慢慢学,慢慢干。
大神博客:https://yolov5.blog.csdn.net/article/details/125148552
我老老实实的按照大神博主的方案进行修改。
第一步:common.py中添加BiFPN模型
# BiFPN
# 两个特征图add操作
class BiFPN_Add2(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add2, self).__init__()
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1]))
# 三个特征图add操作
class BiFPN_Add3(nn.Module):
def __init__(self, c1, c2):
super(BiFPN_Add3, self).__init__()
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
self.conv = nn.Conv2d(c1, c2, kernel_size=1, stride=1, padding=0)
self.silu = nn.SiLU()
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon)
# Fast normalized fusion
return self.conv(self.silu(weight[0] * x[0] + weight[1] * x[1] + weight[2] * x[2]))
使用Ctrl+F查询在elif m is Concat:语句,在其后面加上BiFPN_Add选项,确保yaml的BiFPN参数能够被识别到。
elif m is Concat:
c2 = sum(ch[x] for x in f)
# 添加bifpn_add结构
elif m in [BiFPN_Add2, BiFPN_Add3]:
c2 = max([ch[x] for x in f])
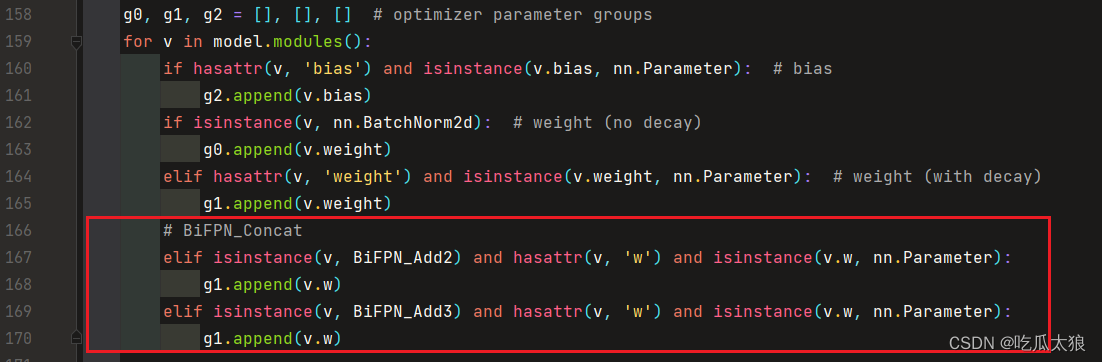
BiFPN_Add2和BiFPN_Add3函数中定义的w参数,加入g1 g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
# BiFPN_Concat
elif isinstance(v, BiFPN_Add2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
elif isinstance(v, BiFPN_Add3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
g1.append(v.w)
按照之前的版本是存在如上代码的,但是yolov5-v7.0版本中,这个部分优化成智能的optimizer。
通过观察可以发现,在大神博主的博客中修改的地方时160行左右附近,我按图索骥,来到这个地方。

与之前相比,这个地方变成了一个智能优化器函数。
smart_optimizer(model, opt.optimizer, hyp['lr0'], hyp['momentum'], hyp['weight_decay'])震惊,我点了进去看看这个函数的实现,发现了惊天大咪咪。
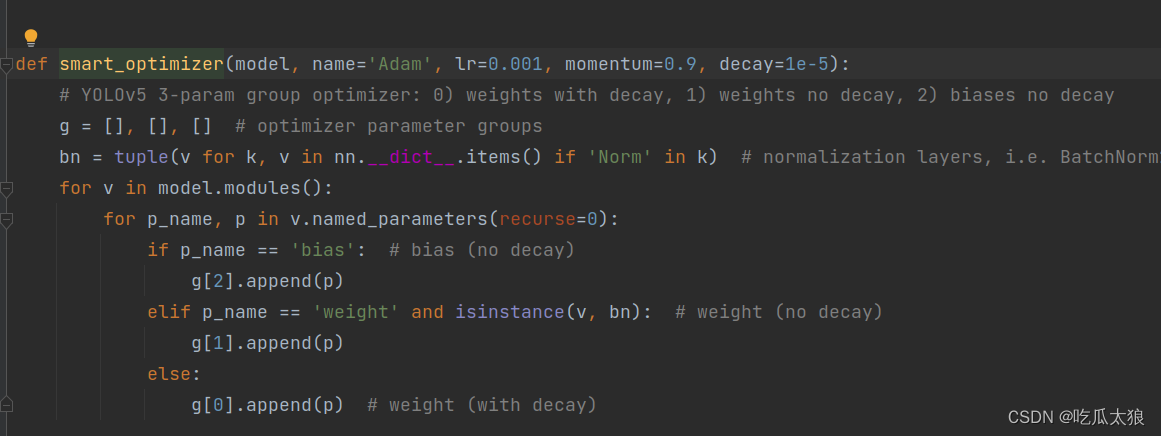
没错,凭着多年直觉,我认为这个地方被重构了。之前的一重for变成了二重for,我来对比一下区别。
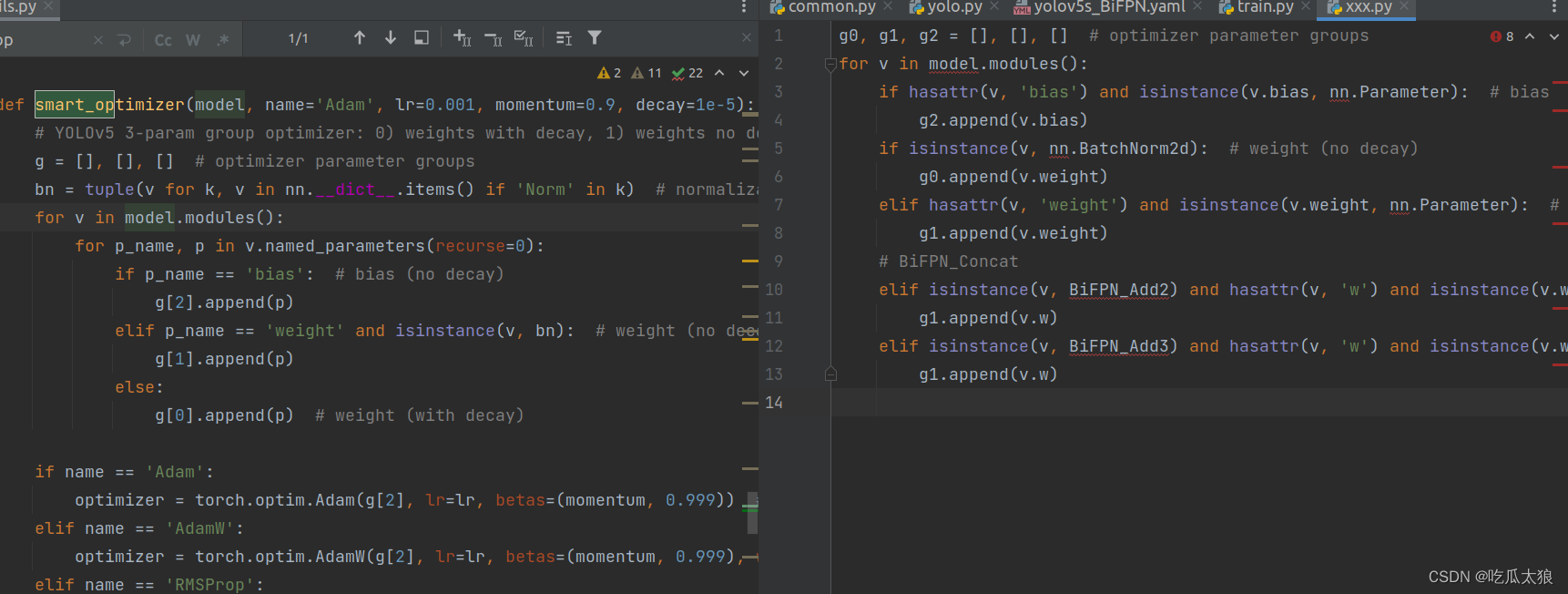
近似度非常高,作者偷懒没有修改注释,我们通过注释可以看出,虽然g[0] g[1] g[2 ]被g = [] [] []代替,但是我们还是可以读出来,这就是我们要的地方。
# optimizer parameter groups我们要注意到博主老版本的地方g[1]代表:
#g[1] weight (with decay)通过注释我们可以看出,v7.0的g[0]代表
# g【0 】 weight (with decay)
所以,我的结论就是第三步对参数g的修改不在需要,直接略过即可,智能优化器会帮我们对多余的部分进行自动增加权重。
将Concat全部换成BiFPN_Add,可以看到原来的Concat,全都变成新的BiFPN结构了。
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.1 BiFPN head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Add2, [256, 256]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Add2, [128, 128]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17
[-1, 1, Conv, [512, 3, 2]],
[[-1, 13, 6], 1, BiFPN_Add3, [256, 256]], #v5s通道数是默认参数的一半
[-1, 3, C3, [512, False]], # 20
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Add2, [256, 256]], # cat head P5
[-1, 3, C3, [1024, False]], # 23
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
现在开始实验有没有效果:
这里出现内存分配不足的情况,我的显卡显存是8G,查阅下资料,我把train的batchsize修改成-1,让训练的模型自适应epoch大小,不过可能会导致精度下降。
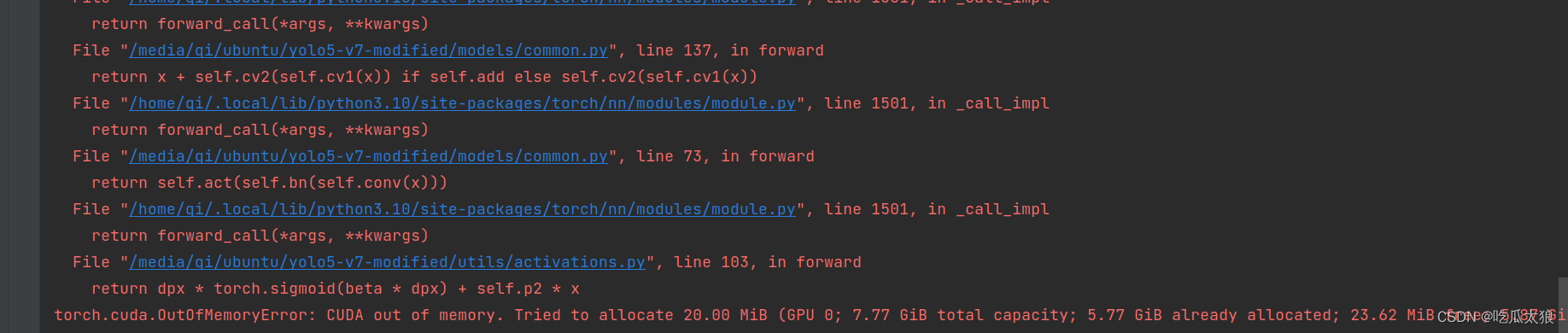
parser.add_argument('--epochs', type=int, default=30, help='total training epochs')默认的batchsize是16,我修改成-1,再进行实验。
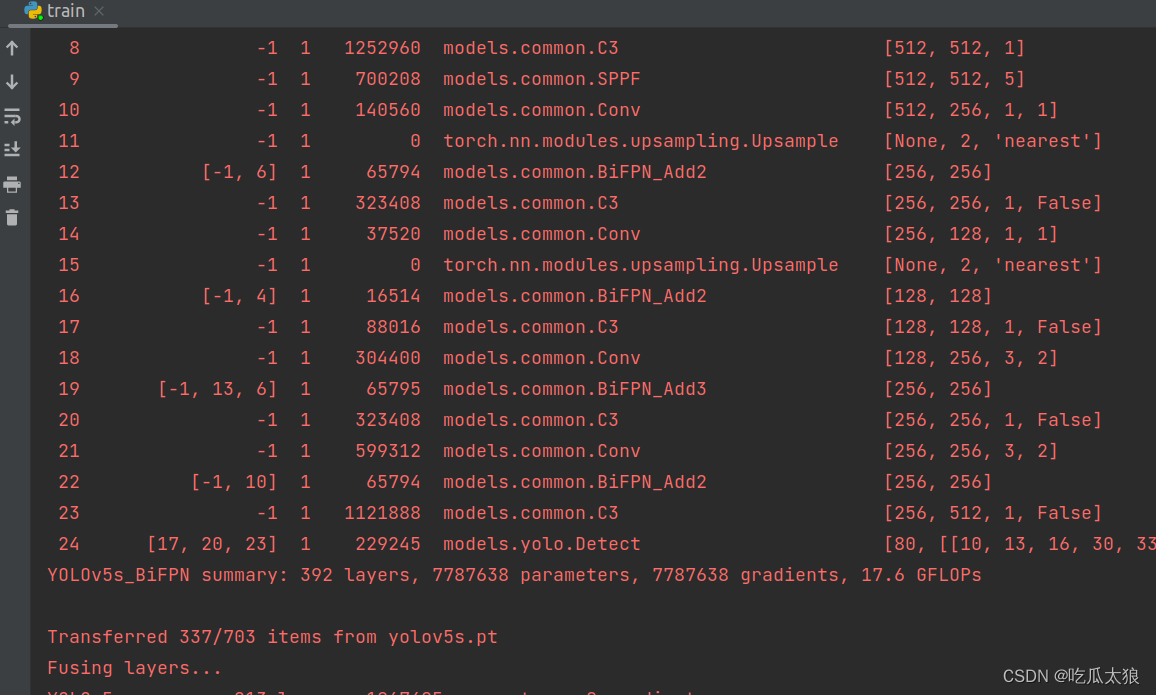
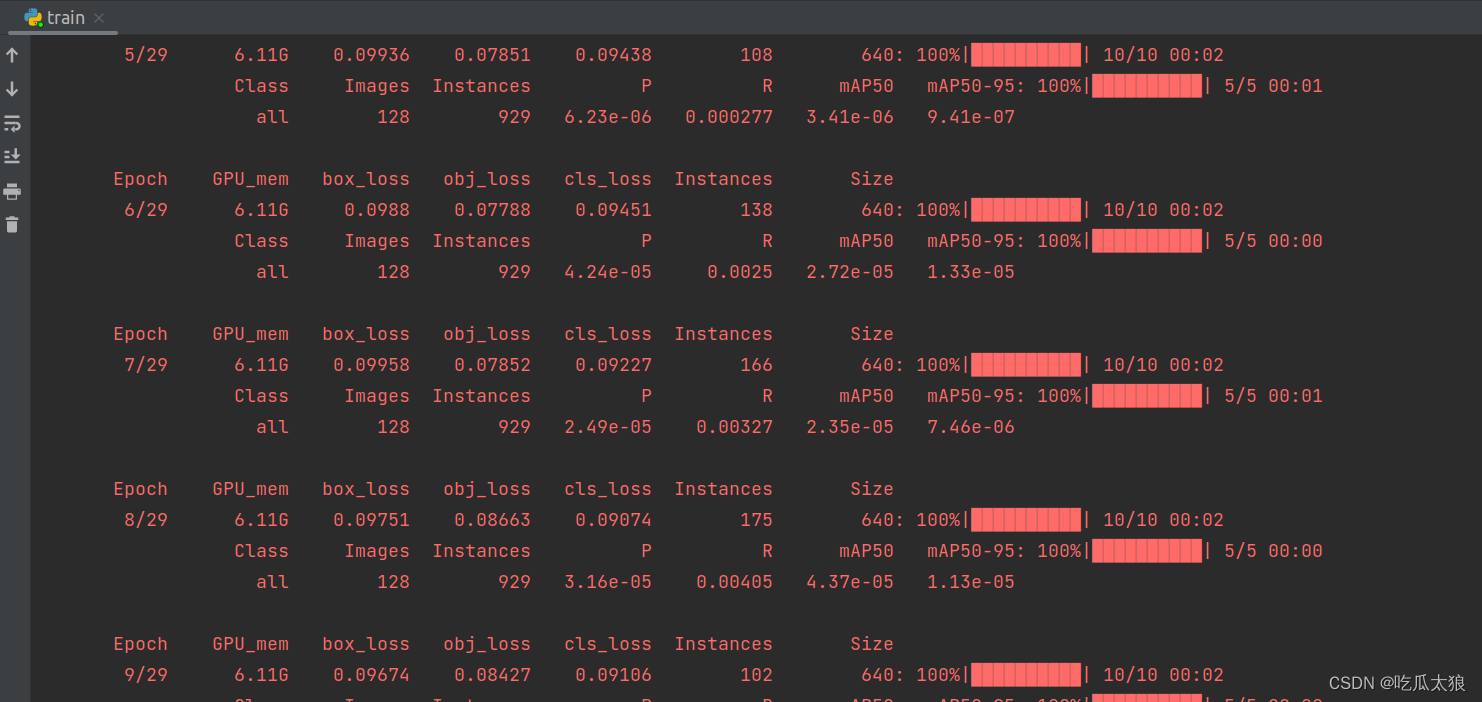
可以看出,进度图已经显示Bi_FPN结构,已经成功运行。
初学小白,难免有纰漏和错误,如有不同看法观点,欢迎交流。
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我有一个ModularSinatra应用程序,我正在尝试将Bootstrap添加到应用程序中。get'/bootstrap/application.css'doless:"bootstrap/bootstrap"end我在views/bootstrap中有所有less文件,包括bootstrap.less。我收到这个错误:Less::ParseErrorat/bootstrap/application.css'reset.less'wasn'tfound.Bootstrap.less的第一行是://CSSReset@import"reset.less";我尝试了所有不同的路径格式,但它
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
当谈到运行时自省(introspection)和动态代码生成时,我认为ruby没有任何竞争对手,可能除了一些lisp方言。前几天,我正在做一些代码练习来探索ruby的动态功能,我开始想知道如何向现有对象添加方法。以下是我能想到的3种方法:obj=Object.new#addamethoddirectlydefobj.new_method...end#addamethodindirectlywiththesingletonclassclass这只是冰山一角,因为我还没有探索instance_eval、module_eval和define_method的各种组合。是否有在线/离线资
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
我正在开发一个创建网络博客的RubyonRails项目。我希望将一个名为featured的boolean数据库字段添加到Post模型中。该字段应该可以通过我添加的事件管理界面进行编辑。我使用了以下代码,但我什至没有在网站上显示另一列。$railsgeneratemigrationaddFeaturedfeatured:boolean$rakedb:migrate我是RubyonRails的新手,非常感谢任何帮助。我的index.html.erb文件中的相关代码(views):FeaturedPost架构.rb:ActiveRecord::Schema.define(:version=>
假设我有一个这样的单例类:classSettingsincludeSingletondeftimeout#lazy-loadtimeoutfromconfigfile,orwhateverendend现在,如果我想知道使用什么超时,我需要编写如下内容:Settings.instance.timeout但我宁愿将其缩短为Settings.timeout使这项工作有效的一个明显方法是将设置的实现修改为:classSettingsincludeSingletondefself.timeoutinstance.timeoutenddeftimeout#lazy-loadtimeoutfromc
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion