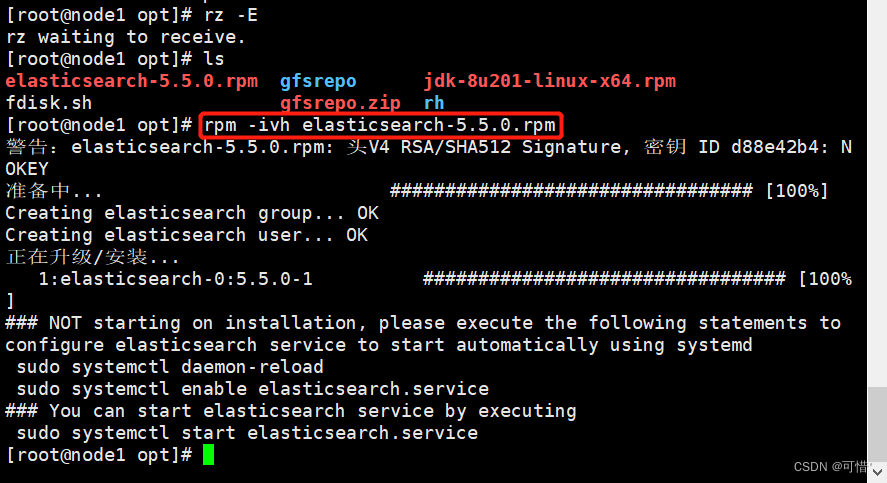
[root@node1 opt]# systemctl daemon-reload
[root@node1 opt]# systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
[root@node1 opt]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak #拷贝一份文件备份
[root@node1 opt]# vim /etc/elasticsearch/elasticsearch.yml
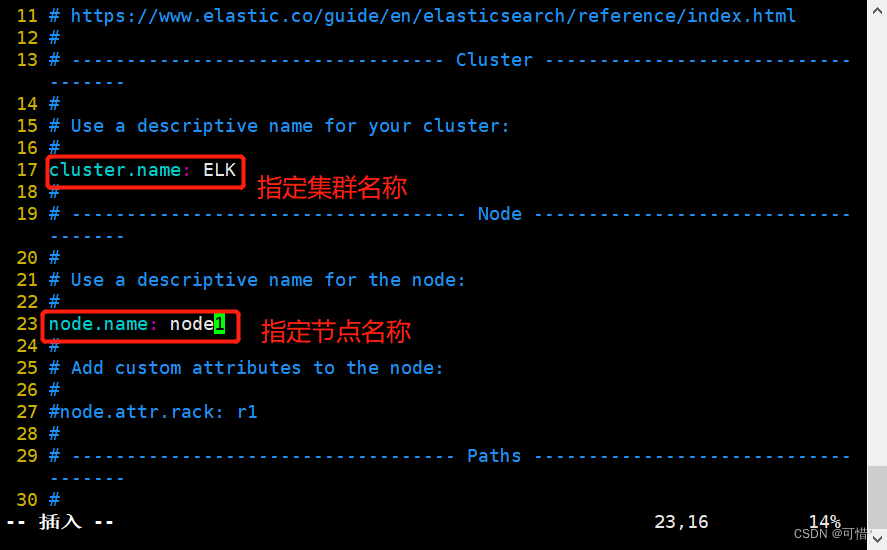
--17--取消注释,指定集群名字
cluster.name: ELK
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
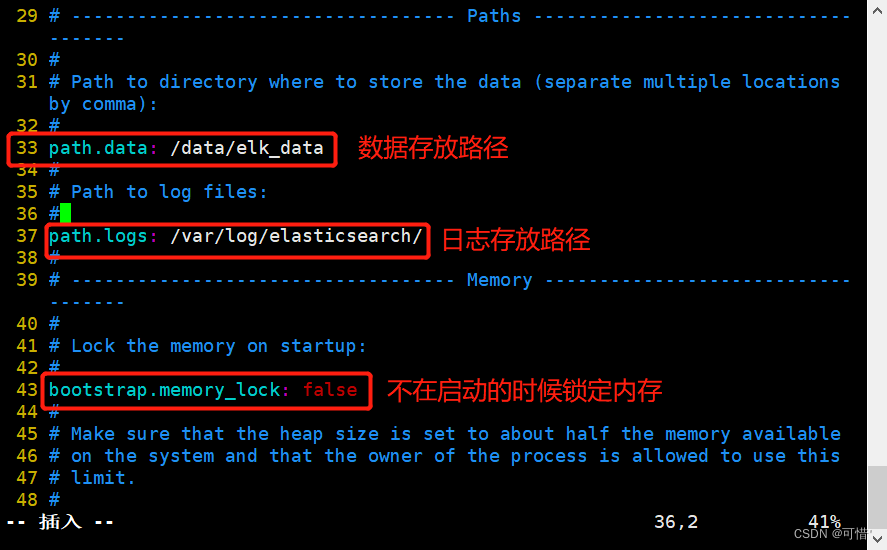
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
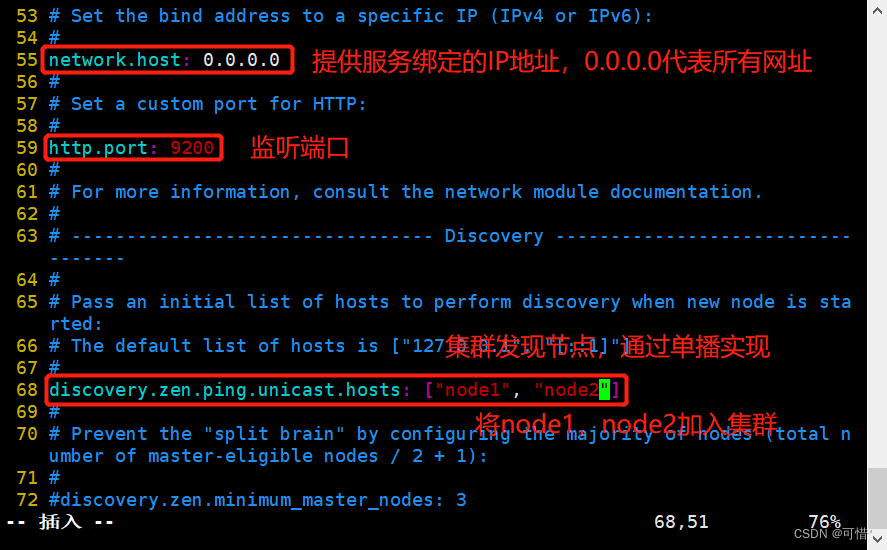
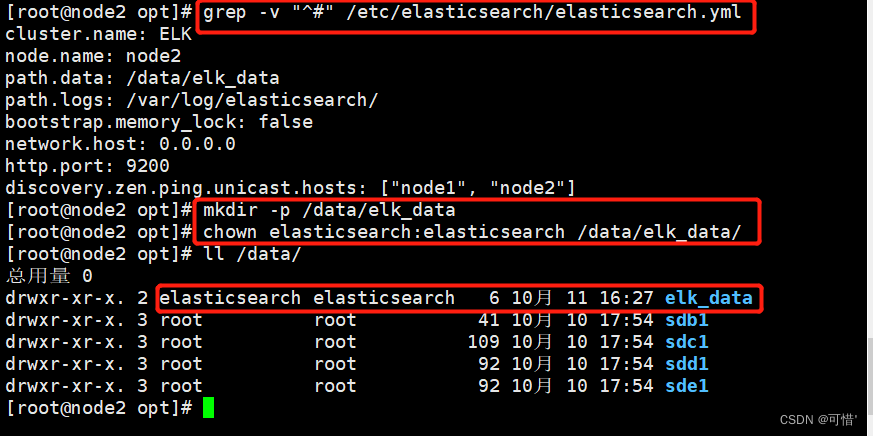
[root@node1 opt]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml ##查看一下有效的配置,注释全去掉
cluster.name: ELK
node.name: node1
path.data: /data/elk_data
path.logs: /var/log/elasticsearch/
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
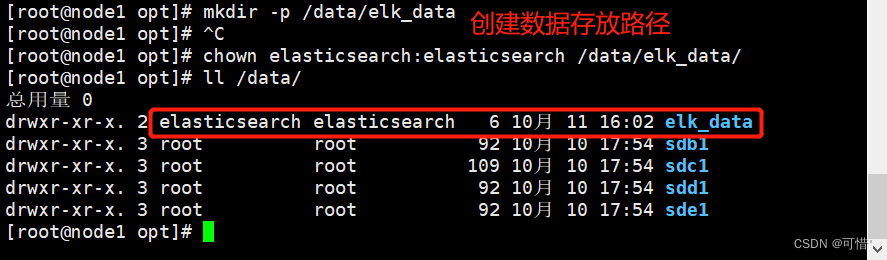
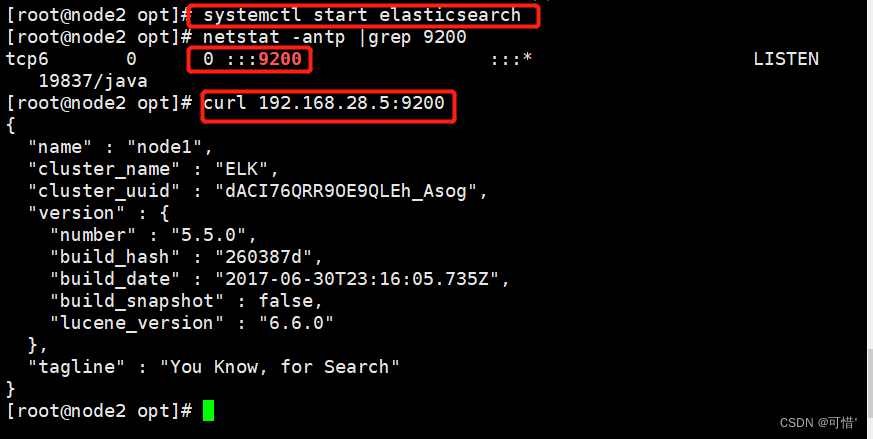
systemctl start elasticsearch
netstat -antp | grep 9200
systemctl enable --now elasticsearch.service #加入开机自启动,立即生效
netstat -antp | grep 9200
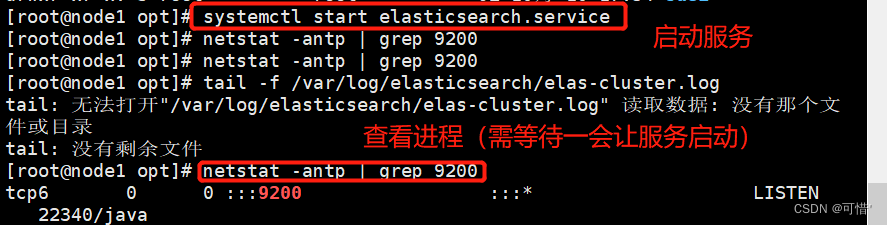
使用浏览器打开 http://192.168.28.5:9200 有文件打开 下面是节点的信息
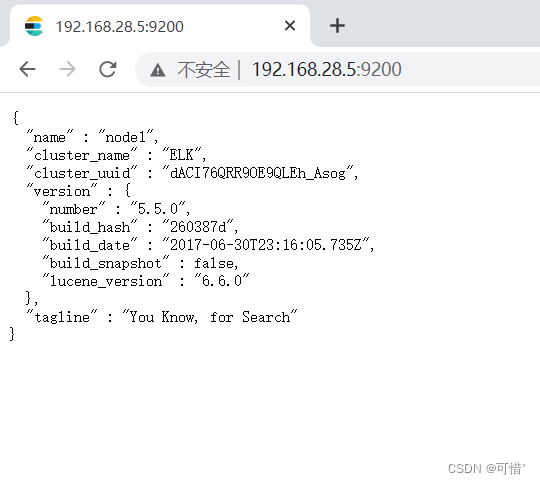
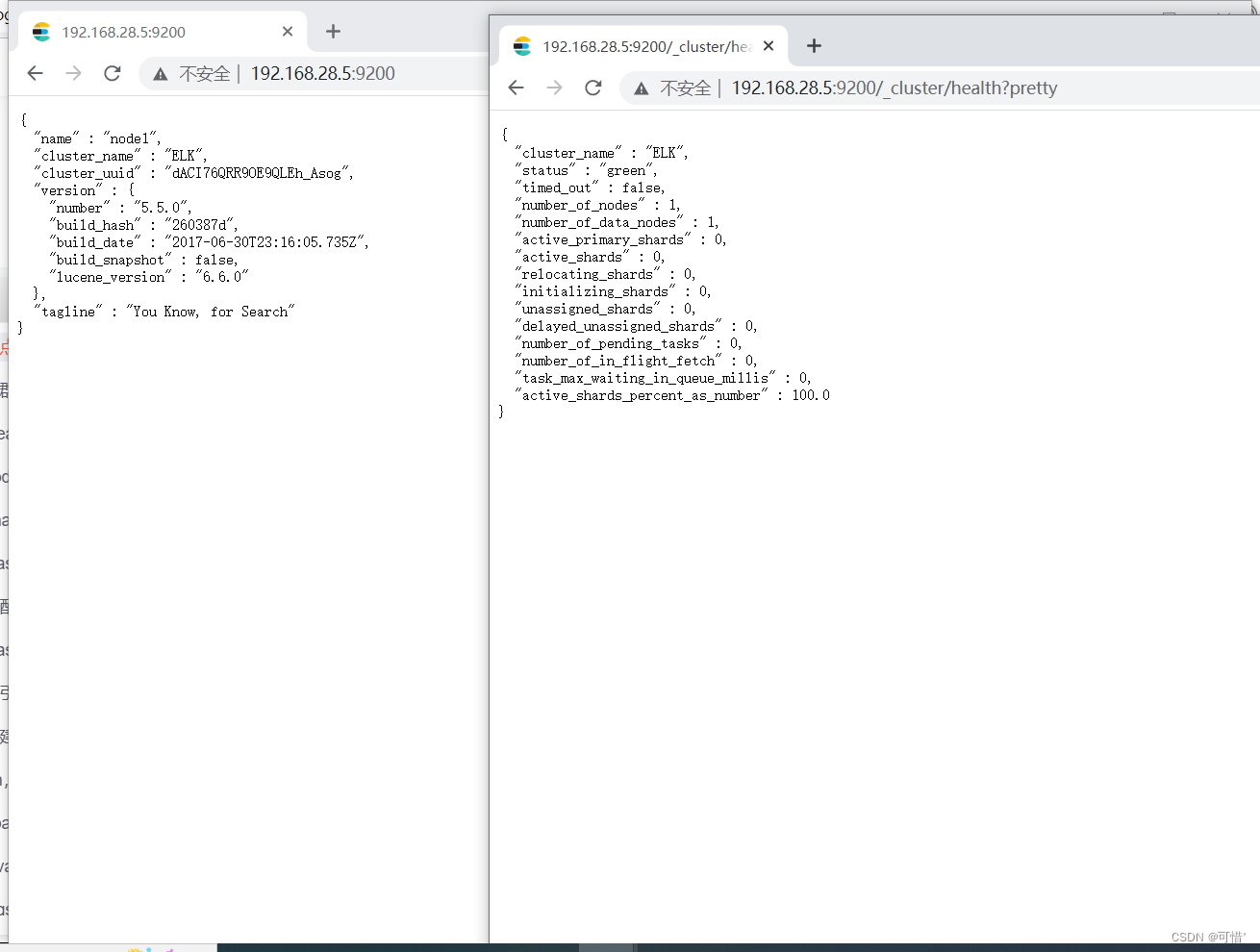
[root@node1 opt]# curl 192.168.28.5:9200 #查看节点信息
{
"name" : "node1",
"cluster_name" : "ELK",
"cluster_uuid" : "dACI76QRR9OE9QLEh_Asog",
"version" : {
"number" : "5.5.0",
"build_hash" : "260387d",
"build_date" : "2017-06-30T23:16:05.735Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
"tagline" : "You Know, for Search"
}
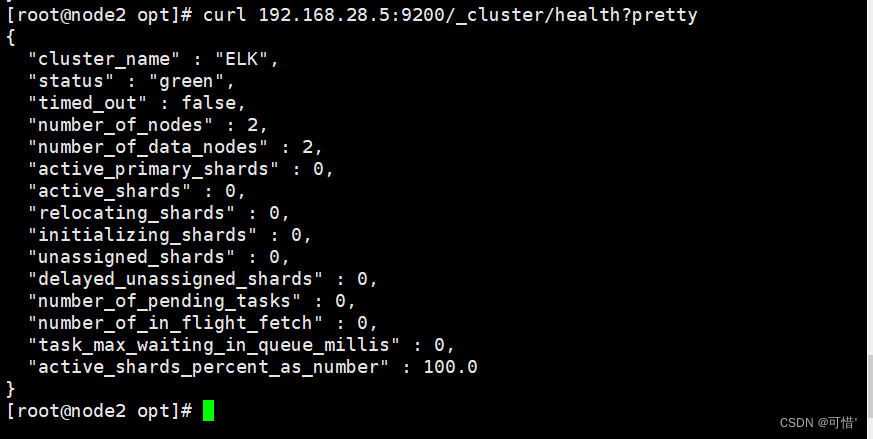
[root@node1 opt]# curl 192.168.28.5:9200/_cluster/health?pretty #查看集群信息
{
"cluster_name" : "ELK",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
步骤与node1节点一致,配置node2与node1一致,需要注意配置文件中的节点名
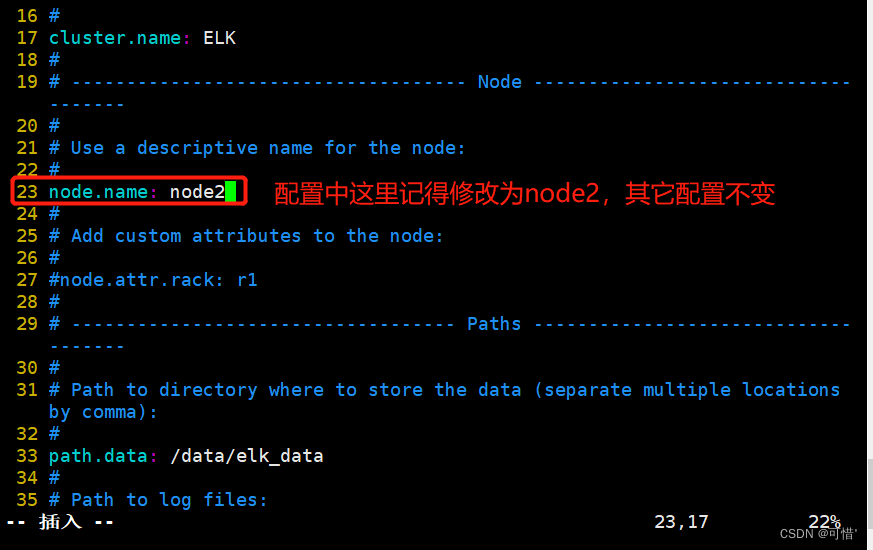
也可在node1节点上把配置文件上传到node2节点,然后修改node节点
scp elasticsearch.yml root@192.168.109.12:/etc/elasticsearch/
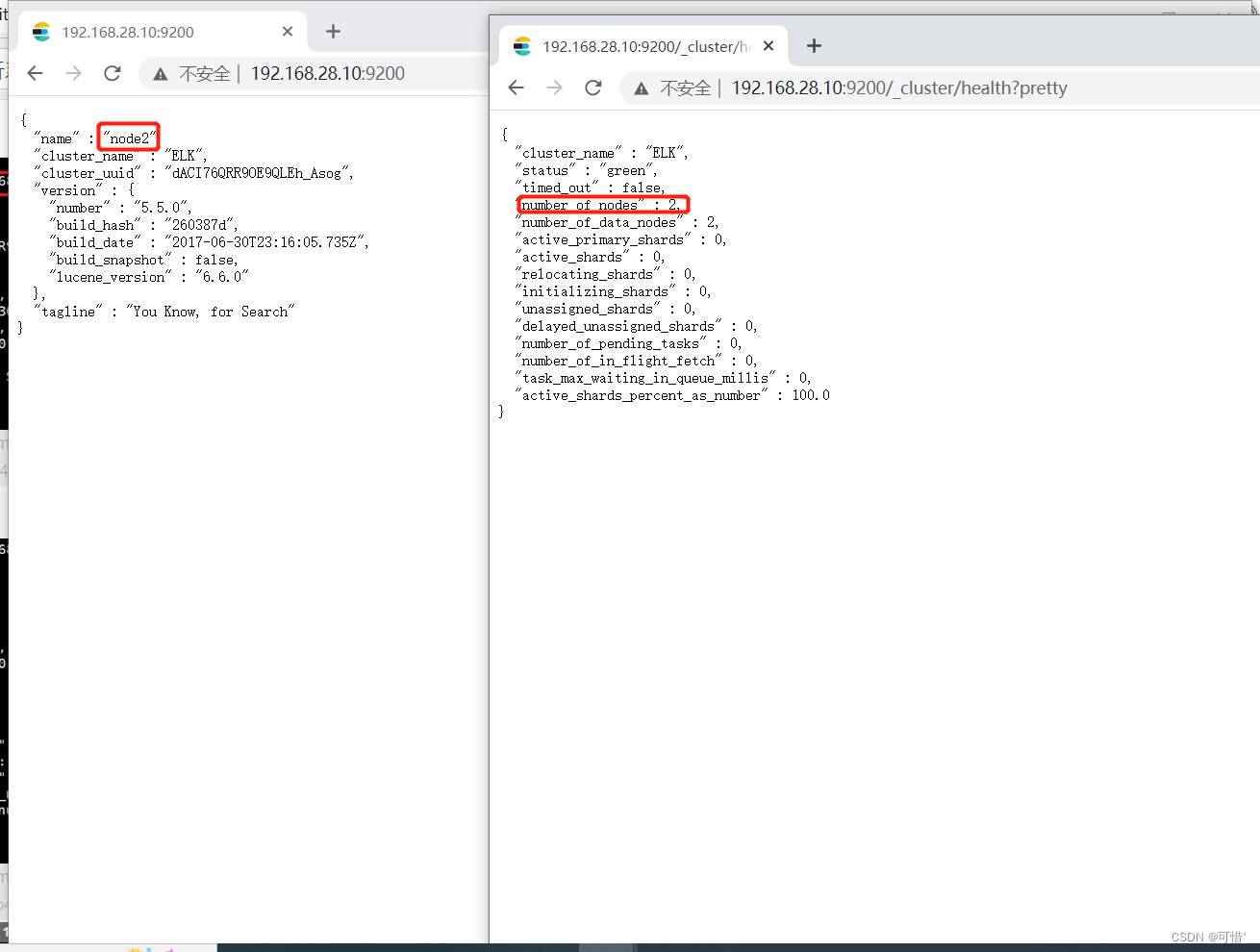
节点正常
上述查看集群的方式,及其不方便,我们可以通过安装elasticsearch-head插件后,来管理集群
-Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make && make install(./configure && make -j3 && make install)
安装过程非常缓慢,需要耐心
上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2到opt
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
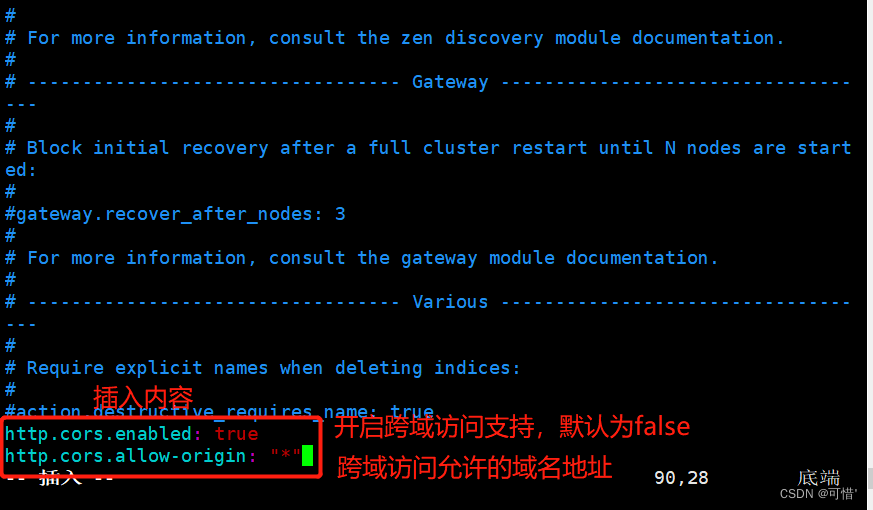
vim /etc/elasticsearch/elasticsearch.yml
--末尾添加以下内容--
http.cors.enabled: true ##开启跨域访问支持,默认为false
http.cors.allow-origin: "*" ## 跨域访问允许的域名地址
systemctl restart elasticsearch #修改完成后重启服务
[root@node1 elasticsearch-head]# vim /etc/elasticsearch/elasticsearch.yml
[root@node1 elasticsearch-head]# systemctl restart elasticsearch.service
cd /usr/local/src/elasticsearch-head/node_modules/grunt/bin
npm run start & #后台启动(
./grunt server #前台启动)
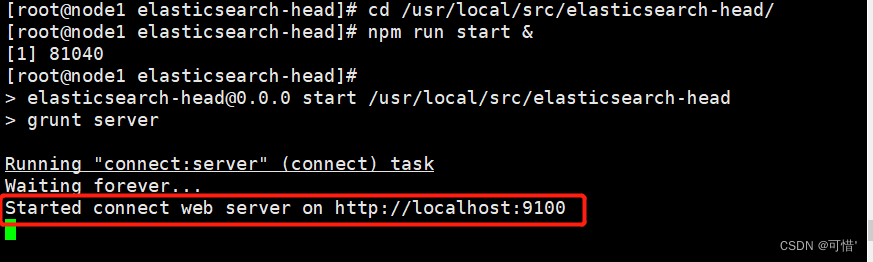
浏览器访问 http://192.168.28.5:9100/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。
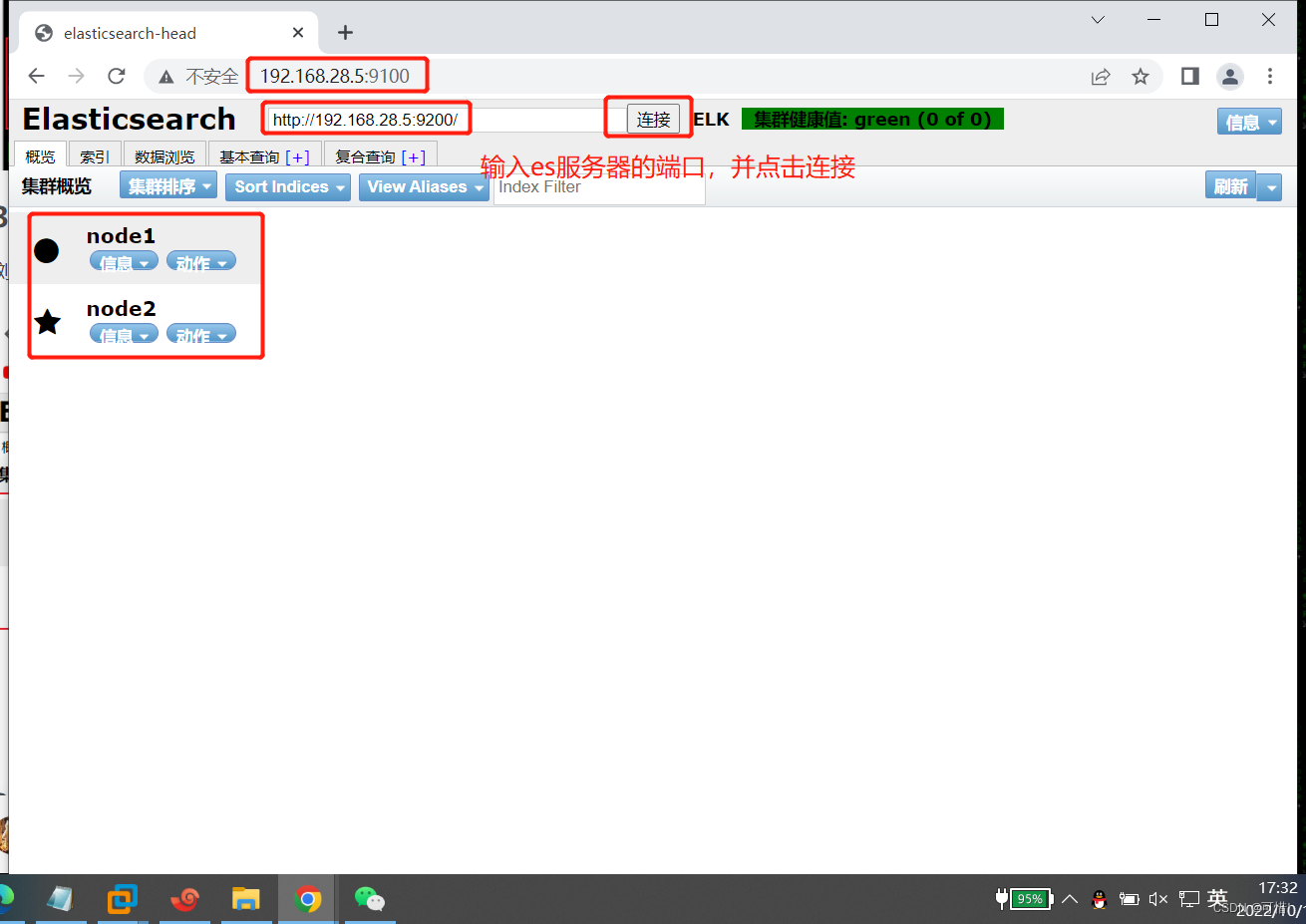
#node1节点插入
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"lcdb","mesg":"lichen youshoujiuxing"}'
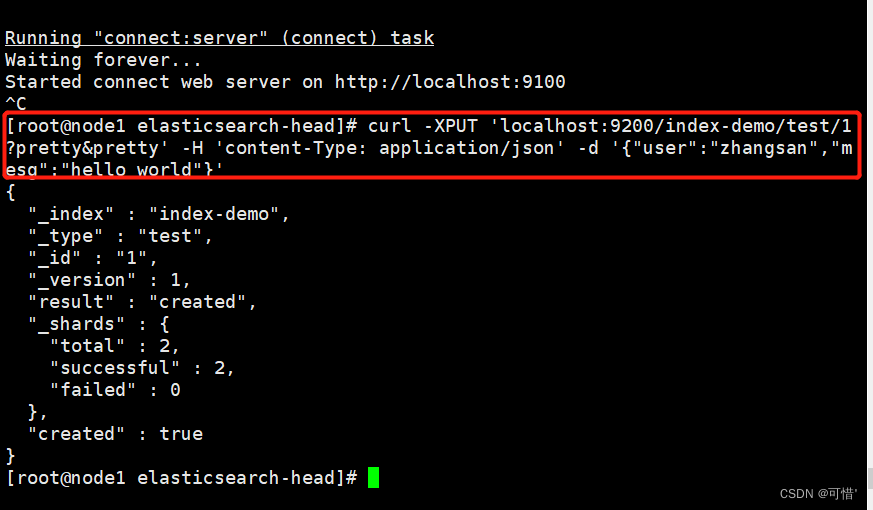
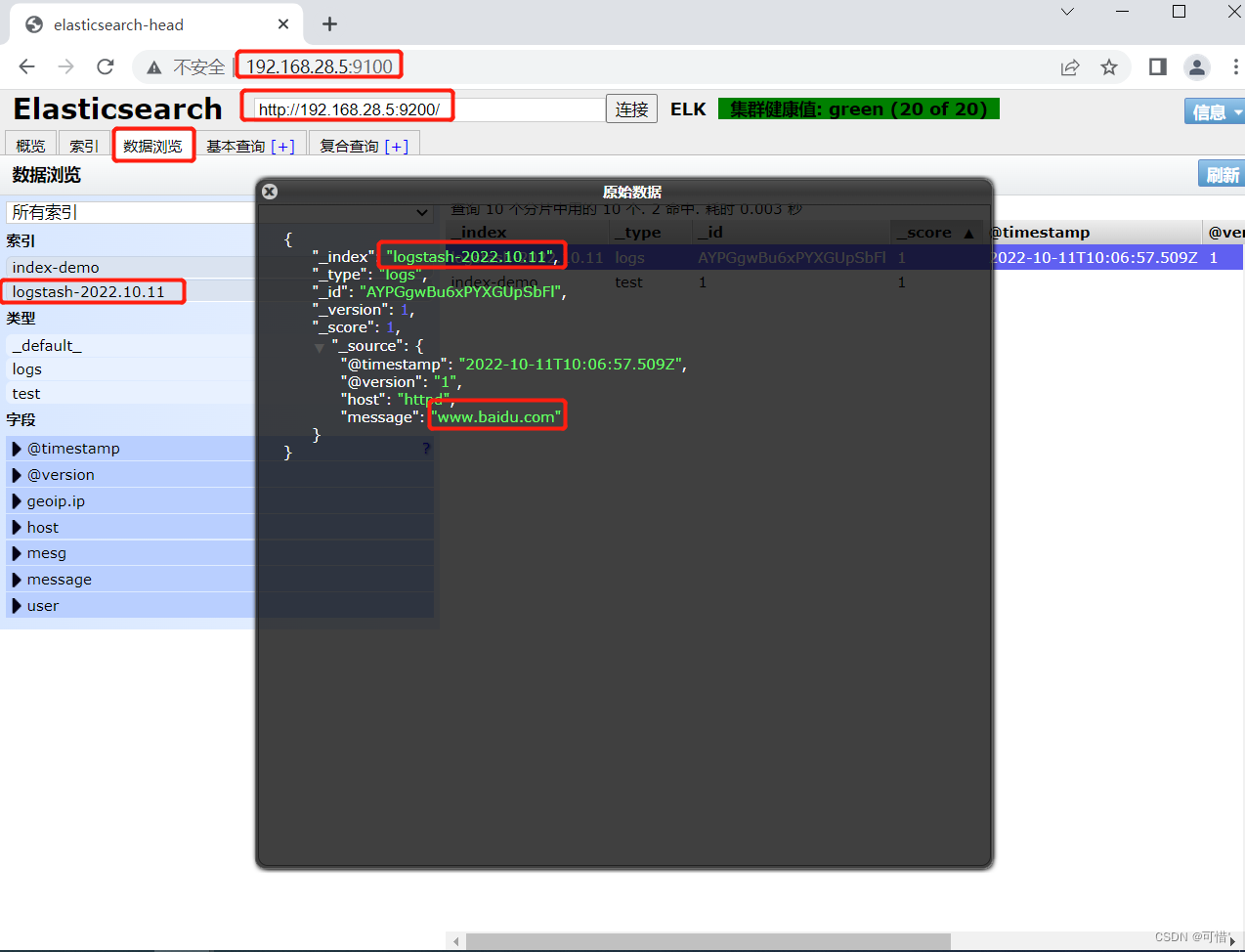
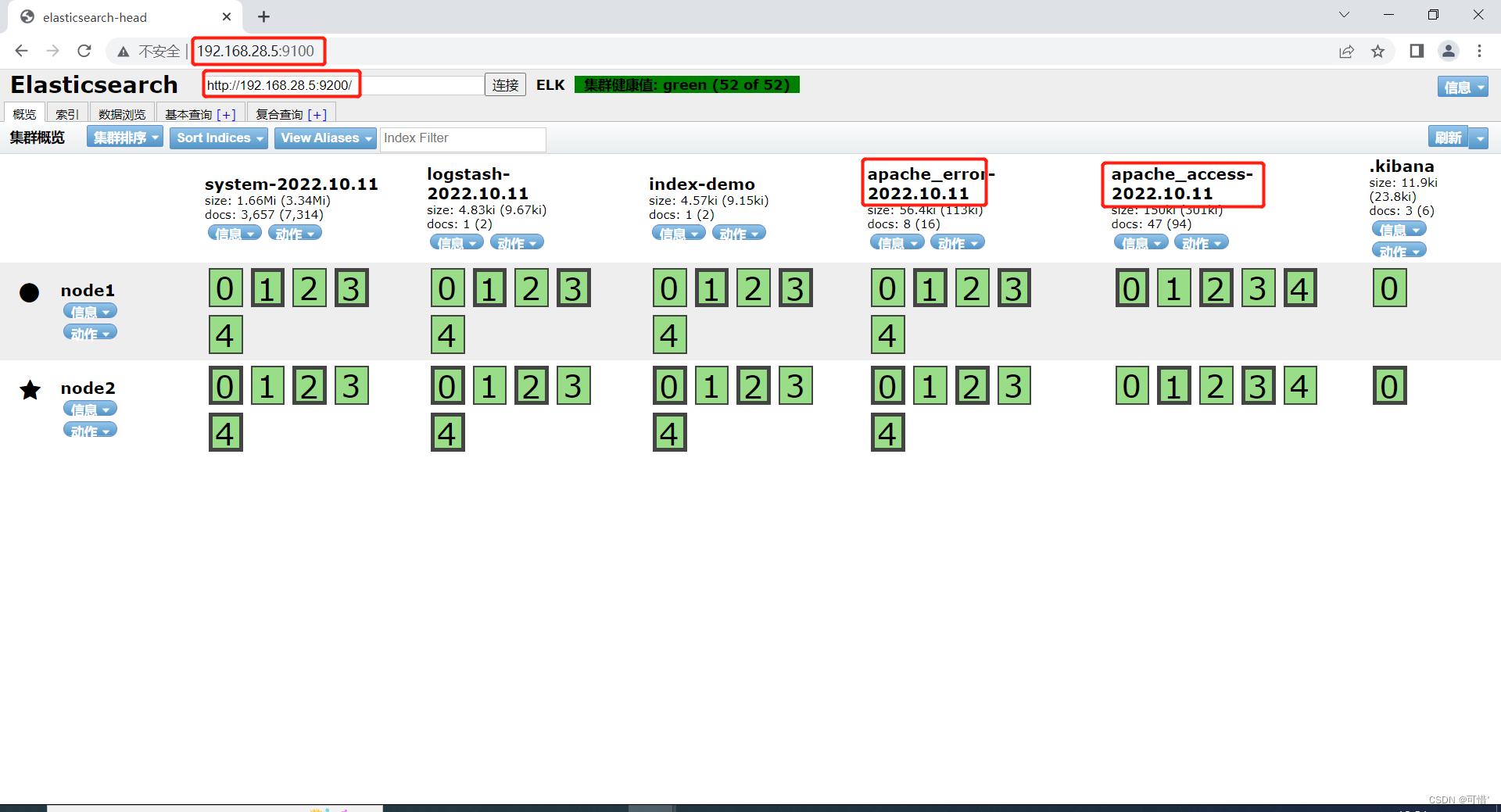
浏览器访问 http://192.168.28.5:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。
点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。
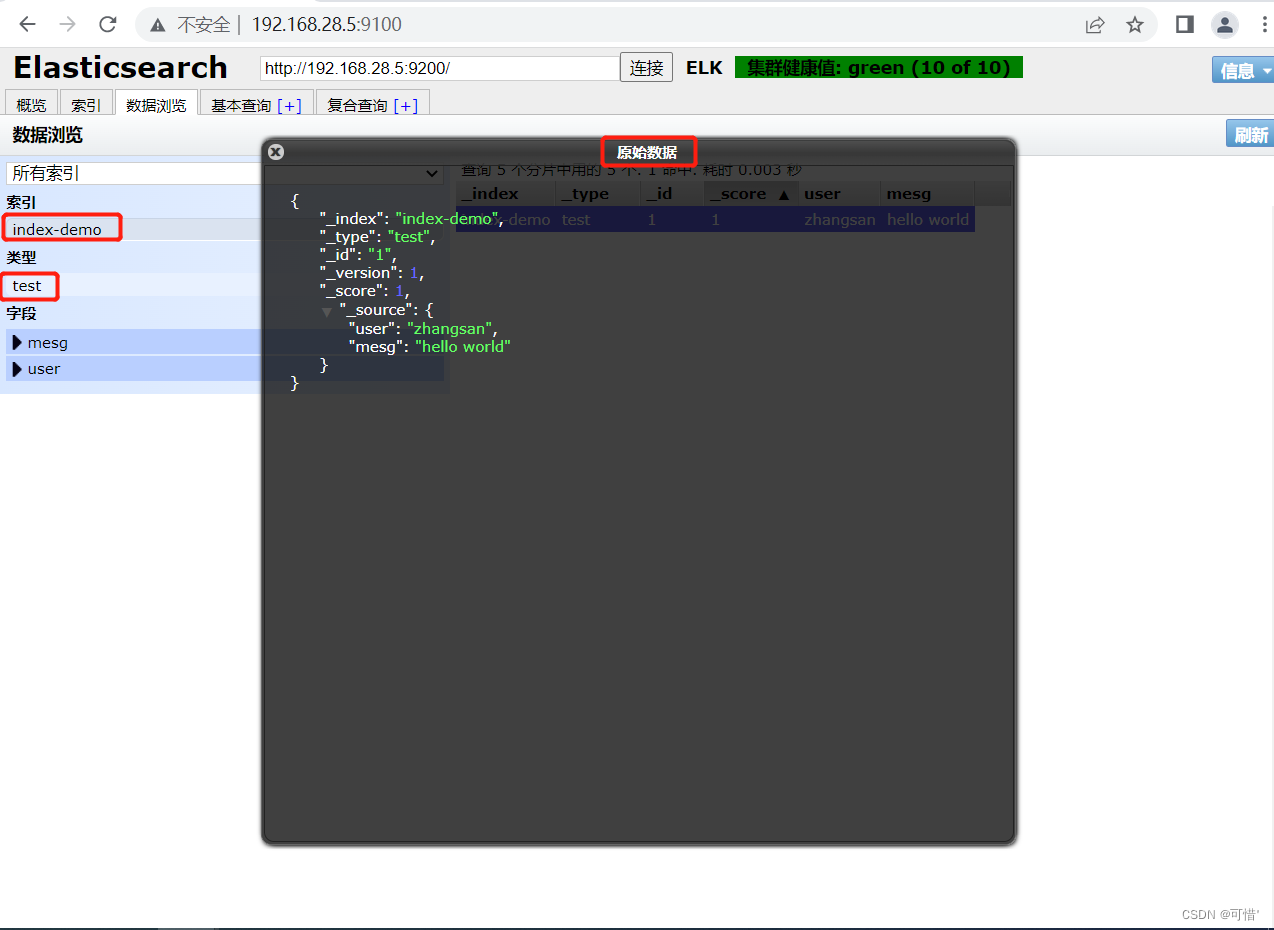
上面图可以看见索引默认被分片5个,并且有一个副本
安装logstash并做一些日志搜集输出到elasticsearch中
下载地址:https://www.elastic.co/cn/downloads/past-releases/logstash-5-5-1
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
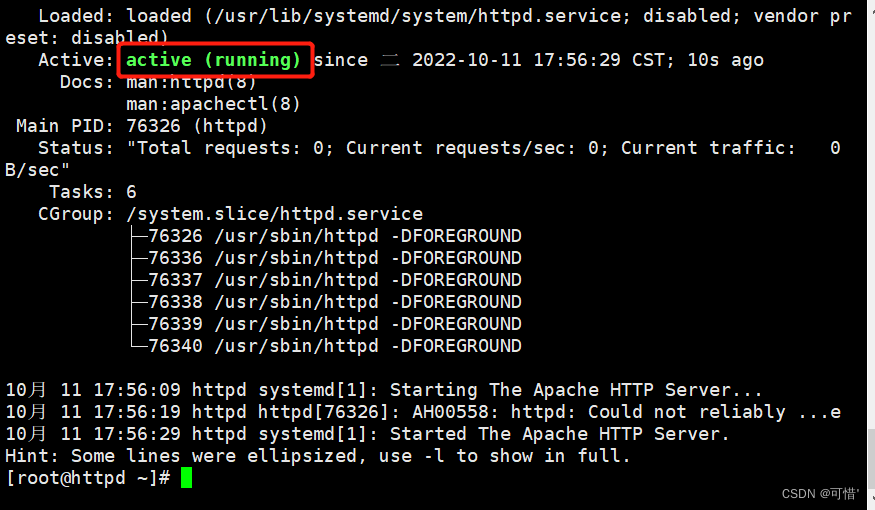
yum -y install httpd
systemctl start httpd
java -version

cd /opt
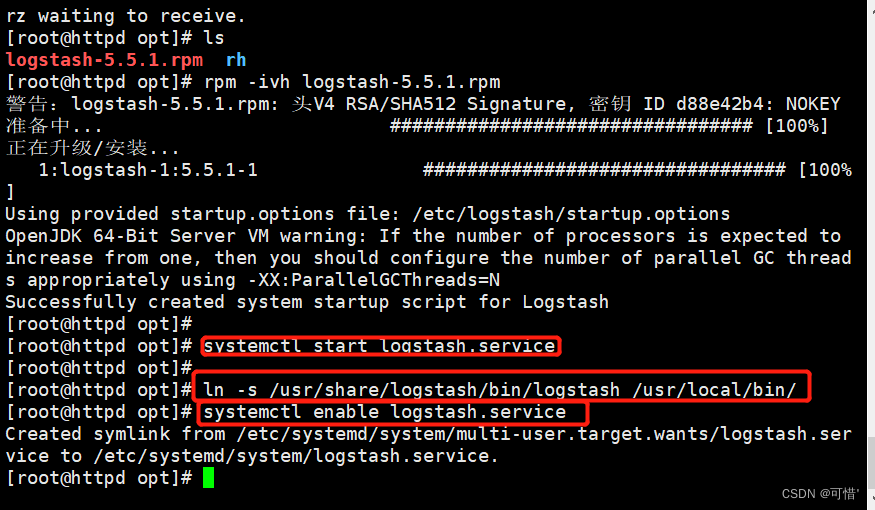
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。
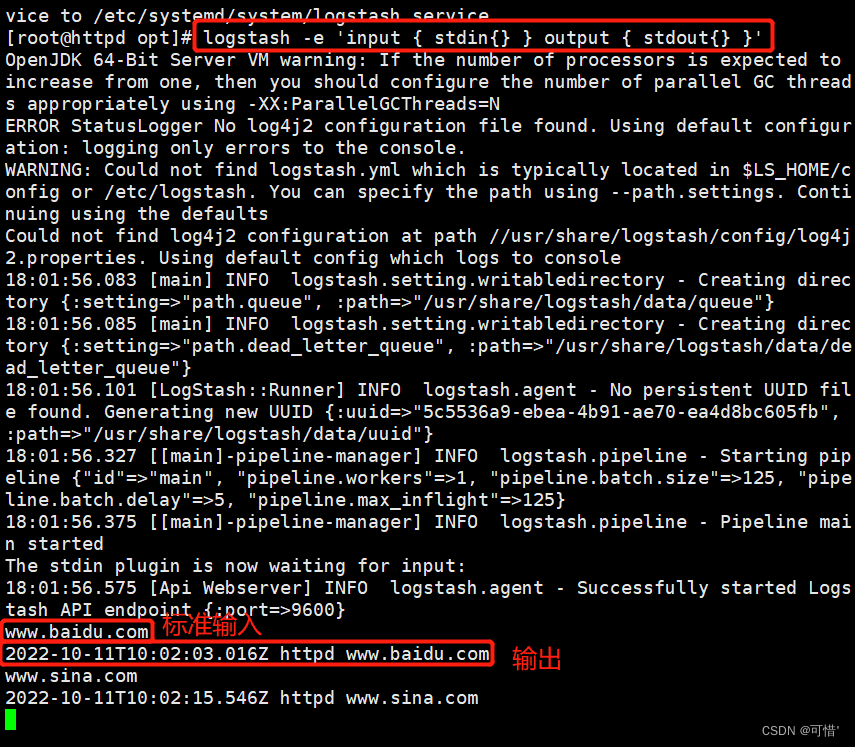
输入采用标准输入,输出采用标准输出(类似管道)
指定数据输入端口,默认为9600~9700
logstash -e 'input { stdin{} } output { stdout{} }'
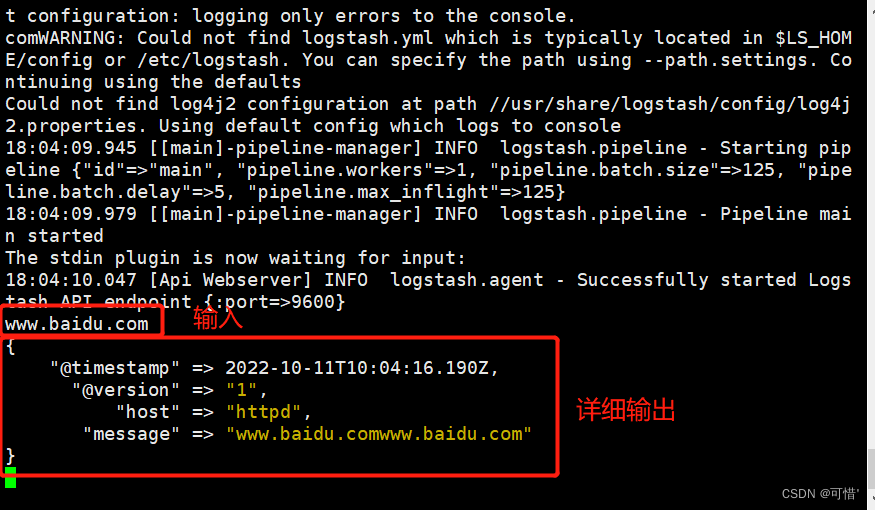
codec为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
使用Logstash将信息写入Elasticsearch中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.28.5:9200"] } }'
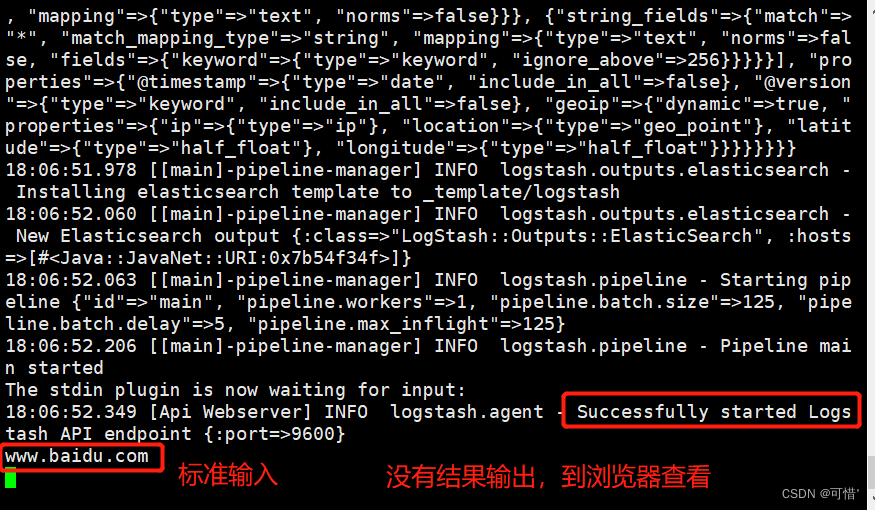
结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.28.5:9100/ 查看索引信息和数据浏览。
Logstash 配置文件基本由三部分组成(根据需要选择使用)
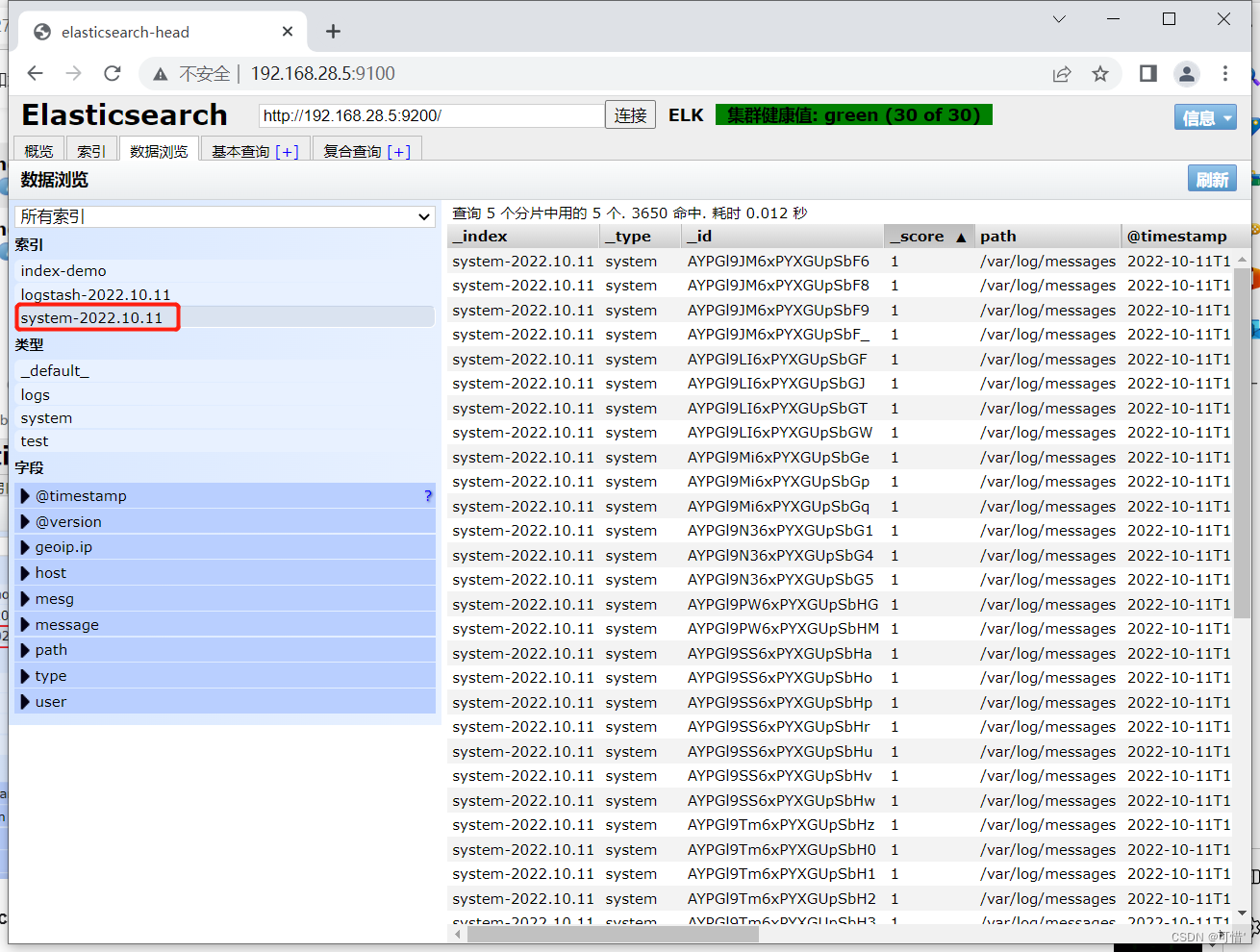
修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中

#创建配置文件
vim /etc/logstash/conf.d/syslog.conf
input {
file{
path =>"/var/log/messages" #指定收集数据的路径
type =>"system" #自定义日志类型标识
start_position =>"beginning" #标识从开头收集数据
}
}
output {
elasticsearch { #输出到elasticsearch
hosts => ["192.168.28.5:9200"] #指定elasticsearch的IP和端口
index =>"system-%{+YYYY.MM.dd}" #指定输出到elasticsearch的索引格式
}
}
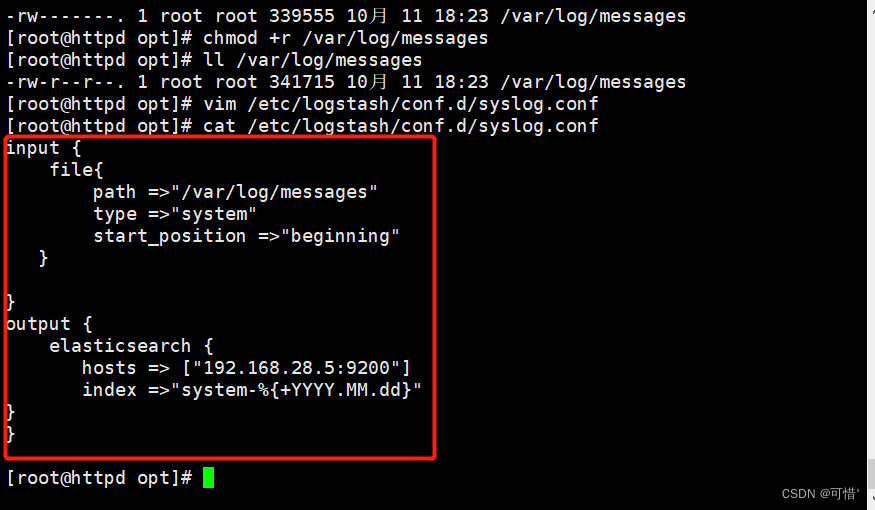
systemctl restart logstash #重启服务
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-5-5-1
cd /opt
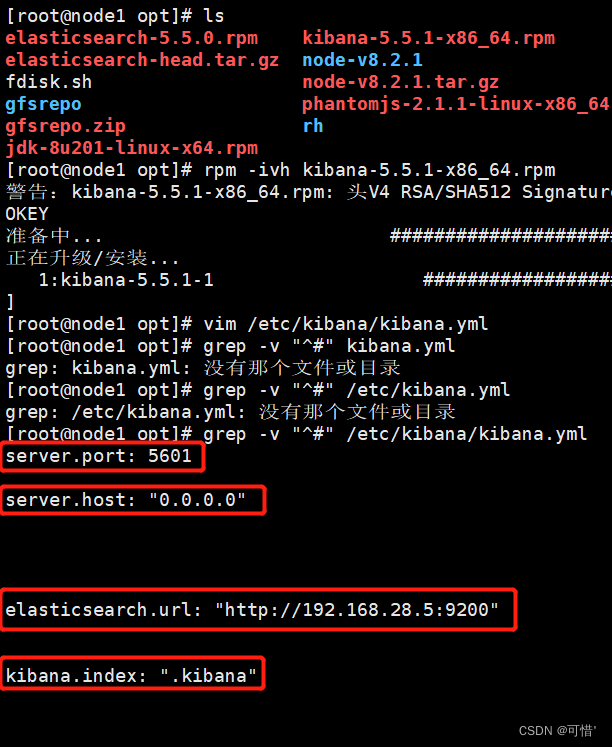
rpm -ivh kibana-5.5.1-x86_64.rpm
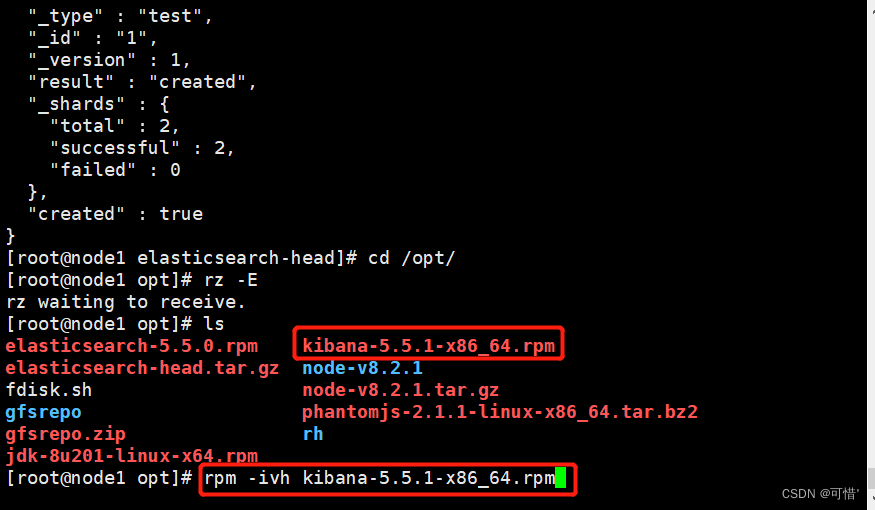
vim /etc/kibana/kibana.yml
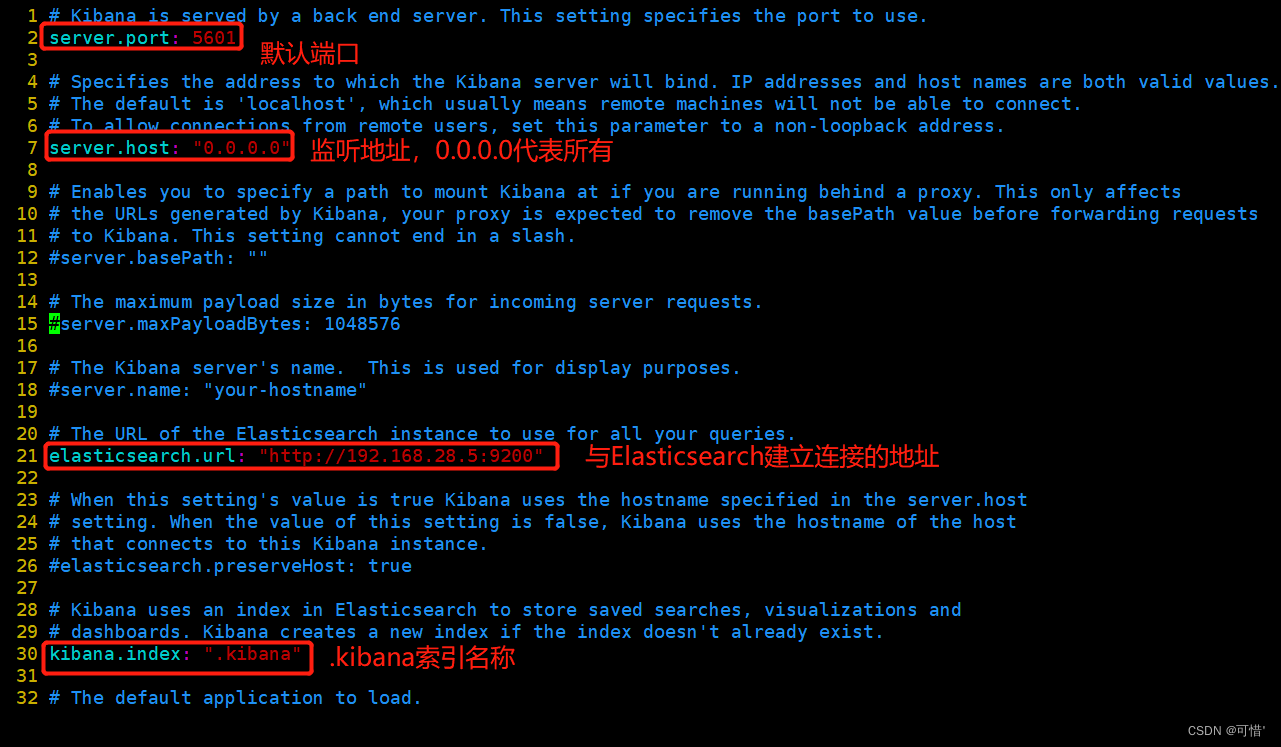
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.28.5:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
systemctl daemon-reload
systemctl start kibana.service
systemctl enable kibana.service
netstat -antp | grep 5601
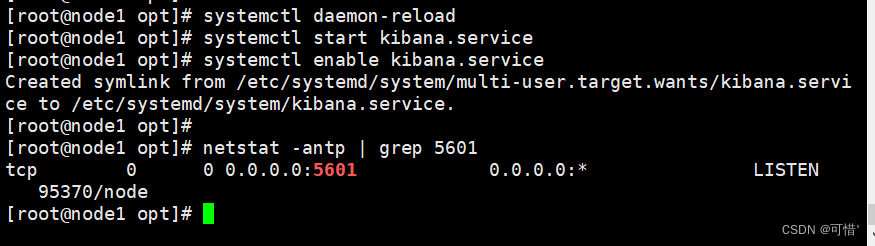
浏览器访问:http://192.168.28.5:5601
点击创建
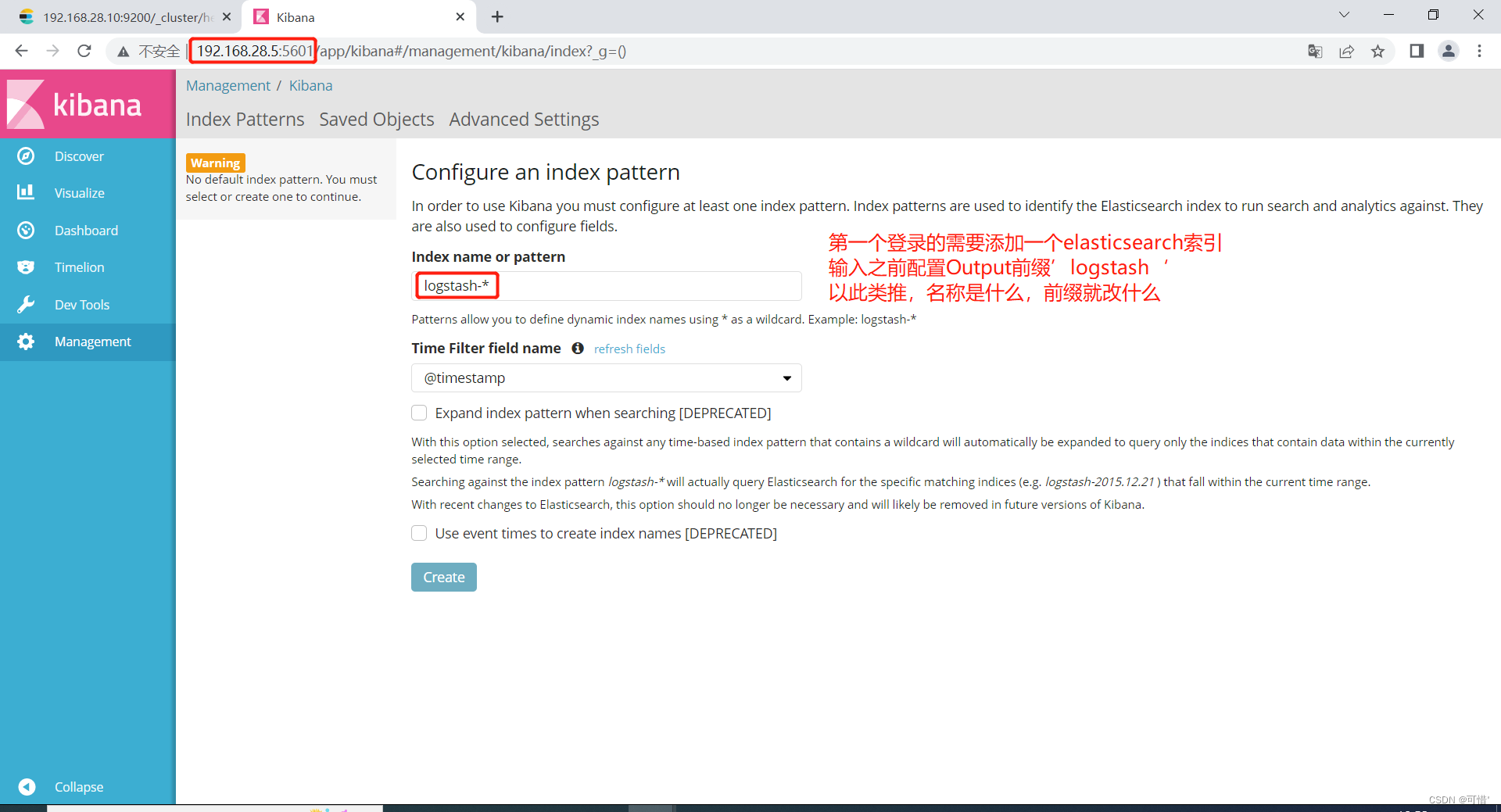
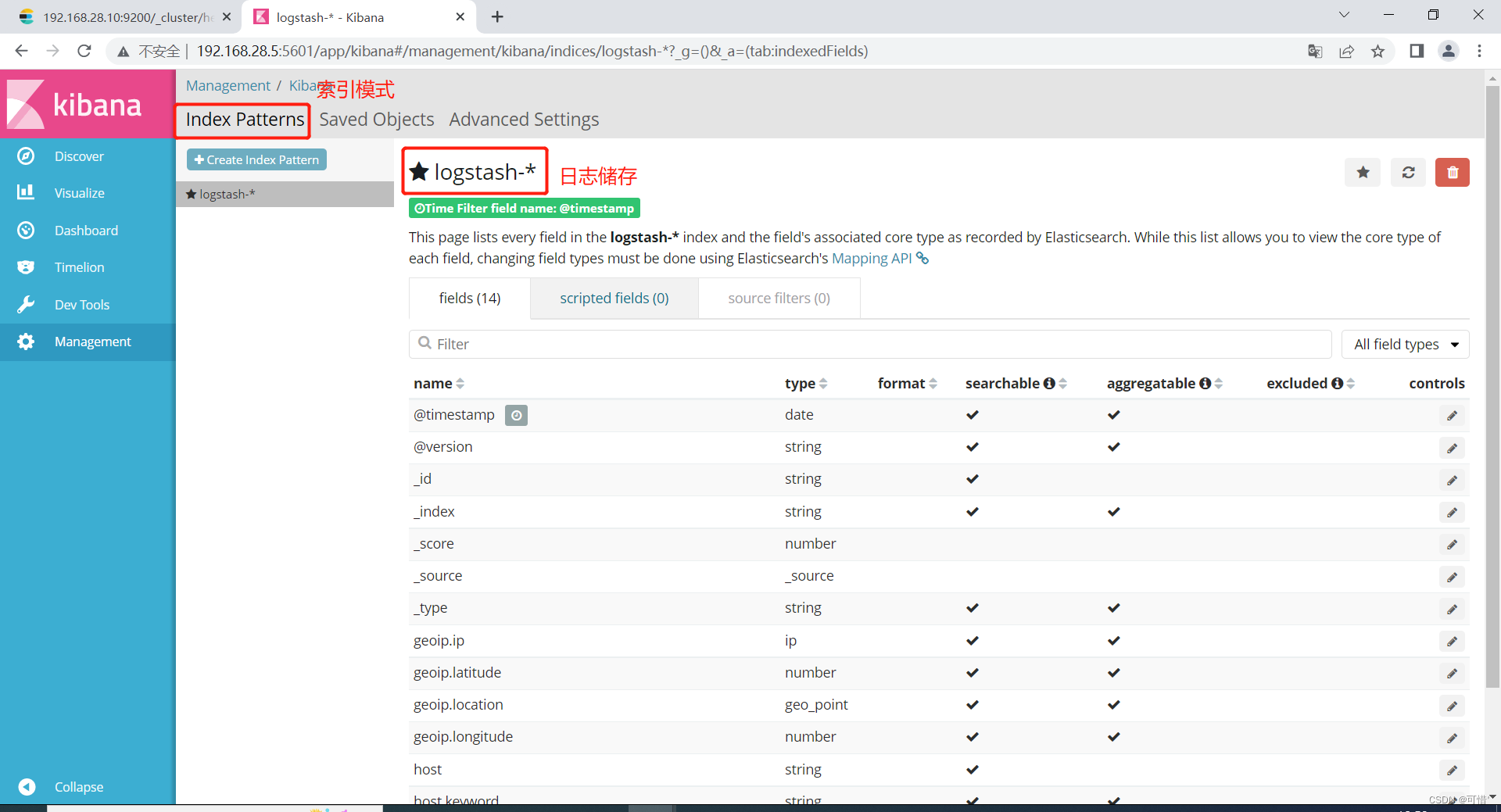
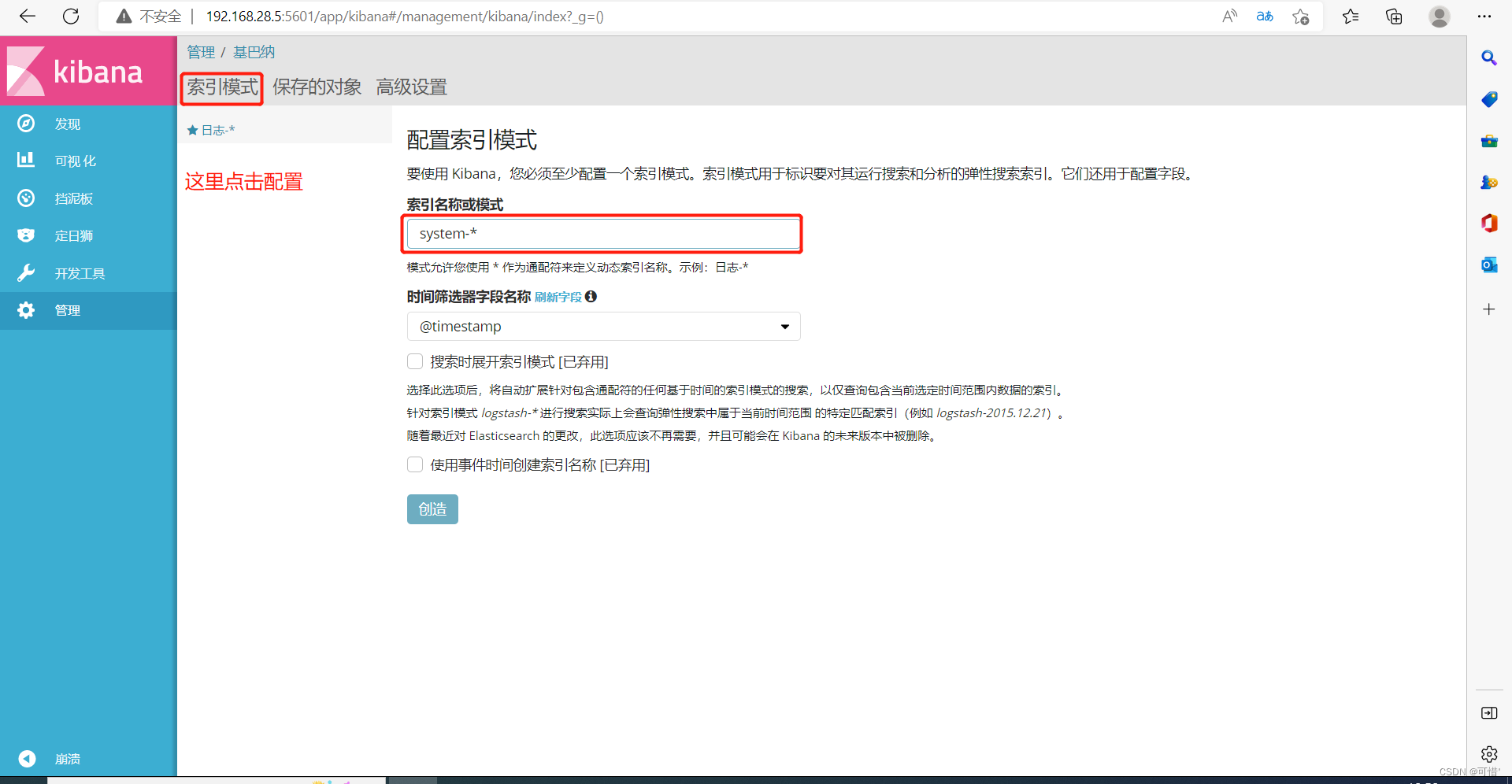
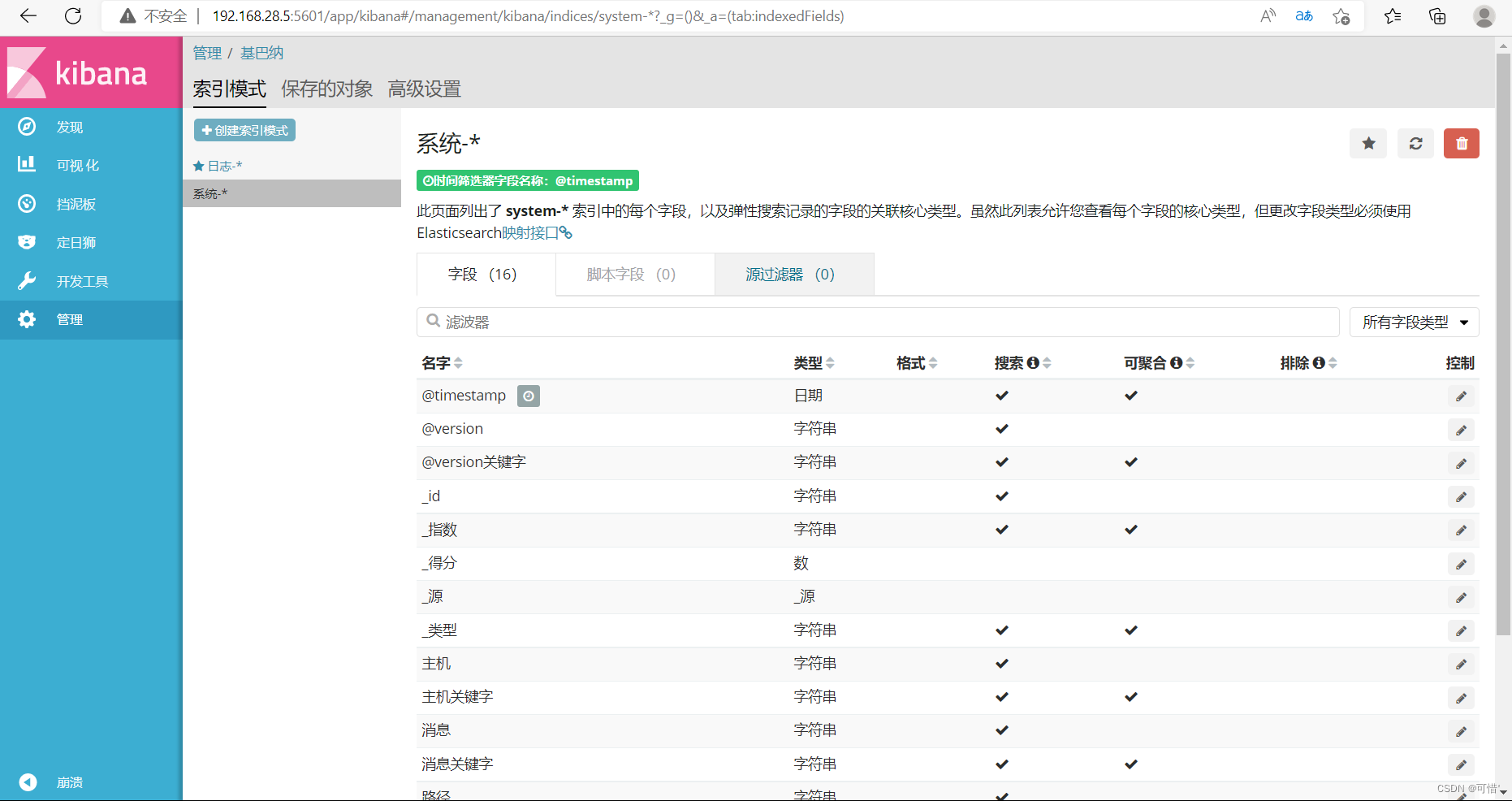
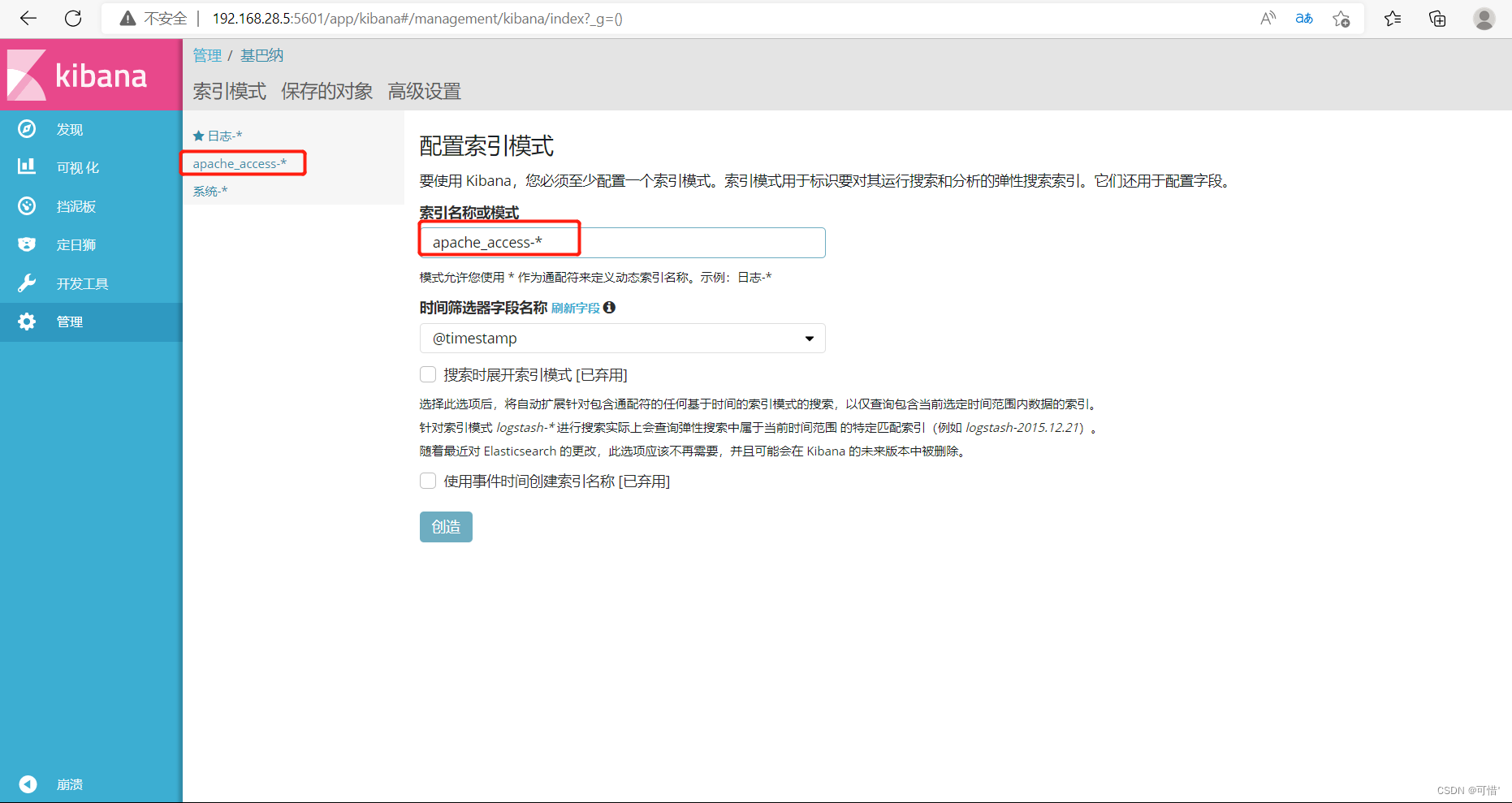
我们先前添加了system的日志,这里可以添加system的索引,点击创造

将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
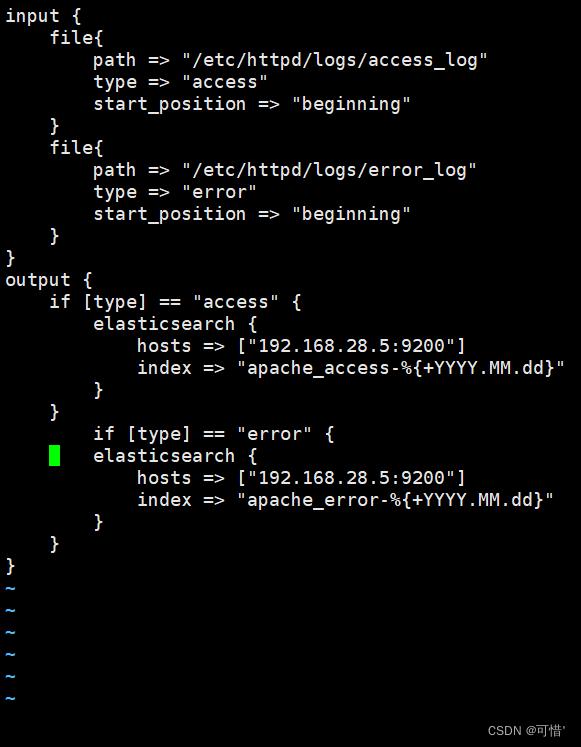
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log" #apahe服务的访问日志
type => "access" #访问日志
start_position => "beginning" #从头开始
}
file{
path => "/etc/httpd/logs/error_log" #apache服务的错误日志路径
type => "error" #错误日志
start_position => "beginning" #开始位置:从头开始
}
}
output {
if [type] == "access" { #判断类型为访问日志
elasticsearch {
hosts => ["192.168.28.5:9200"] #指定与es连接的ip和端口
index => "apache_access-%{+YYYY.MM.dd}" #索引为apache_access的日志
}
}
if [type] == "error" { #判断类型为错误日志
elasticsearch {
hosts => ["192.168.28.5:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf #开启logstash,指定logstash的配置文件
访问apache(192.168.28.100),增加日志
浏览器访问 http://192.168.28.5:9100 查看索引是否创建
/usr/share/logstash/bin/logstash -f apache.conf #xx
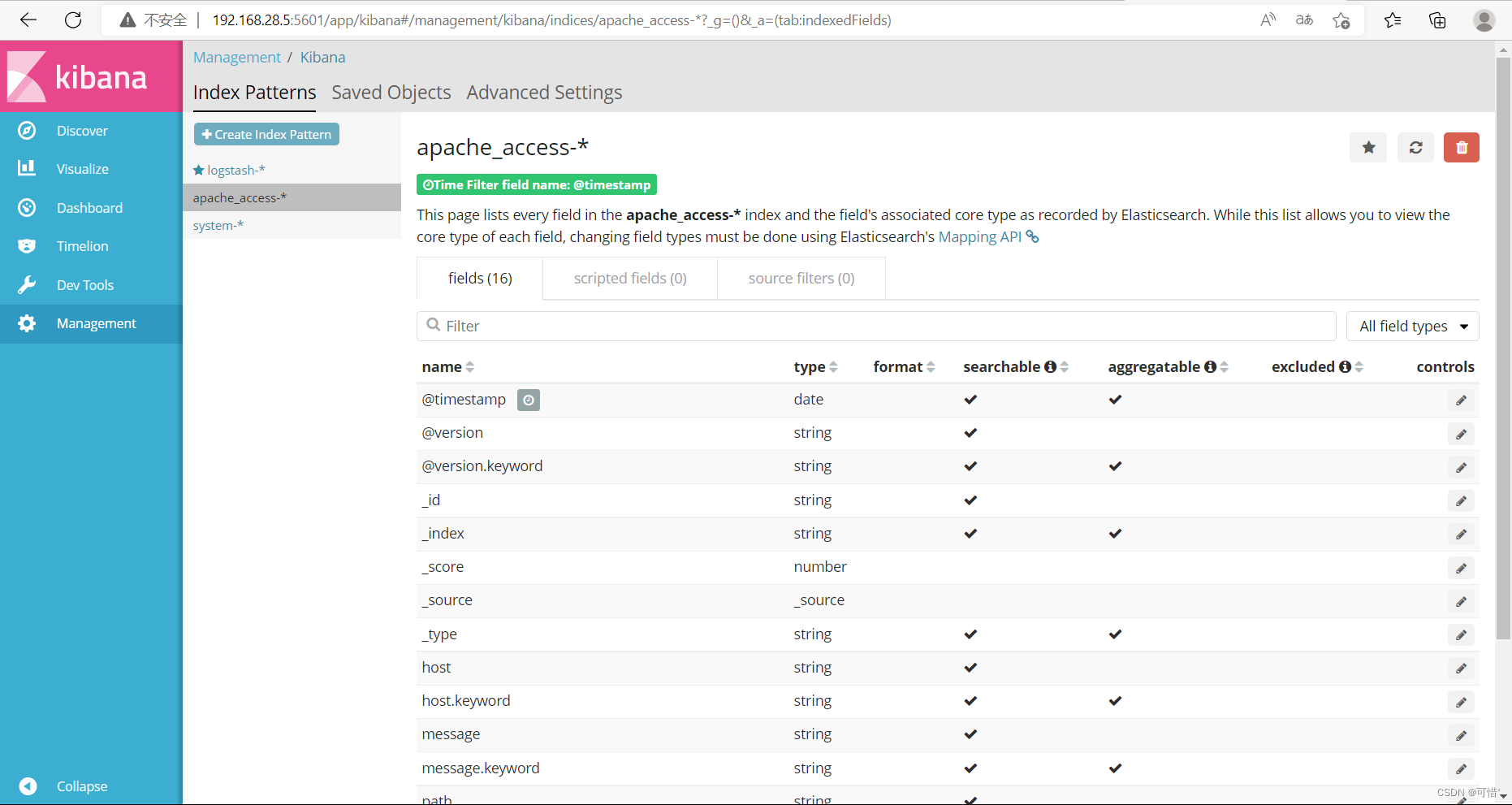
再去discover上查看日志
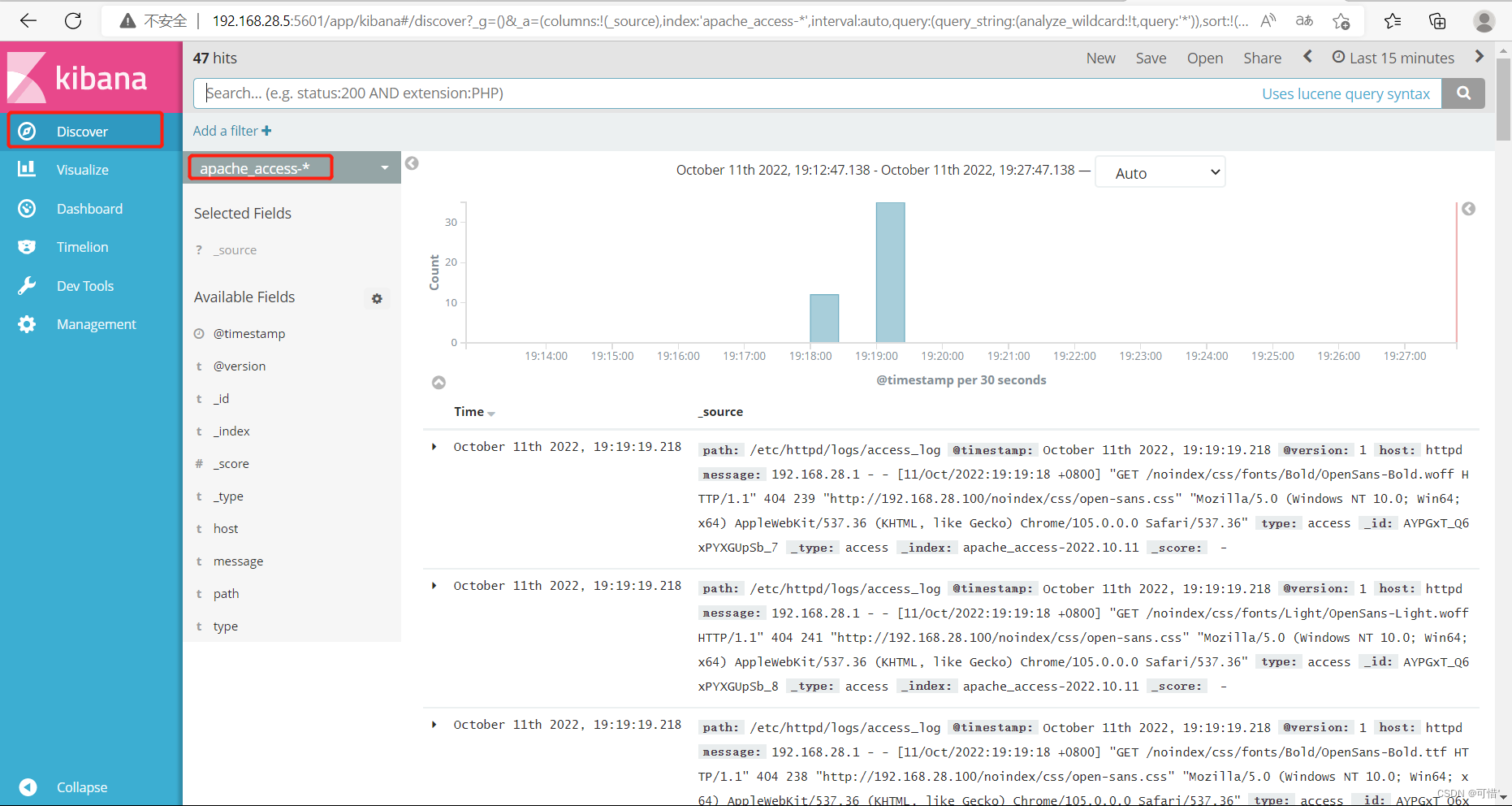
错误日志
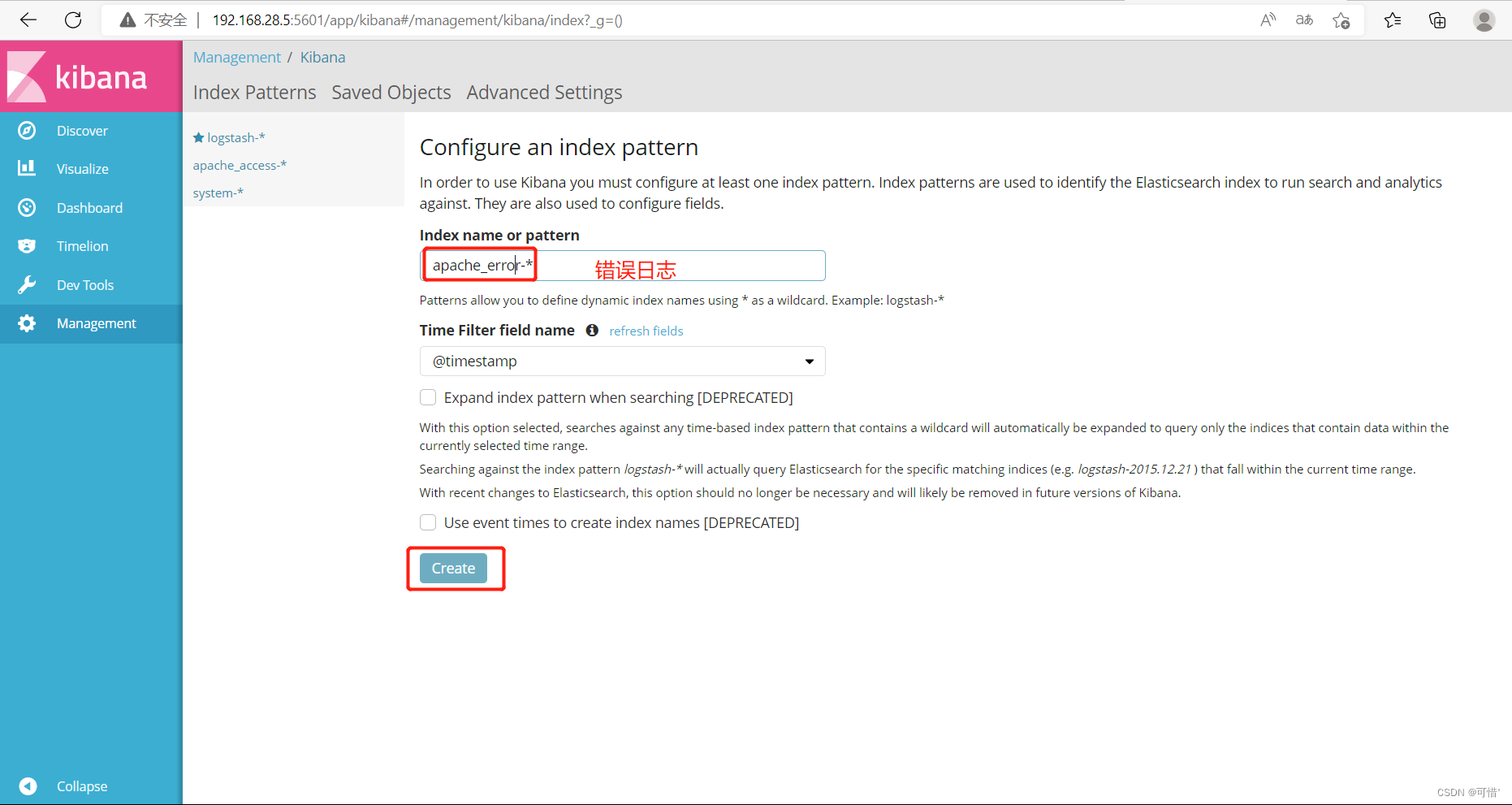
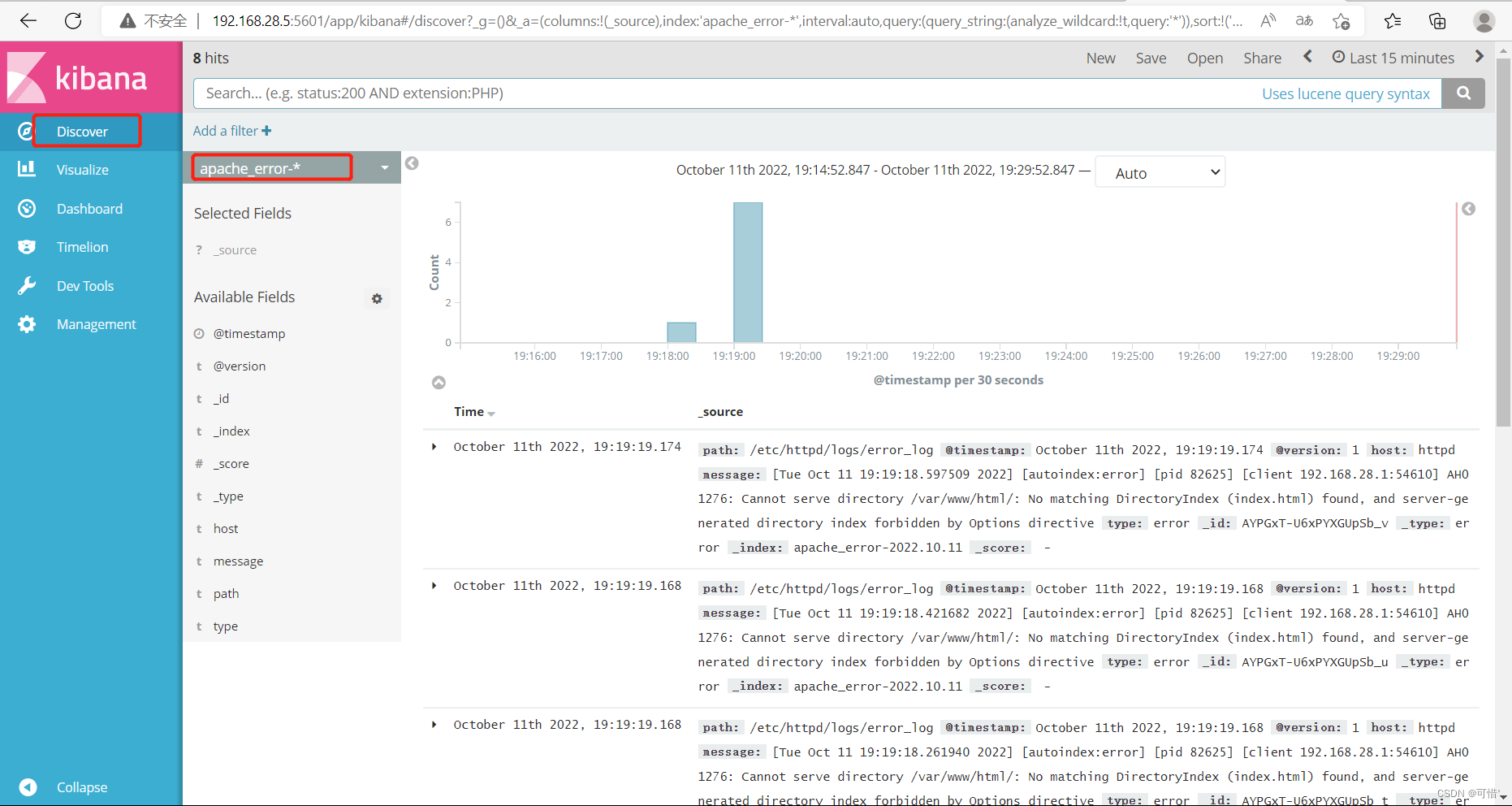
然后在宿主机上刷新访问,会刷新日志,可以在kibana查看时间
日志处理步骤
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题: