第一章 ❤️ 二分查找
文章目录
经历了一段时间的《数据结构与算法》学习,你已经从凡人步入了修仙界,现在你可以尝试去接触一些简单的算法题开始你的修仙生涯了,那今天我们来看看今天的修炼吧⛽⛽⛽

这是是一道非常经典的入门级修炼功法,收录在力扣# 704,而它的名字就已经将写法写在你的脸上了😂——二分查找
ps:工欲善其事必先利其器,一部好的功法可以让你在修仙路上少走许多弯路。😏😏😏
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好,占用系统内存较少;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
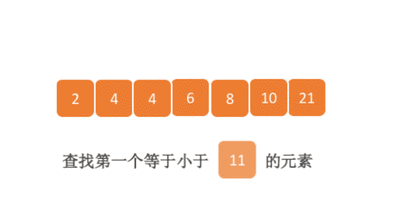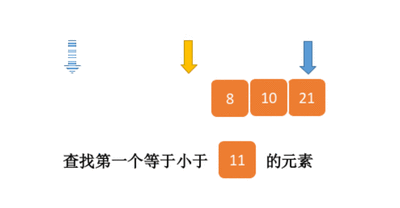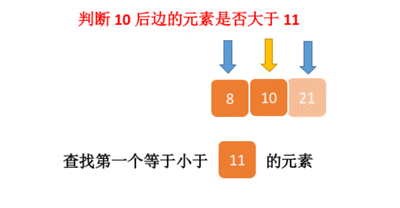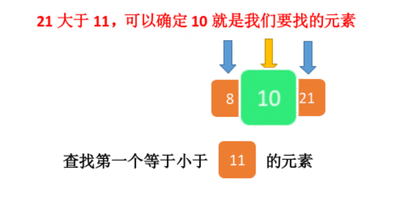
二分查找的基本思想是将n个元素分成大致相等的两部分,取a[n/2]与x做比较,如果x=a[n/2],则找到x,算法中止;如果x<a[n/2],则只要在数组a的左半部分继续搜索x,如果x>a[n/2],则只要在数组a的右半部搜索x.
因此我们需要left变量middle变量,right变量以及以各target变量
在这个阶段我们需要了解二分查找的基本运算方式,以及需要使用的变量。
我们应该了解下二分算法的易错点
1.在循环体的跳出判定条件是左边大于等于右边(left>=right)还是左边大于右边(left>right)
2.如果(str[middle]>target),那么接下来我们应该将(middle)更新为(right)还是(right-1)?
对待该问题我们需要首先将题意理解清楚,我们根据查找区间分为两种写法——左闭右闭写法和左必右开写法
左闭右闭写法故名思意在该区间我们两头的数都应该取到,我们假设一个这样的区间[1,1],很明显我们的判定条件上必须加上等于,与之相反的当区间为[1,1)左闭右开时我们不能加上等于号。
应对第二个问题我们只需简单的假设一下当我们使用左闭右闭写法时我们已经判断了(str[middle]>target)那么我们下一次判断的时候就不用该将(middle)加入进去那么自然我们会将(right)更新为(middle-1),当我们使用左闭右开写法时本来定义中就已经不包含(middle)值,那么我们为啥还要将(right)更新为(middle-1)呢?
简单总结一下:
左闭右闭写法——要等于号,并且(middle)应更新为(left=right+1)或(right=middle-1)
左闭右开写法——不要等于号,并且(middle)应更新为(right=middle和(left=middle+1)(这个地方要好好理解下哟)
#include<stdio.h>
#include<string.h>
#define MAX 100000
int search(int* nums, int numsSize, int target)
{
int left=0, right, middle;
right = numsSize;
while (left <= right)//这里是左闭右闭写法
{
middle = (left + right) / 2;
if (*(nums + middle) > target)
right = middle - 1;
else if (*(nums + middle) < target)
left = middle + 1;
else
return middle;
}
return -1;//查找失败,无该目标值
}
int main()
{
int nums[MAX] = { 0 };
int target = 0;
int numsSize = 0, i;
scanf("%d", &numsSize);//输入区间长度
printf("\n");
for (i = 0;i < numsSize;i++)
scanf("%d", nums + i);//输入查找区间
printf("\n");
scanf("%d", &target);//输入目标值
numsSize = strlen(nums);
printf("下标为:%d", search(nums,numsSize,target));
}
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
我想找到给定字符串中的所有匹配项,包括重叠匹配项。我怎样才能实现它?#Example"a-b-c-d".???(/\w-\w/)#=>["a-b","b-c","c-d"]expected#Solutionwithoutoverlappedresults"a-b-c-d".scan(/\w-\w/)#=>["a-b","c-d"],but"b-c"ismissing 最佳答案 在积极的前瞻中使用捕获:"a-b-c-d".scan(/(?=(\w-\w))/).flatten#=>["a-b","b-c","c-d"]参见Rubyde
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo
我有以下数组:arr=[1,3,2,5,2,4,2,2,4,4,2,2,4,2,1,5]我想要一个包含前三个奇数元素的数组。我知道我可以做到:arr.select(&:odd?).take(3)但我想避免遍历整个数组,而是在找到第三个匹配项后返回。我想出了以下解决方案,我相信它可以满足我的要求:my_arr.each_with_object([])do|el,memo|memo但是有没有更简单/惯用的方法来做到这一点? 最佳答案 使用lazyenumerator与Enumerable#lazy:arr.lazy.select(&:o
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
是否有内置的Ruby方法或众所周知的库可以返回对象的整个方法查找链?Ruby查看一系列令人困惑的类(如thisquestion中所讨论)以查找与消息对应的实例方法,如果没有类响应消息,则调用接收方的method_missing。我将以下代码放在一起,但我确信它遗漏了某些情况或者它是否100%正确。请指出任何缺陷并指导我找到一些更好的代码(如果存在)。defmethod_lookup_chain(obj,result=[obj.singleton_class])ifobj.instance_of?Classreturnadd_modules(result)ifresult.last==B
我有以下数组:A=[1,2,3,4,5]B=[2,6,7,1]我想找到不相交的元素,如下:output=[3,4,5,6,7]我是这样实现的,output=A+B-(A&B)但它效率低下,因为我添加了两个数组,然后删除了公共(public)元素。它类似于查找不相交的元素。我能做得比这更好吗?如果是,怎么办? 最佳答案 如何只选择A中的元素而不是B中的元素以及B中的元素而不是A中的元素。(A-B)+(B-A) 关于arrays-在两个数组中查找不相交元素的有效方法是什么?,我们在Stack
给定一个数组['a','b','c','d','e','f'],我如何获得包含两个的所有子集的列表、三、四元素?我是Ruby的新手(从C#迁移过来),不确定“Ruby之道”是什么。 最佳答案 查看Array#combination然后是这样的:2.upto(4){|n|array.combination(n)} 关于ruby-使用Ruby在数组中查找大小为N的所有子集,我们在StackOverflow上找到一个类似的问题: https://stackoverf