主项目链接:https://gitee.com/java_wxid/java_wxid
项目架构及博文总结:
项目模块:
前期规划,实现部分
java_wxid
├── demo // 演示模块
│ └── 模块名称:apache-mybatis-demo模块 //Apache Mybatis集成(已实现并有博文总结)
│ └── 模块名称:apache-shardingsphere-demo模块 //Apache ShardingSphere集成(已实现并有博文总结)
│ └── 模块名称:design-demo模块 //设计模式实战落地(已实现并有博文总结)
│ └── 模块名称:elasticsearch-demo模块 //ElasticSearch集成(已实现并有博文总结)
│ └── 模块名称:mongodb-demo模块 //MongoDB集成(已实现并有博文总结)
│ └── 模块名称:redis-demo模块 //Redis集成(已实现并有博文总结)
│ └── 模块名称:spring-boot-demo模块 //Spring Boot快速构建应用(已实现并有博文总结)
│ └── 模块名称:spring-cloud-alibaba-nacos-demo模块 //Spring Cloud Alibaba Nacos集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-alibaba-seata-demo模块 //Spring Cloud Alibaba Seata集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-alibaba-sentinel-demo模块 //Spring Cloud Alibaba Sentinel集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-gateway-demo模块 //Spring Cloud Gateway集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-hystrix-demo模块 //Spring Cloud Hystrix集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-open-feign-demo模块 //Spring Cloud Open Feign集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-ribbon-demo模块 //Spring Cloud Ribbon集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-security-oauth2-demo模块 //Spring Cloud Security Oauth2集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-security-oauth2-sso-client-demo模块 //Spring Cloud Security Oauth2集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-skywalking-demo模块 //Spring Cloud Skywalking集成(已实现并有博文总结)
│ └── 模块名称:spring-cloud-stream-demo模块 //Spring Cloud Stream集成(已实现并有博文总结)
│ └── 模块名称:swagger-demo模块 //springfox-swagger2集成(已实现并有博文总结)
│ └── 模块名称:xxl-job模块 //xxl-job集成(已实现并有博文总结)
│ └── 模块名称:apache-spark-demo模块 //Apache Spark集成
│ └── 模块名称:etl-hdfs-hive-hbase-demo模块 //ETL、HDFS、Hive、Hbase集成
│ └── 模块名称:ddd-mode-demo模块 //DDD领域设计
│ └── 模块名称:netty-demo模块 //Netty集成
│ └── 模块名称:vue-demo模块 //前端vue集成
├── document // 文档
│ └── JavaKnowledgeDocument //java知识点
│ └── java基础知识点.md
│ └── mq知识点.md
│ └── mysql知识点.md
│ └── redis知识点.md
│ └── springcould知识点.md
│ └── spring知识点.md
│ └── FounderDocument //创始人
│ └── 创始人.md
系列文章:快速集成各种微服务相关的技术,帮助大家可以快速集成到自己的项目中,节约开发时间。
提示:系列文章还未全部完成,后续的文章,会慢慢补充进去的。
文章目录
创建一个新的虚拟机,文章地址:https://blog.csdn.net/java_wxid/article/details/127132378
下载软件安装包:
链接:https://pan.baidu.com/s/1XRGHX9lqF21k0gaaHv8ReA?pwd=2022
提取码:2022
–来自百度网盘超级会员V2的分享
安装es可能会出现的错误解决办法:https://blog.csdn.net/ADCadc123456789/article/details/104806771
ES不能使用root用户来启动,必须使用普通用户来安装启动。这里我们创建一个普通用户以及定义一些常规目录用于存放我们的数据文件以及安装包等。
创建一个es专门的用户(必须)
使用root用户在服务器执行以下命令
先创建组, 再创建用户:
1)创建 elasticsearch 用户组
groupadd elasticsearch
2)创建用户 liaozhiwei 并设置密码
useradd liaozhiwei
passwd liaozhiwei
3)# 创建es文件夹,
并修改owner为 liaozhiwei用户
mkdir -p /usr/local/es
4)用户es 添加到 elasticsearch 用户组
usermod -G elasticsearch liaozhiwei
先上传安装包elasticsearch-7.6.1-linux-x86_64.tar.gz进行解压,解压目录为/usr/local/es,然后授权
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz
chown -R liaozhiwei /usr/local/es/elasticsearch-7.6.1
5)设置sudo权限
#为了让普通用户有更大的操作权限,我们一般都会给普通用户设置sudo权限,方便普通用户的操作
#三台机器使用root用户执行visudo命令然后为es用户添加权限
visudo
#在root ALL=(ALL) ALL 一行下面
#添加liaozhiwei用户 如下:
liaozhiwei ALL=(ALL) ALL
#添加成功保存后切换到liaozhiwei用户操作
[root@localhost ~]# su liaozhiwei
[liaozhiwei@localhost root]$
将es的安装包下载并上传到服务器的/user/local/es路径下,然后进行解压
使用liaozhiwei用户来执行以下操作,将es安装包上传到指定服务器,并使用es用户执行以下命令解压。
su root
cd /usr/local/es/
sudo chmod 777 elasticsearch-7.6.1-linux-x86_64.tar.gz
tar -zvxf elasticsearch-7.6.1-linux-x86_64.tar.gz -C /usr/local/es/
进入服务器使用baiqi用户来修改配置文件
cd /usr/local/es/elasticsearch-7.6.1/config
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/data
rm -rf elasticsearch.yml
vim elasticsearch.yml
cluster.name: liaozhiwei-es
node.name: node1
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: 192.168.160.128
http.port: 9200
discovery.seed_hosts: ["192.168.160.128"]
cluster.initial_master_nodes: ["node1"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
修改jvm.option配置文件,调整jvm堆内存大小。
node1.liaozhiwei.cn使用liaozhiwei用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g
由于现在使用普通用户来安装es服务,且es服务对服务器的资源要求比较多,包括内存大小,线程数等。所以我们需要给普通用户解开资源的束缚。
问题错误信息描述:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错,三台机器使用baiqi用户执行以下命令解除打开文件数据的限制。
sudo vi /etc/security/limits.conf
添加如下内容: 注意*不要去掉了
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
普通用户启动线程数限制
问题错误信息描述
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
修改普通用户可以创建的最大线程数
max number of threads [1024] for user [es] likely too low, increase to at least [4096]
原因:无法创建本地线程问题,用户最大可创建线程数太小
解决方案:修改90-nproc.conf 配置文件。
三台机器使用baiqi用户执行以下命令修改配置文件
Centos6
sudo vi /etc/security/limits.d/90-nproc.conf
Centos7
sudo vi /etc/security/limits.d/20-nproc.conf
找到如下内容:
* soft nproc 1024#修改为
* soft nproc 4096
错误信息描述:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因:最大虚拟内存太小,解决方案:调大系统的虚拟内存,每次启动机器都手动执行下。三台机器执行以下命令
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存后,执行:
sysctl -p
备注:以上三个问题解决完成之后,重新连接secureCRT或者重新连接xshell生效
cd /usr/local/es/elasticsearch-7.6.1/bin
./elasticsearch-setup-passwords interactive
这里会设置六个账号的密码:elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user.
我这里统一使用liaozhiwei作为这六个账号的密码
elastic作为我直接访问es的账号
三台机器使用liaozhiwei用户执行以下命令启动es服务
nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
后台启动ES 进入bin目录 ./elasticsearch -d
启动成功之后jsp即可看到es的服务进程,并且访问页面
http://192.168.160.128:9200/?pretty
上面配置了用户密码这里访问也需要输入
elastic
liaozhiwei
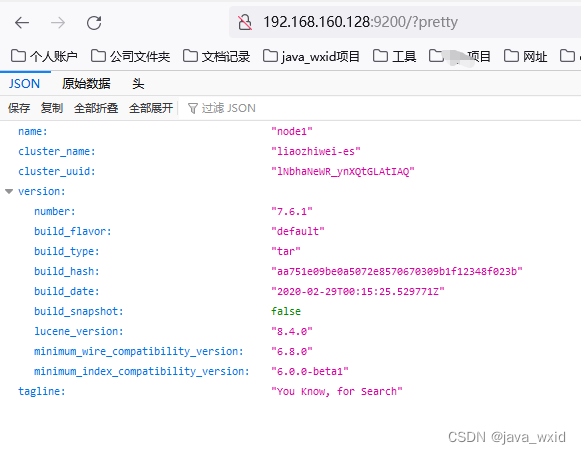
能够看到es启动之后的一些信息
注意:如果哪一台机器服务启动失败,那么就到哪一台机器的
/usr/local/es/elasticsearch-7.6.1/log
这个路径下面去查看错误日志
开启Linux防火墙
systemctl start firewalld
systemctl enable firewalld
centos开放端口宿主机访问
firewall-cmd --add-port=9200/tcp --permanent
firewall-cmd --reload
查询端口是否开启命令
firewall-cmd --query-port=9200/tcp
注意:启动ES的时候出现 Permission denied。原因:当前的用户没有对XX文件或目录的操作权限。
ES主流客户端Kibana,开放9200端口与图形界面客户端交互
1)下载Kibana放之/usr/local/es目录中
2)解压文件:tar -zxvf kibana-X.X.X-linux-x86_64.tar.gz
3)进入/usr/local/es/kibana-X.X.X-linux-x86_64/config目录
4)使用vi编辑器:
vi /usr/local/es/kibana-7.6.1-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "192.168.160.128"
elasticsearch.hosts: ["http://192.168.160.128:9200"]
elasticsearch.username: "kibana"
elasticsearch.password: "liaozhiwei"
i18n.locale: "zh-CN"
centos开放端口宿主机访问
firewall-cmd --add-port=5601/tcp --permanent
firewall-cmd --reload
查询端口是否开启命令
firewall-cmd --query-port=5601/tcp
切换root用户 给es用户这个文件的权限
su root
sudo chown -R liaozhiwei /usr/local/es/kibana-7.6.1-linux-x86_64
5)启动Kibana
./usr/local/es/kibana-7.6.1-linux-x86_64/bin/kibana
后台启动kibana
cd /usr/local/es/kibana-7.6.1-linux-x86_64/bin/
nohup ./kibana &
6)访问Kibana
http://192.168.160.128:5601/app/kibana
上面配置了用户密码这里访问也需要输入
elastic
liaozhiwei
我们后续也需要使用Elasticsearch来进行中文分词,所以需要单独给Elasticsearch安装IK分词器插件。以下为具体安装步骤:
下载Elasticsearch IK分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
切换到liaozhiwei用户,并在es的安装目录下/plugins创建ik
mkdir -p /usr/local/es/elasticsearch-7.6.1/plugins/ik
将下载的ik分词器上传并解压到该目录
cd /usr/local/es/elasticsearch-7.6.1/plugins/ik
unzip elasticsearch-analysis-ik-7.6.1.zip
重启Elasticsearch
ps -ef | grep elastic
kill -9 PID
nohup /usr/local/es/elasticsearch-7.6.1/bin/elasticsearch 2>&1 &
项目代码:https://gitee.com/java_wxid/java_wxid/tree/master/demo/elasticsearch-demo
项目结构如下(示例):
代码如下(示例):
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>elasticsearch-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>elasticsearch-demo</name>
<description>Demo project for Spring Boot</description>
<!-- 属性配置-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<!--引入 Spring Boot、Spring Cloud、Spring Cloud Alibaba 三者 BOM 文件,进行依赖版本的管理,防止不兼容。
在 https://dwz.cn/mcLIfNKt 文章中,Spring Cloud Alibaba 开发团队推荐了三者的依赖关系-->
<spring.boot.version>2.3.12.RELEASE</spring.boot.version>
<spring.cloud.version>Hoxton.SR12</spring.cloud.version>
<spring.cloud.alibaba.version>2.2.7.RELEASE</spring.cloud.alibaba.version>
<elasticsearch.version>7.12.0</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 代表web模块,在这个模块中含了许多JAR包,有spring相关的jar,内置tomcat服务器,jackson等,这些web项目中常用的的功能都会自动引入-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 在SpringBoot 2.4.x的版本之后,对于bootstrap.properties/bootstrap.yaml配置文件(我们合起来成为Bootstrap配置文件)的支持,其实这个jar包里什么都没有,就只有一个标识类Marker,用来标识要开启Bootstrap配置文件的支持,由于父类用了2.5.6版本需要导入如下的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
<version>3.1.0</version>
</dependency>
<!-- 重写覆盖 spring-boot-dependencies 中的依赖版本 -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.2.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<!-- lombok插件-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
</dependencies>
<!--
引入 Spring Boot、Spring Cloud、Spring Cloud Alibaba 三者 BOM 文件,进行依赖版本的管理,防止不兼容。
在 https://dwz.cn/mcLIfNKt 文章中,Spring Cloud Alibaba 开发团队推荐了三者的依赖关系
-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring.cloud.alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
代码如下(示例):
package com.example.elasticsearchdemo.controller;
import com.example.elasticsearchdemo.model.Userinfo;
import com.example.elasticsearchdemo.service.ElasticsearchService;
import org.springframework.data.elasticsearch.core.SearchPage;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.Iterator;
/**
* @author zhiwei Liao
* @Description
* @Date create in 2022/9/12 0012 21:03
*/
@RestController
public class ElasticSearchController {
@Autowired
private ElasticsearchService elasticsearchService;
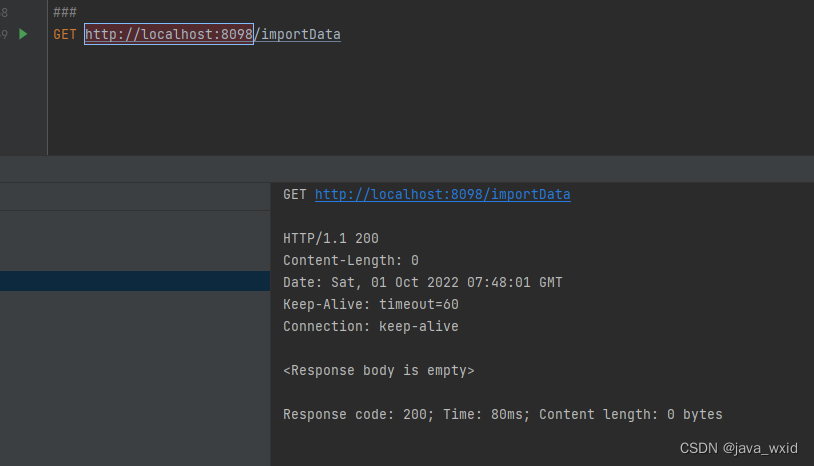
@GetMapping("/importData")
public void importData() {
elasticsearchService.importData();
}
@GetMapping("/search")
public SearchPage<Userinfo> search(){
return elasticsearchService.search();
}
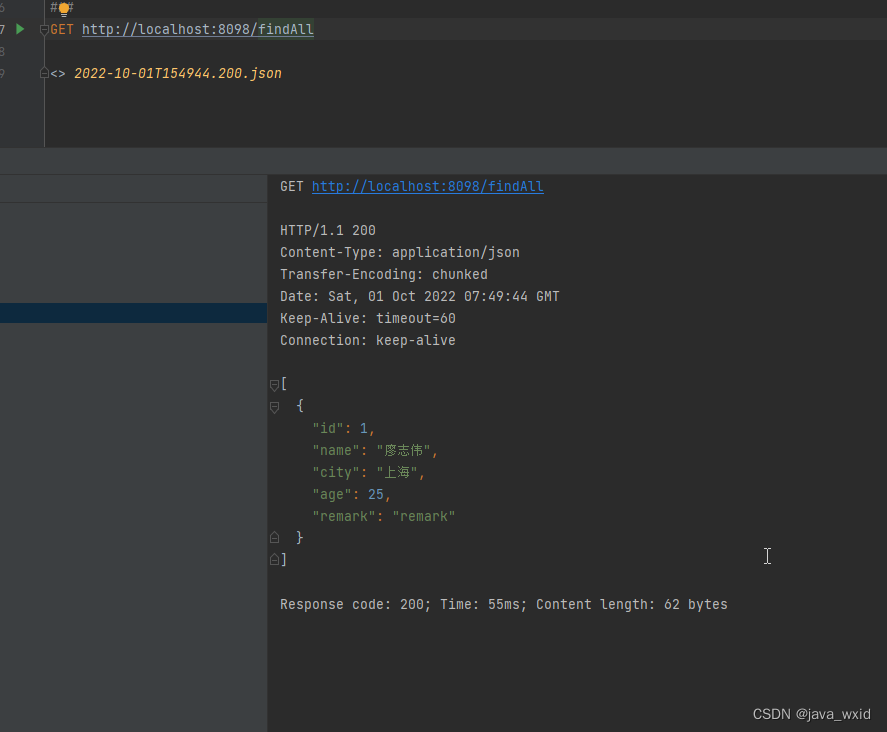
@GetMapping("/findAll")
public Iterator<Userinfo> findAll(){
return elasticsearchService.findAll();
}
}
代码如下(示例):
package com.example.elasticsearchdemo.dao;
/**
* @author zhiwei Liao
* @Description
* @Date create in 2022/9/12 0012 21:03
*/
import com.example.elasticsearchdemo.model.Userinfo;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
//Userinfo对应实体 Long对应主键
public interface ElasticsearchDao extends ElasticsearchRepository<Userinfo,Long> {
}
代码如下(示例):
package com.example.elasticsearchdemo.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
/**
* @author zhiwei Liao
* @Description
* @Date create in 2022/9/12 0012 21:03
*/
@Data
@Document(indexName = "user", shards = 2, replicas = 2) //对应索引库和类型
public class Userinfo implements Serializable {
@Id
@Field(store = false, type = FieldType.Long)
private long id;
@Field(store = false, type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String name;
@Field(store = false, type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String city;
@Field(store = false, type = FieldType.Long)
private Integer age;
@Field(store = false, type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String remark;
}
代码如下(示例):
package com.example.elasticsearchdemo.service;
import com.example.elasticsearchdemo.model.Userinfo;
import org.springframework.data.elasticsearch.core.SearchPage;
import java.util.Iterator;
/**
* @author zhiwei Liao
* @Description
* @Date create in 2022/9/12 0012 21:03
*/
public interface ElasticsearchService {
void importData();
SearchPage<Userinfo> search();
Iterator<Userinfo> findAll();
}
代码如下(示例):
package com.example.elasticsearchdemo.service.impl;
import com.example.elasticsearchdemo.dao.ElasticsearchDao;
import com.example.elasticsearchdemo.model.Userinfo;
import com.example.elasticsearchdemo.service.ElasticsearchService;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedLongTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHitSupport;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.SearchPage;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/**
* @author zhiwei Liao
* @Description
* @Date create in 2022/9/12 0012 21:03
*/
@Service
public class ElasticsearchServiceImpl implements ElasticsearchService {
@Autowired
private ElasticsearchDao dao;
@Resource
private ElasticsearchDao elasticsearchDao;
@Resource
private ElasticsearchRestTemplate elasticsearchTemplate;
/** @description 导入数据
* @params []
* @return void
* @author lxy
* @date 2020/9/29 11:06
**/
@Override
public void importData(){
//从mysql查出所有数据 一般来说可以先查出来是一个对象javabean,然后转换成索引对象Userinfo就行,我这里是直接用的userinfo对象
List<Userinfo> user = new ArrayList<>();
Userinfo userinfo = new Userinfo();
userinfo.setAge(25);
userinfo.setCity("上海");
userinfo.setName("廖志伟");
userinfo.setRemark("remark");
userinfo.setId(1);
user.add(userinfo);
//导入到es
dao.saveAll(user);
}
/** @description es搜索
* @params [parm]
* @return java.util.List<com.bwwl.hive.model.Userinfo>
* @author lxy
* @date 2020/9/29 11:32
**/
@Override
public SearchPage<Userinfo> search() {
//TODO 构建查询对象用于封装各种查询条件 NativeSearchQueryBuilder
//1.构建查询对象
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("name")
.field("age").size(30));
SearchHits<Userinfo> search = elasticsearchTemplate.search(nativeSearchQueryBuilder.build(), Userinfo.class);
int pageNo = 1;
int pageSize = 5;
Pageable pageable = PageRequest.of(pageNo - 1, pageSize);
//7.获取分页数据
SearchPage<Userinfo> searchPageResult = SearchHitSupport.searchPageFor(search, pageable);
System.out.println(String.format("totalPages:%d, pageNo:%d, size:%d", searchPageResult.getTotalPages(), pageNo, pageSize));
return searchPageResult;
}
@Override
public Iterator<Userinfo> findAll() {
return elasticsearchDao.findAll().iterator();
}
}
代码如下(示例):
server:
port: 8098
spring:
application:
name: elasticsearch-demo
elasticsearch:
rest:
username: elastic
password: liaozhiwei
uris: http://192.168.160.128:9200
connection-timeout: 1000
read-timeout: 1000
如下图(示例):

如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht