让我们来看看ChatGPT不能通过Oracle OCP的考试?
ChatGPT已经通过了很多考试,姚远老师是Oracle OCP和MySQL OCP讲师,我很好奇ChatGPT能不能通过Oracle OCP的考试呢?让我们拿Oracle 19c OCP考试(1z0-082)的真题对ChatGPT进行一个测试。
第1道题ChatGPT就做错了,姚远老师心里不禁窃喜,看来ChatGPT也不咋地,我们也许不会失业,让我们来看看第一道题的题目:
Which two statements are true about space-saving features in an Oracle Database?
A.An index created with the UNUSABLE attribute has no segment.
B.Private Temporary Tables(PTTs) store metadata in memory only.
C.Private Temporary Tables(PTTs) when used, are always dropped at the next commit statement. D.An index that is altered to be UNUSABLE will retain its segment
E. A table that is truncated will always have all of its extents removed
ChatGPT的答案是B和C,B是对的,但ChatGPT选择了一个错误的答案C:
Private Temporary Tables(PTTs) when used, are always dropped at the next commit statement.
实际上PTT有两种:Transaction-specific (ON COMMIT DROP DEFINITION)和session-specific (ON COMMIT PRESERVE DEFINITION)。这两种在commit时都会删除表中的数据,但第二种是不会删除表定义的,因此C是错的。
ChatGPT忽略了一个正确的答案A,于是姚远老师问ChatGPT:你为什么没有选择A,请你做一个实验,创建一个UNUSABLE的索引试试?
ChatGPT回答:作为一个AI语言模型,我没有直接的物理数据库来创建索引。…
现在我知道ChatGPT为什么会做错了,因为ChatGPT没有实验环境。
我自己实验了一下:
SQL> create index in_1 on table_1(no) unusable;
Index created.
SQL> select segment_name,blocks from user_segments where segment_name in ('IN_1');
no rows selected
SQL> alter index in_1 rebuild;
Index altered.
SQL> select segment_name,blocks from user_segments where segment_name in ('IN_1');
SEGMENT_NAME BLOCKS
-------------------- ----------
IN_1 8
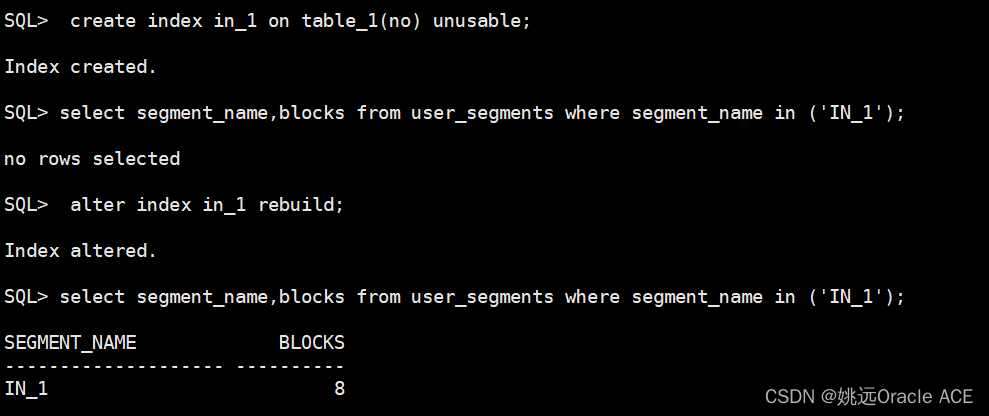
发现创建索引时为unusable是不创建段的,只有重建索引才会有段。
第2道题是关于视图的,ChatGPT对 WITH CHECK的限制很清楚,做对了。
第3道题是PMON进程的作业,ChatGPT还知道从12c后PMON注册监听的功能交给了LRRG进程负责,也做对了。
第4道题是集合的 INTERSECT操作,ChatGPT也做对了。
第5道题是用户的最小权限原则,ChatGPT也做对了。
第6 道题是关于回滚段的题目,ChatGPT做错了,ChatGPT认为:Undo segments can be stored in the SYSTEM tablespace.这个选项是错的,ChatGPT给出的理由是: Undo segments are stored in the undo tablespace, not in the SYSTEM tablespace.
实际上在自动回滚段管理时,如果没有undo表空间,回滚段是可以放在系统表空间中的,在Oracle的官方文档中有下面的内容:
When the database instance starts, the database automatically selects the first available undo tablespace. If no undo tablespace is available, then the instance starts without an undo tablespace and stores undo records in the SYSTEM tablespace. This is not recommended, and an alert message is written to the alert log file to warn that the system is running without an undo tablespace.
感觉ChatGPT做这个选择有点想当然。
第7道题是日期的计算,也做对了。
第8道题做错了,ChatGPT选择了一个下面这个选项:
Directory Naming requires setting the TNS_ADMIN environment variable on the client side.
实际上TNS_ADMIN环境变量不是必需设置的,只有ORACLE_HOME设置了即可。
第9道题错了,ChatGPT选择了一个错误的答案 :
Any user can create a PUBLIC synonym.
实际上即使创建PUBLIC的同义词,也需要 CREATE PUBLIC SYNONYM的系统权限。
ChatGPT还忽略了一个正确的答案:A synonym can have a synonym。
第10道题是关于直接路径导入的压缩格式,这个知识点在Oracle官方文档上面写的清清楚楚,ChatGPT做对了
第11道题是关于延迟段创建特性,ChatGPT也做对了
测试进行到这里,ChatGPT一共做了11道题,错了4道题,正确率为63.6%,而Oracle 19C OCP的1Z0-082的及格线是60%,ChatGPT涉险过关!
更多的Oracle OCP和MySQL OCP题库的解析可以参见:
Oracle 19c OCP和MySQL 8.0 OCP应试指南和题库讲解
姚远老师分析了ChatGPT解题的特点,发现ChatGPT对于在业界答案没有争议的题目做得很好,但ChatGPT也有两个弱点,一个是ChatGPT没有真正的一个Oracle数据库进行实验,因此在解答需要实验验证的题目时很吃亏;另一个是ChatGPT不擅长解决概念上比较绕的问题。但总体来说,ChatGPT已经可以胜任一个初级DBA的工作了,只是对ChatGPT的给出的答案需要一个资深的DBA进行二次验证。
大家觉得ChatGPT能代替Oracle DBA吗?请留言聊一下。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我有:When/^(?:|I)follow"([^"]*)"(?:within"([^"]*)")?$/do|link,selector|with_scope(selector)doclick_link(link)endend我打电话的地方:Background:GivenIamanexistingadminuserWhenIfollow"CLIENTS"我的HTML是这样的:CLIENTS我一直收到这个错误:.F-.F--U-----U(::)failedsteps(::)nolinkwithtitle,idortext'CLIENTS'found(Capybara::Element