1、S3 可以使用aws的sdk集合包,也可以使用S3专用的包:@aws-sdk/client-s3;
2、通过sdk上传的文件,不带自动设置 Content-Type 的逻辑(同样的情况发生在阿里云),所以这里的设置应该属于前端web代码。sdk就不带了,所以要自备mime表;
3、CloudFront 会根据源站的 Content-Type 自动应用压缩算法;
4、可以启用Content-Type的类型参考链接:
但是请注意!!! CF 的自动压缩,测试有大小限制。大约大于6M的文件就要注意是否被CF原样输出了(因为他们认为过大的文件会导致计算资源消耗),网络消耗惊人。
5、CloudFront的CDN缓存策略,会跟阿里云类似,会根据源站的 Cache-Control 来。当然也可以用他们的TTL设定。不过源站的缓存策略完备的话,这里肯定用不着;
6、CloudFront有一个名词叫缓存键,cache key,其实就是定位唯一一条资源的意思。为什么不是直接用文件名呢,是因为CDN还可以根据上发的header或者 cookies 或query_string 做key来映射缓存。比如,假设一个文件 a.txt,设定 header t 为缓存,那此cache的key就可能类似 a.txt_header_t_xx 来缓存所有t = xx 的时候,a.txt。
注意!!!此处有一个巨大的差异,阿里云在默认情况下,会对 query_string 做key。所以客户端的 update 文件夹下的文件,客户端之前在国内是用类似 xxx.game.net/5/update/update.txt?t=135456614 的方法强制CDN回源失效的。
但是!AWS在设置CloudFront 回源S3时,默认的策略,是只把url当key的!由此客户端的取巧全部失效。所以只能老老实实的设置 cache-control。
7、由于6的失误引起的需要no-cache的CDN节点资源已经缓存在外,就需要清空CDN节点了。AWS没有阿里云类似的图形操作界面直接刷新,需要用他们的命令行客户端。
文档:安装或更新最新版本的 AWS CLI - AWS Command Line Interface
步骤:
安装:
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install
配置config(生成在 $HOME/.aws/credentials):
$ aws configure
AWS Access Key ID [None]: XXXXXX
AWS Secret Access Key [None]: XXXXX
Default region name [None]:
Default output format [None]:
使其失效:
aws cloudfront create-invalidation --distribution-id --paths "/*"
1、在对应的区域,创建对应的S3的bucket。注意不要开放公有访问(省的被偷流量,CF免费,这个要钱的!)
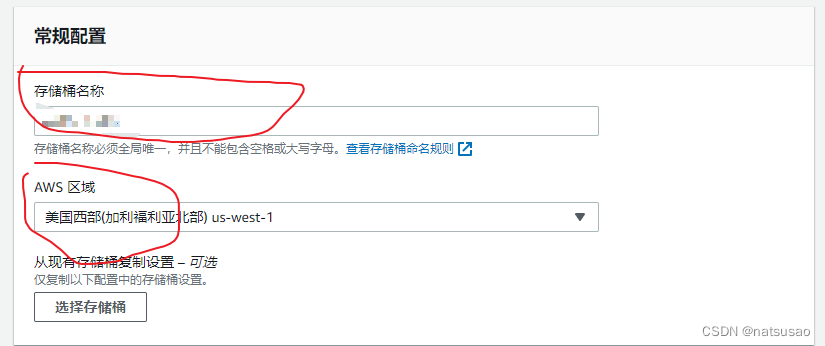

其他保持默认,创建即可。
2、创建一个CF分发
选择S3,不需要自己输入(走外网端口会起反效果):
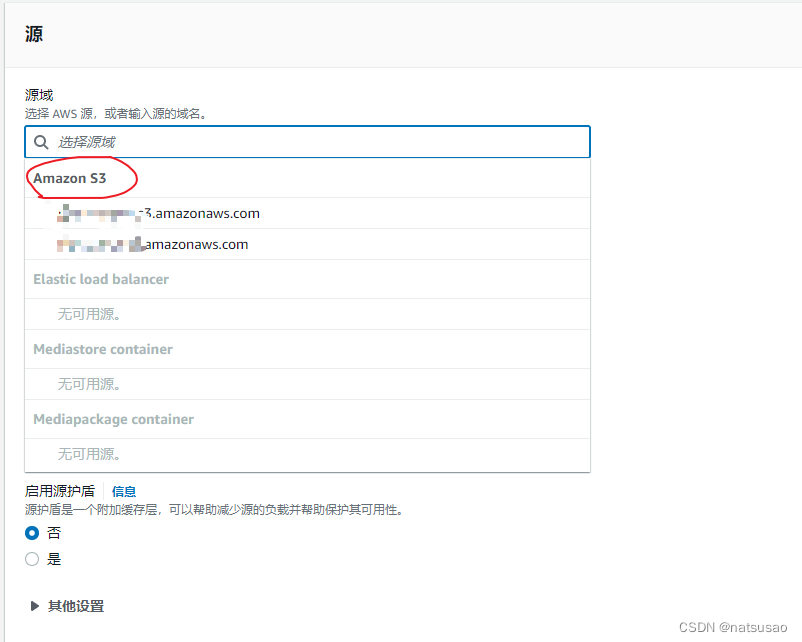
选填名字
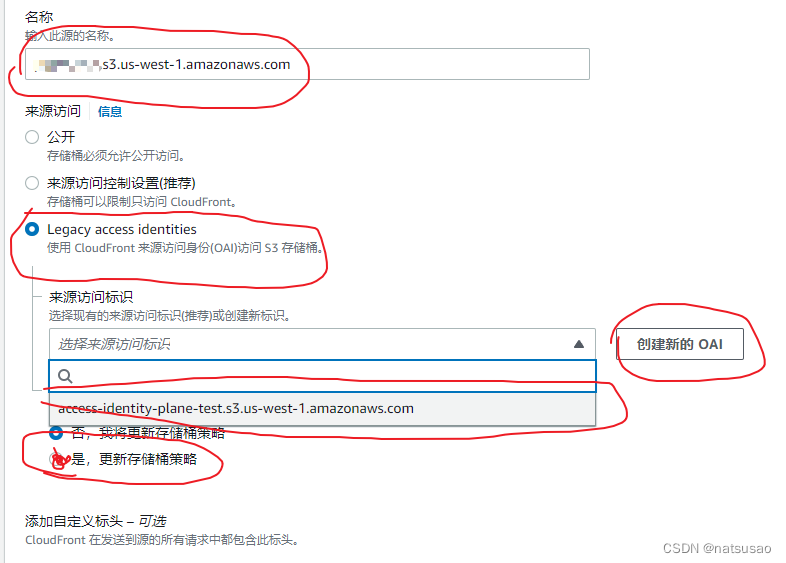
选择Legacy access,然后创建一个OAI,并对这个bucket应用更新(不然就要去S3修改了,很难受)
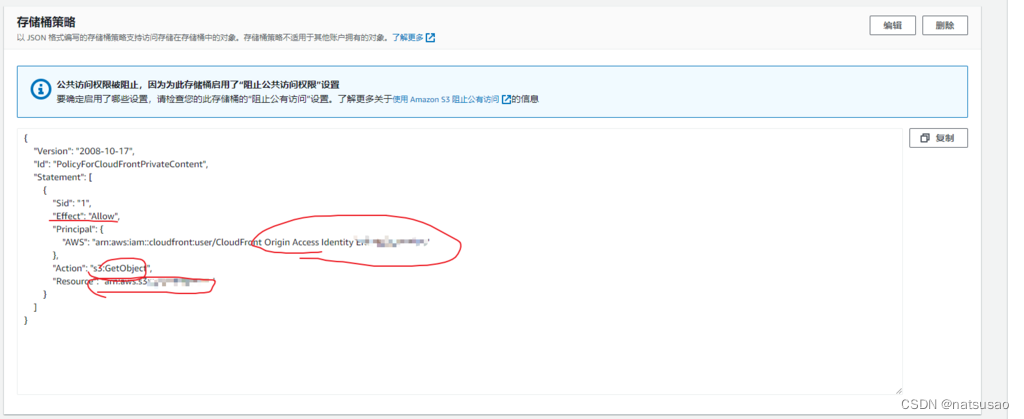
如果这个时候回到S3,就可以看到 bucket 已经生效私有访问策略:
其他不用动,选择Cache策略:

这个策略是AWS对S3的建议,其实很基础,如下:

这个策略提到了上面的很多要素。
CF有每个用户1个月1TB免费流量的 Free Tier,薅羊毛!
然后这里要填入自己的CNAME(也就是用户直接用到的域名了)
注意代理https需要选择对应的证书。

创建好之后,在DNSPod或者其他DNS运营商,解析一下CF的CNAME即可:
至此可以愉快的访问了。在海外AWS的素质一流。
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
我有一个应用程序可以读取文件的内容并为其编制索引。我将它们存储在磁盘本身中,但现在我使用的是AmazonS3,因此以下方法不再适用。事情是这样的:defperform(docId)@document=Document.find(docId)if@document.file?#Youshould'tcreateanewversion@document.versionlessdo|doc|@document.file_content=Cloudoc::Extractor.new.extract(@document.file.file)@document.saveendendend@docu
我知道还有其他相同的问题,但他们没有解决我的问题。我不断收到错误:Aws::Errors::MissingRegionErrorinBooksController#create,缺少区域;使用:region选项或将区域名称导出到ENV['AWS_REGION']。但是,这是我的配置开发.rb:config.paperclip_defaults={storage::s3,s3_host_name:"s3-us-west-2.amazonaws.com",s3_credentials:{bucket:ENV['AWS_BUCKET'],access_key_id:ENV['AWS_ACCE
我目前正在使用带有Carrierwavegem的Rails3.2将文件上传到AmazonS3。现在我需要能够处理用户提交的大于5GB的文件,同时仍然使用Carrierwavegem。Carrierwave或Fog是否有任何其他gem或分支可以处理5GB以上的文件上传到S3?编辑:我不想重写一个完整的Rails上传解决方案,所以像这样的链接没有帮助:https://gist.github.com/908875. 最佳答案 我想出了如何做到这一点,并且现在可以正常工作了。在正确的config/environment文件中,添加以下内容以
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
我在s3上有一堆文件。我使用.fog配置文件设置了雾,这样我就可以启动fog并获得提示。如果我知道文件的路径,现在如何访问和编辑s3上的文件? 最佳答案 最简单的方法可能是使用IRB或PRY获取文件的本地副本,或者编写一个简单的脚本来下载、编辑然后重新上传。假设您有一个名为data.txt的文件。您可以使用以下脚本初始化与S3的连接。require'fog'connection=Fog::Storage.new({:provider=>'AWS',:aws_secret_access_key=>YOUR_SECRET_ACCESS_