目录
最近在学习Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks这篇论文,论文下载地址,想要复现一下文中的代码,过程中遇到了很多问题,因此记录下来。遇到其他问题欢迎在评论区留言,相互解答。
如果没有安装Anaconda或者MIniconda的可以先安装,并学一下简单的环境以及包的管理。基本的语法有:
conda remove -n=your_env_name --all
删除虚拟环境
conda create -n=your_env_name python=3.6
创建虚拟环境
conda info --env
显示所有环境的列表
conda activate env_name
切换至env_name环境
项目结构如下,一般的项目都会包含requirements.txt, environment.yml, setup.py三者之中某些或者全部。
conda env create -f environment.yml
再通过pip来安装visdom,输入:
pip install -r requirements.txt
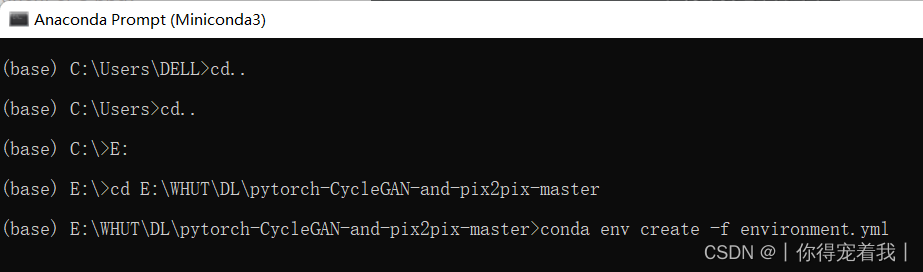
如果使用conda env create -f environment.yml命令时,报错CondaHTTPError,可以参考这篇文章:关于anaconda创建环境时出现CondaHTTPError问题的终极解决办法。如果还是不行,由于environment.yml中的包并不多,可以用pip手动安装。
首先创建一个环境:
conda create -n=MyProject python=3.8
进入环境:
conda activate MyProject
用pip依次安装environment.yml文件中的包(除了torch):
pip install --index-url https://pypi.tuna.tsinghua.edu.cn/simple/ dominate=2.4.0
安装torch:安装教程 , 下载库网址
这里最好下gpu版本的,因为下载gpu版本的,训练时可以选择gpu或者cpu进行训练。但是下载cpu版本,只能选择cpu进行训练。
首先把项目配置在刚才创建的环境中,参考Pycharm中如何配置已有的环境_MrRoose1的博客-CSDN博客。然后在终端输入python -m visdom.server,如果启动成功显示如下:
如果没有反应,或者在Anaconda prompt中输入python -m visdom.server,显示Downloading scripts, this may take a little while,则可以参考博客visdom服务启动时提示Downloading scripts, this may take a little while解决办法亲测有效,可以解决。
如图添加train文件中的参数,把python train.py后面的部分,也就是--dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan复制到Parameter中,然后运行train.py。
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
1)datasets 这个最简单,就是数据集的路径
2)name 这里指的是保存训练权重的文件夹的名字
3)model:训练的模型
如果报错module ‘torch._C’ has no attribute ‘_cuda_setDevice’,可能是因为环境里pytorch下载的CPU版本导致的。查看pytorch版本的方法:
import torch
# 若返回为True,则使用的是GPU版本的torch,若为False,则为CPU版本
print(torch.cuda.is_available())
# 返回的GPU型号为你使用的GPU型号
print(torch.cuda.get_device_name(0))
① 如果时Python文件中调用了GPU,那么设置:
torch.cuda.set_device(-1)
②如果你用命令行执行python文件,那么在最后加上
python train.py --你的GPU的设置对应形参 -1
你的GPU设置对应形参,是你的Python文件中应该会有一个arg是用来设置要使用GPU的编号的,与1同理。
报错信息:UserWarning: Detected call of ‘lr_scheduler.step()’ before ‘optimizer.step()’. In PyTorch 1.1.0 and later, you should call them in the opposite order: ‘optimizer.step()’ before ‘lr_scheduler.step()’. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of ‘lr_scheduler.step()’ before ‘optimizer.step()’. "
把train.py文件中的第43行注释,放到第78行。
model.update_learning_rate() # update learning rates in the beginning of every epoch.
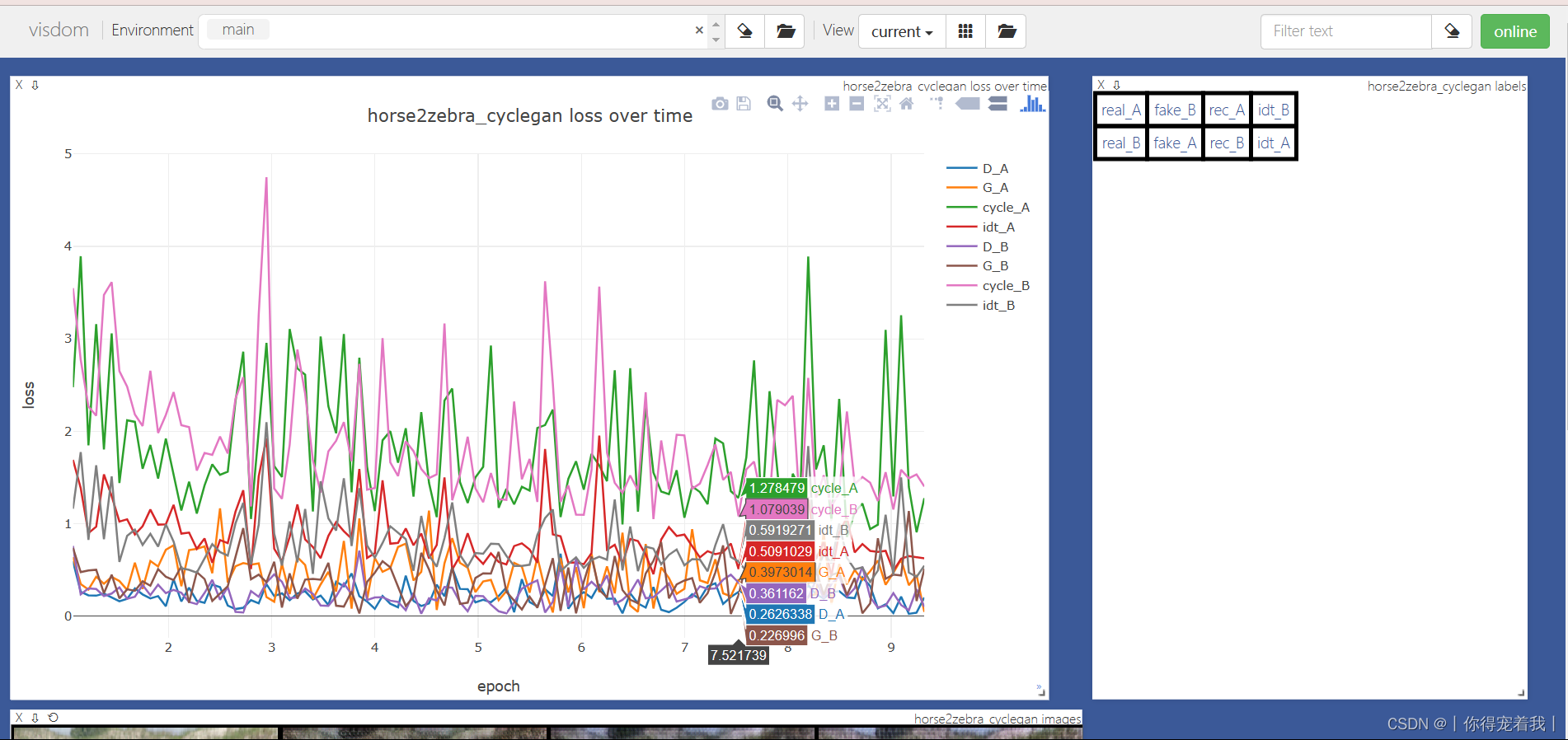
运行成功以后,在Visdom可以看到训练过程。
当运行train.py文件时,在文件夹下保存模型里会生成一个web文件,打开里面的html就能看到八种图片:
其中fake_B一般就是想要生成的图片
如果想要继续训练,运行命令如下:
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan --continue_train
用同样的方法运行test.py文件:
python test.py --dataroot ./datasets/horse2zebra --name horse2zebra --model cycle_gan
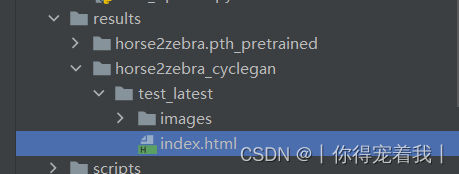
会生成一个results文件夹,打开html可以看到训练的效果。可以看到训练5轮的效果并不好。


--dataroot datasets/horse2zebra/testA --name horse2zebra.pth_pretrained --model test --no_dropout
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra.pth_pretrained --model test --no_dropout
打开results文件夹下horse2zebra.pth_pretrained文件夹中的html,可以看到训练的效果图。

参考:
【毕设】基于CycleGAN的风格迁移【一】环境搭建及运行代码
【深度学习】CycleGAN开源项目学习笔记 | 完整流程 | 报错总结 | pytorch
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/