 想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com
想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com
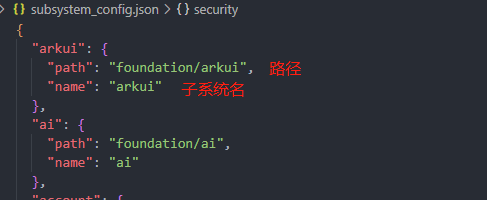
注意:在已有子系统的目录下再创建子系统会导致重复获取到部件配置文件而导致报错。(血泪教训)
{
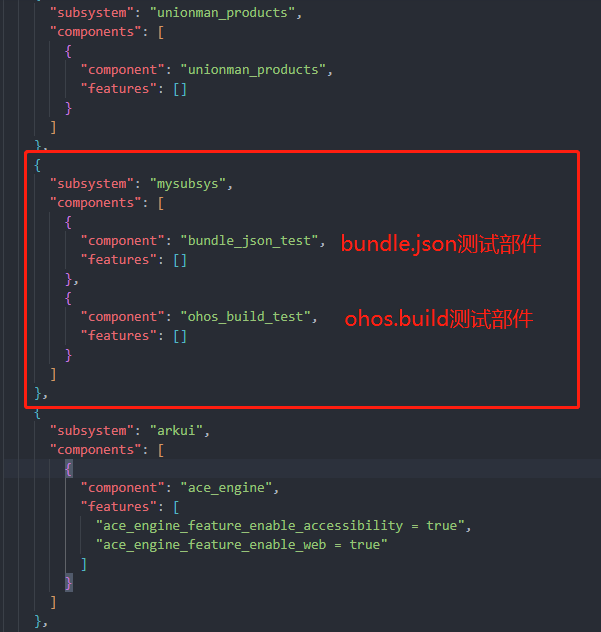
"subsystem": "mysubsys" # mysubsys所属子系统的名字
"parts": {
"ohos_build_test": { # ohos_build_test为部件名称
"module_list": [
"//mysubsys/ohos_build_test:mygroup" # 部件编译入口
]
"test_list": []
}
}
}{
"name": "@ohos/sensor_lite", # HPM部件英文名称,格式"@组织/部件名称"
"description": "Sensor services", # 部件功能一句话描述
"version": "3.1", # 版本号,版本号与OpenHarmony版本号一致
"license": "MIT", # 部件License
"publishAs": "code-segment", # HPM包的发布方式,当前默认都为code-segment
"segment": {
"destPath": ""
}, # 发布类型为code-segment时为必填项,定义发布类型code-segment的代码还原路径(源码路径)
"dirs": {"base/sensors/sensor_lite"}, # HPM包的目录结构,字段必填内容可以留空
"scripts": {}, # HPM包定义需要执行的脚本,字段必填,值非必填
"licensePath": "COPYING",
"readmePath": {
"en": "README.rst"
},
"component": { # 部件属性
"name": "sensor_lite", # 部件名称
"subsystem": "", # 部件所属子系统
"syscap": [], # 部件为应用提供的系统能力
"features": [], # 部件对外的可配置特性列表,一般与build中的sub_component对应,可供产品配置
"adapted_system_type": [], # 轻量(mini)小型(small)和标准(standard),可以是多个
"rom": "92KB", # 部件ROM值
"ram": "~200KB", # 部件RAM估值
"deps": {
"components": [ # 部件依赖的其他部件
"samgr_lite",
"ipc_lite"
],
"third_party": [ # 部件依赖的三方开源软件
"bounds_checking_function"
]
}
"build": { # 编译相关配置
"sub_component": [
""//base/sensors/sensor_lite/services:sensor_service"", # 部件编译入口
], # 部件编译入口,模块在此处配置
"inner_kits": [], # 部件间接口
"test": [] # 部件测试用例编译入口
}
}
}# C/C++模板
ohos_shared_library
ohos_static_library
ohos_executable
ohos_source_set
# 预编译模板:
ohos_prebuilt_executable
ohos_prebuilt_shared_library
ohos_prebuilt_static_library
#hap模板
ohos_hap
ohos_app_scope
ohos_js_assets
ohos_resources
#其他常用模板
#配置文件
ohos_prebuilt_etc
#sa配置
ohos_sa_profileimport("//build/ohos.gni")
ohos_executable("helloworld") {
configs = [] # 配置
part_name = [string] # 部件名称
subsystem_name = [string] # 子系统名称
deps = [] # 部件内模块依赖
external_deps = [ # 跨部件模块依赖定义,
"part_name:module_name", # 定义格式为 "部件名:模块名称"
] # 这里依赖的模块必须是依赖的部件声明在inner_kits中的模块
ohos_test = []
test_output_dir = []
# Sanitizer配置,每项都是可选的,默认为false/空
sanitize = {
# 各个Sanitizer开关
cfi = [boolean] # 控制流完整性检测
cfi_cross_dso = [boolean] # 开启跨so调用的控制流完整性检测
integer_overflow = [boolean] # 整数溢出检测
boundary_sanitize = [boolean] # 边界检测
ubsan = [boolean] # 部分ubsan选项
all_ubsan = [boolean] # 全量ubsan选项
...
debug = [boolean] # 调测模式
blocklist = [string] # 屏蔽名单路径
}
testonly = [boolean]
license_as_sources = []
license_file = [] # 后缀名是.txt的文件
remove_configs = []
static_link = []
install_images = []
module_install_dir = [] # 模块安装路径,从system/,vendor/后开始指定
relative_install_dir = []
symlink_target_name = []
output_dir = [directory] # 存放输出文件的目录
install_enable = [boolean]
version_script = []
use_exceptions = []
}"mysubsys": {
"path": "mysubsys",
"name": "mysubsys"
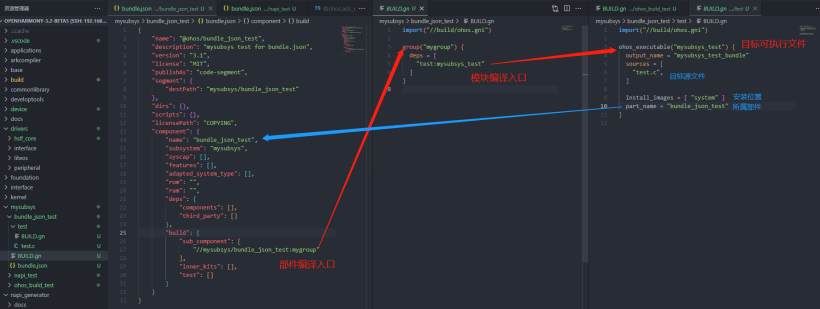
}mysubsys
├── bundle_json_test
│ ├── BUILD.gn
│ ├── bundle.json
│ └── test
│ ├── BUILD.gn
│ └── test.c
└── ohos_build_test
├── BUILD.gn
├── ohos.build
└── test
├── BUILD.gn
└── test.c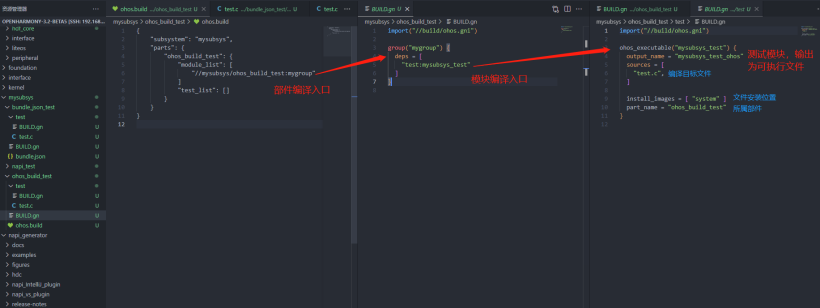 用于测试的源文件test.c:
用于测试的源文件test.c:#include "stdio.h"
int main()
{
printf("test mysubsys for ohos.build\r\n");
return 0;
}
#include "stdio.h"
int main()
{
printf("test mysubsys for bundle.json\r\n");
return 0;
}上述两个实例可以直接在"module_list"或者"sub_component"里面直接将编译入口设置为你的模块目标(动态库、静态库、配置文件、预编译模块等),不过在学习过程中,发现OpenHarmony源码里面关于部件模块的写法(例如third_party),发现很多都会额外写一个BUILD.gn来新建一个group,用来包含一个或多个目标的虚节点,这里我也习惯这么写了。
./build.sh --product-name unionpi_tiger #编译
./device/board/unionman/unionpi_tiger/common/tools/packer-unionpi.sh # 镜像打包 电脑连接开发板debug口,打开串口工具,生成的可执行文件mysubsys_test_ohos,mysubsys_test_bundle都可以在bin目录找到,在终端执行执行:
电脑连接开发板debug口,打开串口工具,生成的可执行文件mysubsys_test_ohos,mysubsys_test_bundle都可以在bin目录找到,在终端执行执行:mysubsys_test_ohos
mysubsys_test_bundle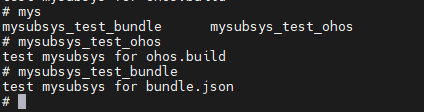 文章相关附件可以点击下面的原文链接前往下载: https://ost.51cto.com/resource/2564。想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com
文章相关附件可以点击下面的原文链接前往下载: https://ost.51cto.com/resource/2564。想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com 很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我不知道为什么,但是当我设置这个设置时它无法编译设置:static_cache_control,[:public,:max_age=>300]这是我得到的syntaxerror,unexpectedtASSOC,expecting']'(SyntaxError)set:static_cache_control,[:public,:max_age=>300]^我只想将“过期”header设置为css、javaascript和图像文件。谢谢。 最佳答案 我猜您使用的是Ruby1.8.7。Sinatra文档中显示的语法似乎是在Ruby1.
在编写Ruby(客户端脚本)时,我看到了三种构建更长字符串的方法,包括行尾,所有这些对我来说“闻起来”有点难看。有没有更干净、更好的方法?变量递增。ifrender_quote?quote="NowthatthereistheTec-9,acrappyspraygunfromSouthMiami."quote+="ThisgunisadvertisedasthemostpopularguninAmericancrime.Doyoubelievethatshit?"quote+="Itactuallysaysthatinthelittlebookthatcomeswithit:themo