🚩本文已收录至专栏:微服务探索之旅
👍希望您能有所收获
Eureka和Nacos一样也可以充当服务的注册中心,让我们一起看看有何区别?
点击跳转👉【微服务】Nacos注册中心
假如我们的服务提供者user-service部署了多个实例,如图:

大家思考几个问题:
问题一:order-service在发起远程调用的时候,该如何得知user-service实例的ip地址和端口?
问题二:有多个user-service实例地址,order-service调用时该如何选择?
问题三:order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
上述问题都需要利用SpringCloud中的注册中心来解决,其中最广为人知的注册中心就是Eureka,其结构如下:
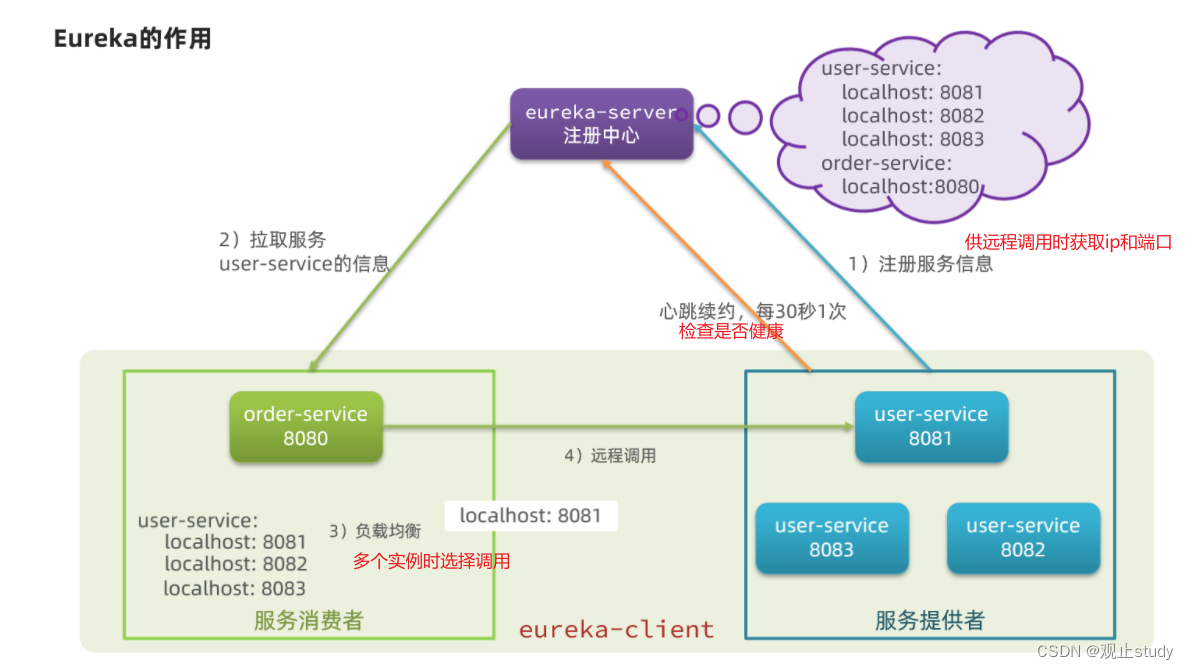
让我们一起看看Eureka如何解决上述问题
问题1:order-service如何得知user-service实例地址?
user-service服务每个实例启动后,都会将自己的信息注册到eureka-server(Eureka服务端)。这个叫服务注册
eureka-server保存服务名称到服务实例地址列表的映射关系
order-service根据服务名称,拉取实例地址列表。这个叫服务发现或服务拉取
问题2:order-service如何从多个user-service实例中选择具体的实例?
order-service从实例列表中利用负载均衡算法选中一个实例地址
向该实例地址发起远程调用
问题3:order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
user-service会每隔一段时间(默认30秒)向eureka-server发起请求,报告自己状态,称为心跳
当超过一定时间没有发送心跳时,eureka-server会认为微服务实例故障,将该实例从服务列表中剔除
order-service拉取服务时,就能将故障实例排除了
注意:一个微服务,既可以是服务提供者(注册信息,发送心跳),又可以是服务消费者(拉取服务列表,远程调用),因此eureka将服务注册、服务发现等功能统一封装到了eureka-client端
接下来让我们按照如下步骤动手实践Eureka使用流程:
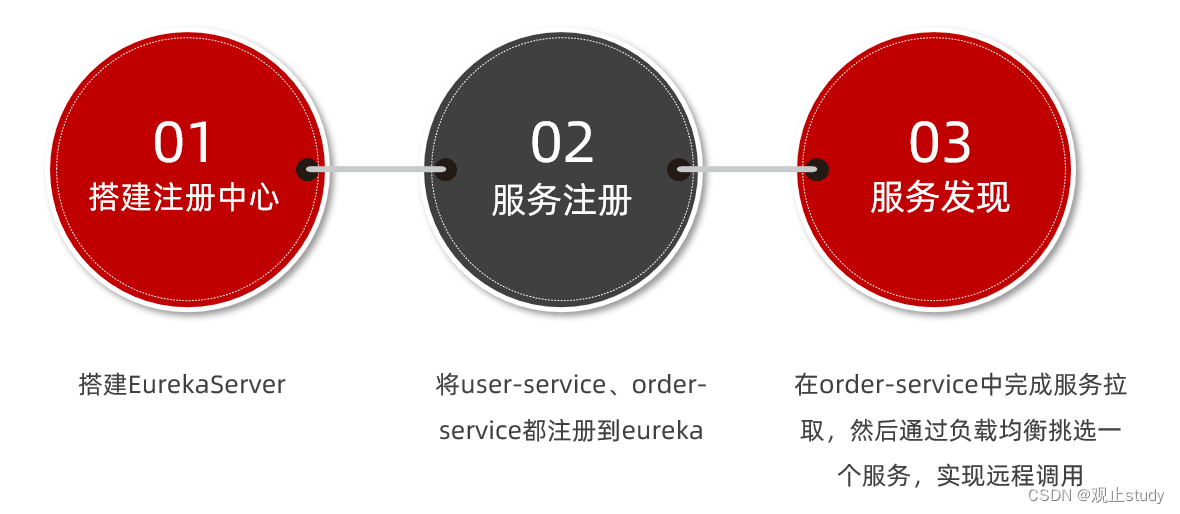
首先注册中心服务端:eureka-server,这必须是一个独立的微服务
在cloud-demo父工程下,创建一个子模块:
填写模块信息:
然后填写服务信息:
在eureka-server的pom文件中引入SpringCloud为eureka提供的starter依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
注:如果父工程没有统一管理依赖版本,此处需要指定依赖版本
给eureka-server服务编写一个启动类,一定要添加@EnableEurekaServer注解,开启eureka的注册中心功能:
package cn.itcast.eureka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
创建一个application.yml文件,添加如下内容:
server:
port: 10086 # 服务端口
spring:
application:
name: eureka-server # eureka的服务名称
eureka:
client:
service-url: # eureka的地址信息
defaultZone: http://127.0.0.1:10086/eureka
说明:eurake也是一个微服务,所以在启动时也会将自己注册到eureka(集群时通信使用)
启动微服务后,可以在浏览器访问上述配置的地址:http://127.0.0.1:10086
看到下面结果应该是成功了:
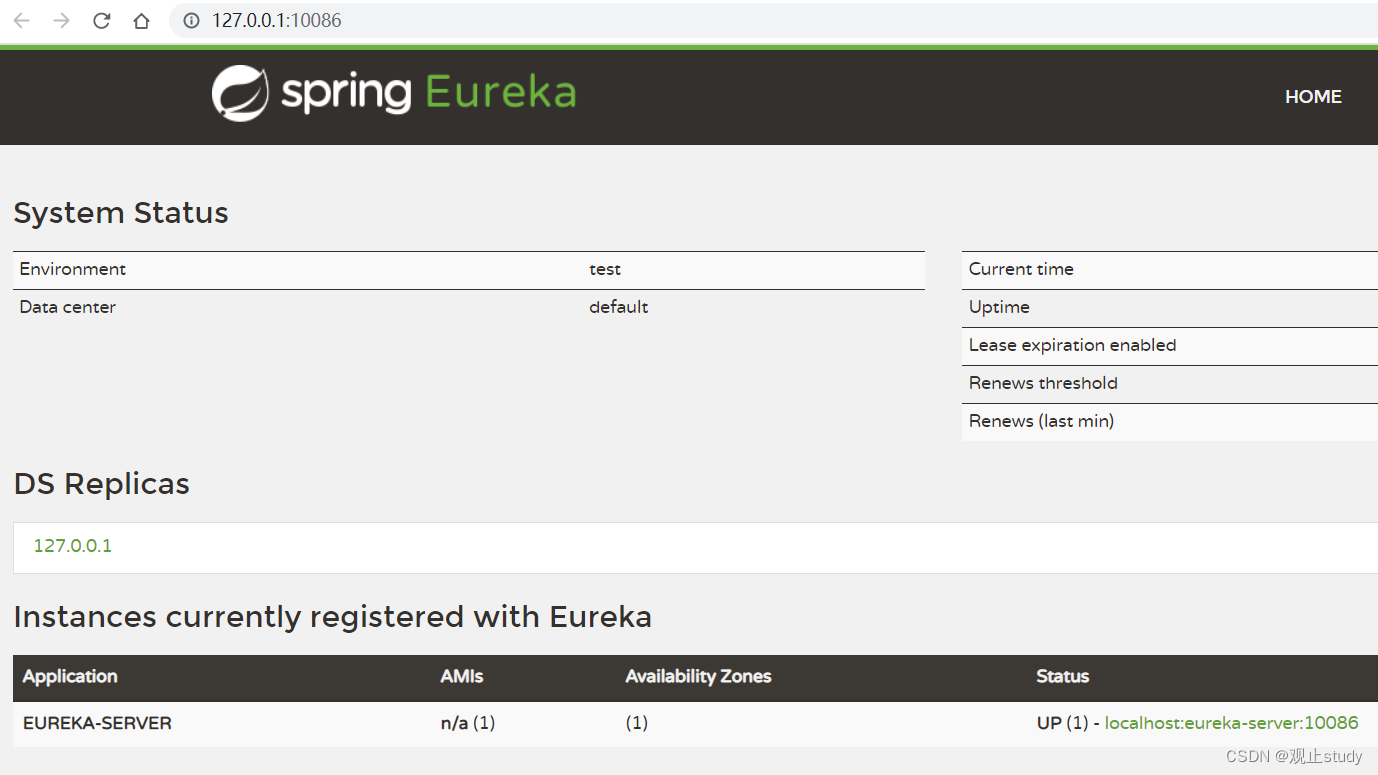
eureka已经搭建好了,接下来,我们将服务user-service注册到eureka-server中去。
在user-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
注:如果父工程没有统一管理依赖版本,此处需要指定依赖版本
在user-service中,修改application.yml文件,添加服务名称、上述eureka地址:
spring:
application:
name: userservice # user服务的服务名称
eureka:
client:
service-url: # euraka的地址信息
defaultZone: http://127.0.0.1:10086/eureka
为了演示一个服务有多个实例的场景,我们添加一个SpringBoot的启动配置,再启动一个user-service。
首先,复制原来的user-service启动配置:
然后,在弹出的窗口中,填写信息:
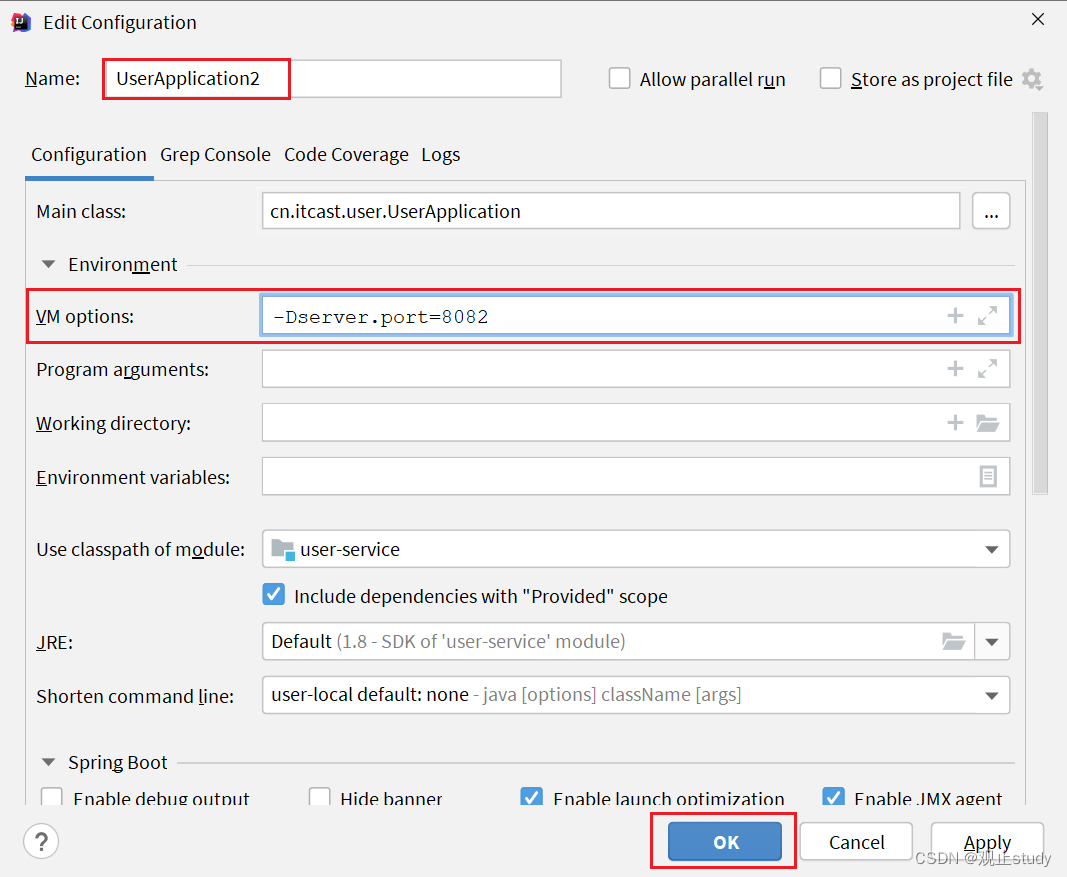
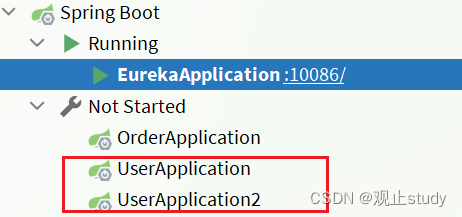
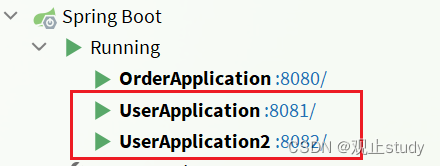

我们可以看到启动的两个user-service实例已经成功注册到eureka
下面,我们将order-service的逻辑修改:向eureka-server拉取user-service的信息,再次进行远程调用(实现服务发现)。
之前说过,服务发现、服务注册统一都封装在eureka-client依赖,因此这一步与服务注册时一致。
在order-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
注:如果父工程没有统一管理依赖版本,此处需要指定依赖版本
服务发现也需要知道eureka地址,因此第二步与服务注册一致,都是配置eureka信息:
在order-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:
application:
name: orderservice # # order服务的服务名称
eureka:
client:
service-url: # euraka的地址信息
defaultZone: http://127.0.0.1:10086/eureka
修改order-service服务中OrderService类中的queryOrderById方法。修改访问的url路径,用注册的服务名代替ip、端口:
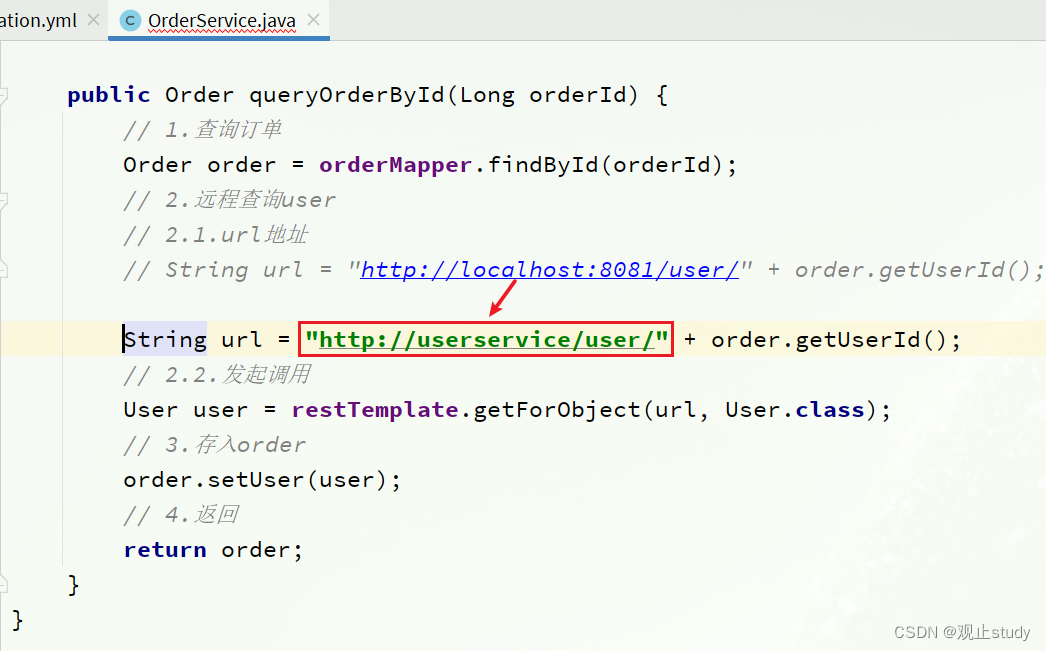
spring会自动帮助我们从eureka-server端,根据userservice这个服务名称,获取实例列表,而后完成负载均衡。
最后,我们要对拉取的user-service服务的实例列表实现负载均衡。
在order-service的启动类OrderApplication中,给RestTemplate这个Bean添加一个@LoadBalanced注解实现负载均衡:
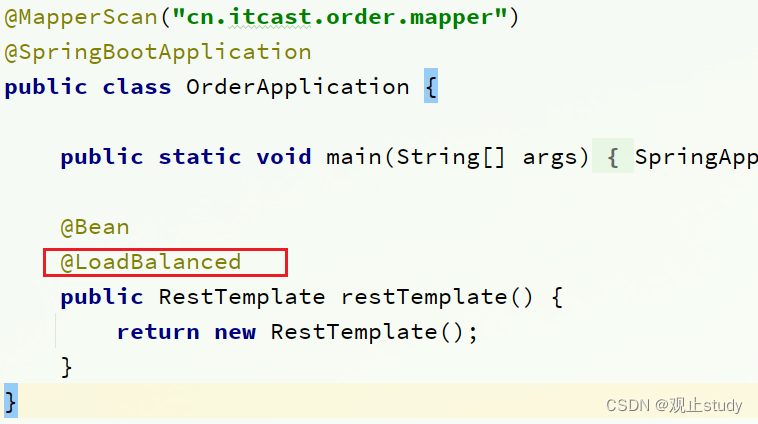
我们可以发现访问:http://localhost:8080/order/ 101 102 103 104 两个实例都接收到了请求并响应实现了负载均衡。
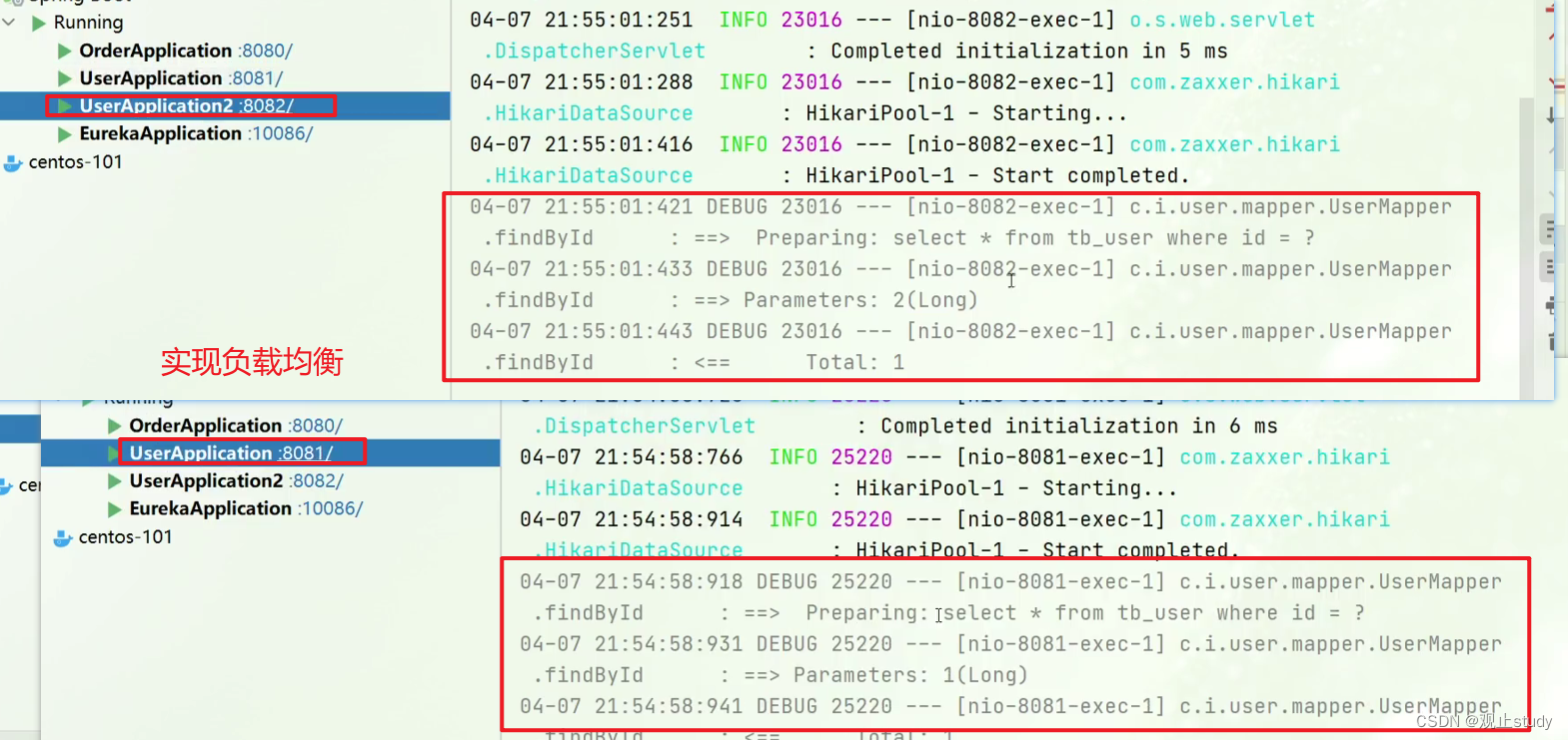
上一节中,我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。
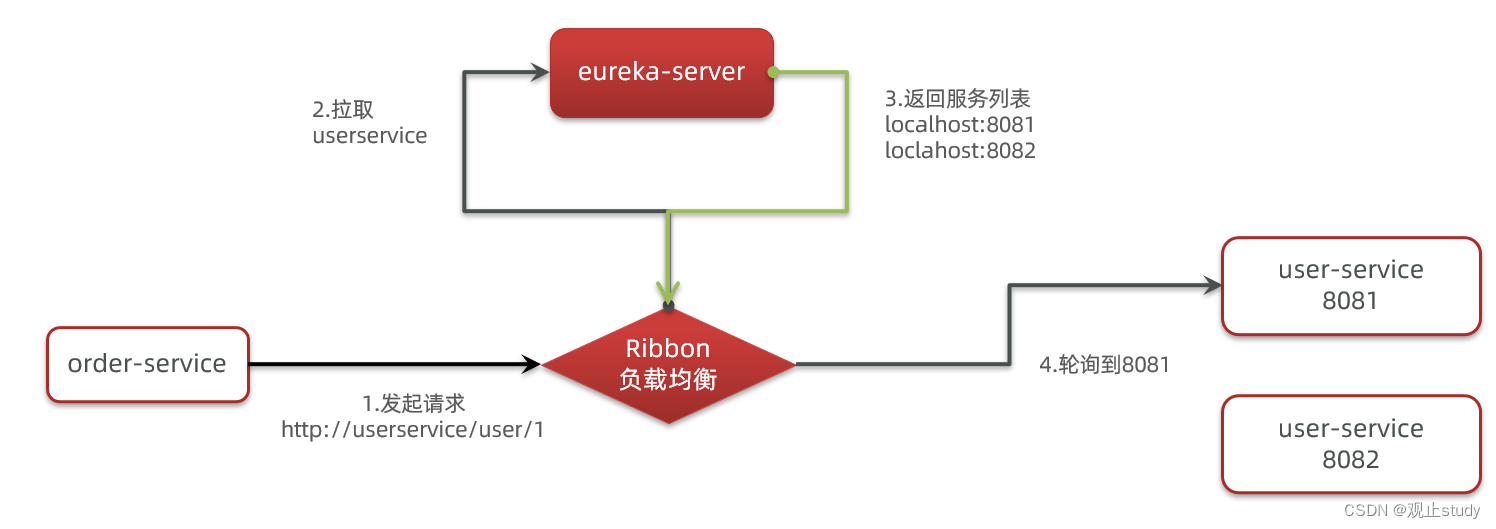
那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们进行源码跟踪:
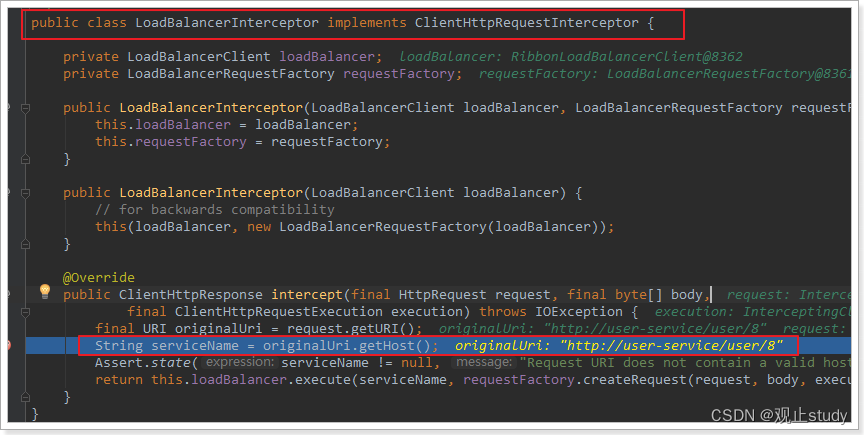
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri,本例中就是 http://user-service/user/8originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-servicethis.loadBalancer.execute():处理服务id,和用户请求。这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入。
继续跟入execute方法:
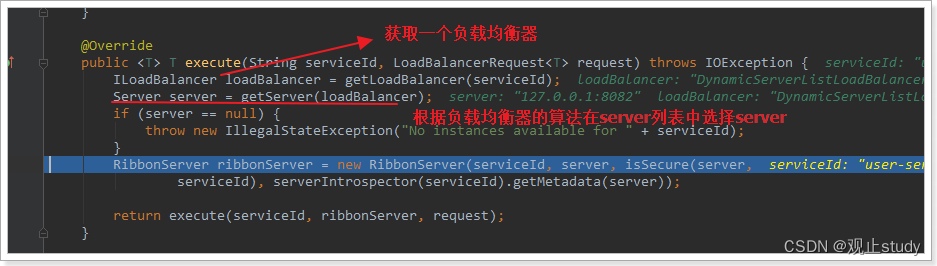
代码是这样的:
放行后,再次访问并跟踪,发现获取的是8081:
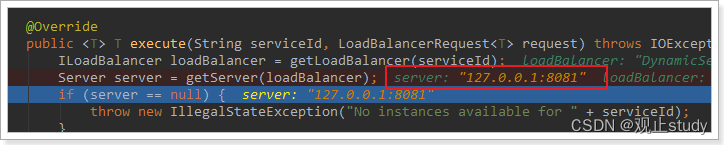
果然实现了负载均衡。
在刚才的代码中,可以看到获取服务使通过一个getServer方法来做负载均衡:
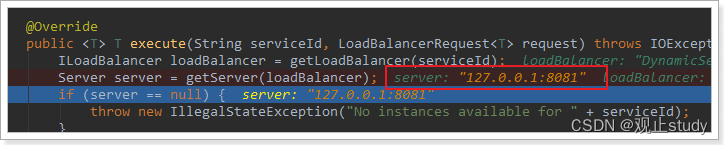
我们继续跟入:
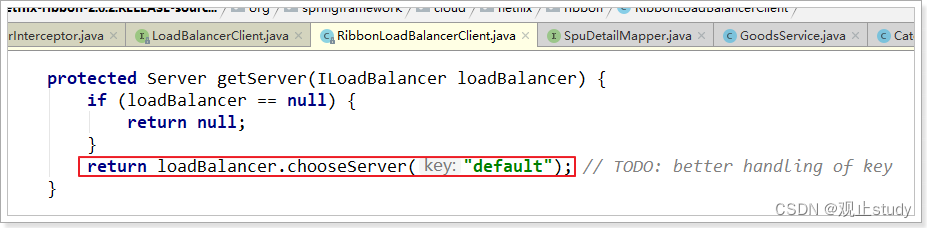
继续跟踪源码chooseServer方法,发现这么一段代码:
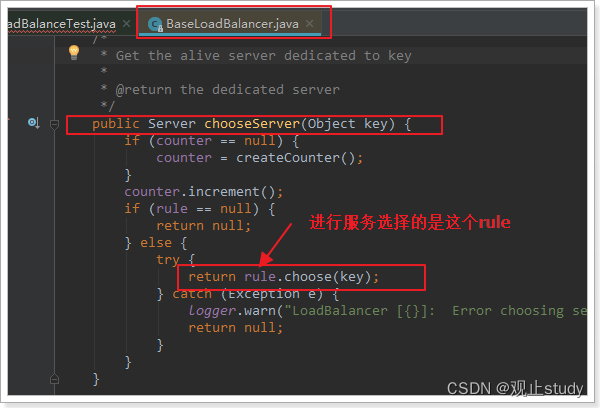
我们看看这个rule是谁:
这里的rule默认值是一个RoundRobinRule,看类的介绍:
这不就是轮询的意思嘛。
到这里,整个负载均衡的流程我们就清楚了。
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
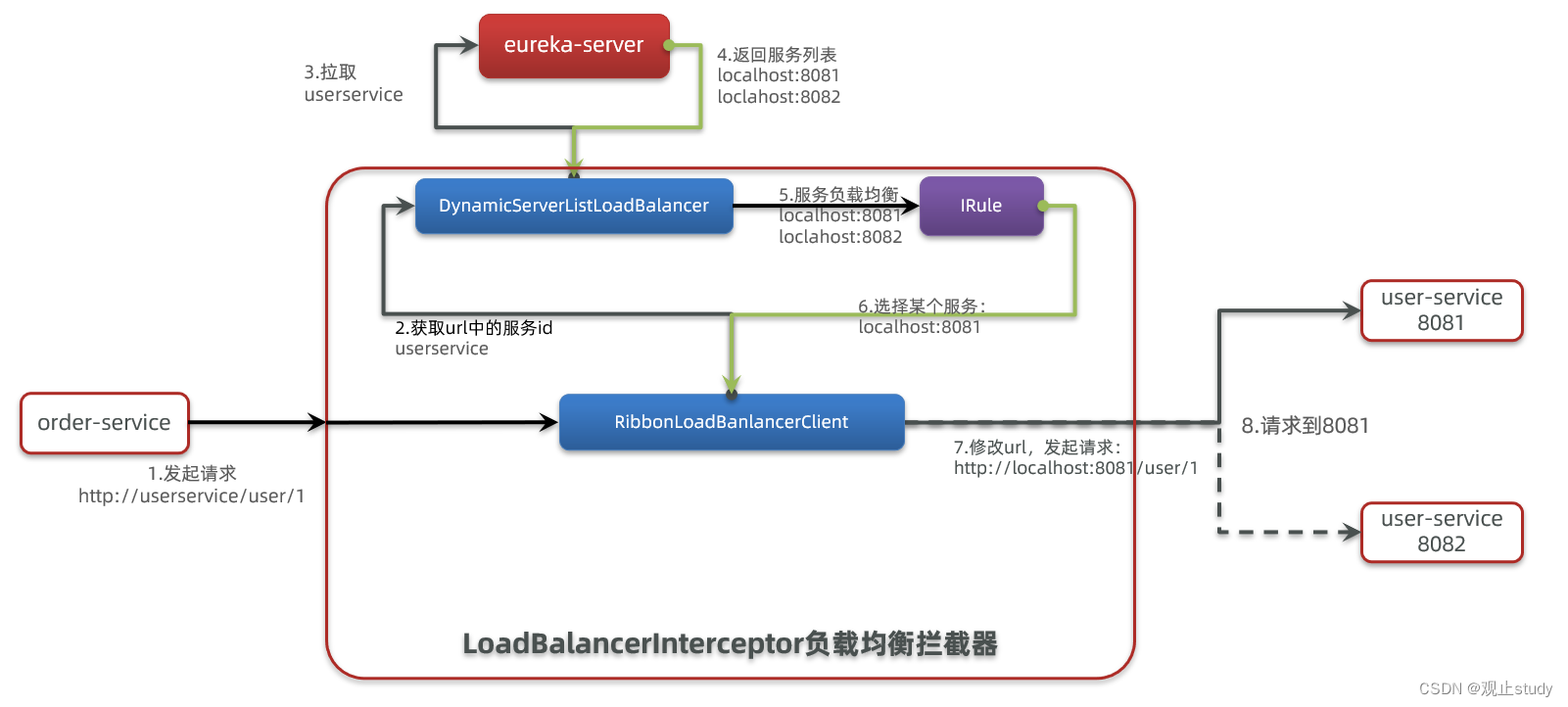
基本流程如下:
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类:
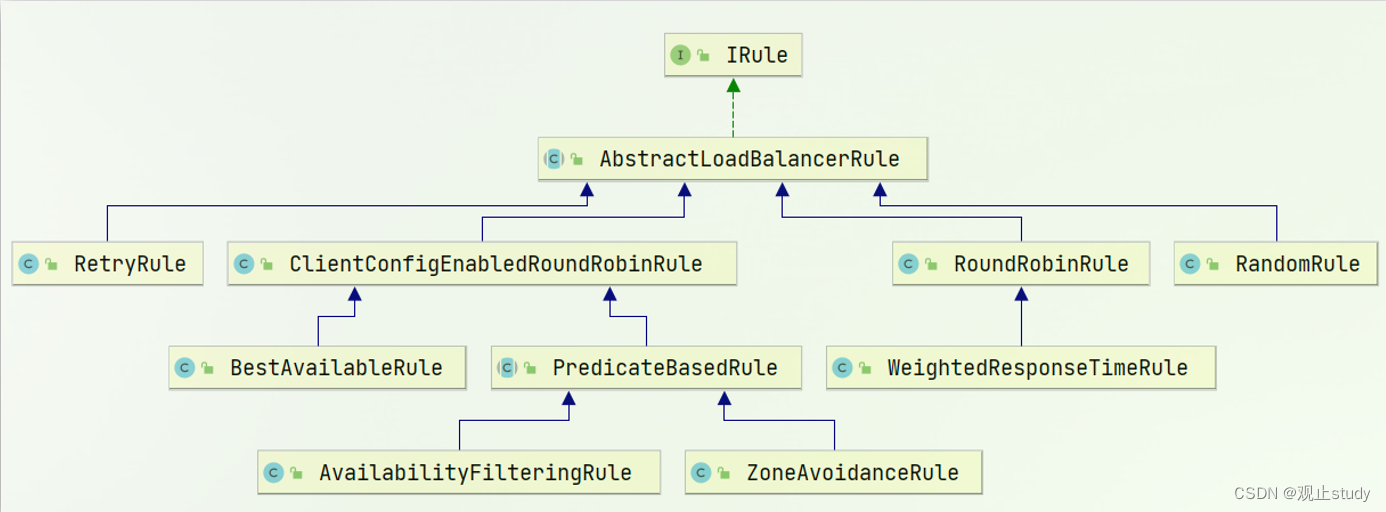
不同规则的含义如下:
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的..ActiveConnectionsLimit属性进行配置。 |
| WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
| BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
| RandomRule | 随机选择一个可用的服务器。 |
| RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
通过定义IRule实现可以修改负载均衡规则,有两种方式:
@Bean
public IRule randomRule(){
return new RandomRule();
}
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则
注意,一般用默认的负载均衡规则,不做修改。
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,可在yml文件中进行下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients: userservice # 指定对userservice这个服务饥饿加载

对比可见请求加载时间缩短了许多
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我在我的项目中有一个用户和一个管理员角色。我使用Devise创建了身份验证。在我的管理员角色中,我没有任何确认。在我的用户模型中,我有以下内容:devise:database_authenticatable,:confirmable,:recoverable,:rememberable,:trackable,:validatable,:timeoutable,:registerable#Setupaccessible(orprotected)attributesforyourmodelattr_accessible:email,:username,:prename,:surname,:
完成这个有困难。我正在使用seed.rb+factory_girl来使用rakedb:seed填充数据库。(我知道固定装置存在,但我想以这种方式完成,这只是一个示例,数据库将填充复杂的关联对象。)我的种子.rb:require'factory_girl_rails'["QM","CDC","SI","QS"].eachdo|n|FactoryGirl.create(:grau,nome:n)end还有我的/factories/graus.rbFactoryGirl.definedofactory:graudonomeendend但是当我运行时:rakedb:seed我得到:rakeab
我正在使用carrierwave上传视频然后有一个名为thumb的版本,带有自定义处理器,可以获取视频并使用streamio-ffmpeg创建屏幕截图。视频和文件都已正确上传,但在调用uploader.url(:thumb)时我得到:ArgumentError:Versionthumbdoesn'texist!VideoUploader.rbrequire'carrierwave/processing/mime_types'require'streamio-ffmpeg'classVideoUploader5)File.renamethumb_path,current_pathendd
我正在使用Deviseauthtokengem用于验证我的Rails应用程序的某些部分。但是,当我尝试使用注册路径创建新用户时,出现以下错误{"errors":["Authorizedusersonly."]}。这是我用于测试的rspec代码,it'createsauserusingemail/passwordcombo'dopostapi_user_registration_path,{email:'xxx',password:'yyy',password_confirmation:'yyy'}putslast_response.bodyexpect(last_response.bo
这道题开始于here.但随着我对雷神的了解越来越多,情况发生了很大变化。我正在尝试创建一个带参数的Thor::Group子命令。奇怪的是,如果没有参数,它就可以工作。我可以使用Thor::Group作为子命令吗?这在我输入时有效:foocounterfoo/bin/foomoduleFooclassCLI但是当我输入时这不起作用:foocounter5moduleFooclassCLI','Countupfromtheinput.')endclassCounter:numeric,:desc=>"Thenumbertostartcounting"desc"Prints2numbersb
我正在使用railswithdevise进行注册。我还添加了一个邀请码,所以不是每个人都可以注册。邀请码通过“/users/sign_up?invite_code=wajdpapojapsd”之类的查询字符串传输,并使用“f.hidden_field:invite_code,:value=>params[”添加到注册表单的隐藏字段中:invite_code]".这很好用。唯一的问题是,如果注册没有得到验证和拒绝,设计重定向到“/users”并丢失带有invite_code的查询字符串。由于电子邮件在尝试失败后保留在注册表单中,我相信这也适用于邀请代码。作为最坏情况的解决方案,在注册
我有一个Rails4.2.3应用程序,我在其中使用Devise进行用户身份验证。我在Bootstrap模式中展示我的注册表单。我已经实现了类似于:https://github.com/plataformatec/devise/wiki/How-To:-Display-a-custom-sign_in-form-anywhere-in-your-app.注册时我不断收到此错误:Completed406NotAcceptablein512033ms(ActiveRecord:5.8ms)ActionController::UnknownFormat(ActionController::Un
我使用geokit和geokit-railsgemforrails有一段时间了,但我还没有找到答案的一个问题是如何找到一组点的计算聚合中心。我知道如何计算两点之间的距离,但不会超过2。我的理由是,我在同一个城市中有一系列的点……一切都完美的城市会有一个我可以使用的中心,但有些城市,比如柏林没有一个完美的中心。他们有多个中心,我只想使用我数据库中的所有地点列表来计算特定分布的中心。还有其他人遇到过这个问题吗?有什么建议吗?谢谢 最佳答案 之前从未使用过Geokit,这个操作背后的数学原理相对容易自己实现。假设这些点由纬度和经度组成,您