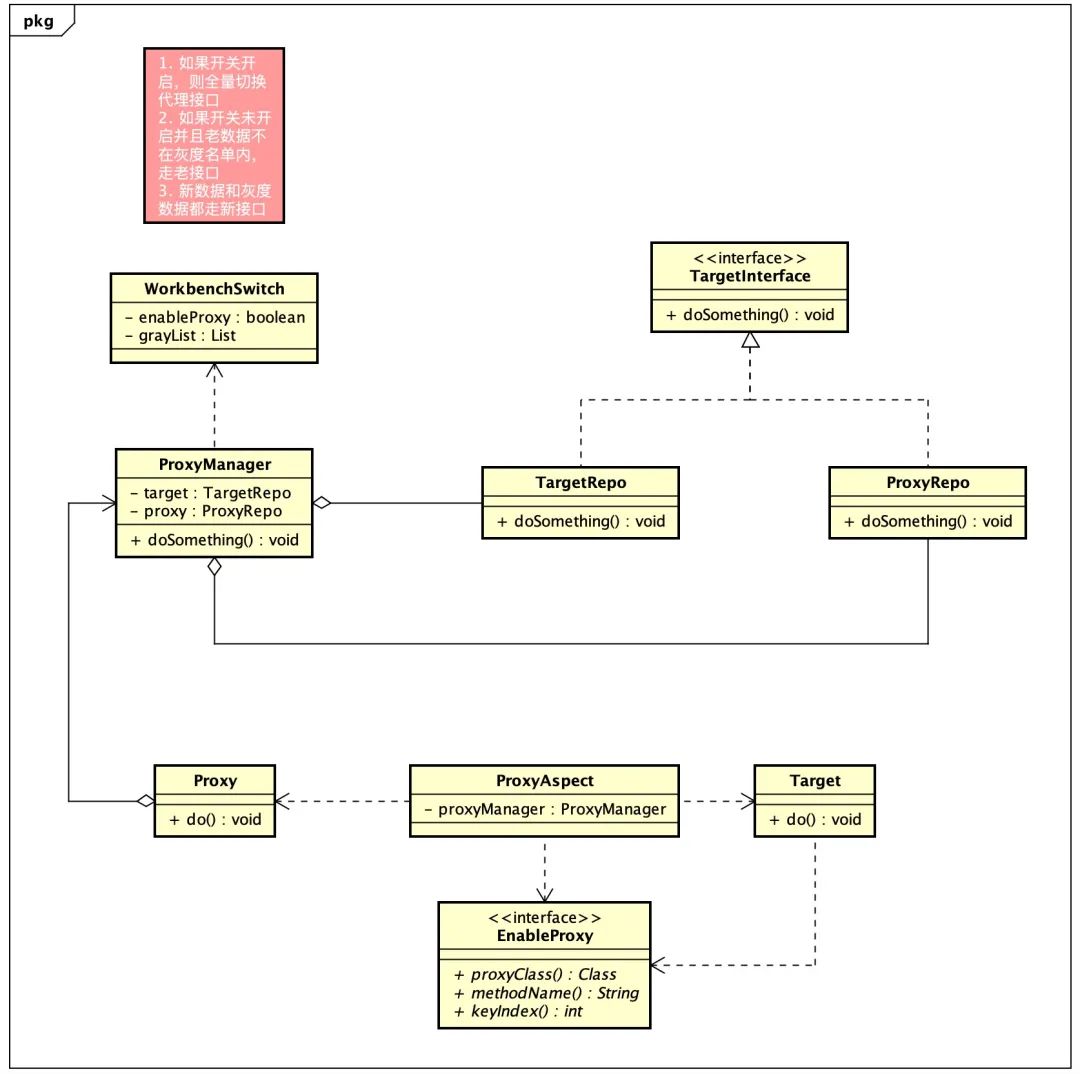
 针对不同的接口逻辑,代理接口实现逻辑会有差异,具体场景如下文所述。
针对不同的接口逻辑,代理接口实现逻辑会有差异,具体场景如下文所述。 /**
* 是否开启代理
*
* @param ctx 上下文
* @return 是:开启代理,否:不开启代理
*/
public Boolean enableProxy(ProxyEnableContext ctx) {
if (ctx == null) {
return false;
}
// 判断总开关
if (总开关打开) {
// 说明数据迁移完成,接口全部切换
return true;
}
if (单个门店操作) {
if (存在老数据源) {
// 判断是否在灰度名单,是则返回true;否则返回false;
} else {
// 新数据
return true;
}
} else {
// 批量查询,需要走代理合并新、老数据源
return true;
}
}@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface EnableProxy {
// 用于标识代理类
Class<?> proxyClass();
// 用于标识转发的代理类的方法,默认取目标类的方法名
String methodName() default "";
// 对于单条数据的查询,可以指定key的参数索引位置,会解析后转发
int keyIndex() default -1;
}@Component
@Aspect
@Slf4j
public class ProxyAspect {
// 核心代理类
@Resource
private ProxyManager proxyManager;
// 注解拦截
@Pointcut("@annotation(***)")
private void proxy() {}
@Around("proxy()")
@SuppressWarnings("rawtypes")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
try {
MethodSignature methodSignature = (MethodSignature)joinPoint.getSignature();
Class<?> clazz = joinPoint.getTarget().getClass();
String methodName = methodSignature.getMethod().getName();
Class[] parameterTypes = methodSignature.getParameterTypes();
Object[] args = joinPoint.getArgs();
// 拿到方法的注解
EnableProxy enableProxyAnnotation = ReflectUtils
.getMethodAnnotation(clazz, EnableProxy.class, methodName, parameterTypes);
if (enableProxyAnnotation == null) {
// 没有找到注解,直接放过
return joinPoint.proceed();
}
//判断是否需要走代理
Boolean enableProxy = enableProxy(clazz, methodName, args, enableProxyAnnotation);
if (!enableProxy) {
// 不开启代理,直接放过
return joinPoint.proceed();
}
// 默认取目标类的方法名称
methodName = StringUtils.isNotBlank(enableProxyAnnotation.methodName())
? enableProxyAnnotation.methodName() : methodName;
// 通过反射拿到代理类的代理方法
Object bean = ApplicationContextUtil.getBean(enableProxyAnnotation.proxyClass());
Method proxyMethod = ReflectUtils.getMethod(enableProxyAnnotation.proxyClass(), methodName, parameterTypes);
if (bean == null || proxyMethod == null) {
// 没有代理类或代理方法,直接走原逻辑
return joinPoint.proceed();
}
// 通过反射,转发代理类方法
return ReflectUtils.invoke(bean, proxyMethod, joinPoint.getArgs());
} catch (BizException bizException) {
// 业务方法异常,直接抛出
throw bizException;
} catch (Throwable throwable) {
// 其他异常,打个日志感知一下
throw throwable;
}
}
}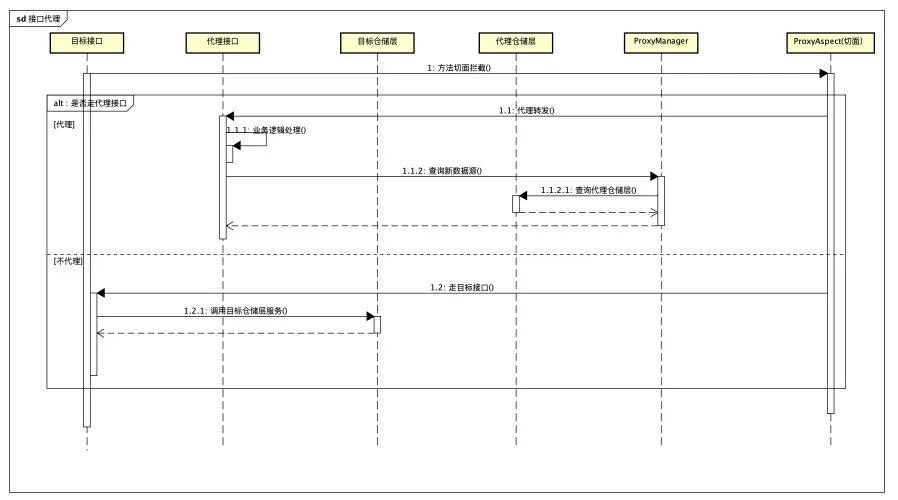 例如单个门店的信息查询,那么我们核心控制器ProxyManager方法逻辑就可以这么实现:
例如单个门店的信息查询,那么我们核心控制器ProxyManager方法逻辑就可以这么实现:public <T> T getById(Long id, Boolean enableProxy) {
if (enableProxy) {
// 开启代理,就走代理仓储层的查询服务
return proxyRepository.getById(id);
} else {
// 没开启代理,走原来仓储层的服务
return targetRepository.getById(id);
}
}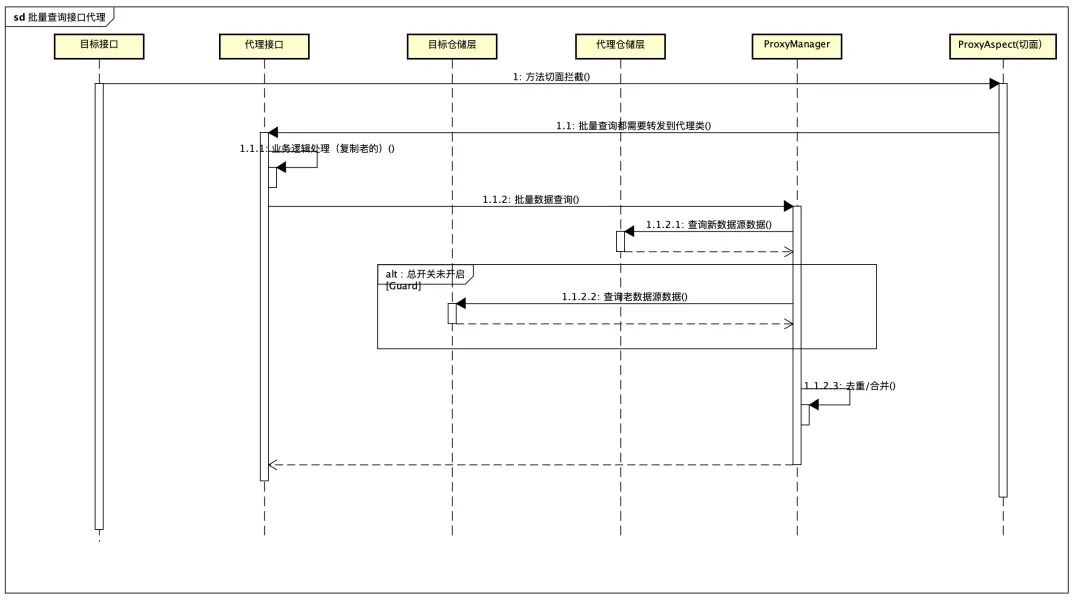 例如批量查询门店列表,可以这么合并,核心实现如下:
例如批量查询门店列表,可以这么合并,核心实现如下: public <T> List<T> queryList(List<Long> ids, Function<T, Long> idMapping) {
if (CollectionUtils.isEmpty(ids)) {
return Collections.emptyList();
}
// 1. 查询老数据
Supplier<List<T>> oldSupplier = () -> targetRepository.queryList(ids);
// 2. 查询新数据
Supplier<List<T>> newSupplier = () -> proxyRepository.queryList(ids);
// 3. 根据合并规则合并,依赖合并工具(对合并逻辑进行抽象后的工具类)
return ProxyHelper.mergeWithSupplier(oldSupplier, newSupplier, idMapping);
}public class ProxyHelper {
/**
* 核心去重逻辑,判断是否采用新表数据
*
* @param existOldData 是否存在老数据
* @param existNewData 是否存在新数据
* @param id 门店id
* @return 是否采用新表数据
*/
public static boolean useNewData(Boolean existOldData, Boolean existNewData, Long id) {
if (!existOldData && !existNewData) {
//两张表都没有
return true;
} else if (!existNewData) {
//新表没有
return false;
} else if (!existOldData) {
//老表没有
return true;
} else {
//新表老表都有,判断开关和灰度开关
return 总开关打开 or 在灰度列表内
}
}
/**
* 合并新/老表数据
*
* @param oldSupplier 老表数据
* @param newSupplier 新表数据
* @return 合并去重后的数据
*/
public static <T> List<T> mergeWithSupplier(
Supplier<List<T>> oldSupplier, Supplier<List<T>> newSupplier, Function<T, Long> idMapping) {
List<T> old = Collections.emptyList();
if (总开关未打开) {
// 未完成切换,需要查询老的数据源
old = oldSupplier.get();
}
return merge(idMapping, old, newSupplier.get());
}
/**
* 去重并合并新老数据
*
* @param idMapping 门店id映射函数
* @param oldData 老数据
* @param newData 新数据
* @return 合并结果
*/
public static <T> List<T> merge(Function<T, Long> idMapping, List<T> oldData, List<T> newData) {
if (CollectionUtils.isEmpty(oldData) && CollectionUtils.isEmpty(newData)) {
return Collections.emptyList();
}
if (CollectionUtils.isEmpty(oldData)) {
return newData;
}
if (CollectionUtils.isEmpty(newData)) {
return oldData;
}
Map<Long/*门店id*/, T> oldMap = oldData.stream().collect(
Collectors.toMap(idMapping, Function.identity(), (a, b) -> a));
Map<Long/*门店id*/, T> newMap = newData.stream().collect(
Collectors.toMap(idMapping, Function.identity(), (a, b) -> a));
return ListUtils.union(oldData, newData)
.stream()
.map(idMapping)
.distinct()
.map(id -> {
boolean existOldData = oldMap.containsKey(id);
boolean existNewData = newMap.containsKey(id);
boolean useNewData = useNewData(existOldData, existNewData, id);
return useNewData ? newMap.get(id) : oldMap.get(id);
})
.filter(Objects::nonNull)
.collect(Collectors.toList());
}
}@Transactional(rollbackFor = Throwable.class)
public <T> Boolean update(T t) {
if (t == null) {
return false;
}
if (总开关没打开) {
// 数据没有迁移完毕
// 更新要双写,如有,保持数据一致
targetRepository.update(t);
}
// 更新新数据
proxyRepository.update(t);
return true;
}如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我希望用户从一个模型的三个选项中选择一个。即我有一个模型视频,可以被评为正面/负面/未知目前我有三列bool值(pos/neg/unknown)。这是处理这种情况的最佳方式吗?为此,表单应该是什么样的?目前我有类似的东西但显然它允许多项选择,而我试图将它限制为只有一个..怎么办? 最佳答案 如果要使用字符串列,让我们说rating。然后在你的表单中:#...#...它只允许一个选择编辑完全相同但使用radio_button_tag: 关于ruby-on-rails-Rails单选按钮-模
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
我正在创建一个新的Rails3.1应用程序。我希望这个新应用程序重用现有数据库(由以前的Rails2应用程序创建)。我创建了新的应用程序定义模型,它重用了数据库中的一些现有数据。在开发和测试阶段,一切正常,因为它在干净的表数据库上运行,但是当尝试部署到生产环境时,我收到如下消息:PGError:ERROR:column"email"ofrelation"users"alreadyexists***[err::localhost]:ALTERTABLE"users"ADDCOLUMN"email"charactervarying(255)DEFAULT''NOTNULL但是我在迁移中有这
我写了很多initialize代码,将attrs设置为参数,类似于:classSiteClientattr_reader:login,:password,:domaindefinitialize(login,password,domain='somedefaultsite.com')@login=login@password=password@domain=domainendend有没有更像Ruby的方式来做到这一点?我觉得我在一遍又一遍地编写相同的样板设置代码。 最佳答案 您可以使用rubyStruct:classMyClass或