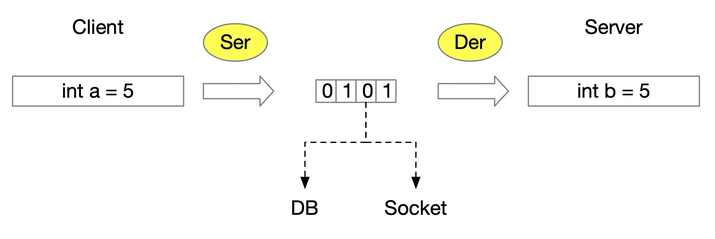
序列化协议 | 特点 |
jdk | 1. 序列化:除了 static、transient类型 |
fastjson | 1. 可读性好,空间占用小 |
hessian | 1. 序列化:除了 static、transient 类型 |
Father father = new Father();
father.name = "厨师";
father.comment = "川菜馆";
father.simpleInt = 1;
father.boxInt = new Integer(10);
father.simpleDouble = 1;
father.boxDouble = new Double(10);
father.bigDecimal = new BigDecimal(11.5);jdk序列化结果长度:626,耗时:55
jdk反序列化结果:Father{version=0, name='厨师', comment='川菜馆', boxInt=10, simpleInt=1, boxDouble=10.0, simpleDouble=1.0, bigDecimal=11.5}耗时:87
hessian序列化结果长度:182,耗时:56
hessian反序列化结果:Father{version=0, name='厨师', comment='川菜馆', boxInt=10, simpleInt=1, boxDouble=10.0, simpleDouble=1.0, bigDecimal=11.5}耗时:7
Fastjson序列化结果长度:119,耗时:225
Fastjson反序列化结果:Father{version=0, name='厨师', comment='川菜馆', boxInt=10, simpleInt=1, boxDouble=10.0, simpleDouble=1.0, bigDecimal=11.5}耗时:69public class Father implements Serializable {
/**
* 静态类型不会被序列化
*/
private static final long serialVersionUID = 1L;
/**
* transient 不会被序列化
*/
transient int version = 0;
/**
* 名称
*/
public String name;
/**
* 备注
*/
public String comment;
/**
* 包装器类型1
*/
public Integer boxInt;
/**
* 基本类型1
*/
public int simpleInt;
/**
* 包装器类型2
*/
public Double boxDouble;
/**
* 基本类型2
*/
public double simpleDouble;
/**
* BigDecimal
*/
public BigDecimal bigDecimal;
public Father() {
}
@Override
public String toString() {
return "Father{" +
"version=" + version +
", name='" + name + '\'' +
", comment='" + comment + '\'' +
", boxInt=" + boxInt +
", simpleInt=" + simpleInt +
", boxDouble=" + boxDouble +
", simpleDouble=" + simpleDouble +
", bigDecimal=" + bigDecimal +
'}';
}
}public class Son extends Father {
/**
* 名称,与father同名属性
*/
public String name;
/**
* 自定义类
*/
public Attributes attributes;
/**
* 枚举
*/
public Color color;
public Son() {
}
}public class Attributes implements Serializable {
private static final long serialVersionUID = 1L;
public int value;
public String msg;
public Attributes() {
}
public Attributes(int value, String msg) {
this.value = value;
this.msg = msg;
}
}public enum Color {
RED(1, "red"),
YELLOW(2, "yellow")
;
public int value;
public String msg;
Color() {
}
Color(int value, String msg) {
this.value = value;
this.msg = msg;
}
}使用到的对象及属性设置
Son son = new Son();
son.name = "厨师"; // 父子类同名字段,只给子类属性赋值
son.comment = "川菜馆";
son.simpleInt = 1;
son.boxInt = new Integer(10);
son.simpleDouble = 1;
son.boxDouble = new Double(10);
son.bigDecimal = new BigDecimal(11.5);
son.color = Color.RED;
son.attributes = new Attributes(11, "hello");使用 Hessian 序列化,结果写入文件,使用 vim 打开。使用 16 进制方式查看,查看命令:%!xxd
00000000: 4307 6474 6f2e 536f 6e9a 046e 616d 6504 C.dto.Son..name.
00000010: 6e61 6d65 0763 6f6d 6d65 6e74 0662 6f78 name.comment.box
00000020: 496e 7409 7369 6d70 6c65 496e 7409 626f Int.simpleInt.bo
00000030: 7844 6f75 626c 650c 7369 6d70 6c65 446f xDouble.simpleDo
00000040: 7562 6c65 0a61 7474 7269 6275 7465 7305 uble.attributes.
00000050: 636f 6c6f 720a 6269 6744 6563 696d 616c color.bigDecimal
00000060: 6002 e58e a8e5 b888 4e03 e5b7 9de8 8f9c `.......N.......
00000070: e9a6 869a 915d 0a5c 430e 6474 6f2e 4174 .....].\C.dto.At
00000080: 7472 6962 7574 6573 9205 7661 6c75 6503 tributes..value.
00000090: 6d73 6761 9b05 6865 6c6c 6f43 0964 746f msga..helloC.dto
000000a0: 2e43 6f6c 6f72 9104 6e61 6d65 6203 5245 .Color..nameb.RE
000000b0: 4443 146a 6176 612e 6d61 7468 2e42 6967 DC.java.math.Big
000000c0: 4465 6369 6d61 6c91 0576 616c 7565 6304 Decimal..valuec.
000000d0: 3131 2e35 0a 11.5.对其中的十六进制数逐个分析,可以拆解为一下结构:参考 hessian 官方文档,链接:http://hessian.caucho.com/doc/hessian-serialization.html
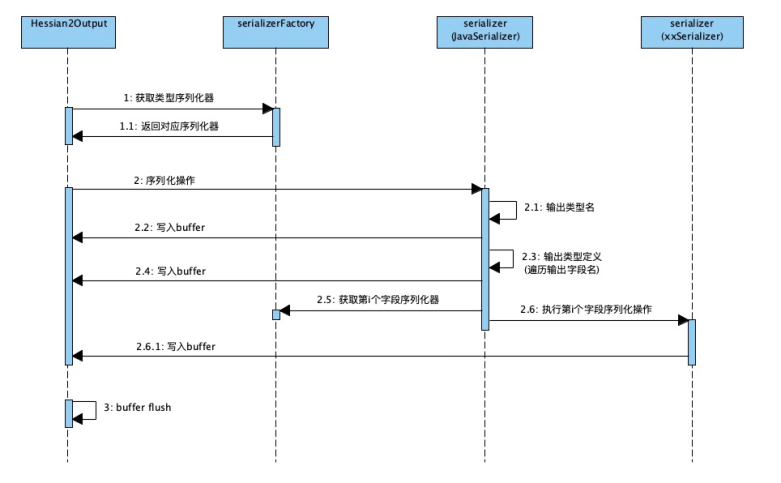
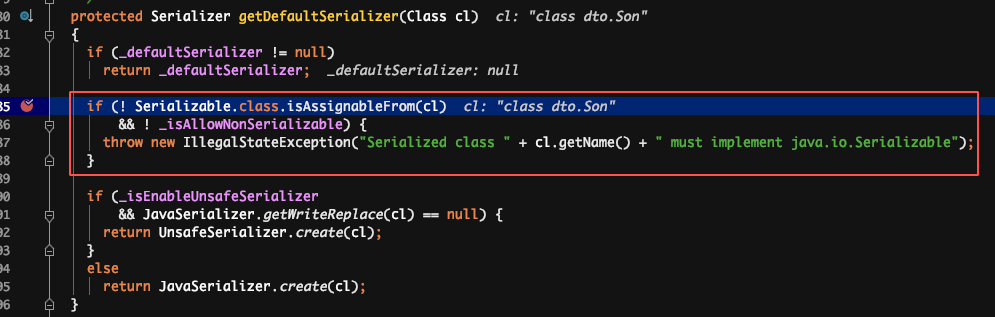
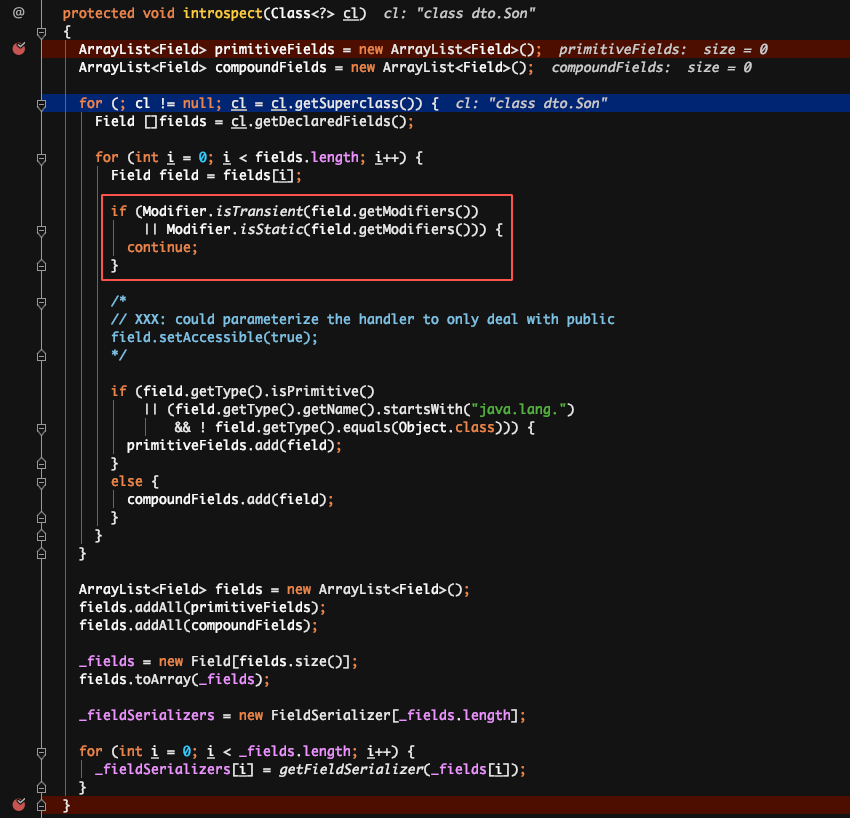

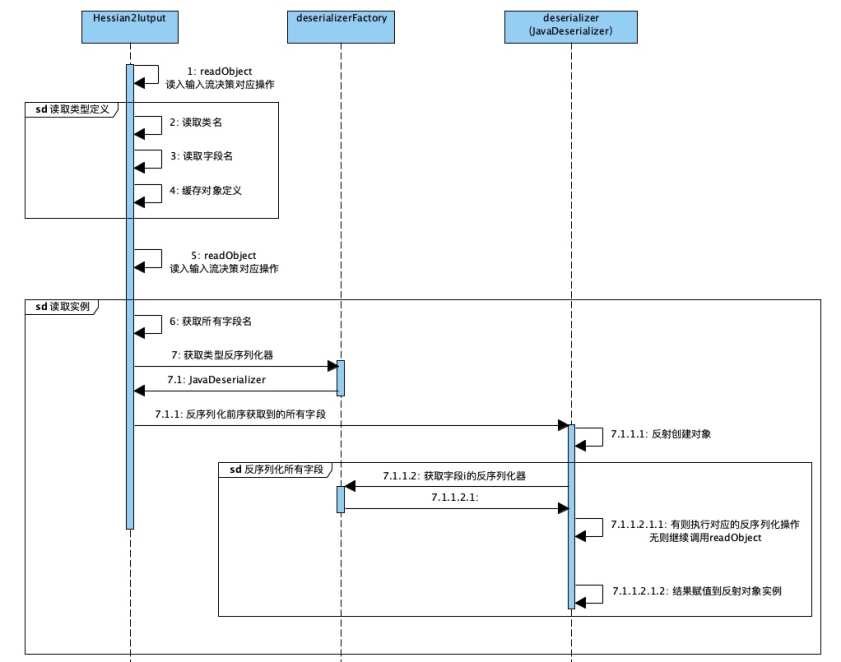
通俗原理图:
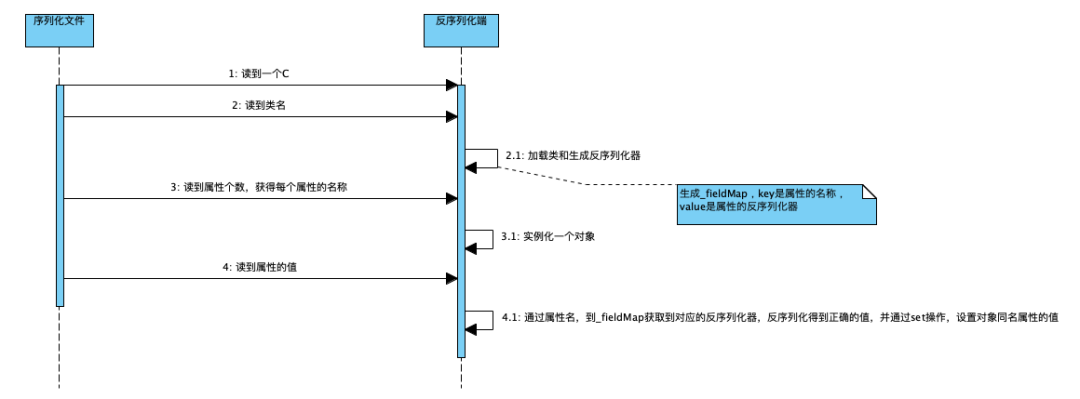
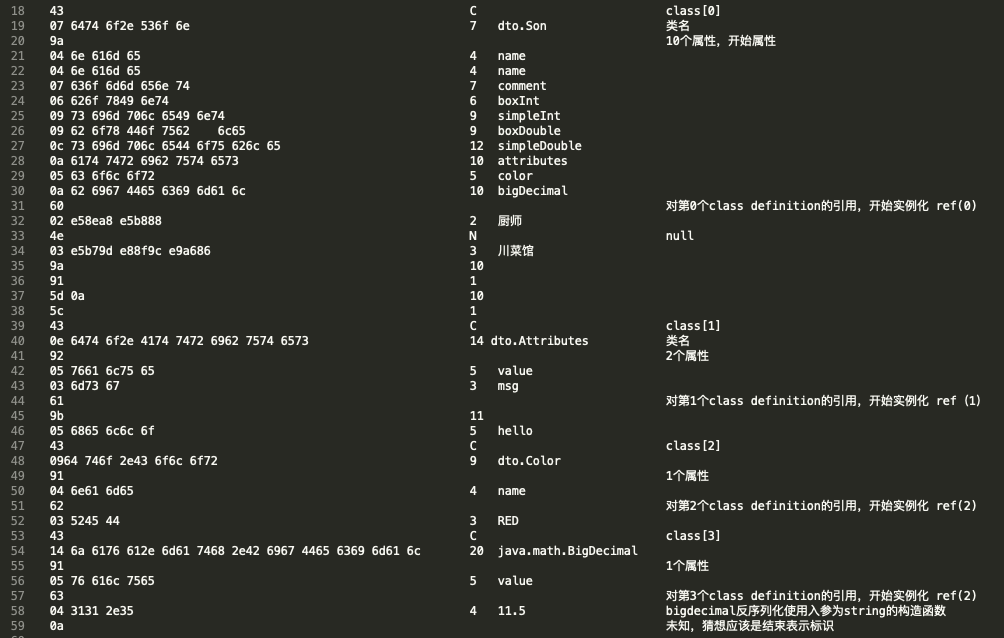
解释:这是前边的序列化文件,可以对着这个结构理解反序列化的过程。
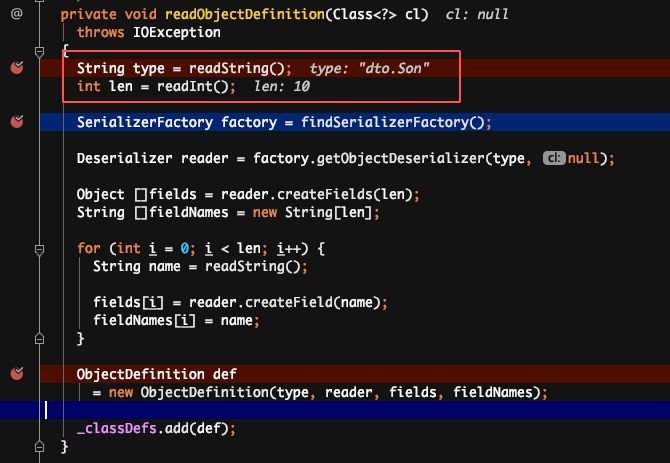
解释:读取到“C”之后,它就知道接下来是一个类的定义,接着就开始读取类名,属性个数和每个属性的名称。并把这个类的定义缓存到一个_classDefs 的 list 里。
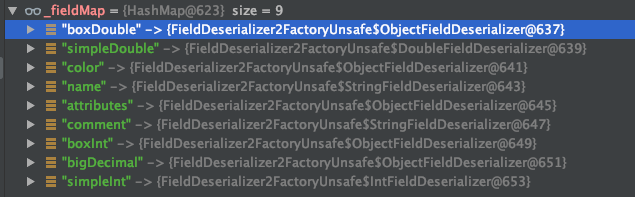
解释:通过读取序列化文件,获得类名后,会加载这个类,并生成这个类的反序列化器。这里会生成一个_fieldMap,key 为反序列化端这个类所有属性的名称,value 为属性对应的反序列化器。
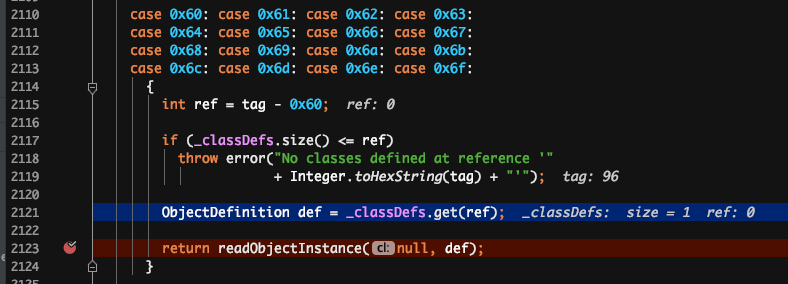
解释:读到 6 打头的 2 位十六进制数时,开始类的实例化和赋值。
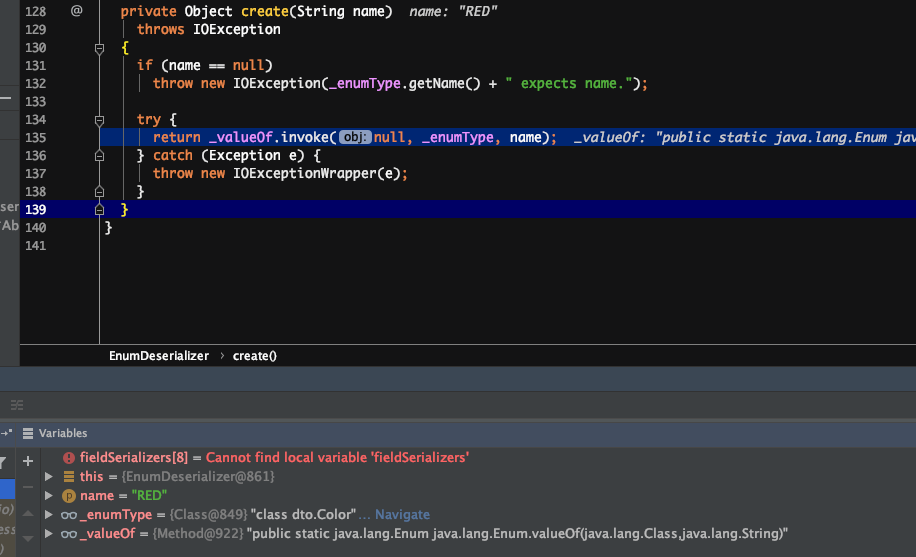
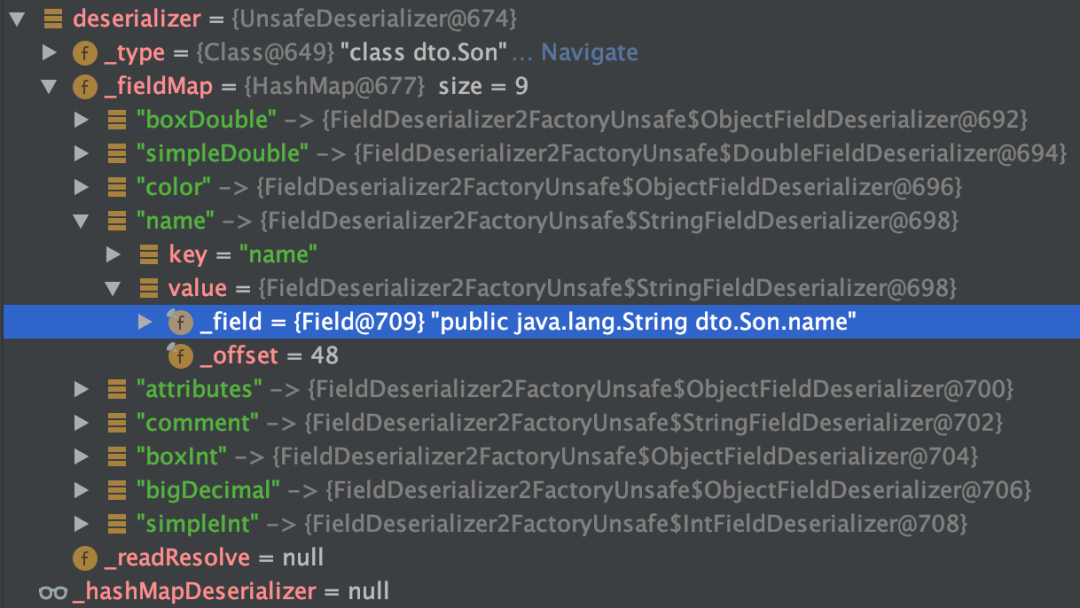

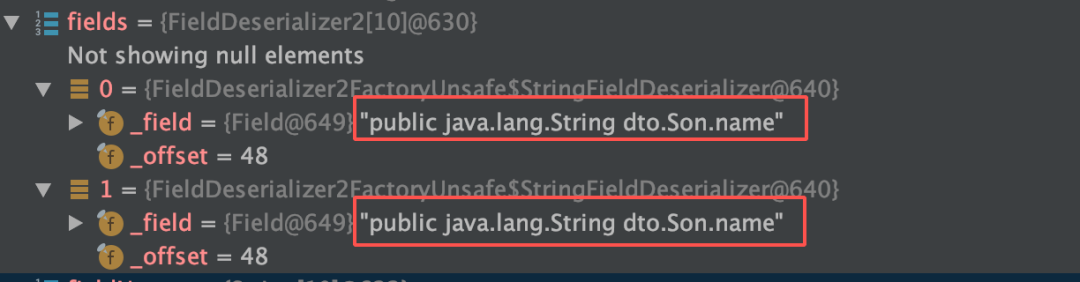
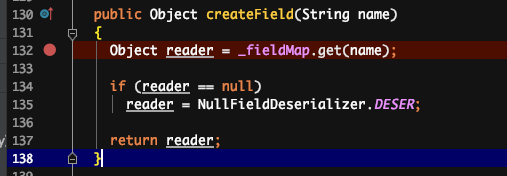
原因:反序列化时,是先通过类名加载同名类,并生成同名类的反序列化器,同名类每个属性对应的反序列化器存储在一个 map 中。在反序列化二进制文件时,通过读取到的属性名,到 map 中获取对应的反序列化器。若获取不到,默认是 NullFieldDeserializer.DESER。待到读值的时候,仅读值,不作 set 操作
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
我有一个存储JSON数据的列。当它处于编辑状态时,我不知道如何显示它。serialize:value,JSON=f.fields_for:valuedo|ff|.form-group=ff.label:short=ff.text_field:short,class:'form-control'.form-group=ff.label:long=ff.text_field:long,class:'form-control' 最佳答案 代替=f.fields_for:valuedo|ff|请使用以下代码:=f.fields_for:va
在RubyonRails中,如果数组为空,则具有序列化数组字段的模型将不会在.save()上更新,而它之前有数据。我正在使用:ruby2.2.1rails4.2.1sqlite31.3.10我创建了一个字段设置为文本的新模型:railsgmodel用户名:stringexample:text在我添加的User.rb文件中:serialize:example,Array我实例化了User类的一个新实例:test=User.new然后我保存用户以确保它正确保存:test.save()(0.1ms)begintransactionSQL(0.4ms)INSERTINTO"users"("cr
是否可以在使用YAML.load_file时强制Ruby调用初始化方法?我想调用该方法以便为我不序列化的实例变量提供值。我知道我可以将代码分解成一个单独的方法并在调用YAML.load_file之后调用该方法,但我想知道是否有更优雅的方法来处理这个问题。 最佳答案 我认为你做不到。由于您要添加的代码确实特定于要反序列化的类,因此您应该考虑在类中添加该功能。例如,让Foo成为您要反序列化的类,您可以添加一个类方法,例如:classFoodefself.from_yaml(yaml)foo=YAML::load(yaml)#editth
我有以下工厂:FactoryGirl.definedofactory:foodosequence(:name){|n|"Foo#{n}"}trait:ydosequence(:name){|n|"Fooy#{n}"}endendend如果我跑create:foocreate:foocreate:foo,:y我得到Foo1,Foo2,Fooy1。但我想要Foo1,Foo2,Fooy3。我怎样才能做到这一点? 最佳答案 经过smile2day'sanswer的一些提示后和thisanswer,我得出以下解决方案:FactoryGirl.
我有两个Foo对象列表。每个Foo对象都有一个时间戳,Foo.timestamp。两个列表最初都按时间戳降序排列。我想以最终列表也按时间戳降序排序的方式合并Foo对象的两个列表。实现这个并不难,但我想知道是否有任何内置的Ruby方法可以做到这一点,因为我认为内置方法会产生最佳性能。谢谢。 最佳答案 这会起作用,但不会提供很好的性能,因为它不会利用事先已经排序的列表:list=(list1+list2).sort_by(&:timestamp)我不知道有任何内置函数可以满足您的需求。 关于
除了使用\x08删除前导字符外,是否可以同时删除尾随字符?是否有一个转义序列将删除下一个字符而不是前一个字符?我看到delete显然映射到ASCII127,即Hex7F,但以下代码:puts"a\x08b\x7fcd"产生b⌂cd我预计\x7f会删除它后面的'c'字符,但它没有。 最佳答案 您实际上并没有使用\x08删除任何内容,您只是用“b”覆盖了“a”。想象一下您使用电传纸质终端的过去。您实际上会在纸上看到的是打印的“a”,电传打字机会备份一个空格,然后在其上打印“b”。所有非打印的ascii码都是为了控制电传纸终端的移动而发明