本文的教程仅为个人的操作经验所写,每个人下载的版本不一样,所以会出现不同的情况异常等,如有问题可询问博主或百度查找解决方法。
本机的配置环境如下:
hadoop(3.3.1)
jdk版本(jdk-8)
Linux(64位)
在Ubuntu中用压缩包安装jdk较为麻烦,需要配置系统环境变量和配置文件,一步出错可能无法使用。所以本文在Ubuntu中使用命令安装jdk。其他方法安装jdk也可。
打开终端
执行以下命令:
sudo apt-get install openjdk-8-jdk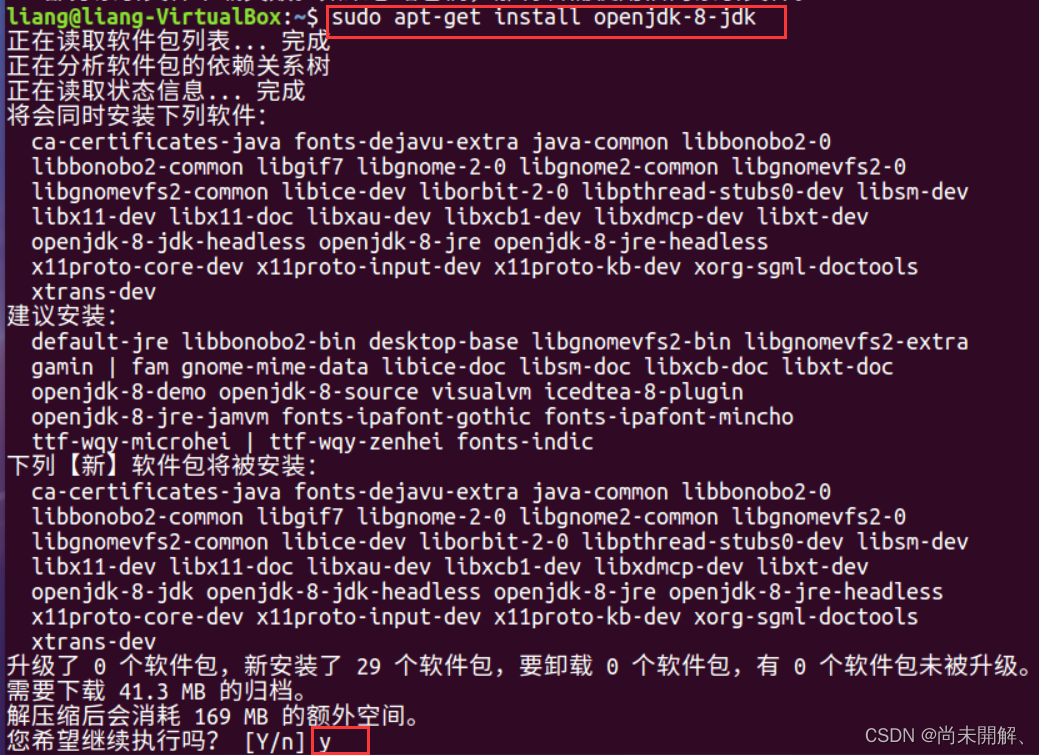
输入y回车,等待安装完成
java -version安装完成后用 java -version 检验是否安装成功,如果如下图则安装成功
当想要卸载jdk则使用以下命令:sudo apt remove openjdk*

打开环境文件
sudo gedit ~/.bashrc
文件顶部加入以下语句并保存
sudo apt-get install openjdk-8-jdk 命令安装的jdk默认路径为 /usr/lib/jvm/java-8-openjdk-amd64
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 #目录要换成自己jdk所在目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH 使环境生效
source ~/.bashrc 使用 echo $JAVA_HOME 显示JAVA_HOME即为成功
sudo apt-get install ssh openssh-server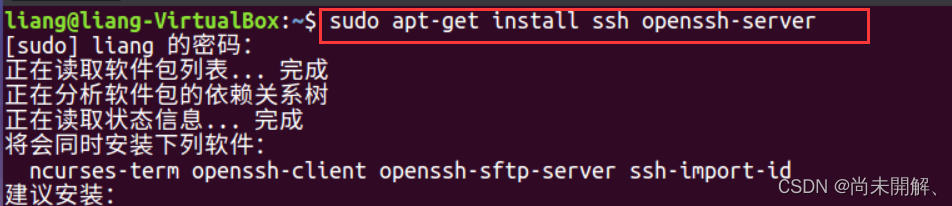
安装完毕后,在终端中依次进行继以下命令操作
cd ~/.ssh/生成密钥
ssh-keygen -t rsa 将秘钥加入到授权中
cat id_rsa.pub >> authorized_keys再验证ssh localhost 如下图,不用密码登录即为成功。
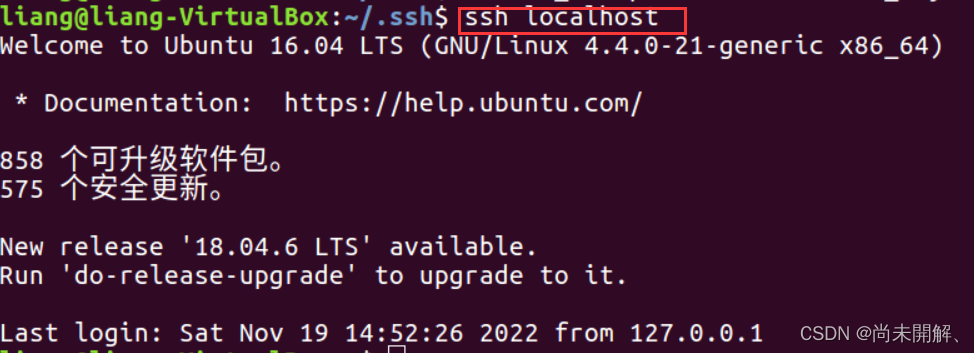
1)安装hadoop并解压
镜像下载链接https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/
下载好的压缩包传到 /usr/local/目录下
使用如下命令解压缩Hadoop安装包:
tar -zxvf hadoop-3.1.1.tar.gz
解压完成之后进入hadoop-3.1.1文件内容如下:

2) 配置相关文件
core-site.xml
打开/etc中的core-site.xml 文件,加入如下语句并保存
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.3.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
注意其中路径要修改为自己的

hdfs-site.xml
和上面一样,打开/etc中的hdfs-site.xml 文件,加入如下语句并保存
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.3.1/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.3.1/tmp/dfs/data</value>
</property>
hadoop-env.sh
查看你的 jdk安装目录
echo $JAVA_HOME
打开 hadoop-env.sh 文件配置如下并保存:
export JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64" # 根据自己的路径写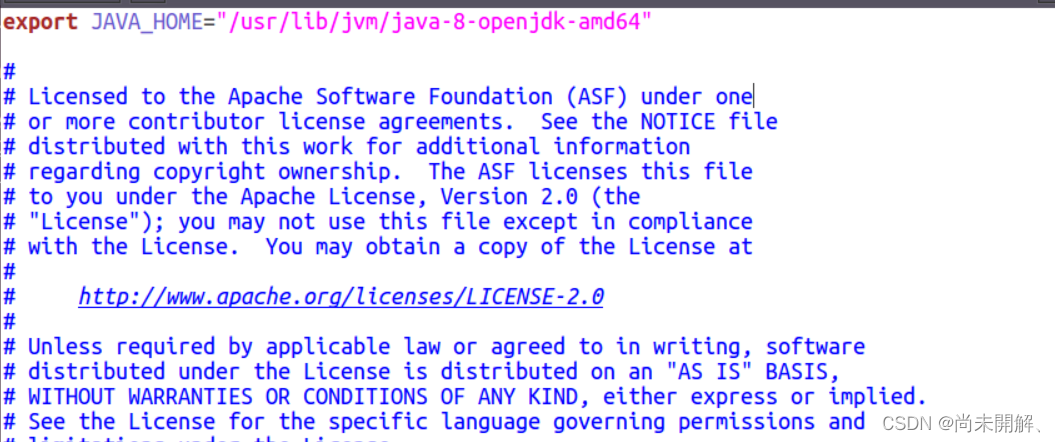
1)首先初始化HDFS系统
在hadop3.3.0目录下使用如下命令进行初始化:
bin/hdfs namenode -format成功后如下图:

2)开启NameNode和DataNode守护进程
继续运行如下命令开启hadoop
sbin/start-dfs.sh成功如下图:

3)查看jps进程信息
jps
如下图即为成功

关闭hadoop使用命令 sbin/stop-dfs.sh
打开浏览器输入http://localhost:9870,成功打开

4)创建hadoop用户组
使用/bin/bash作为shell sudo useradd -m hadoop -s /bin/bash
设置密码 sudo passwd hadoop
添加hadoop至管理员权限 sudo adduser hadoop sudo
搭建前请保证已经搭建好了HDFS的环境,即配置好所上内容。
1)终端输入hostname查看主机名
hostname2)打开/etc下yarn-site.xml,在在configuration标签中加入如下,注意主机名要修改为自己的
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--Resource Manager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>liang-VirtualBox</value><!--你的hostname的主机名-->
</property>3)打开mapred-site.xml 文件,配置如下(在configuration标签中间加入)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4)输入命令启动yarn
sbin/start-yarn.sh
jps查看进程信息多了两个东西
成功启动如下图

在浏览器输入主机名:8088 打开成功

JobHistory用来记录已经finished的mapreduce运行日志,日志信息存放于HDFS目录中,默认情况下没有开启此功能,需要在mapred-site.xml、yarn-site.xml配置,并手动启动
mapred-site.xml添加如下配置(在configuration标签中间加入)
<property>
<name>mapreduce.jobhistory.address</name>
<value>主机名:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主机名:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value></property>
yarn-site.xml添加如下配置(在configuration标签中间加入)
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
hadoop fs -ls /history查看历史记录

开启history进程
mapred --daemon start historyserver通过浏览器访问 主机名:19888
成功如下图
至此,hadoop全部配置完成,可下载eclipse进行wordcount等运算实验。
如有任何疑问,请留言,尽仅有所学帮助。
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应