译注:cstack在github维护了一个简单的、类似sqlite的数据库实现,通过这个简单的项目,可以很好的理解数据库是如何运行的。本文是第十一篇,主要是实现递归搜索B-Tree
上次我们在插入第15行数据报错的时候结束:
db > insert 15 user15 person15@example.com
Need to implement searching an internal node
首先,使用一个新的函数调用替换埋桩的代码。
if (get_node_type(root_node) == NODE_LEAF) {
return leaf_node_find(table, root_page_num, key);
} else {
- printf("Need to implement searching an internal node\n");
- exit(EXIT_FAILURE);
+ return internal_node_find(table, root_page_num, key);
}
}
这个函数会执行二叉搜索来查找子节点是否会包含给定的 Key。请记住,这些指向右子节点的 Key 都是他们指向的子节点中包含的最大 Key 。
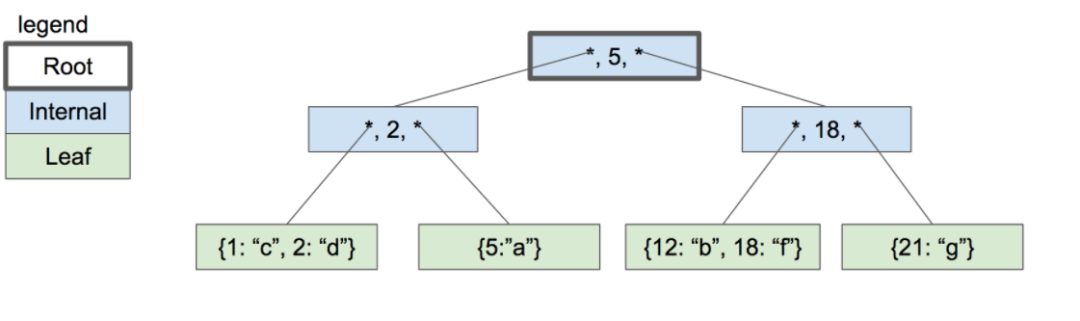
three-level btree
所以我们的二叉搜索比较查找的 Key 和指向右边子节点的的指针。
+Cursor* internal_node_find(Table* table, uint32_t page_num, uint32_t key) {
+ void* node = get_page(table->pager, page_num);
+ uint32_t num_keys = *internal_node_num_keys(node);
+
+ /* Binary search to find index of child to search */
+ uint32_t min_index = 0;
+ uint32_t max_index = num_keys; /* there is one more child than key */
+
+ while (min_index != max_index) {
+ uint32_t index = (min_index + max_index) / 2;
+ uint32_t key_to_right = *internal_node_key(node, index);
+ if (key_to_right >= key) {
+ max_index = index;
+ } else {
+ min_index = index + 1;
+ }
+ }
另请记住,内部节点的子节点可以是叶节点,也可以是内部节点。在我们查找到正确的子节点后,会在节点上调用适合的搜索函数:
+ uint32_t child_num = *internal_node_child(node, min_index);
+ void* child = get_page(table->pager, child_num);
+ switch (get_node_type(child)) {
+ case NODE_LEAF:
+ return leaf_node_find(table, child_num, key);
+ case NODE_INTERNAL:
+ return internal_node_find(table, child_num, key);
+ }
+}
现在向一个多节点btree插入 key 不再会导致报错结果。所以我们可以更新我们的测例:
" - 12",
" - 13",
" - 14",
- "db > Need to implement searching an internal node",
+ "db > Executed.",
+ "db > ",
])
end
我觉得现在是反思一下我们的另一个测试的时候了。也就是尝试插入1400行数据。仍然会报错,但是报错信息变成新的其他报错。现在,当程序 crash 的时候,我们的测试不能很好的处理这种报错。如果发生这种报错情况,到目前为止我们只使用获得的输出。
raw_output = nil
IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
- pipe.puts command
+ begin
+ pipe.puts command
+ rescue Errno::EPIPE
+ break
+ end
end
pipe.close_write
下面显示出了我们在测试插入1400行时输出的报错:
end
script << ".exit"
result = run_script(script)
- expect(result[-2]).to eq('db > Error: Table full.')
+ expect(result.last(2)).to match_array([
+ "db > Executed.",
+ "db > Need to implement updating parent after split",
+ ])
end
看起来这是我们待办事项列表中的下一个!
Enjoy GreatSQL ?
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。

使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir