 作者更是表示,如果你有 8 个 GPU 可用,整个训练过程只需要 2 分钟,实现 11.5 倍的性能加速。
作者更是表示,如果你有 8 个 GPU 可用,整个训练过程只需要 2 分钟,实现 11.5 倍的性能加速。 下面我们来看看他到底是如何实现的。
下面我们来看看他到底是如何实现的。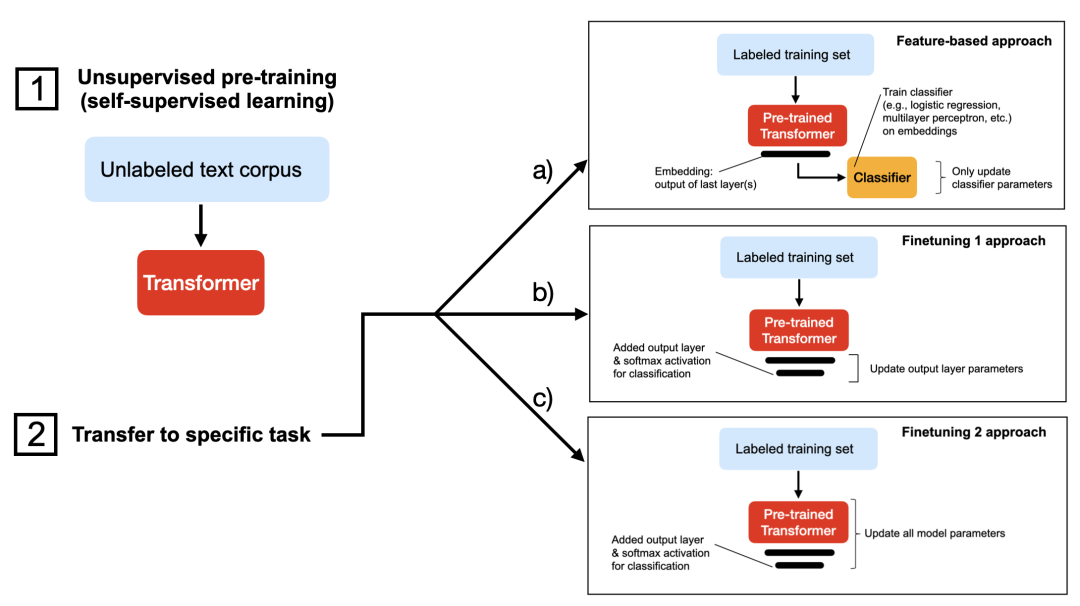 基本任务交代清楚后,下面就是 PyTorch 的训练过程。为了让大家更好地理解这项任务,作者还贴心地介绍了一下热身练习,即如何在 IMDB 电影评论数据集上训练 DistilBERT 模型。如果你想自己运行代码,可以使用相关的 Python 库设置一个虚拟环境,如下所示:相关软件的版本如下:
基本任务交代清楚后,下面就是 PyTorch 的训练过程。为了让大家更好地理解这项任务,作者还贴心地介绍了一下热身练习,即如何在 IMDB 电影评论数据集上训练 DistilBERT 模型。如果你想自己运行代码,可以使用相关的 Python 库设置一个虚拟环境,如下所示:相关软件的版本如下: 现在省略掉枯燥的数据加载介绍,只需要了解本文将数据集划分为 35000 个训练示例、5000 个验证示例和 10000 个测试示例。需要的代码如下:
现在省略掉枯燥的数据加载介绍,只需要了解本文将数据集划分为 35000 个训练示例、5000 个验证示例和 10000 个测试示例。需要的代码如下: 代码部分截图完整代码地址:https://github.com/rasbt/faster-pytorch-blog/blob/main/1_pytorch-distilbert.py然后在 A100 GPU 上运行代码,得到如下结果:
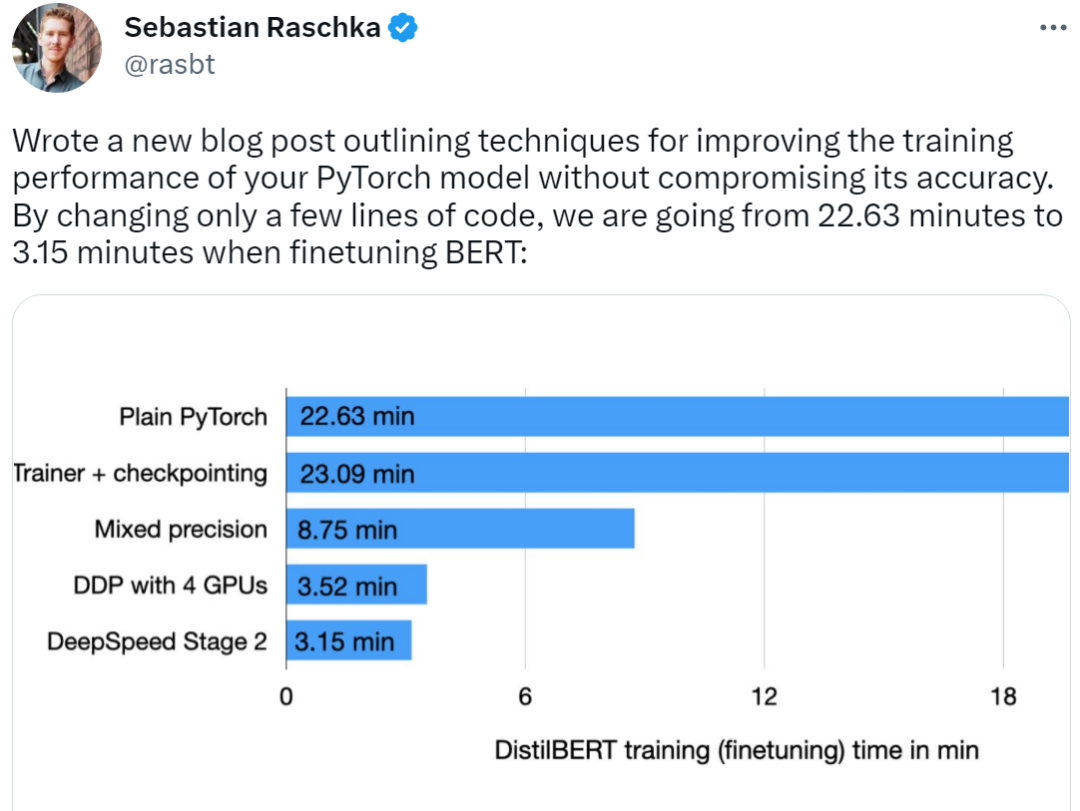
代码部分截图完整代码地址:https://github.com/rasbt/faster-pytorch-blog/blob/main/1_pytorch-distilbert.py然后在 A100 GPU 上运行代码,得到如下结果: 部分结果截图正如上述代码所示,模型从第 2 轮到第 3 轮开始有一点过拟合,验证准确率从 92.89% 下降到了 92.09%。在模型运行了 22.63 分钟后进行微调,最终的测试准确率为 91.43%。使用 Trainer 类接下来是改进上述代码,改进部分主要是把 PyTorch 模型包装在 LightningModule 中,这样就可以使用来自 Lightning 的 Trainer 类。部分代码截图如下:
部分结果截图正如上述代码所示,模型从第 2 轮到第 3 轮开始有一点过拟合,验证准确率从 92.89% 下降到了 92.09%。在模型运行了 22.63 分钟后进行微调,最终的测试准确率为 91.43%。使用 Trainer 类接下来是改进上述代码,改进部分主要是把 PyTorch 模型包装在 LightningModule 中,这样就可以使用来自 Lightning 的 Trainer 类。部分代码截图如下: 完整代码地址:https://github.com/rasbt/faster-pytorch-blog/blob/main/2_pytorch-with-trainer.py上述代码建立了一个 LightningModule,它定义了如何执行训练、验证和测试。相比于前面给出的代码,主要变化是在第 5 部分(即 ### 5 Finetuning),即微调模型。与以前不同的是,微调部分在 LightningModel 类中包装了 PyTorch 模型,并使用 Trainer 类来拟合模型。
完整代码地址:https://github.com/rasbt/faster-pytorch-blog/blob/main/2_pytorch-with-trainer.py上述代码建立了一个 LightningModule,它定义了如何执行训练、验证和测试。相比于前面给出的代码,主要变化是在第 5 部分(即 ### 5 Finetuning),即微调模型。与以前不同的是,微调部分在 LightningModel 类中包装了 PyTorch 模型,并使用 Trainer 类来拟合模型。 之前的代码显示验证准确率从第 2 轮到第 3 轮有所下降,但改进后的代码使用了 ModelCheckpoint 以加载最佳模型。在同一台机器上,这个模型在 23.09 分钟内达到了 92% 的测试准确率。
之前的代码显示验证准确率从第 2 轮到第 3 轮有所下降,但改进后的代码使用了 ModelCheckpoint 以加载最佳模型。在同一台机器上,这个模型在 23.09 分钟内达到了 92% 的测试准确率。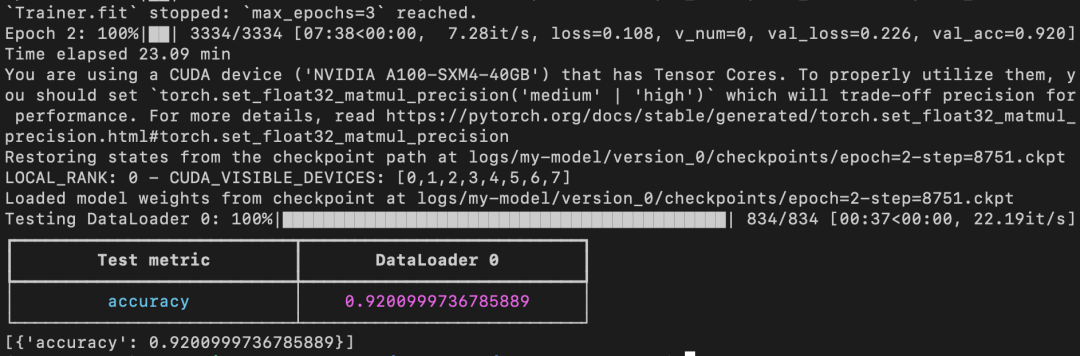 需要注意,如果禁用 checkpointing 并允许 PyTorch 以非确定性模式运行,本次运行最终将获得与普通 PyTorch 相同的运行时间(时间为 22.63 分而不是 23.09 分)。自动混合精度训练进一步,如果 GPU 支持混合精度训练,可以开启 GPU 以提高计算效率。作者使用自动混合精度训练,在 32 位和 16 位浮点之间切换而不会牺牲准确率。
需要注意,如果禁用 checkpointing 并允许 PyTorch 以非确定性模式运行,本次运行最终将获得与普通 PyTorch 相同的运行时间(时间为 22.63 分而不是 23.09 分)。自动混合精度训练进一步,如果 GPU 支持混合精度训练,可以开启 GPU 以提高计算效率。作者使用自动混合精度训练,在 32 位和 16 位浮点之间切换而不会牺牲准确率。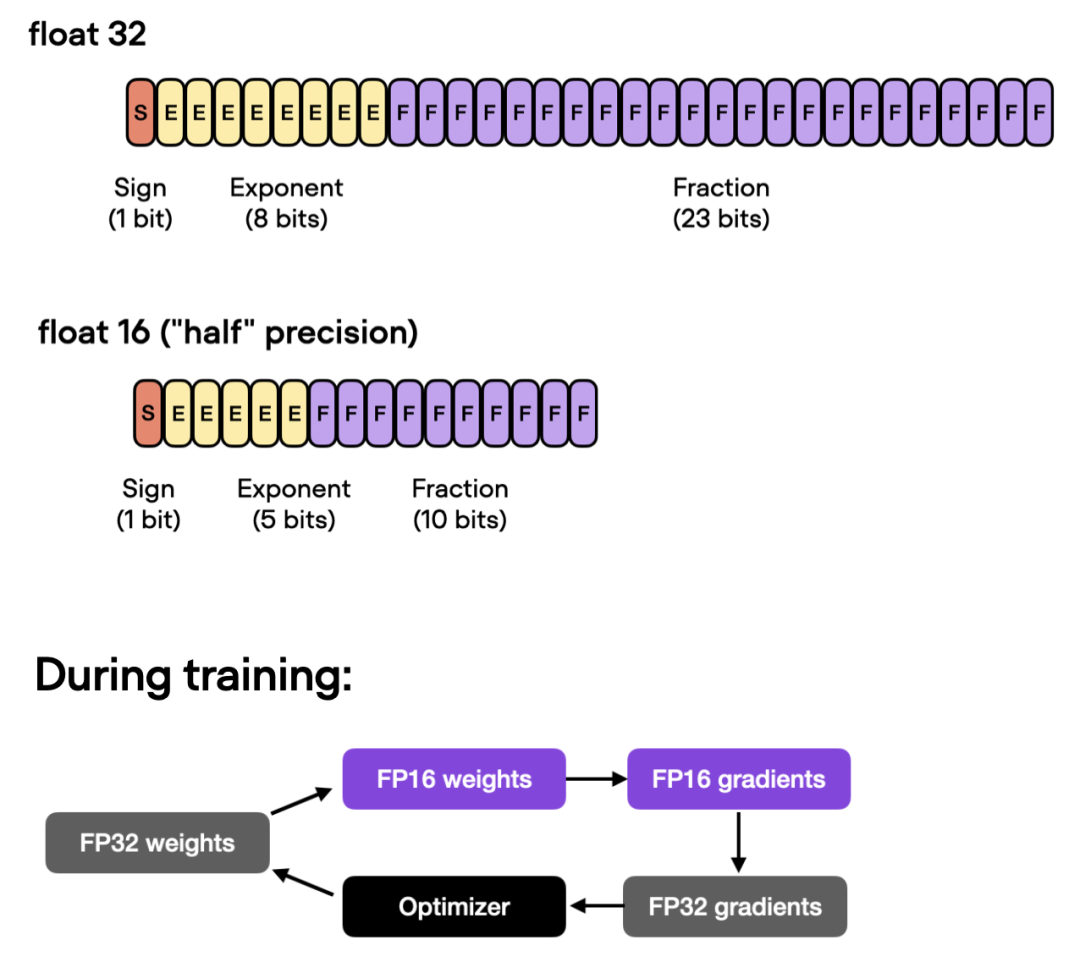 在这一优化下,使用 Trainer 类,即能通过一行代码实现自动混合精度训练:
在这一优化下,使用 Trainer 类,即能通过一行代码实现自动混合精度训练: 上述操作可以将训练时间从 23.09 分钟缩短到 8.75 分钟,这几乎快了 3 倍。测试集的准确率为 92.2%,甚至比之前的 92.0% 还略有提高。
上述操作可以将训练时间从 23.09 分钟缩短到 8.75 分钟,这几乎快了 3 倍。测试集的准确率为 92.2%,甚至比之前的 92.0% 还略有提高。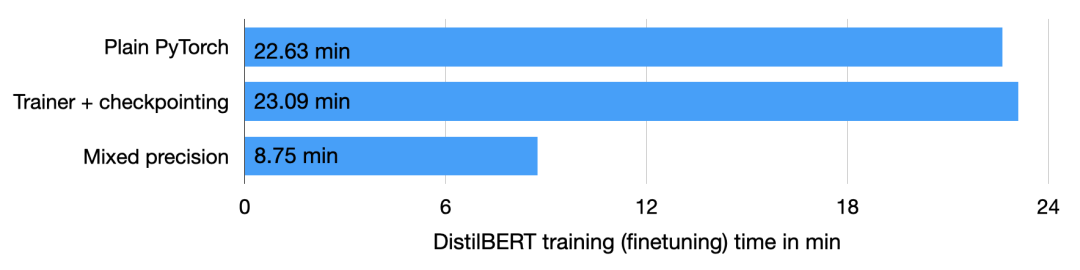 使用 Torch.Compile 静态图最近 PyTorch 2.0 公告显示,PyTorch 团队引入了新的 toch.compile 函数。该函数可以通过生成优化的静态图来加速 PyTorch 代码执行,而不是使用动态图运行 PyTorch 代码。
使用 Torch.Compile 静态图最近 PyTorch 2.0 公告显示,PyTorch 团队引入了新的 toch.compile 函数。该函数可以通过生成优化的静态图来加速 PyTorch 代码执行,而不是使用动态图运行 PyTorch 代码。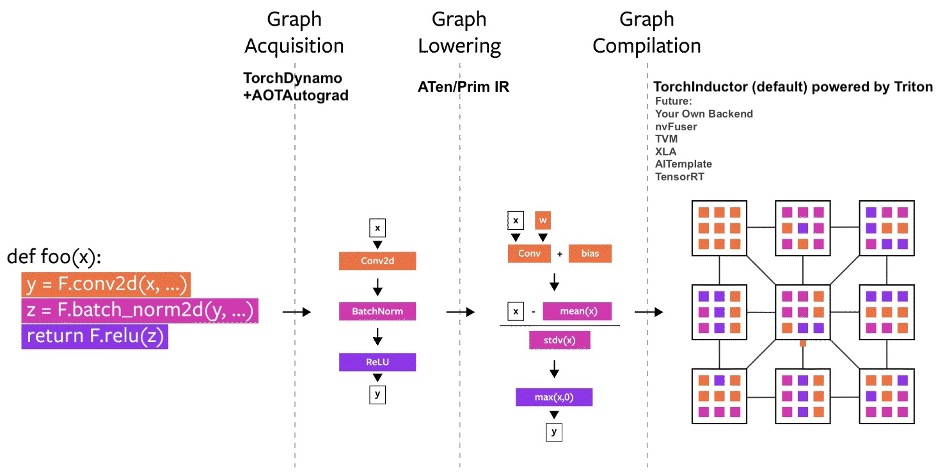 由于 PyTorch 2.0 尚未正式发布,因而必须先要安装 torchtriton,并更新到 PyTorch 最新版本才能使用此功能。
由于 PyTorch 2.0 尚未正式发布,因而必须先要安装 torchtriton,并更新到 PyTorch 最新版本才能使用此功能。
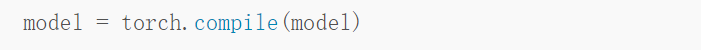 在 4 块 GPU 上进行分布式数据并行上文介绍了在单 GPU 上加速代码的混合精度训练,接下来介绍多 GPU 训练策略。下图总结了几种不同的多 GPU 训练技术。
在 4 块 GPU 上进行分布式数据并行上文介绍了在单 GPU 上加速代码的混合精度训练,接下来介绍多 GPU 训练策略。下图总结了几种不同的多 GPU 训练技术。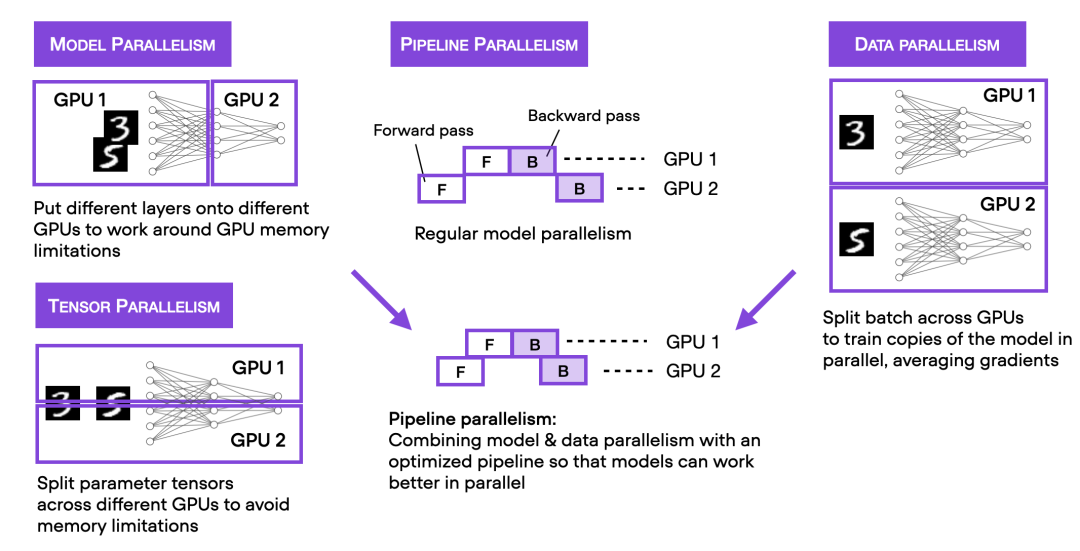 想要实现分布式数据并行,可以通过 DistributedDataParallel 来实现,只需修改一行代码就能使用 Trainer。
想要实现分布式数据并行,可以通过 DistributedDataParallel 来实现,只需修改一行代码就能使用 Trainer。 经过这一步优化,在 4 个 A100 GPU 上,这段代码运行了 3.52 分钟就达到了 93.1% 的测试准确率。
经过这一步优化,在 4 个 A100 GPU 上,这段代码运行了 3.52 分钟就达到了 93.1% 的测试准确率。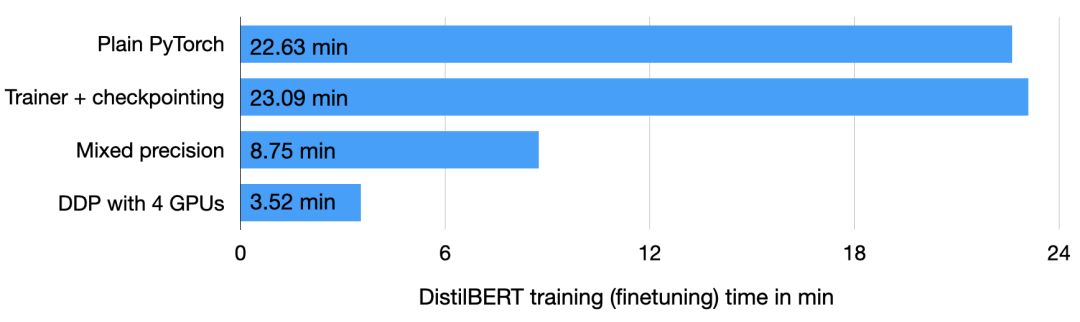
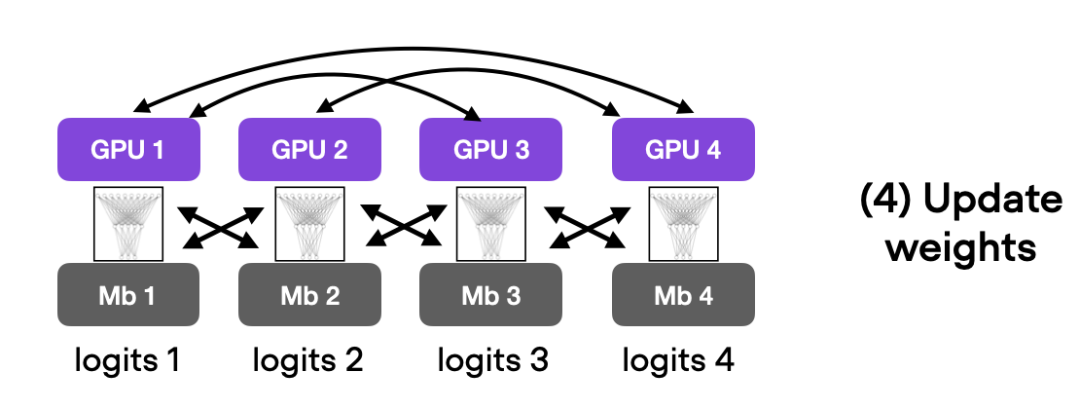 DeepSpeed最后,作者探索了在 Trainer 中使用深度学习优化库 DeepSpeed 以及多 GPU 策略的结果。首先必须安装 DeepSpeed 库:
DeepSpeed最后,作者探索了在 Trainer 中使用深度学习优化库 DeepSpeed 以及多 GPU 策略的结果。首先必须安装 DeepSpeed 库: 接着只需更改一行代码即可启用该库:
接着只需更改一行代码即可启用该库: 这一波下来,用时 3.15 分钟就达到了 92.6% 的测试准确率。不过 PyTorch 也有 DeepSpeed 的替代方案:fully-sharded DataParallel,通过 strategy="fsdp" 调用,最后花费 3.62 分钟完成。
这一波下来,用时 3.15 分钟就达到了 92.6% 的测试准确率。不过 PyTorch 也有 DeepSpeed 的替代方案:fully-sharded DataParallel,通过 strategy="fsdp" 调用,最后花费 3.62 分钟完成。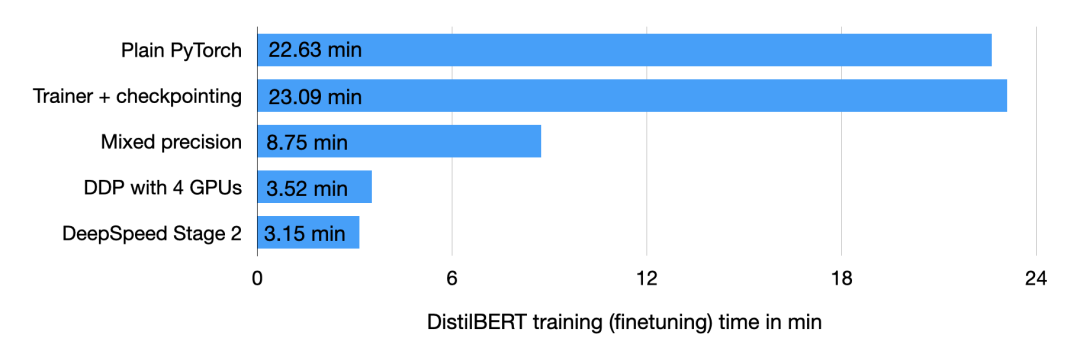 以上就是作者提高 PyTorch 模型训练速度的方法,感兴趣的小伙伴可以跟着原博客尝试一下,相信你会得到想要的结果。
以上就是作者提高 PyTorch 模型训练速度的方法,感兴趣的小伙伴可以跟着原博客尝试一下,相信你会得到想要的结果。 我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我需要检查DateTime是否采用有效的ISO8601格式。喜欢:#iso8601?我检查了ruby是否有特定方法,但没有找到。目前我正在使用date.iso8601==date来检查这个。有什么好的方法吗?编辑解释我的环境,并改变问题的范围。因此,我的项目将使用jsapiFullCalendar,这就是我需要iso8601字符串格式的原因。我想知道更好或正确的方法是什么,以正确的格式将日期保存在数据库中,或者让ActiveRecord完成它们的工作并在我需要时间信息时对其进行操作。 最佳答案 我不太明白你的问题。我假设您想检查