在上一篇文章CLR类型系统概述里提到,当运行时挂起时, 垃圾回收会执行堆栈遍历器(stack walker)去拿到堆栈上值类型的大小和堆栈根。这里我们来翻译BotR里一篇专门介绍Stackwalking的文章,希望能加深理解。
顺便说一句,StackWalker在中文里似乎还没有统一的翻译,Java里有把它翻译成堆栈步行器,微软有的(机翻)文档把它翻译为堆栈查看器,我这里暂且将它翻译为堆栈遍历器,如有更合适的翻译,欢迎评论区指出。
.NET运行时之书(Book of the Runtime,简称BotR)是一系列描述.NET运行时的文档,2007年左右在微软内部创建,最初目的是为了帮助其新员工快速上手.NET运行时;随着.NET开源,BotR也被公开了出来,如果想深入理解CLR,这系列文章不可错过。
BotR系列目录:
[1] CLR类型加载器设计(Type Loader Design)
[2] CLR类型系统概述(Type System Overview)
[3] CLR堆栈遍历(Stackwalking in CLR)
原文:https://github.com/dotnet/runtime/blob/main/docs/design/coreclr/botr/stackwalking.md
作者: Rudi Martin - 2008
翻译:几秋 (https://www.cnblogs.com/netry/)
CLR大量使用了一种称为堆栈遍历(或者也叫stack crawling)的技术,这涉及迭代特定线程的调用帧(call frames)序列,从最近的调用帧(线程的当前函数)后退到堆栈的底部。
运行时出于多种目的使用堆栈遍历:
在这里,我们定义了一些常用术语并描述了线程堆栈的典型布局。
逻辑上,一个堆栈被拆分成若干个帧(frame),每一帧代表若干函数(托管或非托管),这些函数要么是当前正在执行的,要么是已经调用了其它函数,正在等待返回。帧包含了其关联函数的特定调用所需的状态。通常包括局部变量的空间、调用另一个函数的推送参数、保存的调用者寄存器等。
帧的具体定义因平台而异,在很多平台上,并没有一个所有函数都严格遵守的帧格式定义(x86平台就是其中一个例子)。相反,编译器通常可以自由优化帧的具体格式,在这样的系统上,无法保证堆栈遍历返回100正确或者完整的结果(出于调试目的,会使用像pdb文件这样的符号表来填补空白,以便调试器可以生成更准确的堆栈跟踪)。
然而这对CLR来说不是一个问题,因为我们不需要完全广义(fully generalized)的的堆栈遍历,相反我们只对来自以下情况的帧感兴趣:
特别是不保证第三方非托管帧的保真度(fidelity),除非知道到这些帧在何处转换到运行时本身或从运行时本身转换出来(也就是我们感兴趣的一种帧)。
因为我们控制我们感兴趣帧的格式(我们稍后再详细讨论这个问题),我们可以确保这些帧可抓取(crawlable),且具有100%的保真度。唯一的额外要求是一种将不相交的运行时帧(disjoint groups of runtime frames)链接在一起的机制,这样我们就可以跳过任何干预的非托管帧(和不可抓取的)。
下图说明了包含所有帧类型的堆栈(请注意,本文档使用了一种惯例,即堆栈向叶(page)顶部增长):
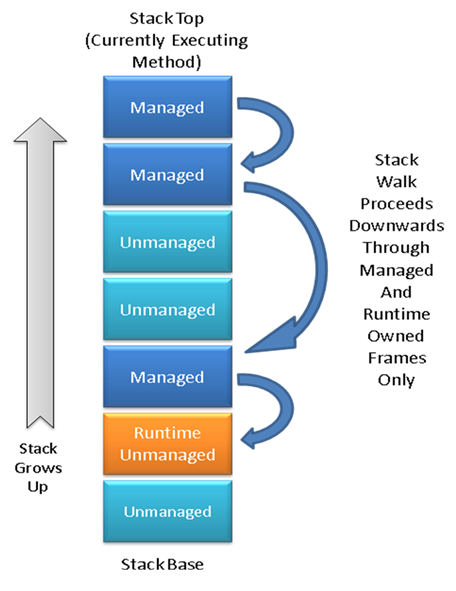
因为运行时拥有和控制JIT(Just-in-Time编译器),它可以安排托管方法始终留下可以抓取的帧。这里的一种解决方案是对所有方法使用严格的(rigid)帧格式。然而在实践中,这可能低效,尤其是对于小叶子(small leaf)方法(例如典型的属性访问器)。
因为方法的调用次数通常多于其帧被抓取的次数(抓取堆栈在运行时中是相对较少的,至少就通常调用方法的速率而言),用方法调用性能换取一些额外的抓取时间是有合理的。因此,JIT会为其编译的每个方法生成额外的元数据,其中包括足够的信息,供堆栈爬虫解码属于该方法的堆栈帧。
这些元数据可以通过以方法中某处的指令指针(instruction pointer)作为键,查找哈希表得到。JIT使用压缩技术来最小化这种额外的每方法元数据的影响。
给定几个重要寄存器的初始值(例如,基于 x86 的系统上的 EIP、ESP 和 EBP),堆栈爬虫可以定位托管方法和其关联的JIT元数据,并使用这些信息将寄存器值回滚到方法调用者中的当前值。用这种方式,可以从最近的调用者到最老的调用者,遍历一系列托管方法帧,此操作有时称为虚拟展开(virtual unwind)(虚拟的是因为我们实际上并没有更新ESP等的真实值,堆栈保持不变)。
运行时(有)部分是以非托管代码实现的(例如coreclr.dll). 大多数这些代码的特殊之处在于,它是作为手动托管的代码运行,也就是说,它遵守托管代码的许多规则和协议,但以显式控制的方式。例如,此类代码可以显式地启用或禁用GC抢占模式(pre-emptive mode),并且需要相应地管理其对象引用的使用。
与托管代码进行这种谨慎交互的另一个区域是在堆栈遍历过程中。由于大多数运行时的非托管代码是用C++编写的,因此我们对方法帧格式的控制不如托管代码。同时,在很多情况下,运行时非托管帧包含了堆栈遍历期间非常重要的信息,这包括非托管函数在局部变量中保存对象引用(必须在垃圾回收期间报告)和异常处理的情况。
非托管函数不是试图使每个非托管帧变得抓取,而是将有趣的数据报告到堆栈爬虫,
与其试图使每个非托管帧可抓取,带有有趣信息的非托管函数,堆栈爬取将信息捆绑到数据结构中,将信息捆绑到称为Frame的数据结构中,这个名称非常有歧义,因此本文档总是将该数据结构变量称为大写的Frame。
Frame实际上是整个Frame类型层次结构的抽象基类。 Frame被子类型化,以表达堆栈遍历可能感兴趣的不同类型的信息。但是堆栈遍历器如何找到这些Frame,并且它们与托管方法使用的帧有何关系?
每个Frame都是单链表的一部分,单链表有一个next指针,指向这个线程的堆栈上下一个更老的Frame(或者是null,如果这个Frame以及是最老的了)。CLR Thread结构持有一个指向最新Frame的指针。非托管运行时代码可以根据需要通过操作线程(Thread)结构和Frame列表来推送(push)或弹出(pop)Frame。
按照这种方式,堆栈遍历器可以按照最新到最旧的顺序迭代非托管Frames, 但是托管和非托管的方法可以被交叉使用,并且处理后面跟着非托管Frames的所有托管帧将会出错,反之亦然,因为它不能准确地表示真正的调用序列。
为了解决这个问题,Frame被进一步限制,它们必须被分配到堆栈上的方法帧中,该方法帧将它们推送到Frame列表中。由于堆栈遍历器知道每个托管帧的堆栈边界,因此它可以执行简单的指针比较,以判断给定Frame是否比给定托管帧旧或新。
本质上,堆栈遍历器在解码当前帧后,对于下一个(更老的)帧总是有两种可能选择:通过寄存器集(register set)的虚拟展开(virtual unwind)确定下一个托管帧,或者线程Frame列表上的下一个更老的Frame。这可以通过判断哪个占用更靠近栈顶的栈空间来决定哪个合适。所涉及的(involved)实际计算是平台相关的,但通常转移(devolves)到一个或两个指针比较上。
当托管代码调用非托管运行时时,非托管目标方法通常会推送数种形式的转换Frame中的一种,这被下面两种情况需要:
可用Frame类型及其用途的完整描述超出了本文档的范围,更多的细节可以在frames.h头文件里找到。
完整的堆栈遍历接口仅公开给运行时非托管代码(System.Diagnostics.StackTrace类是一个对托管代码可用的简化子集),典型的入口点是通过运行时 Thread类上的StackWalkFramesEx()方法,这个方法的调用者要提供下面三个主要的输入:
GetThreadContext())或一个初始Frame(在你知道有问题的代码是在运行时非托管代码中的情况下)。 尽管大多数堆栈遍历都是从堆栈顶部进行的,但如果你可以确定正确的起始上下文,则可以从较低位置开始。StackWalkFramesEx()声明的上方).StackWalkFramesEx()返回一个枚举值,该值指示遍历是否正常终止(到达堆栈基并用完要报告的方法),是否被某一种回调中止(回调函数将同一类型的枚举返回到堆栈遍历)或遇到一些其它错误。
除了传递给StackWalkFramesEx() 的上下文值之外,堆栈回调函数还传递了另一段上下文:CrawlFrame,这个类定义在 stackwalk.h ,这个类包含了在堆栈遍历过程中收集的各种上下文。例如,CrawlFrame为托管帧指示 MethodDesc* ,为非托管Frames指示 Frame*。它还提供了通过虚拟展开帧推断出的当前寄存器集到该点。
堆栈遍历实现的更多低级细节目前不在本文档的范围内。 如果您了解这些知识并愿意分享这些知识,请随时更新此文档。
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我想从0到2循环@a:0,1,2,0,1,2。defset_aif@a==2@a=0else@a=@a+1endend也许有更好的方法? 最佳答案 (0..2).cycle(3){|x|putsx}#=>0,1,2,0,1,2,0,1,2item=[0,1,2].cycle.eachitem.next#=>0item.next#=>1item.next#=>2item.next#=>0... 关于ruby-循环遍历数组的元素,我们在StackOverflow上找到一个类似的问题:
我在MySql中进行了查询,但在Rails和mysql2gem中工作。信息如下:http://sqlfiddle.com/#!2/9adb8/6查询工作正常,没有问题,并显示以下结果:UNITV1A1N1V2A2N2V3A3N3V4A4N4V5A5N5LIFE200120000000000ROB010012000000000-为rails2.3.8安装了mysql2gemgeminstallmysql2-v0.2.6-创建Controller:classPolicyController这是日志:SQL(0.9ms)selectdistinct@sql:=concat('SELECTpb
我一直在尝试使用简单的递归方法在Ruby中为一个更大的程序的一部分实现目录遍历。但是我发现Dir.foreach不包括其中的目录。我怎样才能列出它们?代码:defwalk(start)Dir.foreach(start)do|x|ifx=="."orx==".."nextelsifFile.directory?(x)walk(x)elseputsxendendend 最佳答案 问题是每次递归,你传递给File.directory?的路径isno只是实体(文件或目录)名称;所有上下文都丢失了。所以说你进入one/two/three/检
我有Sinatra应用程序,需要测试我的应用程序。features/support/env.rb:require_relative"../../application"require"capybara"require"capybara/cucumber"require"rspec"WorlddoCapybara.app=ApplicationincludeCapybara::DSLincludeRSpec::Matchersendfeatures/one.feature:Feature:TesthomepageInordertomakesurepeoplecanopenmysiteIw
刚刚将应用程序从rails3.0.9升级到3.2.1,当我运行bundleexecrakeassets:precompile时出现错误,这很好,但是回溯没有告诉我在哪里语法问题来self的css或scss文件。我尝试对“0ee5c0e69c92af0”进行greping,但该字符串没有出现在我的项目中。bundleexecrakeassets:precompile:allRAILS_ENV=productionRAILS_GROUPS=assets--trace**Invokeassets:precompile:all(first_time)**Executeassets:precom
我只是好奇,是否可以将程序的所有变量和当前状态转储到一个文件中,然后在另一台计算机上恢复它?!假设我有一个用Python或Ruby编写的小程序,给定特定条件,它会将所有当前变量和当前状态转储到一个文件中。稍后,我可以在另一台机器上再次加载它,然后返回它。类似VM快照功能。我在这里看到过这样的问题,但与Java相关,保存当前的JVM并在不同的JVM中再次运行它。大多数人都说没有那样的东西,只有Terracotta有一些东西,仍然不完美。谢谢。阐明我要实现的目标:给定2个或更多RaspberryPi,我试图在Pinº1上运行我的软件,但是当我需要用它做一些不同的事情时,我需要将软件移动到P