一,概述
二,数据类型
三,分词器
四,Node节点类型
五,分片 Shard
六,节点分片示意图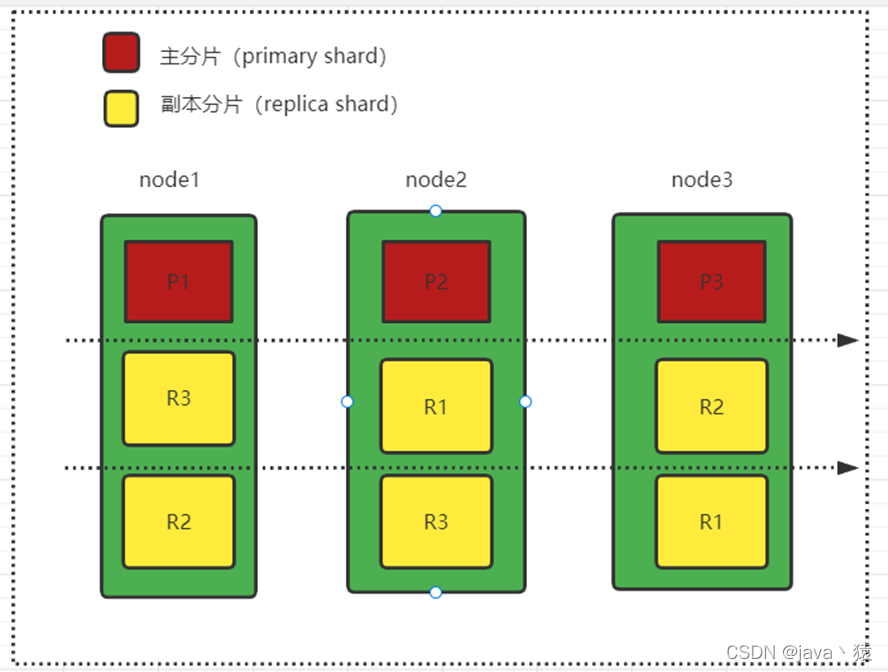
七,分段 Segment
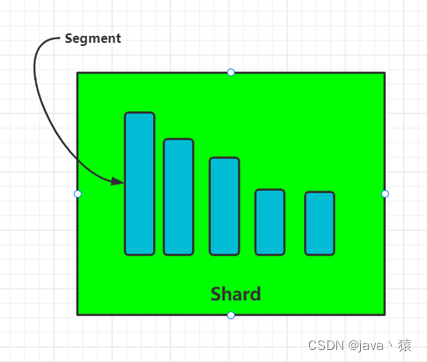
八,基于Segment数据读写,更新过程
九,倒排索引数据结构
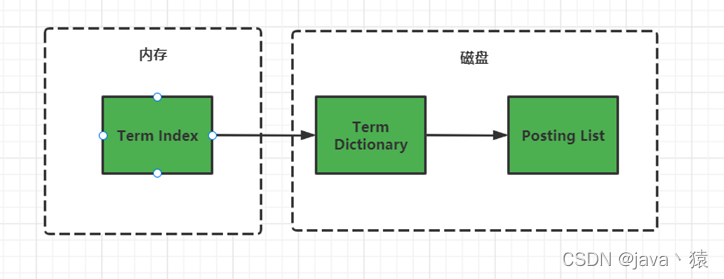
十,倒排索引

十一,整体结构示意图

十二,单词查找过程
通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找,确定term的在磁盘中的位置,找到单词对应的倒排项。
注:term index是通过FST (Finite State Transducer)的压缩技术进行压缩,保证term index可以被缓存到内存中,减少磁盘IO,提高效率。
FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。

十三,ES数据写入过程

十四,ES数据读取数据过程-查询阶段

十五,ES数据读取数据过程-取回阶段
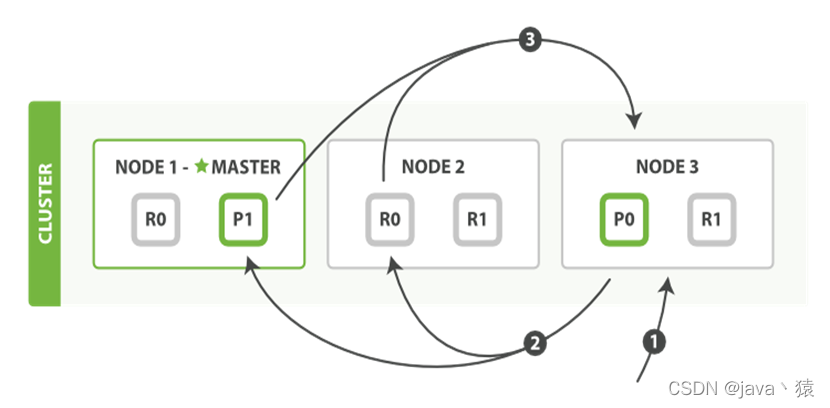
十六,ES数据存储过程
1,一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog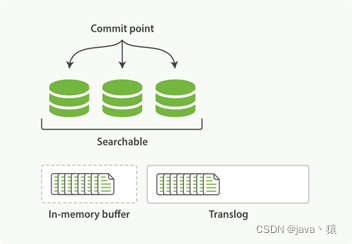
2,分片每秒执行一次refersh,这些在内存缓冲区的文档被写入到一个新的segment中,
segment被打开,文档可被索引到,同时清空内存buffer
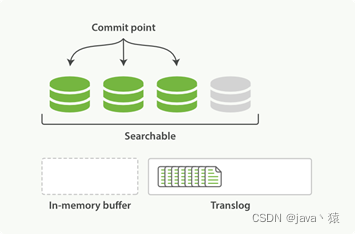
3,这个进程继续工作,更多的文档被添加到内存缓冲区和追加到translog
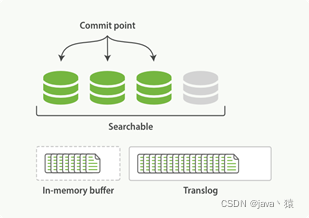
4,每间隔一段时间,或translog变得越来越大索引将被flush
1)内存缓冲区的数据被写入新的segment
2)缓冲区被清空
3)文件系统缓存被刷入磁盘(flush操作)
4)清空translog

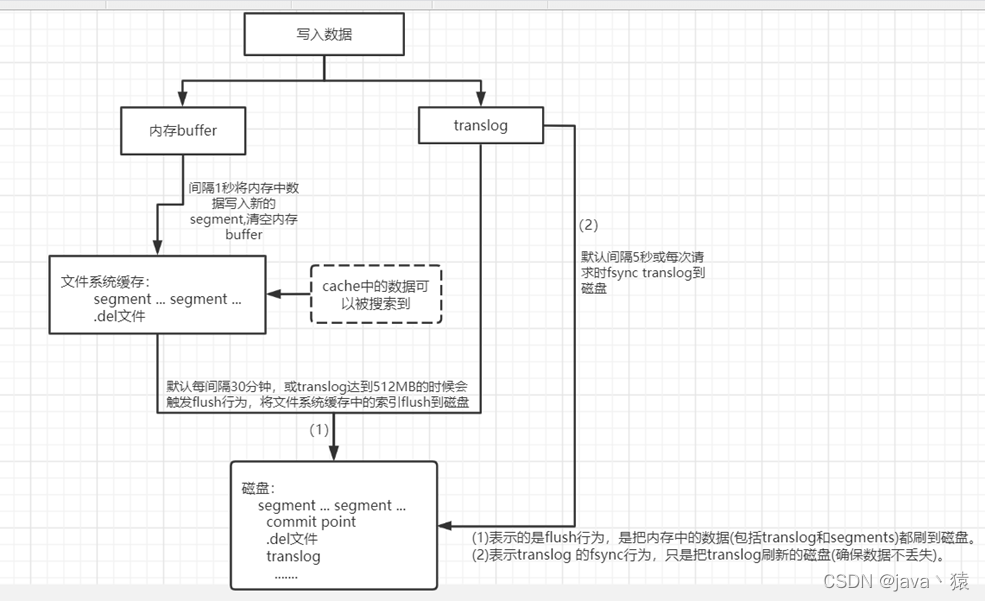
十七,ES数据存储原理
十八,基本语法
查看索引信息:GET /_cat/indices?v
查看集群节点信息:GET /_cat/nodes
删除索引:DELETE /my_index
创建索引: PUT /my_index?pretty
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}设置索引信息:PUT /my_index/_mappings
keyword 类型 ignore_above 指的是长度超过指定字符后,不会被索引,但是会被存储
text 类型的 ignore_above 指超过长度不能被整体索引,不会精确匹配到
{
"properties": {
"content_type": {
"type": "integer"
},
"content_id": {
"type": "long"
},
"user_name": {
"type": "keyword",
"ignore_above": 5
},
"title": {
"type": "text",
"fields": {
"key": {
"type": "keyword",
"ignore_above": 15
}
},
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"desc": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"create_time": {
"type": "date"
}
}
}查看索引结构信息:GET /my_index
查看索引结构信息:GET /my_index/_mappings
删除文档:DELETE /my_index/_doc/1
创建文档:PUT /my_index/_doc/1001
{
"content_id": 1001,
"content_type": 1,
"user_name": "小明",
"create_time": "2020-11-01",
"title": "一则小明的花边新闻",
"desc": "小明昨天表白失败"
}
{
"content_id": 1002,
"content_type": 1,
"user_name": "小红",
"create_time": "2020-11-01",
"title": "小红花边新闻",
"desc": "小红昨天拒绝了小明的表白"
}
{
"content_id": 1003,
"content_type": 2,
"user_name": "小胡",
"create_time": "2020-11-02",
"title": "小红和小胡的感情纠葛",
"desc": "小红因为暗恋小胡拒绝了小明的追求"
}
{
"content_id": 1004,
"content_type": 2,
"user_name": "小红小明小胡",
"create_time": "2020-11-02",
"title": "小红小明小胡的生死三角恋导致的诸多问题引发社会关心",
"desc": "小红因为暗恋老王拒绝了小明的追求"
}term 对搜索词不做分词,会将输入作为一个整体,在倒排索引中查找准确的词项:GET /my_index/_search
{
"query": {
"term": {
"user_name": "小胡"
}
}
}
{
"query": {
"term": {
"title": "小红"
}
}
}match 用在一个分词字段上,他会分词去匹配。用在一个精确匹配的字段上或者数字、日期类型字段上他会精确查找:GET /my_index/_search
{
"query": {
"match": {
"user_name": "小红"
}
}
}
加上分页
{
"query": {
"match": {
"title": "小红和"
}
},
"from":0,
"size":"1"
}range 范围查询:GET /my_index/_search
{
"query": {
"range": {
"content_id": {
"gte":1002,
"lte":1004
}
}
}
}bool 多条件组合查询:GET /my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "小胡"
}
},
{
"range": {
"content_id": {
"gte": 1002,
"lte": 1004
}
}
}
]
}
}
}
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us