哈喽,大家好。
之前给大家分享过一次配料表识别程序,这次我们用ChatGPT改造一下。
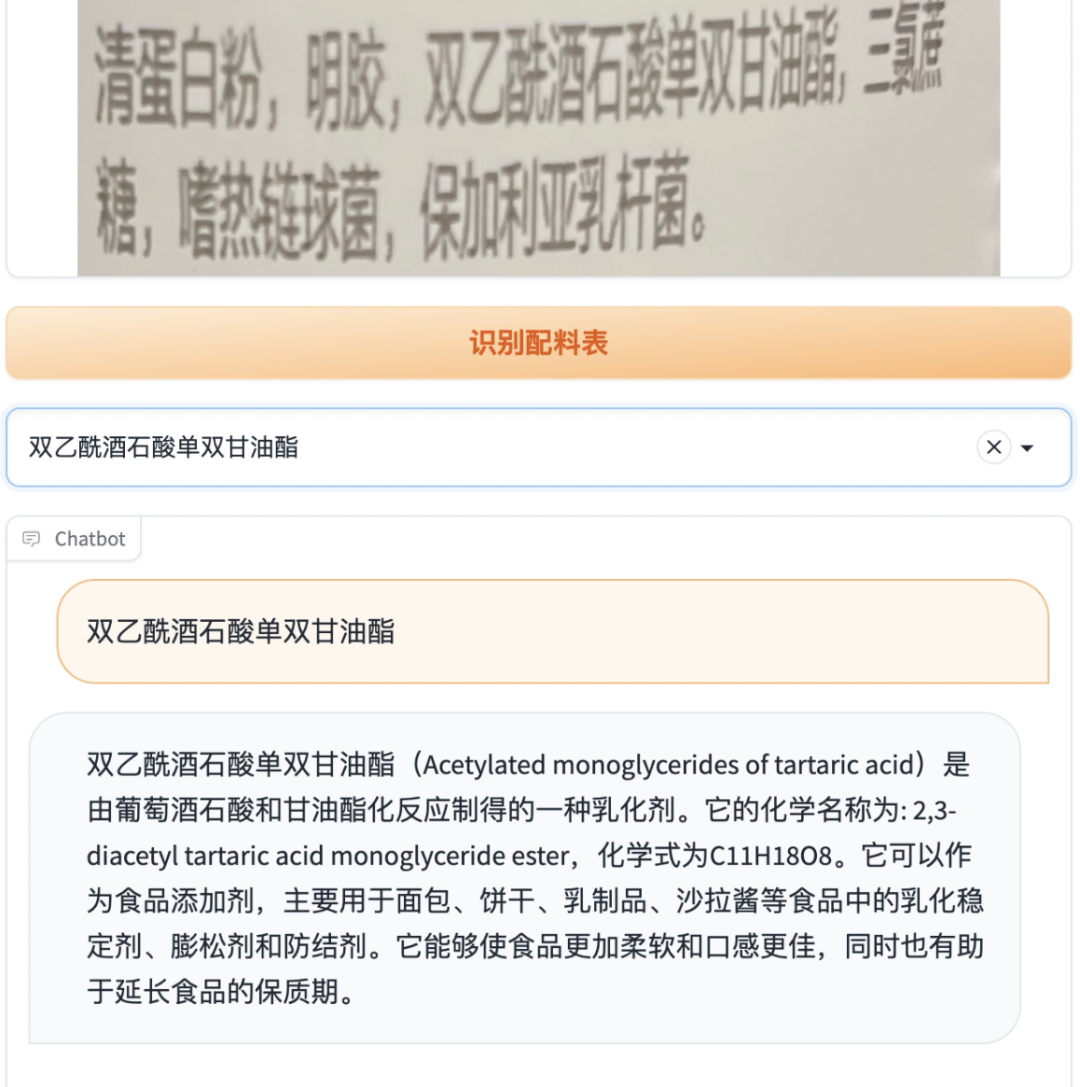
之前的大致思路是,用OCR识别配料表文字,然后开发一个爬虫,爬取每种配料的详细信息(爬百度百科)。
这次的程序不两个不同的地方,第一,配料详情调用ChatGPT获取,免爬取,结果更精准。
第二,web开发框架用gradio,gradio和streamlit类似,都是为了方便AI人员能快速构建web app的框架。
源码已经打包好,大家见文末。
简单贴下核心代码
ocr识别使用paddle
def __init__(self):
self.paddle_ocr = PaddleOCR(use_angle_cls=False, lang="ch")
def ocr(self, img):
result = self.paddle_ocr.ocr(img, cls=True)ocr可以直接用预训练模型,也可以自己训练一个文字识别模型。之前都有介绍过,这里不再赘述了。
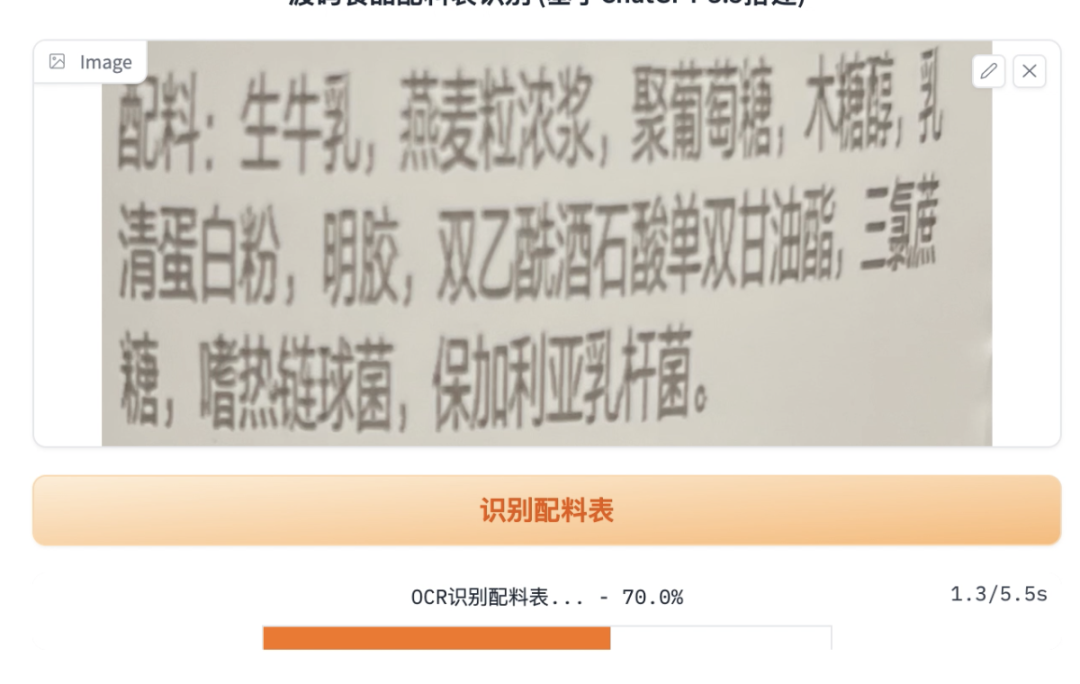
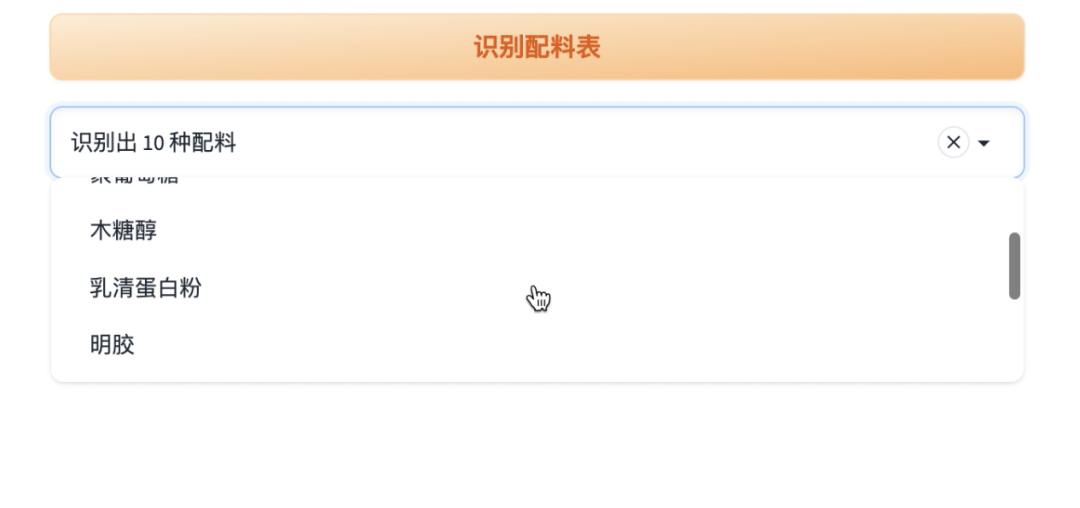
用下拉列表展示识别出来的配料
点击每种配料,调用ChatGPT的api获取配料详情
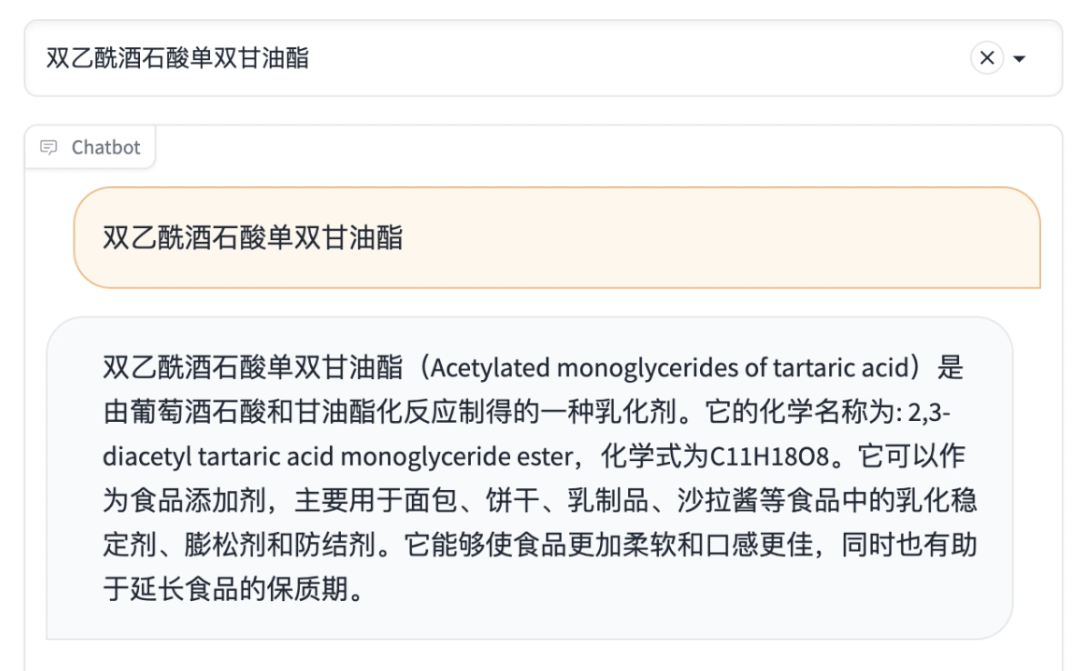
也可以多做一个对话框,支持跟ChatGPT进一步交流
使用ChatGPT还需要魔法和api key,大家需要自行解决。
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
Heroku支持人员告诉我,为了在我的Web应用程序中使用自定义字体(未安装在系统中,您可以在bash控制台中使用fc-list查看已安装的字体)我必须部署一个包含所有字体的.fonts文件夹里面的字体。问题是我不知道该怎么做。我的意思是,我不知道文件名是否必须遵循heroku的任何特殊模式,或者我必须在我的代码中做一些事情来考虑这种字体,或者如果我将它包含在文件夹中它是自动的......事实是,我尝试以不同的方式更改字体的文件名,但根本没有使用该字体。为了提供更多详细信息,我们使用字体的过程是将PDF转换为图像,更具体地说,使用rghostgem。并且最终图像根本不使用自定义字体。在
在我让另一个人重做我的前端UI之前,我的Rails应用程序运行平稳。我已经尝试解决此错误3天了。这是错误:Nosuchfileordirectory-identifyExtractedsource(aroundline#59):575859606162@post=Post.find(params[:id])authorize@postif@post.update_attributes(post_params)flash[:notice]="Postwasupdated."redirect_to[@topic,@post]else{"utf8"=>"✓","_method"=>"patc
如果我们有一个数组array=[1,1,0,0,2,3,0,0,0,3,3,3]我们如何识别给定数字的运行(具有相同值的连续数字的数量)?例如:run_pattern_for(array,0)->2run_pattern_for(array,3)->1run_pattern_for(array,1)->1run_pattern_for(array,2)->0没有2的运行,因为没有连续出现2。3有一个运行,因为只有一个幻影以树为连续数字。 最佳答案 尝试:classArraydefcount_runs(element)chunk{|n
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
当尝试创建一个heroku应用程序并通过git推送到它时,我收到以下错误:$herokucreate'"C:\ProgramFiles\ruby-1.9.2\bin\ruby.exe"isnotrecognizedasaninternalorexternalcommand,operableprogramorbatchfile.但是,$ruby-vruby1.9.3p125[i386-mingw32]我已经检查了PATH环境,它肯定包含“C:\ProgramFiles(x86)\ruby-1.9.2\bin”。同样有趣的是,当导航到该目录时,它实际上并不包含名为ruby.exe的文件