之前尝试复现学姐前几年的一个工作,但是因为框架有点古老而作罢。
然鹅,自己的实验结果一直跑得十分奇怪,为了去学姐的代码中寻找参考,今天再次进行了尝试。
我的需求是安装Tensorflow_gpu_1.6.0(文中简称TensorFlow),目前机器已配置cuda11和cuda10,非root用户。
当我安装完毕并运行Tensorflow_gpu_1.6.0时,出现了以下错误:
ImportError: libcublas.so.9.0: cannot open shared object file: No such file
这意味着TensorFlow需要对应版本的CUDA,对于CUDA、cuDNN和TensorFlow的关系,知乎有回答写得很好:
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。
cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。
它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
基本上所有的深度学习框架都支持cuDNN这一加速工具,例如:Caffe、Caffe2、TensorFlow、Torch、Pytorch、Theano等。
来自CW大佬的文章,知道只要 nvcc -V 显示的版本低于 nvidia-smi 显示版本就没有问题。
CUDA有runtime API 和 driver API,而nvcc -V显示的是前者版本,nvidia-smi显示的是后者版本。
nvidia-smi展示的 driver API 代表机器能够支持的最高版本CUDA,如果driver (nvidia-smi)的版本低于runtime (nvcc -V)版本,通常不会出现问题。
产生原因:安装CUDA可以通过CUDA Toolkit installer 或 GPU driver installer,如果使用了单独的GPU driver installer来安装CUDA,就可能会出现版本不一致的现象,而通过CUDA Toolkit installer安装则会保持一致。
我尝试了通过conda安装对应的CUDA9.0 以及cuDNN,安装过程很顺利,但Tensorflow并不能跑起来,提示缺少对应的.so文件,而在/usr/local 下也并没有找到我装的cuda9.0。
参考知乎回答 , pytorch如何寻找CUDA:
- 先取默认 cuda 安装目录 /usr/local/cuda
- 如默认目录不存在(例如安装原生 cuda 到其他自定义位置),那么搜索 nvcc 所在的目录
- 如果 nvcc 不存在,那么直接寻找 cudart 库文件目录(此时可能是通过 conda 安装的 cudatoolkit,一般直接用 conda install cudatoolkit,就是在这里搜索到 cuda 库的),库文件目录的上级目录就作为 CUDA_HOME。
- 如果最终未能得到 CUDA_HOME,那么生成的 pytorch 将不使用 CUDA。
TensorFlow同理,但我并没有成功修复调用顺序的问题。那么如果conda安装正确,且机器没有其他版本CUDA(如/usr/local/cuda),理论上能直接用?
安装TensorFlow环境,需要配合对应版本的CUDA、cuDNN和python,而CUDA需要配合对应版本的gcc,
我的目标是装tf_gpu_1.6.0,从官网查到匹配的环境信息如下:官网-TensorFlow对应CUDA
| 版本 | Python 版本 | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| Tensorflow_gpu-1.6.0 | 2.7、3.3-3.6 | GCC 4.8 | Bazel 0.9.0 | 7 | 9 |
# 查看命令
cat /etc/os-release
# 或uname -a
gcc --version
nvcc -V
nvidia-smi
python --version
| 版本 | Python 版本 | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| None | 3.6.1 | GCC 8.4.0 | -- | -- | 10.1 |
按照依赖关系,gcc -> CUDA -> cuDNN -> python -> TensorFlow
不同的CUDA支持的gcc版本不同,现在用的服务器gcc版本比较新,实测cuda9.0在gcc8.4.0下安装程序会失败,所以需要降级。
首先在位置/home/[username]/, 建立目录如下:参考博客
.
├── gcc # 新建,用于存放gcc版本
│ ├──gcc640 # 新建
│ └── gcc-6.4.0.tar.gz # 下载
└── ... # 其他文件
(方式1) 手动下载:http://ftp.gnu.org/gnu/gcc/ 后传输到服务器
(方式2) cmd:
wget http://ftp.gnu.org/gnu/gcc/gcc-6.4.0/gcc-6.4.0.tar.gz
参考:官方gcc安装教程
下载完成后进行解压
cd /home/[username]/gcc
tar xzf gcc-6.4.0.tar.gz
cd gcc-6.4.0
./contrib/download_prerequisites # 运行脚本,自动安装依赖
mkdir objdir # 在gcc-6.4.0源码文件夹下,新建一个文件夹用于编译
cd objdir
使用configure生成 Makefile,为下一步的编译做准备:
$PWD/../gcc-6.4.0/configure --prefix=$HOME/gcc/gcc640 --enable-checking=release --enable-languages=c,c++ --enable-threads=posix --disable-multilib
# --prefix=/usr/local/gcc6 指定安装路径
# --enable-languages=c,c++ 支持的编程语言
# --enable-threads=posix 使用POSIX/Unix98作为线程支持库
# --disable-multilib 取消多目标库编译(取消32位库编译)
接下来编译
make # 或者make -j8 使用8个线程并行编译
可能问题1: make[3]: *** No rule to make target '../build-x86_64-pc-linux-gnu/libiberty/libiberty.a', needed by 'build/genmddeps'. Stop.
在解压后需要在源码文件夹下新建一个文件夹,如/home/[username]/gcc/gcc-6.4.0/objdir,之后的make过程均在新建的编译文件夹内
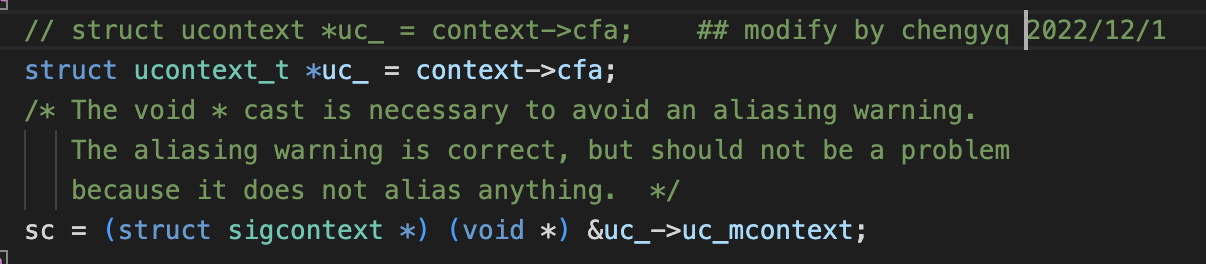
** 可能问题2: ./md-unwind-support.h:65:48: error: dereferencing pointer to incomplete type 'struct ucontext'**
参考博客,原因是现在安装版本的gcc语法不兼容:
如果你机器上已经默认安装的是gcc8.1,现在想要使用gcc6.x,那么编译gcc6.x源码过程中会出现好些错误,这些错误是因为gcc在升级过程中对头文件的一些结构变量的定义的更改变化没有做向后兼容处理,或者某些语法的严格性要求不一样(比较常见的是struct的定义和申明)
打开报错指出的文件地址
/home/[username]/gcc/gcc-6.4.0/x86_64-pc-linux-gnu/libgcc/md-unwind-support.h
修改第61行的
struct ucontext * uc_ = context->cfa;
为
struct ucontext_t * uc_ = context->cfa;
接下来继续make
可能问题3: sanitizer_platform_limits_posix.cc:158:23: fatal error: sys/ustat.h: No such file or directory #include <sys/ustat.h>
参考博客,修改代码文件
vim libsanitizer/sanitizer_common/sanitizer_platform_limits_posix.cc
(1)首先注释158行#include <sys/ustat.h>
(2)将250行语句unsigned struct_ustat_sz = sizeof(struct ustat);注释,修改为如下内容:
// Use pre-computed size of struct ustat to avoid <sys/ustat.h> which
// has been removed from glibc 2.28.
#if defined(__aarch64__) || defined(__s390x__) || defined (__mips64) \
|| defined(__powerpc64__) || defined(__arch64__) || defined(__sparcv9) \
|| defined(__x86_64__)
#define SIZEOF_STRUCT_USTAT 32
#elif defined(__arm__) || defined(__i386__) || defined(__mips__) \
|| defined(__powerpc__) || defined(__s390__)
#define SIZEOF_STRUCT_USTAT 20
#else
#error Unknown size of struct ustat
#endif
unsigned struct_ustat_sz = SIZEOF_STRUCT_USTAT;
(3)保存后,重新make
可能问题4 :../../.././libsanitizer/sanitizer_common/sanitizer_stoptheworld_linux_libcdep.cc:270:22: error: aggregate ‘sigaltstack handler_stack’ has incomplete type and cannot be defined
(1)打开libsanitizer/sanitizer_common/sanitizer_linux.h文件,注释第22行的struct sigaltstack;
(2)修改31.32行:
uptr internal_sigaltstack(const struct sigaltstack* ss,
struct sigaltstack* oss);
为
uptr internal_sigaltstack(const void* ss, void* oss);
(3)修改libsanitizer/sanitizer_common/sanitizer_linux.cc文件549、550行
uptr internal_sigaltstack(const struct sigaltstack *ss,
struct sigaltstack *oss) {
为
uptr internal_sigaltstack(const void *ss, void *oss) {
(4)修改libsanitizer/sanitizer_common/sanitizer_stoptheworld_linux_libcdep.cc270行
struct sigaltstack handler_stack;
为
stack_t handler_stack;
(5)修改libsanitizer/tsan/tsan_platform_linux.cc294行
__res_state *statp = (__res_state*)state;
为
struct __res_state *statp = (struct __res_state*)state;
(6)继续make
可能问题5: ../../.././libsanitizer/sanitizer_common/sanitizer_internal_defs.h:254:72: error: size of array ‘assertion_failed__1139’ is negative
(1)修改 /gcc-6.3.0/configure文件
(2)删除文件中 target-libsanitizer \,大概在2700多行
(3)继续make
make install
检查包含以下目录,即安装成功:/home/[username]/gcc/gcc640

[要安装GCC的路径]:/home/[username]/gcc/gcc640
#路径要在环境变量前
export PATH=[要安装GCC的路径]/bin:[要安装GCC的路径]/lib64:$PATH
export LD_LIBRARY_PATH=[要安装GCC的路径]/lib/:$LD_LIBRARY_PATH
最后刷新
source ~/.bashrc
gcc --version
CUDA 下载地址:https://developer.nvidia.com/cuda-toolkit-archive
.
├── cuda # 新建,用于存放不同的cuda版本,即安装目录
│ ├── cuda-9.0 # 新建
│ └── tem # 新建,用于cuDNN的解压,安装完成后就删除该目录
│ │ ├── cudnn-9.1-linux-x64-v7.1.tgz # 后续下载
│ └── cuda_9.1.85_387.26_linux.run # 后续下载
└── ... # 其他文件
chmod +x cuda_9.1.85_387.26_linux.run
sh cuda_9.1.85_387.26_linux.run
安装过程记录:
-----------------
Do you accept the previously read EULA?
accept/decline/quit: accept
You are attempting to install on an unsupported configuration. Do you wish to continue?
(y)es/(n)o [ default is no ]: y
# 已有Driver API,不安装
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n
Install the CUDA 9.0 Toolkit?
(y)es/(n)o/(q)uit: y
# 非root用户,所以安装在自定义目录
Enter Toolkit Location
[ default is /usr/local/cuda-9.0 ]: /home/[username]/cuda/cuda-9.0
# 非root用户,尝试过无法链接到/usr/local
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: n
Install the CUDA 9.0 Samples?
(y)es/(n)o/(q)uit: y
Enter CUDA Samples Location
[ default is /home/[username] ]: /home/[username]/cuda/cuda-9.0
Installing the CUDA Toolkit in /home/[username]/cuda/cuda-9.0 ...
Missing recommended library: libGLU.so
Missing recommended library: libXi.so
Missing recommended library: libXmu.so
Installing the CUDA Samples in /home/[username]/cuda/cuda-9.0 ...
Copying samples to /home/[username]/cuda/cuda-9.0/NVIDIA_CUDA-9.0_Samples now...
Finished copying samples.
参考博客
安装程序最后已经准备好了卸载的接口,卸载程序在/[安装目录]/bin下,需要注意的是cuda10.0及之前的版本卸载程序名为uninstall_cuda_xx.x.pl,而cuda10.1及之后的版本卸载程序名为cuda-uninstaller。
找到之后运行卸载程序即可,这里的xx.x表示自己的cuda版本。
参考博客
cudnn下载地址:https://developer.nvidia.com/rdp/cudnn-archive
tar -zxvf cudnn-9.1-linux-x64-v7.1.tgz
cp /home/[username]/cuda/include/cudnn.h /home/[username]/cuda/cuda-9.0/include
cp /home/[username]/cuda/lib64/libcudnn* /home/[username]/cuda/cuda-9.0/lib64
chmod a+r /home/[username]/cuda/cuda-9.0/include/cudnn.h /home/[username]/cuda/cuda-9.0/lib64/libcudnn*
修改个人用户目录下的.bashrc文件(用vi ~/.bashrc编辑),在文件最后面加入以下指令并保存:
export PATH=//home/[username]/cuda/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/home/[username]/cuda/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
最后输入命令source .bashrc 使新配置的环境变量生效
可能问题: Could not find a version that satisfies the requirement tensorflow-1.6.0 (from versions: none)
参考:https://stackoverflow.com/questions/38896424/tensorflow-not-found-using-pip
一般情况下是python版本不对应,但目前python版本是正确的,以下两种解决方案:
(1) 把pip install替换成pip3 install --upgrade
pip3 install --upgrade TF_BINARY_URL
(2) 检查自己的语法(事实证明是我错写成tensorflow-gpu-1.6.0了)
pip3 install tensorflow-gpu==1.6.0
import tensorflow as tf
import os
os.environ['CUDA_VISIBLE_DEVICES']='4' # tensorflow默认占用机器所有卡,所以记得事先选择
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices()) # 检查TF可用的卡
Note: TensorFlow默认会对卡从0开始重新编号
Ref:
[1] https://blog.csdn.net/wanggao_1990/article/details/120989070
[2] https://stackoverflow.com/questions/9450394/how-to-install-gcc-piece-by-piece-with-gmp-mpfr-mpc-elf-without-shared-libra
[3] https://blog.csdn.net/XCCCCZ/article/details/80958414
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我在rspec中收到来自webkit驱动程序的以下消息:Capybara::Driver::Webkit::WebkitInvalidResponseError:UnabletoloadURL:http://127.0.0.1:44923/posts几天前它成功了。问题出在save_page方法上。有什么问题吗? 最佳答案 当我的页面出现错误时,我收到过类似的错误消息。您应该通过在测试模式下启动服务器(railss-etest)并自行访问页面来手动检查情况是否如此。 关于ruby-on-