本文是关于使用flutter_download_manager下载功能的实践和探索。我们将基于flutter_download_manager的功能扩展,改造成自己想要的样子。在阅读本文之前,建议先了解前两篇文章:
本文将基于第二篇中的扩展框架,将网络库从dio切换为httpclient,并结合改造过程中发现的问题提出自己的想法。
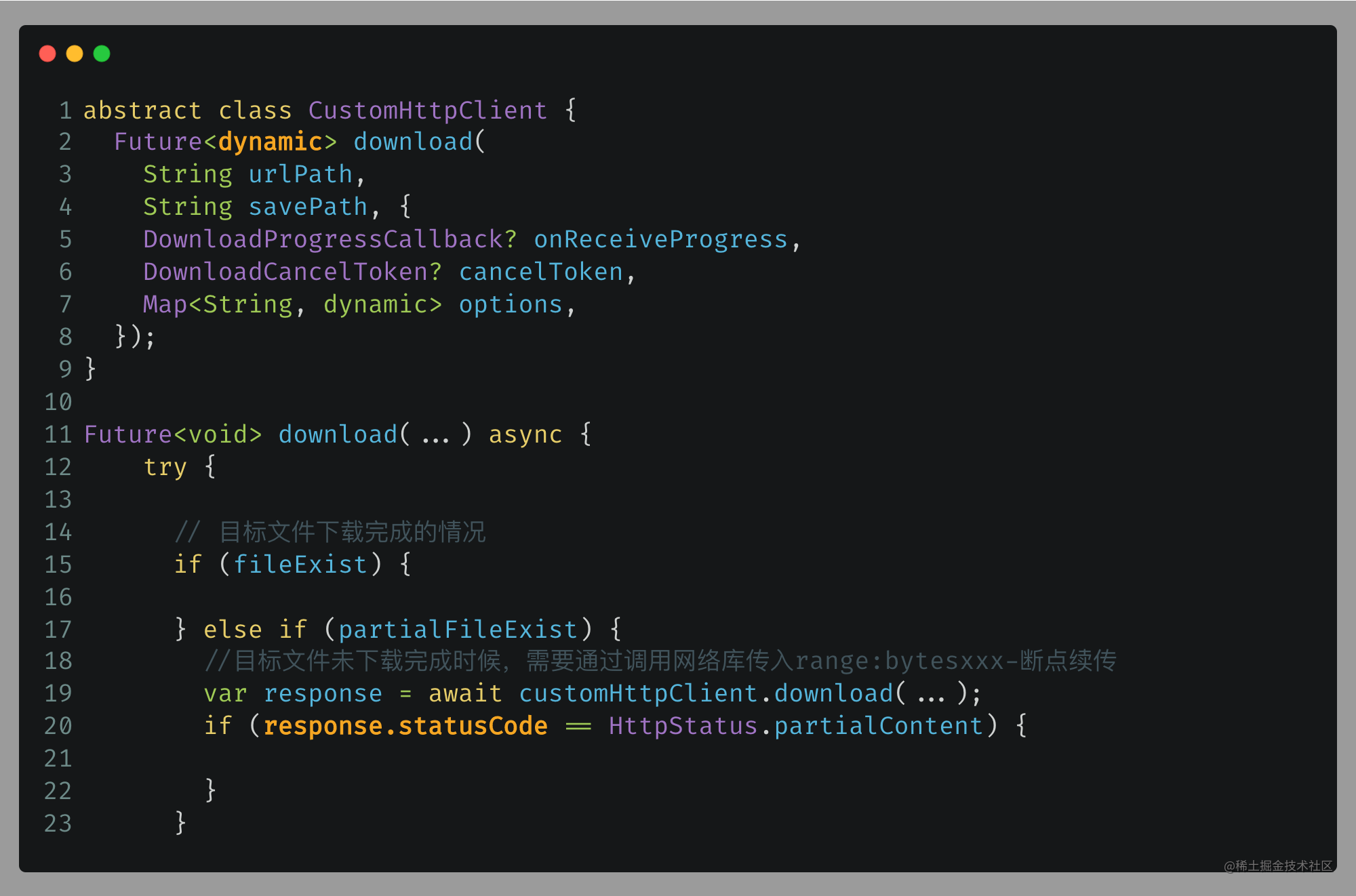
在第2和20行中,黄色标记表明,如果第2行中的每个网络库下载的返回值可能不同,则考虑将其设置为“dynamic”,这可能导致第20行中出现响应状态码的告警,因为该属性可能不存在。
为了确保 download 接口的返回值具有 statusCode 属性,在这里定义了一个专门的返回类以进行限制。具体定义如下:
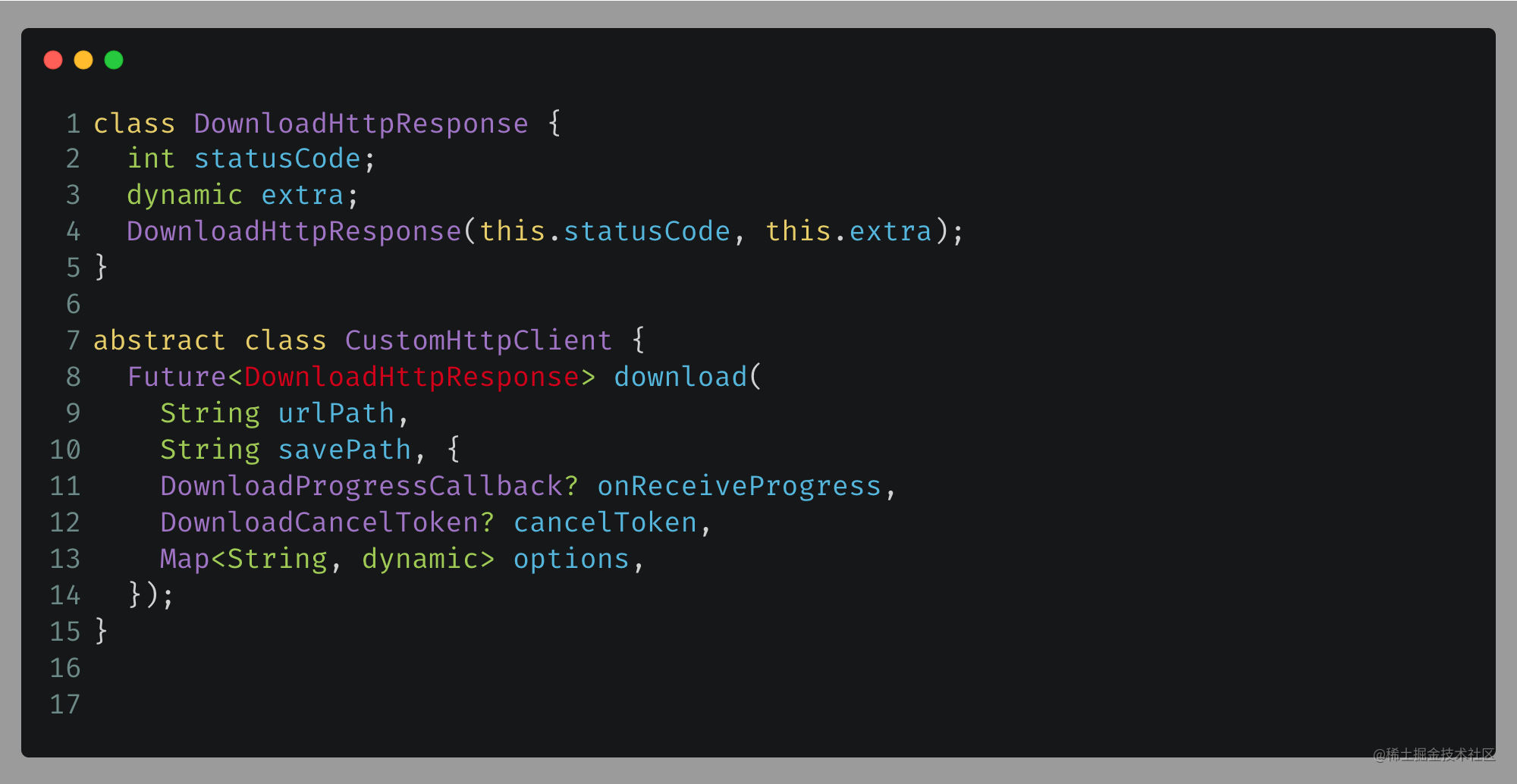
这样就解决了statusCode告警问题,其中extra可以存放原始download response对象。
只用实现上一篇中的网络接口CustomHttpClient,然后修改IDownloader:createObject其中网络注入对象即可,如下:
//实现这个接口定义
abstract class CustomHttpClient {
Future<DownloadHttpResponse> download(
String urlPath,
String savePath, {
DownloadProgressCallback? onReceiveProgress,
DownloadCancelToken? cancelToken,
Map<String, dynamic>? options,
});
DownloadCancelToken generateToken();
}
------【idownloader.dart】----------
abstract class IDownloader {
factory IDownloader() => createObject(
//将这个注入修改成我们实现的即可 原来:customHttpClient: CustomDioImpl(),
customHttpClient: CustomHttpClientImp(),
);
}
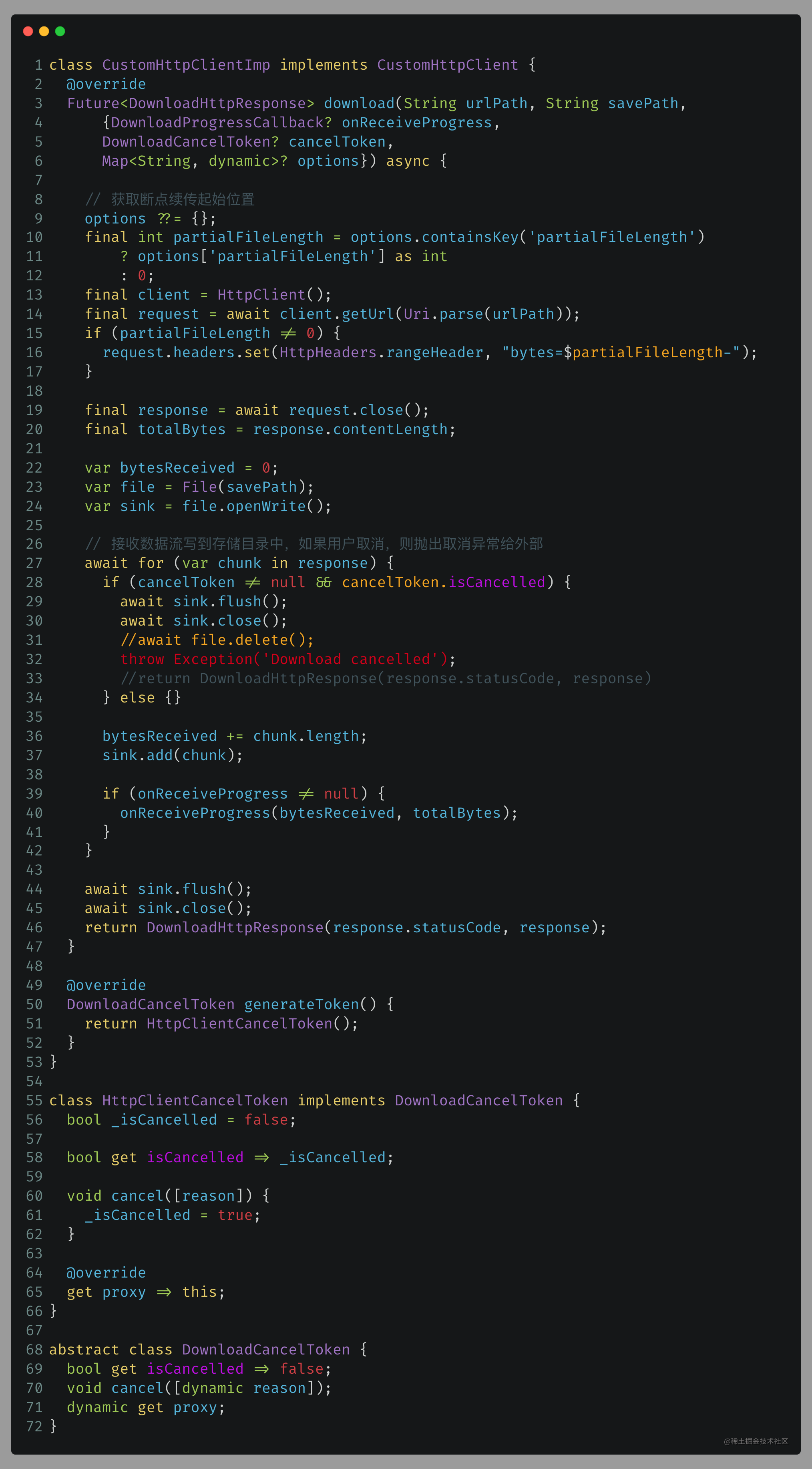
如果不传,会浪费带宽和时间。在处理大文件时,内存压力会增大,中断的可能性也会增加。此外,用户界面可能会出现进度条跳跃的问题。
cancelToken.isCancelled 方法,因为上一篇中没有定义 isCancelled 属性,这里必须在 DownloadCancelToken 中提供该方法(第69行)。完成上述实践后,发现官方进度错误BUG。如果多次暂停、取消,然后再恢复下载,会出现进度起始位置错误的问题。下载会从已下载文件的长度开始,效果如下所示:
在暂停时,暂停前未将下载流写入已下载的文件中。
如果用户点击了暂停,会抛出取消异常,此时捕获该异常并判断当前下载任务状态是暂停态,将已下载的数据流写入未下载完全的文件中。
已提交PR到官方库中,见PR地址。
完整代码传送门,其中包含了httpclient实现和上述官方进度问题修复方案。
在切换flutter_download_manager网络库时,我们发现解耦方案仍然存在问题。
在httpclient中使用了isCancelled方法,不得不将其加入DownloadCancelToken中,这在设计上是有问题的。
我查看了dio的download过程,发现其中也存在对取消状态的判断。dio.CancelToken类中也定义了这个方法,那么为什么我没有考虑到呢?原因是我没有实践过,当时只是用downloadTokenProxy去代理了CancelToken,它可以跑,就认为设计没有问题。果然,自己挖的坑需要自己踩一遍才能真正理解其中的问题。
为了让该库正常运行,必须与相关的网络库配合使用。
在我使用httpclient进行实现过程中,我发现如果取消操作,必须抛出一个异常(请参考代码中第32行),才能确保程序能够顺利地执行case1而不出现官方文档中提到的问题。
Future<void> download(
String url, String savePath, DownloadCancelToken cancelToken,
{forceDownload = false}) async {
late String partialFilePath;
late File partialFile;
try {
var task = getDownload(url);
var response = await customHttpClient.download(...);
} else {
var response = await customHttpClient.download(...
);
}
} catch (e) {
var task = getDownload(url)!;
if (task.status.value != DownloadStatus.canceled &&
//...
} else if (task.status.value == DownloadStatus.paused) {
// 只有抛出取消异常才能走到保持下载流到未下载完全文件中 case1
final ioSink = partialFile.openWrite(mode: FileMode.writeOnlyAppend);
final f = File(partialFilePath + tempExtension);
final fileExist = await f.exists();
if (fileExist) {
await ioSink.addStream(f.openRead());
await f.delete();
}
await ioSink.close();
}
}
因为flutter_download_manager一开始网络库就是绑定的dio,而dio中对取消操作的结果反馈就是取消异常。如果用户取消了任何一个请求,就会抛出该异常。
话说,取消发送一条消息难道非得抛出异常才可以吗?其实有很多方法可以实现这个功能。
由于flutter_download_manager已经处理了返回码206和200,如果不提供网络请求返回码,相关逻辑无法执行。
话说,请求成功返回结果的方式也可以是发消息吧。
如果将flutter_download_manager作为代码片段使用是没有问题的,但从下载框架设计的角度来看,仍需要进一步改进和优化。
出现上述提到的约束问题,主要是将关系集中在DownloadManager和网络库上,陷入网络细节中。实际上,这两者没有直接关系,主要是flutter_download_manager作者将它们耦合在一起导致的。
从下载框架角度说,类之间依赖关系应该如下:
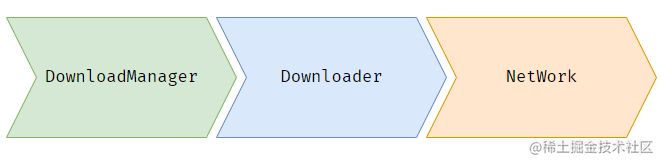
DownloadManager依赖下载器,下载器依赖网络库。
三者间交互关系如下:

本文介绍了Flutter下载功能的实践和探索,包括网络库的切换和优化。使用了httpclient实现网络库,并解决了官方进度错误BUG。还回顾了flutter_download_manager的设计缺陷,并提出了下载框架的设计思路。总之,提供了有关Flutter下载功能的实用信息和思考。
太棒了!鼓励自己坚持到底。我希望我为你投入的时间增加了一些价值。
如果觉得文章对你有帮助,点赞、收藏、关注、评论,一键四连支持,你的支持就是我创作最大的动力。
❤️本文由公众号编程黑板报 原创,关注我,获取我的最新文章~❤️
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1