主要考察对测试的理解以及计算机基础、算法与逻辑思维。
主要考察项目相关以及编程能力。相关知识能说多少说多少,面试官不会打断你,主要看技术深度 。
编程题手写有困难的情况下,必须介绍分析思路、准备用什么方法
一般不会挂人。
来源与网易、网易互娱、360、头条、商汤等公司面试真题,整理自牛客网link。
1.tcp、udp属于哪层,区别,应用
属于传输层
TCP与UDP基本区别

应用:
TCP 每个数据封包都需要确认,因此天然不适应高速数据传输场景,比如观看视频(流媒体应用)、网络游戏(TCP 有延迟)等。具体来说,如果网络游戏用 TCP,每个封包都需要确认,可能会造成一定的延迟;再比如音、视频传输天生就允许一定的丢包率;
Ping 和 DNS Lookup,这类型的操作只需要一次简单的请求/返回,不需要建立连接,用 UDP 就足够了。如果考虑希望传输足够块,就可能会用 UDP。
再比如 HTTP 协议,如果考虑请求/返回的可靠性,用 TCP 比较合适。
第一类:TCP 场景
远程控制(SSH)
TELNET
File Transfer Protocol(FTP)
邮件(SMTP、IMAP)等
点对点文件传出(微信等)
HTTP
第二类:UDP 场景
网络游戏
音视频传输
DNS
Ping
直播
TFTP
SNMP
第三类:模糊地带(TCP、UDP 都可以考虑)
HTTP(目前以 TCP 为主)
文件传输
2.你知道的什么软件是用tcp协议什么软件是用UDP协议
3.TCP三次握手四次挥手的过程及状态, 三次握手?两次会怎样?四次挥手?3次会怎样?TIME_WAIT出现在哪 为什么要有TIME_WAIT
三次握手:
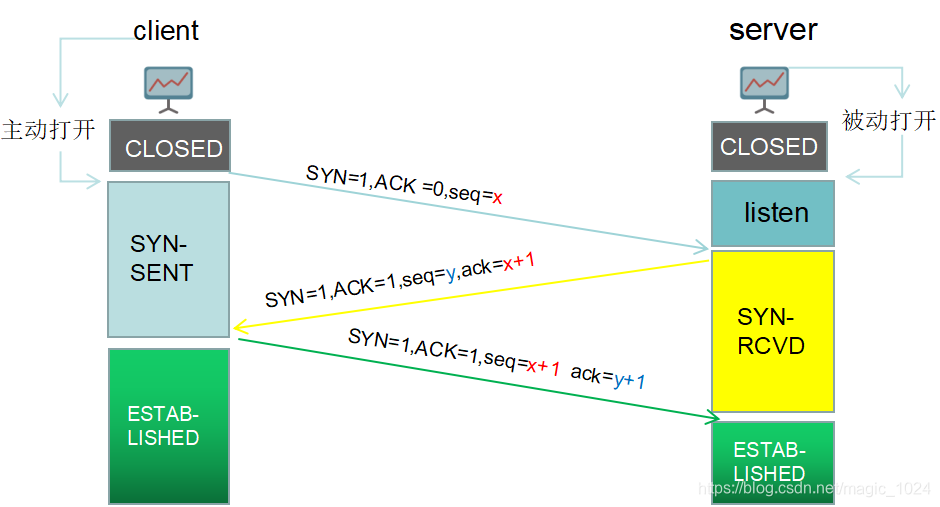
默认情况下客户端client和服务端sever的TCP进程都处于CLOSED(关闭)状态。
服务端TCP服务进程先建立传输控制块TCB,然后服务端进入LISTEN状态,等待客户端连接请求。
上面的连接建立过程就是TCP三次握手。
为什么client收到确认报文后,还要再发送一次确认报文给server呢?这主要是为了防止已失效的连接请求报文段突然又送到了Server端。
假设现在TCP连接是两次握手机制,如下图server在收到client的连接请求,确认后就进入ESTAB-LISHED状态,会存在这样一种问题:
client发送连接请求报文,由于网络原因,长时间阻塞在某个网络节点上了,于是client重传了一次请求连接报文,第二次请求报文正常达到server,连接正常建立,数据传输完毕后,释放连接。但是假设此时第一次发送的请求报文并没有丢失,而是延误一段时间才到达server,这本是已失效的连接请求报文段,但是server收到后,会以为是client重新发送的连接请求,于是向client发送确认报文后,进入ESTAB-LISHED状态,但是client并没有发出新建连接的请求,就会忽略server的确认报文,server却在一直等待client发送数据,导致server资源浪费严重。
四次挥手:

第一次挥手
TCP 发送一个 FIN(结束),用来关闭客户到服务端的连接。
客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为 seq=u(等于前面已经传送过来的数据的最后一个字节的序号加 1),此时,客户端进入 FIN-WAIT-1(终止等待 1)状态。TCP 规定,FIN 报文段即使不携带数据,也要消耗一个序号。
第二次挥手
服务端收到这个 FIN,他发回一个 ACK(确认),确认收到序号为收到序号+1,和 SYN 一样,一个 FIN 将占用一个序号。
服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号 seq=v,此时,服务端就进入了 CLOSE-WAIT(关闭等待)状态。TCP 服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个 CLOSE-WAIT 状态持续的时间。
客户端收到服务器的确认请求后,此时,客户端就进入 FIN-WAIT-2(终止等待 2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
第三次挥手
服务端发送一个 FIN(结束)到客户端,服务端关闭客户端的连接。
服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为 seq=w,此时,服务器就进入了 LAST-ACK(最后确认)状态,等待客户端的确认。
第四次挥手
客户端发送 ACK(确认)报文确认,并将确认的序号+1,这样关闭完成。
客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是 seq=u+1,此时,客户端就进入了 TIME-WAIT(时间等待)状态。注意此时 TCP 连接还没有释放,必须经过 2*MSL(最长报文段寿命)的时间后,当客户端撤销相应的 TCB 后,才进入 CLOSED 状态。
服务器只要收到了客户端发出的确认,立即进入 CLOSED 状态。同样,撤销 TCB 后,就结束了这次的 TCP 连接。可以看到,服务器结束 TCP 连接的时间要比客户端早一些。
思考:那么为什么是 4 次挥手呢?
为了确保数据能够完成传输。
关闭连接时,当收到对方的 FIN 报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可能未必会马上会关闭 SOCKET,也即你可能还需要发送一些数据给对方之后,再发送 FIN 报文给对方来表示你同意现在可以关闭连接了,所以它这里的 ACK 报文和 FIN 报文多数情况下都是分开发送的。
可能有人会有疑问,tcp 我握手的时候为何 ACK(确认)和 SYN(建立连接)是一起发送。挥手的时候为什么是分开的时候发送呢。
因为当 Server 端收到 Client 端的 SYN 连接请求报文后,可以直接发送 SYN+ACK 报文。其中 ACK 报文是用来应答的,SYN 报文是用来同步的。但是关闭连接时,当 Server 端收到 FIN 报文时,很可能并不会立即关闭 SOCKET,所以只能先回复一个 ACK 报文,告诉 Client 端,"你发的 FIN 报文我收到了"。只有等到我 Server 端所有的报文都发送完了,我才能发送 FIN 报文,因此不能一起发送。故需要四步挥手。
time_wait状态是什么
简单来说:time_wait状态是四次挥手中服务器向客户端发送FIN终止连接后进入的状态。
下图为tcp四次挥手过程

可以看到time_wait状态存在于客户端收到服务器Fin并返回ack包时的状态
当处于time_wait状态时,我们无法创建新的连接,因为端口被占用。
4.http状态码
下面给出一些状态码的适用场景:
100:客户端在发送POST数据给服务器前,征询服务器情况,看服务器是否处理POST的数据,如果不处理,客户端则不上传POST数据,如果处理,则POST上传数据。常用于POST大数据传输
206:一般用来做断点续传,或者是视频文件等大文件的加载
301:永久重定向会缓存。新域名替换旧域名,旧的域名不再使用时,用户访问旧域名时用301就重定向到新的域名
302:临时重定向不会缓存,常用 于未登陆的用户访问用户中心重定向到登录页面
304:协商缓存,告诉客户端有缓存,直接使用缓存中的数据,返回页面的只有头部信息,是没有内容部分
400:参数有误,请求无法被服务器识别
403:告诉客户端禁止访问该站点或者资源,如在外网环境下,然后访问只有内网IP才能访问的时候则返回
404:服务器找不到资源时,或者服务器拒绝请求又不想说明理由时
503:服务器停机维护时,主动用503响应请求或 nginx 设置限速,超过限速,会返回503
504:网关超时
5.http和https的区别 https的加密方式
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTPS和HTTP的主要区别
1、https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl/tls加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL/TLS+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
6.get,post区别
Get和post是表单提交数据的两种基本方式,get请求数据通过域名后缀url传送,用户可见,不安全,post请求数据通过在请求报文正文里传输,相对比较安全。
get是通过url传递表单值,post通过url看不到表单域的值;
get传递的数据量是有限的,如果要传递大数据量不能用get,比如type=“file”上传文章、type=“password”传递密码或者< text area >发 Get和post是表单提交数据的两种基本方式,get请求数据通过域名后缀url传送,用户可见,不安全,post请求数据通过在请求报文正文里传输,相对比较安全。
get是通过url传递表单值,post通过url看不到表单域的值;
get传递的数据量是有限的,如果要传递大数据量不能用get,比如type=“file”上传文章、type=“password”传递密码或者< text area >发表大段文章,post则没有这个限制;
post会有浏览器提示重新提交表单的问题,get则没有(加分的回答)
7.HTTP协议中,除了GET和POST还有什么请求?
HTTP/1.1协议中共定义了八种方法(也叫“动作”)来以不同方式操作指定的资源:
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。参见安全方法
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
向指定资源位置上传其最新内容。
请求服务器删除Request-URI所标识的资源。
回显服务器收到的请求,主要用于测试或诊断。
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
8.cookie,session区别,应用场景
cookie的执行原理:就是当客户端访问服务器的时候(服务器运用了cookie),服务器会生成一份cookie传输给客户端,客户端会自动把cookie保存起来,以后客户端每次访问服务器,都会自动的携带着这份cookie。
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了session是一种特殊的cookie。cookie是保存在客户端的,而session是保存在服务端。
cookie和session的共同点
cookie和session都是用来跟踪浏览器用户身份的会话方式。
cookie和session区别
cookie是保存在客户端的
cookie有大小限制
session是保存在服务器端
session更加安全
session会比较占用服务器性能,当访问增多时应用cookie
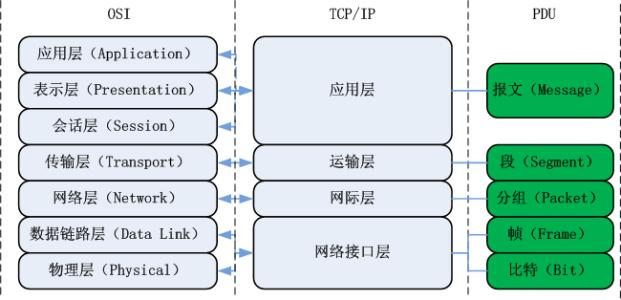
9.OSI七层模型
10.arp协议与arp攻击
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址mac的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收对应主机返回的消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。
ARP是建立在网络中各个主机互相信任的基础上的,局域网络上的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机ARP缓存;由此攻击者就可以向某一主机发送伪ARP应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个ARP欺骗(也称为ARP攻击)。
ARP命令可用于查询本机ARP缓存中IP地址和MAC地址的对应关系、添加或删除静态对应关系等。
这里需要注意的是,ARP本身是没有重试机制的,如果有重试,有可能是上层协议采取的处理方式。
11.浏览器请求,浏览器输入一个连接,到展示到页面,经过了什么

1、DNS解析: 当用户输入一个网址并按下回车键的时候,浏览器得到一个域名,而在实际通信过程中,我们需要的是一个 IP地址,因此需要先把域名转换成相应的 IP地址。
2、TCP连接: 浏览器通过 DNS获取到 Web服务器真正的 IP地址后,便向 Web服务器发起 TCP连接请求,通过 TCP三次握手建立好连接后,浏览器便可以将 HTTP请求数据发送给服务器了。
3、发送 HTTP请求: 浏览器向 Web服务器发起一个 HTTP请求,HTTP协议是建立在 TCP协议之上的应用层协议,其本质是建立起的 TCP连接中,按照 HTTP协议标准发送一个索要网页的请求。在这一过程中,会涉及到负载均衡等操作。
4、处理请求并返回: 服务器获取到客户端的 HTTP请求后,会根据 HTTP请求中的内容决定如何获取相应的文件,并将文件发送给浏览器。
5、浏览器渲染: 浏览器根据响应开始显示页面,首先解析 HTML文件构建 DOM树,然后解析 CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。
树并将其绘制到屏幕上。
6、断开连接: 客户端和服务器通过四次握手终止 TCP连接。
12.TCP与IP 协议的区别
1.TCP工作于传输层,提供面向连接、可靠的地数据传输服务,PDU为报文。IP工作于网络层,提供无连接的、不可靠的、尽最大努力交付的数据报服务。PDU为分组。
2.TCP提供应用进程之间的通信,而IP提供主机之间的通信。
3.TCP以IP为基础,面向应用层提供服务。IP协议为TCP提供服务。IP协议将数据从一台主机发送至另一台主机,TCP则保证了其传输可靠性。
1.查看进程,哪些进程占用了8080
ps aux
(第二列是进程号)
netstat -tln | grep 8080
2.查看一个端口的占用情况,并杀死占用的进程
lsof -i : 端口号 用于查看某一端口的占用情况,比如查看8080端口使用情况,lsof -i:8080
结束进程直接 kill -9 进程号就可以了
3.统计字符串出现的次数
grep -c ‘object’ fileName
案例里使用的文件:aa.txt ,用来做统计的字符串:2
4.查找
find
5.新建文件
touch
6.查看文件
cat
7.修改文件
vim
8.查看日志
tail
9.修改文件权限
chmod 777 error.log

10.文件压缩解压
压缩:
zip -r newfilename.zip filename
tar -cvf newfilename.tar filename
gzip filename.tar filename.tar.gz
tar -zcvf newfilename.tar.gz filename
解压:
unzip newfilename.zip
gzip -d filename.tar.gz
tar -xvf filename.tar
tar -zxvf filename.tar.gz
11.修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
整理数据库与SQL常见考点及真题答案戳链接?
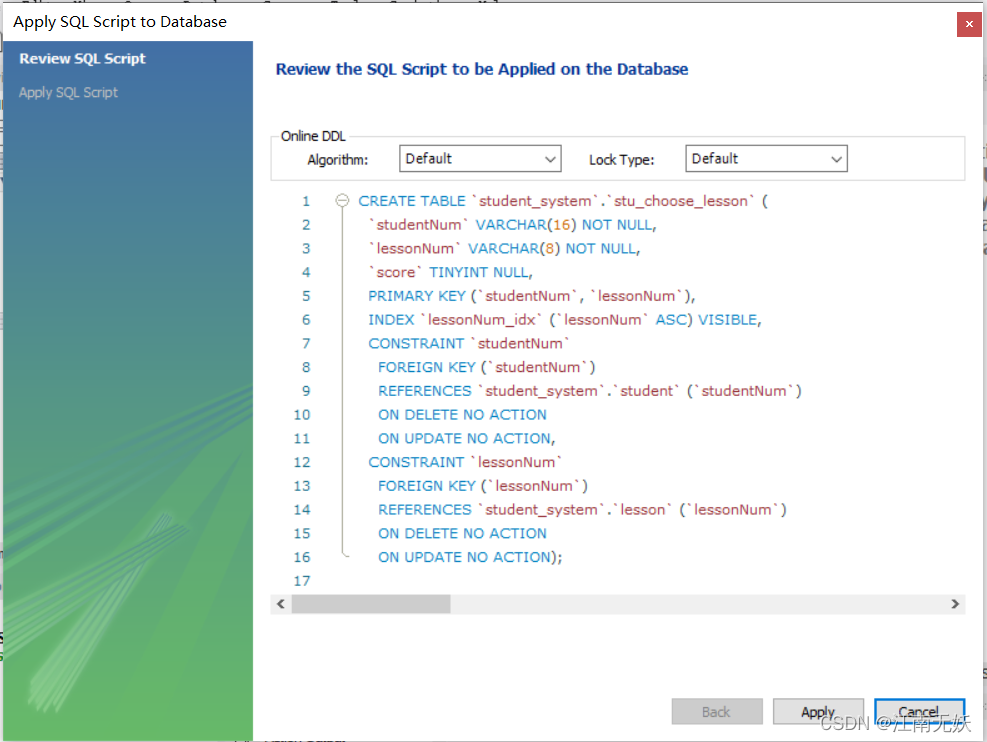
1.创建表CREATE TABLE
2.创建视图CREATE VIEW
视图可以当做虚拟表格,与表格不同的是,表格中有实际存储的资料,而视图是建立在表格之上的一个架构,其本身不实际存储资料。
CREATE VIEW “VIEW_NAME”AS “SQL语句”
3.创建索引CREATE INDEX
索引可以帮助快速查找资料。索引的存在,数据库系统可以先从这个索引找出需要的资料在表格的位置,在进行抓取。
CREATE INDEX “INDEX_NAME”ON “TABLE_NAME”(COLUMN_NAME)
4.更改表结构ALTER TABLE
ALTER TABLE “TABLE_NAME”[改变方式]
具体操作可以包括:增加栏位ADD,删除栏位DROP,改变栏位名称CHANGE和改变栏位种类MODIFY。
alter table Student add name
5.删除表格DROP TABLE
DROP TABLE “表格名”
drop table Student
6.修改表格UPDATE
使用UPDATA指令,可以修改表格中的资料。
UPDATE“表格名” SET “栏位1”=[新值] WHERE {条件}
7.插入资料INSERT INTO
加入一些资料进入表格
INSERT INTO “表格名”(“栏位1”,“栏位2”,……)
VALUES(“值1”,“值2”,…)
8.删除资料DELETE FROM
有时需要直接从数据库中去除一些资料。可以使用DELETE FROM实现。
DELETE FROM “表格名”
WHERE{条件}
9.限制条件CONSTRAINT
NOT NULL:不允许一个栏位含有NULL值。
UNIQUE:保障一个栏位中的所有资料都是不一样的值。
CHECK:限制保障一个栏位的所有资料符合某些条件。
PRIMARY KEY:主键
FOREIGN KEY:外键
10.select查询
select (列名) from (表名)where (限制)

(1)ORDER BY
可以对获取的资料进行排序,从小到大ASC,从大到小DESC
ORDER BY “栏目名” [ASC,DESC]
(2)LIKE
多在WHERE中使用,能根据特征模式获取我们要的数据
SELECT “栏目名”
FROM “表格名”
WHERE “栏目名”LIKE{模式}
例:WHERE store_name LIKE ‘%AN%’
(3)BETWEEN
可以使我们通过一个范围获得数据库中的值
SELECT “栏目名”
FROM “表格名”
WHERE “栏目名”BETWEEN ‘值一’AND‘值二’
例:WHERE Date BETWEEN ‘1919-02-02’ AND ‘2020-02-20’
(4)DISTINCT
在表中,有可能会包含重复值,DISTINCT 可以返回唯一不同的值。
SELECT DISTINCT 列 FROM 表
(5)GROUP BY
可以将表按照列属性进行分组,进行分开处理
SELECT “栏位1”,SUM“栏位2”
FROM “表格名”
GROUP BY “栏位1”
(6)HAVING
实现对组的值的筛选,一般跟在GROUP BY的后面,一个含有HAVING字句的SQL并不一定有GROUP BY 子句。
SELECT “栏位1”
FROM “表格名”
GROUP BY “栏位1”
HAVING (函数条件)
(7)区别HAVING 和WHERE
①WHERE 和HAVING 都是用来筛选的
②HAVING 用来筛选组,WHERE 用来筛选记录。where搜索条件在分组操作之前应用,having搜索条件在进行分组操作之后应用
③当一个查询包含了where条件和聚合函数,先执行条件过滤,再进行聚合函数,如:SELECT SUM(score) FROM sc WHERE score > 60 先过滤出score>60的记录,再进行SUM求和
④having在聚合之后进行过滤,having在分组的时候会用,对分组结果进行过滤,通常分组里面包含聚合函数,如:
SELECT sid,AVG(score) FROM sc GROUP BY sid HAVING AVG(score) >60;
(8)集合函数
AVG 平均
COUNT 计数
SUM 求和
MAX 最大值
MIN 最小值
(9)连接
自然连接:比较两个表的共同列,并保存共同的列值。
SELECT “栏位1”
FROM TABLE_A NATURAL JOIN TABLE_B
左连接:保留左表的全部列,和右表与左表相同的列值。
SELECT “栏位1”
FROM TABLE_A LEFT JOIN TABLE_B ON [A表值]=[B表值]
右连接:保留右表的全部列,和左表与右表相同的列值。
SELECT “栏位1”
FROM TABLE_A RIGHT JOIN TABLE_B ON [A表值]=[B表值]
11. sql主键
主键约束
PRIMARY KEY 约束唯一标识数据库表中的每条记录。
主键必须包含唯一的值。
主键列不能包含 NULL 值。
每个表都应该有一个主键,并且每个表只能有一个主键。
12.sql外键
一、外键的定义
1. 外键是一种索引,是通过一张表中的一列指向另一张表的主键,使得这两张表产生关联
2. 是某个表中的一列,它包含在另一个表的主键中
3. 一张表中可以有一个外键也可以有多个外键
二、外键的作用
减少单张表的冗余信息
三、使用外键后想要删除/更新主表的相关列会报错,因为从表正在使用。使用外键后若想向从表中插入新列,但是外键值主表中没有,会报错,更新从表的外键值,但是值不在从表中会报错。
13.视图与表的区别
为什么要创建索引呢?这是因为,创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序 子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
第一,创建索引和维护索引要耗费时间,这种时间随着数据 量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
C++ 三大特性是:封装,继承,多态
封装(encapsulation):封装就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成“类”,其中数据和函数都是类的成员。封装的目的是增强安全性和简化编程,使用者不必了解具体的实现细节,而只是要通过 外部接口,一特定的访问权限来使用类的成员。通过封装使一部分成员充当类与外部的接口,而将其他的成员隐蔽起来,这样就达到了对成员访问权限的合理控制,使不同类之间的相互影响减少到最低限度,进而增强数据的安全性和简化程序的编写工作。
继承:继承是面向对象软件技术当中的一个概念。如果一个类B继承自另一个类A,就把这个B称为A的子类,而把A称为B的父类。**继承可以使得子类具有父类的各种属性和方法,而不需要再次编写相同的代码。**在令子类继承父类的同时,可以重新定义某些属性,并重写某些方法,即覆盖父类的原有属性和方法,使其获得与父类不同的功能。
多态(Polymorphisn):多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说:允许将子类类型的指针赋值给父类类型的指针。多态性在C++中都是通过虚函数(Virtual Function)实现的。虚函数就是允许被其子类重新定义的成员函数。而子类重新定义父类虚函数的做法,称为“覆盖”或者称为“重写”(override)。
1、概念
数组:存储连续多个相同类型的数据;
指针:变量,存的是地址
2、赋值
同类型的指针变量可以相互赋值,数组不行,只能一个一个元素的赋值或拷贝
3、存储方式
数组:连续内存空间。
指针:灵活,可以指向任意类型的数据。指向的是地址空间的内存。
4、sizeof
数组的sizeof求的是占用的空间(字节)。
在32位平台下,无论指针的类型是什么,sizeof(指针名)都是4,在64位平台下,无论指针的类型是什么,sizeof(指针名)都是8。
还会什么语言
14. shell脚本 awk切割文件 sed替换 改名字
15. C:\log.txt,查找文件中‘ABCD’出现的次数. cat log.txt | grep -o ‘ABCD’|wc -l C语言实现会写吗?
从测试方法上分,软件测试可分为白盒测试和黑盒测试。
(1)白盒
把程序看成装在一个透明的白箱子里,测试者完全知道程序的结构和算法。
白盒测试,又称结构测试,主要用于单元测试阶段。
白盒测试根据软件的内部逻辑设计测试用例,常用的技术是逻辑覆盖。
主要的覆盖标准有 6 种:语句覆盖、判定覆盖、条件覆盖、判定/条件覆盖、组合条件覆盖和路径覆盖。
语句覆盖:每个语句执行一次
判定覆盖:每个语句+每个可能结果执行一次
条件覆盖:每个语句+每个条件执行一次
判定/条件覆盖:判定覆盖+条件覆盖 每个条件的每个结果出现一次
条件组合覆盖:每个条件结果的所有组合出现一次
路径覆盖:每个执行到的路径经过一次
(2)黑盒
把软件看作一个不透明的黑箱子,完全不考虑(或不了解)软件的内部结构和处理算法,它只检查软件功能是否能按照软件需求说明书的要求正常使用,软件是否能适当地接收输入数据并产生正确的输出信息,软件运行过程中能否保持外部信息(例如文件和数据库)的完整性等。
黑盒测试,又称功能测试,主要用于集成测试和确认测试阶段。
常用的黑盒测试技术包括等价类划分、边值分析、错误推测和因果图等。
等价类划分:等价类就是输入域的集合,等价类划分就是对输入域的划分,分为有效和无效,分别用来检测功能有效性和软件容错性。
边值分析:测试用例在边界附近
错误推测:人员自主推测,容易出错的部分
因果图:输入与输出的因果关系设计
需求分析:分析客户的需求可不可行。
编写测试计划。
编写测试用例:测试用例就是指导测试的文档。
执行测试:提交bug,回归测试。
编写测试总结报告。
1、从是否关心内部结构来看
(1)白盒测试。
(2)黑盒测试。
(3)灰盒测试:是一种综合测试法,它将“黑盒”测试与“白盒”测试结合在一起,是基于程序运行时的外部表现又结合内部逻辑结构来设计用例。
2、从是否执行代码看
(1)静态测试:指不运行被测程序本身,仅通过分析或检查源程序的语法、结构、过程、接口等来检查程序的正确性。
(2)动态测试:是指通过运行被测程序,检查运行结果与预期结果的差异,并分析运行效率、正确性和健壮性等性能指标。
3、从开发过程级别看
(1)单元测试:又称模块测试,是针对软件设计的最小单位-程序模块或功能模块。其目的在于检验程序各模块是否存在各种差错,是否能正确地实现了其功能,满足其性能和接口要求。
(2)集成测试:又叫组装测试或联合,是单元测试的多级扩展,是在单元测试的基础上进行的一种有序测试。旨在检验软件单元之间的接口关系,以期望通过测试发现各软件单元接口之间存在的问题,最终把经过测试的单元组成符合设计要求的软件。
(3)系统测试:是为判断系统是否符合要求而对集成的软、硬件系统进行的测试活动、它是将已经集成好的软件系统,作为基于整个计算机系统的一个元素,与计算机硬件、外设、某些支持软件、人员、数据等其他系统元素结合在一起,在实际运行环境下,对计算机系统进行一系列的组装测试和确认测试。
4、从执行过程是否需要人工干预来看
(1)手工测试:就是测试人员按照事先为覆盖被测软件需求而编写的测试用例,根据测试大纲中所描述的测试步骤和方法,手工地一个一个地输入执行,包括与被测软件进行交互(如输入测试数据、记录测试结果等),然后观察测试结果,看被测程序是否存在问题,或在执行过程中是否会有一场发生,属于比较原始但是必须执行的一个步骤。
(2)自动化测试:实际上是将大量的重复性的测试工作交给计算机去完成,通常是使用自动化测试工具来模拟手动测试步骤,执行用某种程序设计语言编写的过程(全自动测试就是指在自动测试过程中,不需要人工干预,由程序自动完成测试的全过程;半自动测试就是指在自动测试过程中,需要手动输入测试用例或选择测试路径,再由自动测试程序按照人工指定的要求完成自动测试
5、从测试实施组织看
(1)开发测试:开发人员进行的测试
(2)用户测试:用户方进行的测试
(3)第三方测试:有别于开发人员或用户进行的测试,由专业的第三方承担的测试,目的是为了保证测试工作的客观性
6、从测试所处的环境看
(1)阿尔法测试:是由一个用户在开发环境下进行的测试,也可以是公司内部的用户在模拟实际操作环境下进行的测试
(2)贝塔测试:是用户公司组织各方面的典型终端用户在日常工作中实际使用贝塔版本,并要求用户报告
7、其他测试类型
(1)回归测试(regression testing)是指对软件的新的版本测试时,重复执行上一个版本测试时的用例。
(2)冒烟测试(smoke testing),是指在对一个新版本进行大规模的测试之前,先验证一下软件的基本功能是否实现,是否具备可测性。
(3)随机测试(random testing),是指测试中所有的输入数据都是随机生成的,其目的是模拟用户的真实操作,并发现一些边缘性的错误。
【功能测试】
1.输入正确的用户名密码是否能够正确登录
用户名存在、对应密码存在正确 弹框:登入成功、跳转页面
2.输入错误的用户名密码是否会判断错误
用户名存在、对应密码存在不正确 弹框:密码错误
用户名不存在、密码存在 弹框:用户名或密码错误
用户名不存在、密码不存在 弹框:用户名或密码错误
输入相同账号输错密码三次以上需等待三分钟再次输入
3.登陆成功后能否跳到正确页面
4.用户名和密码,如果太短或者太长,应该怎么处理
用户名或密码输入太短或太长 弹框:输入不合法
5.用户名和密码,中有特殊字符,和其他非英文的情况
弹框:输入不合法
6.验证码:随机生成图片;点击可换取随机生成图片
7.输入框可粘贴与粘贴长度:密码框可粘贴长度不超过20,用户账号框粘贴长度不超过12
8.密码是否以星号显示
【界面测试(UI Test)】
布局是否合理,2个testbox 和一个按钮是否对齐
testbox和按钮的长度,高度是否复合要求
界面是否好看
图片,颜色,字体,超链接,是否都显示正确
【性能测试(performance test)】
打开登录页面,需要几秒
输入正确的用户名和密码后,登录成功跳转到新页面,不超过5秒
能支持多少个用户同时登陆
【安全性测试(Security test)】
登录成功后生成的Cookie,是否是httponly (否则容易被脚本盗取)
用户名和密码是否通过加密的方式,发送给Web服务器
用户名和密码的验证,应该是用服务器端验证, 而不能单单是在客户端用javascript验证
用户名和密码的输入框,应该屏蔽SQL 注入攻击
用户名和密码的的输入框,应该禁止输入脚本 (防止XSS攻击)
错误登陆的次数限制(防止暴力破解)
【可用性测试(Usability Test)】
是否可以全用键盘操作,是否有快捷键
输入用户名,密码后按回车,是否可以登陆
【兼容性测试(Compatibility Test)】
主流的浏览器下能否显示正常已经功能正常(IE,6,7,8,9, Firefox, Chrome, Safari,等)
不同的平台是否能正常工作,比如Windows, Mac
移动端ios、安卓
一、功能
红包封面:(1)不选择会有默认封面;(2)是否可以选择红包封面
红包描述:(1)在红包描述中是否可以输入汉字,英文,符号,表情,纯数字,汉字英语符号emjo,动态表情以及现场拍摄的图片等;(3)红包描述中输入自己的表情,抢红包的人是否可以正常看见;(4)红包描述中最多能有多少个字符(超过10个)。
红包金额:(1)在红包钱数和红包个数输入框中只能输入数字(测试输入红包钱数是不是只能输入数字);(2)红包里最多和最少可以输入的钱数(最多:200,最少:0.01);(3)如果直接输入小数点,那么小数点之前应该有一个0;(4)当红包钱数超过最大范围是不是有对应的提示(一对一:200,群发:20000);(5)输入钱数为0,“塞钱进红包”置灰;(6)发红包金额和收到的红包金额应该匹配(分别测试一对一和群发的场景)。
塞钱进红包,扣钱顺序:(1)主动设置优先级;(2)默认顺序(从零钱开始支付;如果零钱不足,看那种方式付钱比较充足);(3)确认的时候,自己选择付款方式。
余额不足:(1)银行卡;(2)零钱;(3)零钱通。
支付验证方式:(1)密码;(2)指纹;(3)刷脸;(4)声音;(5)免密支付。
取消发送:可以按取消键,取消发送红包;
支付成功后,退回聊天界面;
发送红包:(1)测试发送出去的红包能否撤回(可以测试转账能否撤回);(2)发送的红包别人是否可以领取,针对一对一场景,测试发的红包自己是否可以领取,群发的是否可以正常领取。
领红包:超过24小时没有领取的红包,是否还可以领取(不可以)。
红包记录:(1)在发红包界面能否看到以前的收发红包记录;(2)红包记录里的信息与实际发红包记录是否匹配。
是否可以连续多次发红包;
退款到账的时间。
电脑(PC端)是否可以抢微信红包。
二、性能
断网时,无法抢红包。
不同网速时,发红包,抢红包的时间。
发红包和收红包成功时的跳转时间。
收发红包时的耗电量。
三、兼容性
苹果、安卓是否都可以发红包,抢红包。
四、界面
发红包界面没有错别字。
抢完红包界面没有错别字。
发红包和收红包界面排版是否合理。
发红包和收红包界面颜色搭配是否合理。
群发红包后,红包收取记录界面。
五、安全性
红包呗领取以后,发送红包人的金额是否会减少,收红包人的金额是否会增加。
发送红包失败,查看余额和银行卡里的钱是否会变化。
红包发送成功,是否会收到微信支付的通知。
六、易用性
红包描述中,金额,红包个数框里是否支持复制粘贴操作。
红包描述,是否可以通过语音输入。
是否可以指纹支付,密码支付,或者免密,刷脸等。
3.对桌子测试(什么鬼问题
需求测试:查看国家相关标准。
功能:桌子是办公,或者放置用的,首先考虑桌子的面积大小是否适度.抽屉够不够,高度合不合适。
界面:桌子的版面是否平滑,桌子有没有凹凸不平的地方
安全:桌子肯定有它的支撑点,若支撑点不稳,容易摔坏物品,使用起来也不方便
易用:桌子的移动性好不.它的重量是否合适
可靠性:将桌子推倒后,再检查桌子是否很容易被损坏.
性能:将很重的物品放在桌子上,看它最大承受的重量是多少...
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI