
目录划分如下:首先是环境,分为网络和service。global是全局的配置,也就是backend的配置,这次使用s3的存储作为backend的存储。最后就是模块做了一些封装。

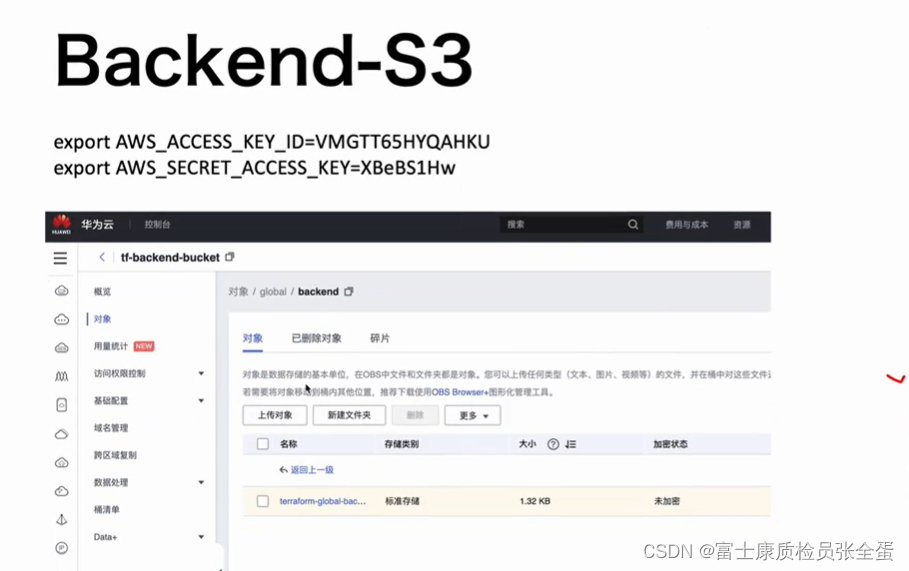
在global里面的backend里面的main.tf去创建s3的存储。华为云支持s3存储,所以这里可以使用。
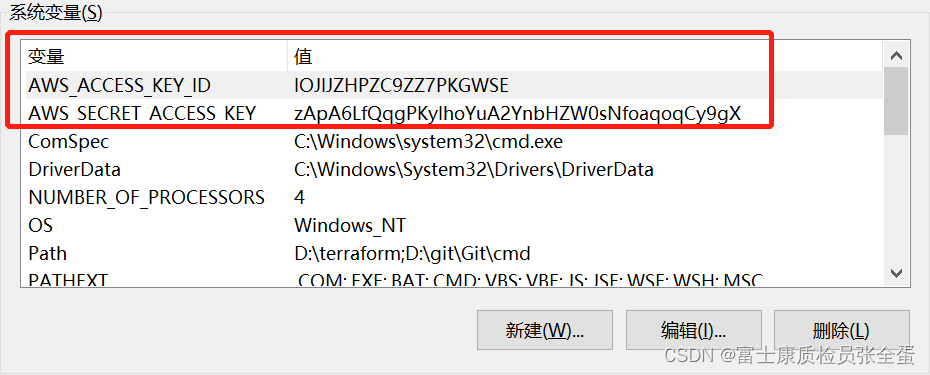
定义好了ak sk信息就需要去创建s3存储了。
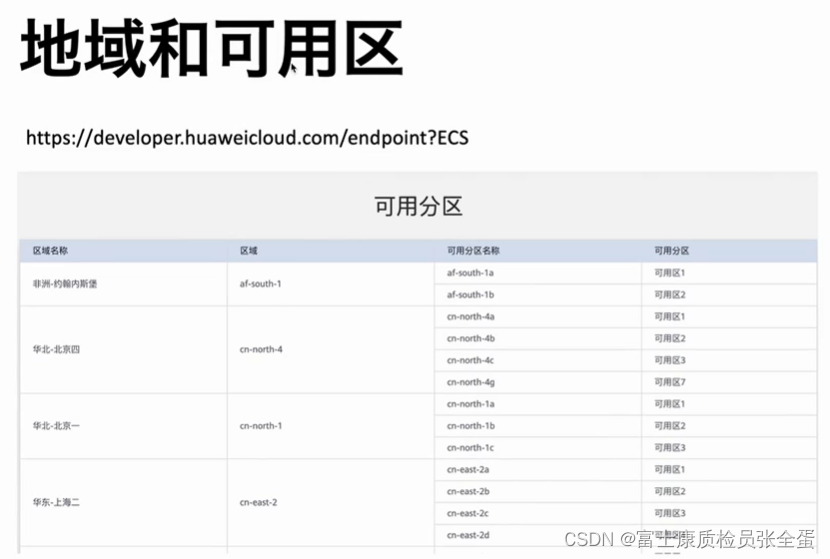
在指定provider里面的信息的时候,因为ak sk信息已经环境变量里面声明了,只需要声明region。
provider "huaweicloud" {
region = var.region
}
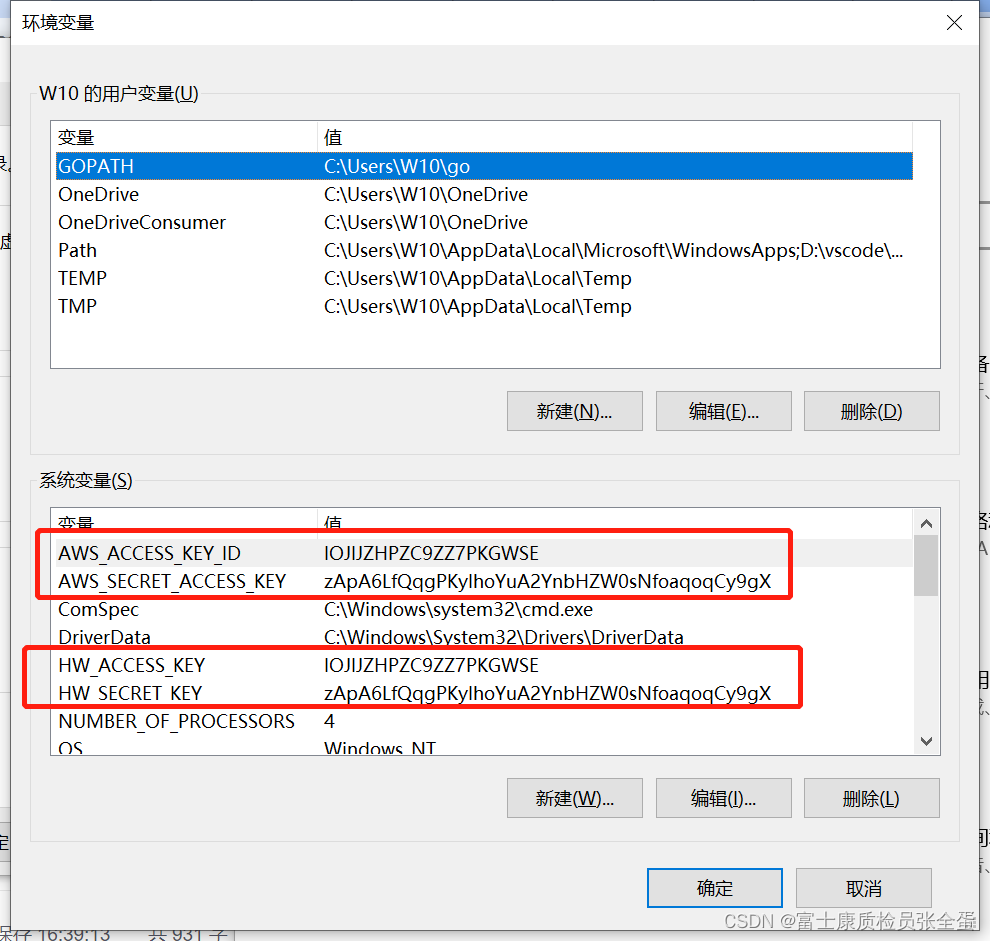
因为华为云使用的是s3存储,s3默认是aws这块的,所以这里需要声明aws的ak sk信息。 其实值都是华为的账号,但是变量还是加上aws的。

然后后面创建bucket的信息。
resource "huaweicloud_obs_bucket" "bucket" {
region = var.region
bucket = "test-backend-bucket"
multi_az = true
acl = "private"
tags = {
type = "bucket"
}
}创建好了bucket然后就是配置使用backend。AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY要定义一下。
terraform {
backend "s3" {
bucket = "test-backend-bucket"
key = "global/backend/terraform-global-backend.tfstate"
region = "cn-east-3"
endpoint = "obs.cn-east-3.myhuaweicloud.com"
skip_region_validation = true
skip_metadata_api_check = true
skip_credentials_validation = true
}
}传到云端之后就可以将这个stat文件删除了。注意就是使用backend要将aws的key给加上。

如果你是Windows系统,那么环境变量去高级系统配置里面去配置,然后去重启的你vv code就可以成功加载你的环境变量了。
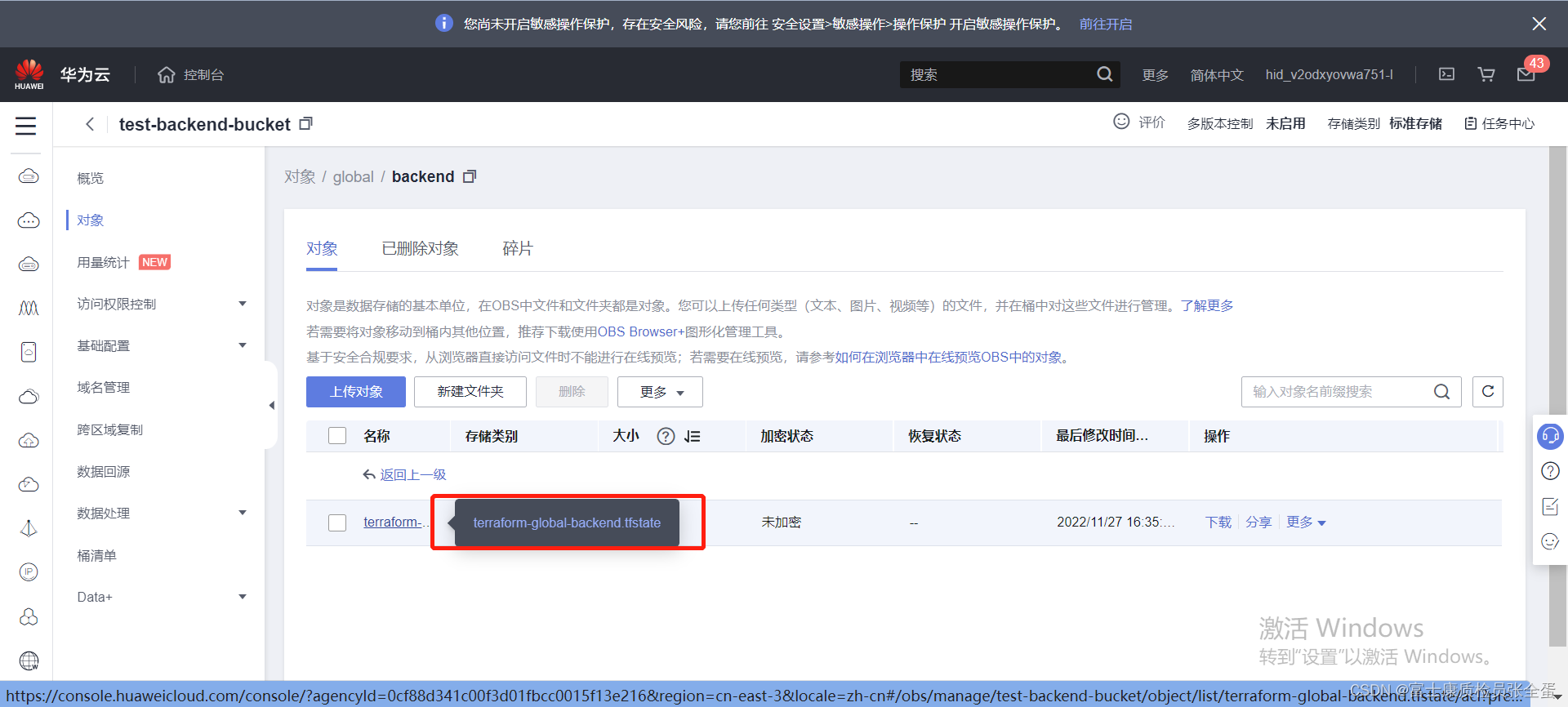
可以看到文件信息存储上去了,本地之前创建bucket的state.tf文件就可以手动删除了。
之后在network下面创建其backend。
terraform {
backend "s3" {
bucket = "test-backend-bucket"
key = "env/dev/network/terraform-dev-network.tfstate"
region = "cn-east-3"
endpoint = "obs.cn-east-3.myhuaweicloud.com"
skip_region_validation = true
skip_metadata_api_check = true
skip_credentials_validation = true
}
}配置好backend之后就去init一下。
init完之后就去模块化资源,然后创建vpc和安全组。(反正就是注意使用variable去定义模块需要传入的参数和output模块需要输出的参数)
注意vpc里面需要设置gateway的IP,这是一个特殊的地方。
resource "huaweicloud_vpc" "vpc" {
name = var.vpc_name
cidr = var.vpc_cidr
}
resource "huaweicloud_vpc_subnet" "subnet" {
name = var.subnet_name
cidr = var.subnet_cidr
gateway_ip = var.subnet_gateway_ip
vpc_id = huaweicloud_vpc.vpc.id
availability_zone = var.availability_zone
}接下来就是创建安全组和规则了。
网络这块是单独使用state进行存储的,后面在创建ecs和service的时候,需要使用到这里的输出,所以需要将vpc和subnet的id都得拿出来。(这个是在service模块调用的时候使用的输出)
output "vpc_id" {
value = module.dev-vpc.vpc_id
}
output "subnet_id" {
value = module.dev-vpc.subnet_id
}
output "subnet_subnet_id" {
value = module.dev-vpc.subnet_subnet_id
}
output "secgroup_id" {
value = module.dev-secgroup.secgroup_id
}
network搞定了,后面就是创建service目录。
这里ecs所需要的id都需要通过远程的数据源去拿到,我们需要network里面提供的state,那就需要读取远程的state。
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "test-backend-bucket"
key = "env/dev/network/terraform-dev-network.tfstate"
region = "cn-east-3"
endpoint = "obs.cn-east-3.myhuaweicloud.com"
skip_region_validation = true
skip_metadata_api_check = true
skip_credentials_validation = true
}
}output里面两个输出,一个是当前实例的id,一个是当前实例的ip,因为后面elb是需要挂载ecs的,所以需要拿到内网的IP。
output "instance_id" {
value = huaweicloud_compute_instance.basic.id
}
output "instance_ip" {
value = huaweicloud_compute_instance.basic.access_ip_v4
}
上面创建的ecs两台没有公网ip,所以这里需要关联上,这里要关联上eip使用yum去安装。
这里创建了公共的带宽,也就是共享带宽,然后将弹性公网ip加入这个池就行了。
所以第一步创建共享的带宽,然后下面是创建eip,eip的个数和ecs主机的数量一样。
resource "huaweicloud_vpc_bandwidth" "bandwidth_1" {
name = var.bandwidth_name
size = 5
}
resource "huaweicloud_vpc_eip" "eip" {
count = length(var.instances)
publicip {
type = "5_bgp"
}
bandwidth {
share_type = "WHOLE"
id = huaweicloud_vpc_bandwidth.bandwidth_1.id
}
}然后eip和实例关联上
resource "huaweicloud_compute_eip_associate" "associated" {
count = length(var.instances)
public_ip = huaweicloud_vpc_eip.eip[*].address[count.index]
instance_id = var.instances[count.index]
}可以看到count不仅可以在模块当中使用也可以在resource当中使用。
最后导入模块。
locals {
bandwidth_name = "dev-bandwidth"
instances = module.dev-ecs[*].instance_id
}
module "dev-eip" {
source = "../../../module/eip"
bandwidth_name = local.bandwidth_name
instances = local.instances
}共享带宽创建
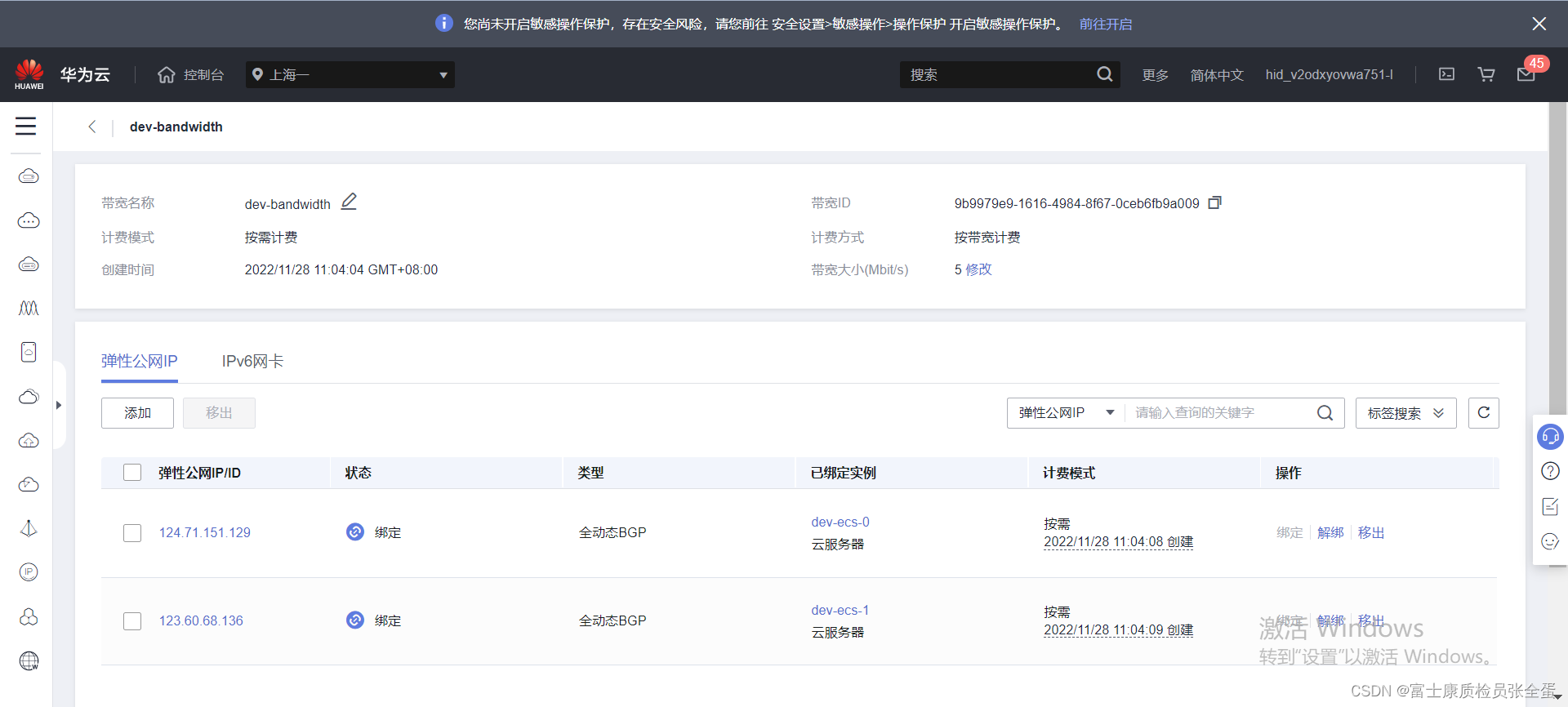
将eip加入共享带宽

然后访问弹性公网,看看是否可以访问到站点


可以看到公网ip就分别绑定了不太的ecs。
其实就是负载均衡实例+监听器就行了。
首先拿到subnet的id
resource "huaweicloud_lb_loadbalancer" "lb" {
vip_subnet_id = var.subnet_id
}然后是listener,监听80端口
resource "huaweicloud_lb_listener" "listener" {
protocol = "HTTP"
protocol_port = 80
loadbalancer_id = huaweicloud_lb_loadbalancer.lb.id
}然后是地址池子,其实就是服务器组。
resource "huaweicloud_lb_member" "member" {
count = length(var.instance_ips)
address = var.instance_ips[count.index]
protocol_port = 80
pool_id = huaweicloud_lb_pool.pool.id
subnet_id = var.subnet_id
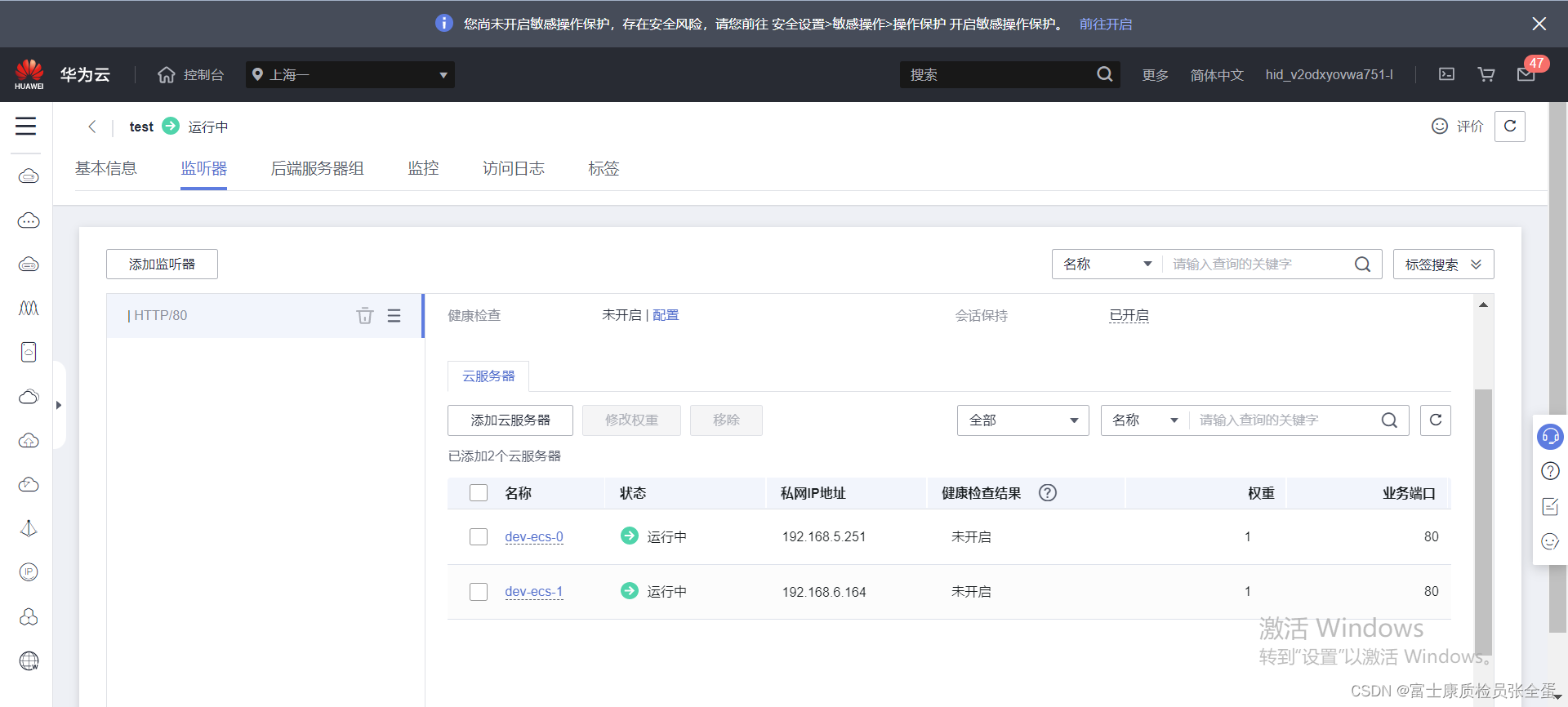
}每个ecs实例其实就是有个member,然后将member加入到这里面来。
elb关联的是子网的id。
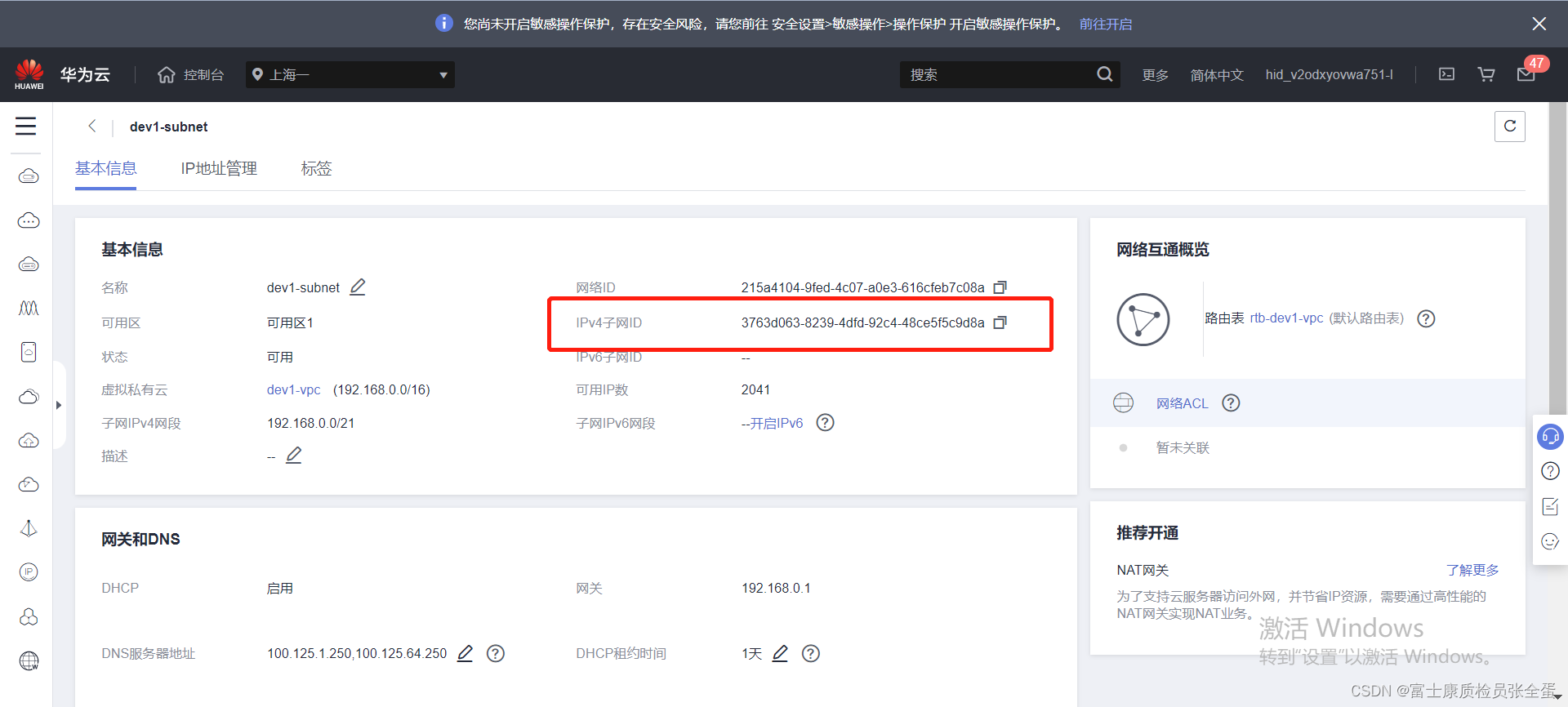
用的是这个id号,子网id。
output "subnet_subnet_id" {
value = huaweicloud_vpc_subnet.subnet.subnet_id
}这里也拿到了所有的instance_ip,通过在模块ecs里面output输出。
module "dev-elb" {
source = "../../../module/elb"
subnet_id = data.terraform_remote_state.network.outputs.subnet_subnet_id
instance_ips = module.dev-ecs[*].instance_ip
}
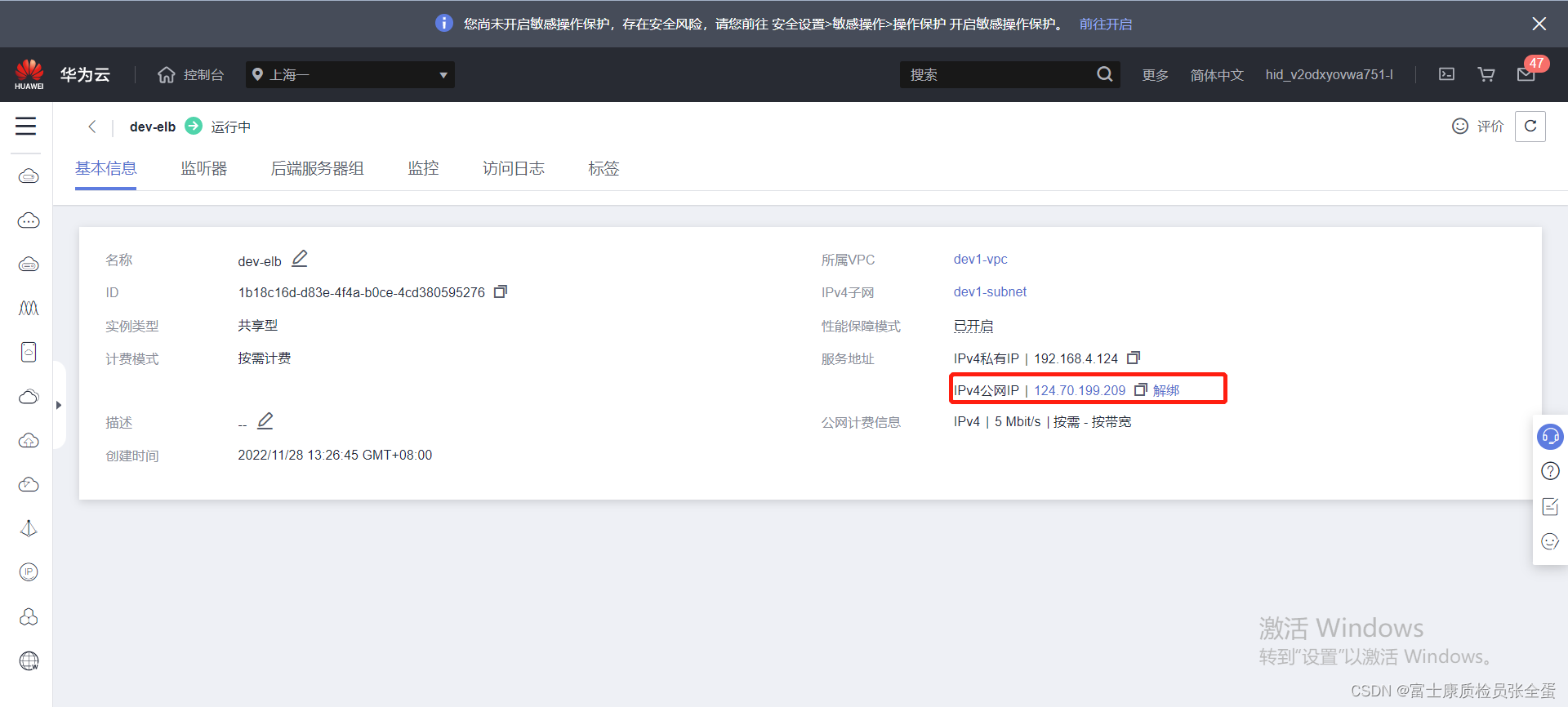
这里创建的eip还是使用之前的共享带宽
resource "huaweicloud_vpc_eip" "elb-eip" {
publicip {
type = "5_bgp"
}
bandwidth {
share_type = "WHOLE"
id = module.dev-eip.bandwidth_id
}
}端口和eip绑定即可
resource "huaweicloud_networking_eip_associate" "eip_elb" {
public_ip = huaweicloud_vpc_eip.elb-eip.address
port_id = module.dev-elb.elb_vip_port_id
}

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
system-view进入系统视图quit退到系统视图sysname交换机命名vlan20创建vlan(进入vlan20)displayvlan显示vlanundovlan20删除vlan20displayvlan20显示vlan里的端口20Interfacee1/0/24进入端口24portlink-typeaccessvlan20把当前端口放入vlan20undoporte1/0/10删除当前VLAN端口10displaycurrent-configuration显示当前配置02配置交换机支持TELNETinterfacevlan1进入VLAN1ipaddress192.168.3.100
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我似乎经常遇到一些设计问题,但我不知道是什么是真的很合适。一方面我经常听到我应该限制耦合和坚持单一职责,但当我这样做时,我常常发现它很困难到在需要时将信息获取到程序的一部分。为了例如,classSingerdefinitialize(name)@name=nameendattr:nameend那么Song应该是:classSongdefnew(singer)@singer=singerendend或classSongdefnew(singer_name)@singer_name=singer_nameendend后者耦合性小,按道理应该用。但如果我以后发现宋有什么需要了解更多歌手,我的
我需要使用ActiveMerchant库在我们的一个Rails应用程序中设置支付解决方案。尽管这个问题非常主观,但人们对主要网关(BrainTree、Authorize.net等)的体验如何?它必须:处理定期付款。有能力记入个人帐户。能够取消付款。有办法存储用户的付款详细信息(例如Authotize.netsCIM)。干杯 最佳答案 ActiveMerchant很棒,但在过去一年左右的时间里,我在使用它时发现了一些问题。首先,虽然某些网关可能会得到“支持”——但并非所有功能都包含在内。查看功能矩阵以确保完全支持您选择的网关-http
我有一个像这样的ruby散列{"stuff_attributes"=>{"1"=>{"foo"=>"bar","baz"=>"quux"},"2"=>{"foo"=>"bar","baz"=>"quux"}}}我想把它变成一个看起来像这样的散列{"stuff_attributes"=>[{"foo"=>"bar","baz"=>"quux"},{"foo"=>"bar","baz"=>"quux"}]}我还需要保留键的数字顺序,并且键的数量是可变的。上面是super简化的,但我在底部包含了一个真实的例子。执行此操作的最佳方法是什么?附言还需要递归就递归而言,这是我们可以假设的:1)