好家伙,本篇为《JS高级程序设计》第二十六章“模块”学习笔记
JS开发会遇到代码量大和广泛使用第三方库的问题。
解决这个问题的方案通 常需要把代码拆分成很多部分,然后再通过某种方式将它们连接起来。
若代码量较大,我们使用模块化开发的模式,也能够使代码容易维护
我们需要模块
把逻辑分块,各自封装,相互独立,每个块自行决定对外暴露什么,同时自行决定引入执行哪 些外部代码。
这就是模块模式的思想
注意了,这不是某个包或者某个方法,而是某种规范
CommonJS 规范概述了同步声明依赖的模块定义。
//moduleA.js
module.exports = 'foo'
//moduleB.js
var moduleA = require('./moduleA');
console.log(moduleA);
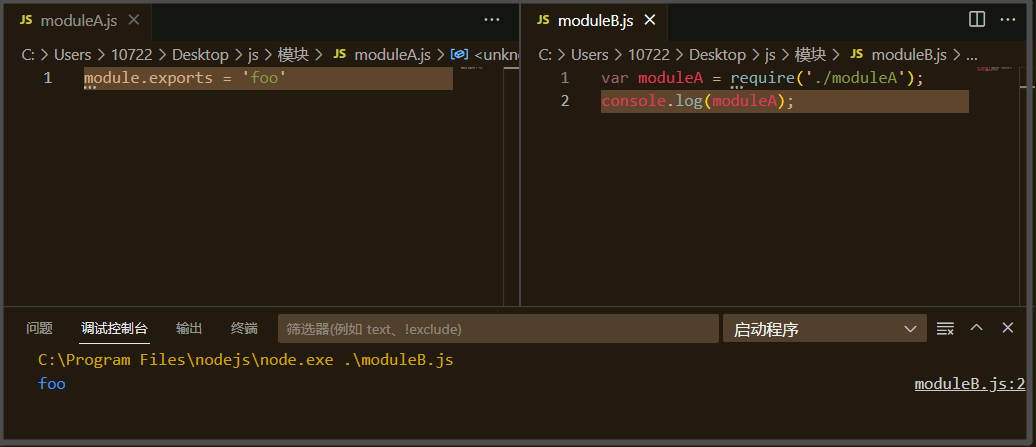
CommonJS 依赖几个全局属性如 require 和 module.exports。
如果想在浏览器中使用 CommonJS 模块,就需要与其非原生的模块语法之间构筑“桥梁”。
模块级代码与浏览器运行时之间也需要某种“屏 障”,因为没有封装的 CommonJS 代码在浏览器中执行会创建全局变量。
全局变量出现了,那么就违背了模块模式的"各自封装,相互独立"
CommonJS 以服务器端为目标环境,能够一次性把所有模块都加载到内存,
而异步模块定义的模块定义系统则以浏览器为目标执行环境,这需要考虑网络延迟的 问题。
AMD 的一般策略是让模块声明自己的依赖,而运行在浏览器中的模块系统会按需获取依赖,并 在依赖加载完成后立即执行依赖它们的模块。
AMD 模块实现的核心是用函数包装模块定义。这样可以防止声明全局变量,并允许加载器库控制 何时加载模块。
// ID 为'moduleA'的模块定义。moduleA 依赖 moduleB,
// moduleB 会异步加载
define('moduleA', ['moduleB'], function(moduleB) {
return {
stuff: moduleB.doStuff();
};
});
CommonJS模块和AMD模块之间的冲突主要是在模块加载方面。
CommonJS模块是同步加载的,而AMD模块是异步加载的,这使得CommonJS模块和AMD模块无法很好地运行在一起。
此外,CommonJS模块和AMD模块的模块定义语法也不同,这也会对它们之间的冲突产生影响。
ES6 模块系统是集 AMD 和 CommonJS 之大成者。
tips:扩展名为 .mjs 的文件是 JavaScript 源代码文件,在 Node.js 应用程序中用作 ECMA 模块(ECMAScript 模块)。
Node.js 的 natvie 模块系统是 CommonJS,用于将代码拆分到不同的文件中,以保持 JS 代码的组织性。
MJS 是 Node.js 用来识别模块是 CommonJS 还是 ES6 的唯一方法。
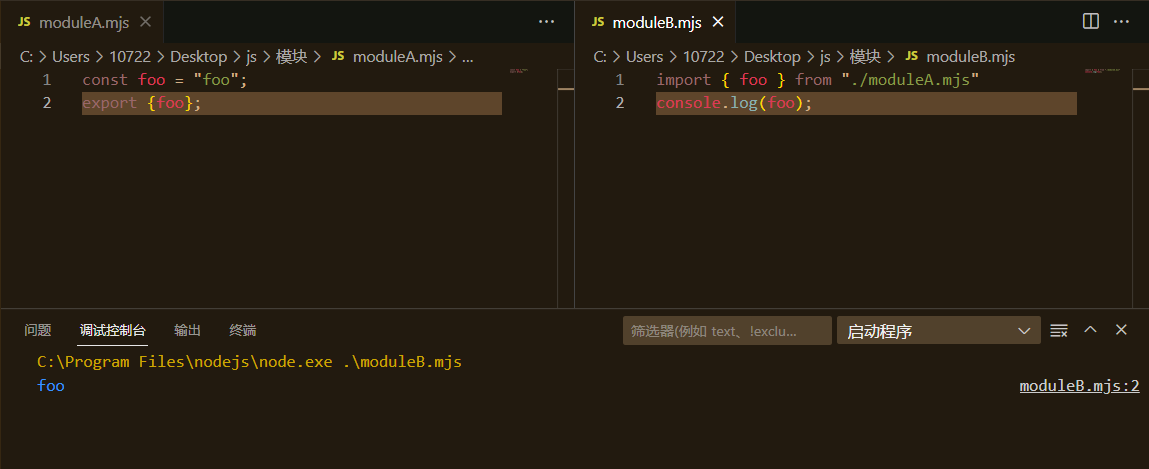
外部文件引入示例:
//moduleA.mjs
const foo = "foo";
export {foo};
//moduleB.mjs
import { foo } from "./moduleA.mjs"
console.log(foo);
<script type="module" src="moduleA.js"></script>
与commonJS规范和AMD规范相比,ES6模块有什么优点?
答: 1.更安全,因为ES6模块有自己独立的作用域,避免了变量污染。
2.更容易维护,因为模块可以明确的规定输入和输出,便于模块的重用和维护。
3.更简洁,ES6模块的语法更加简洁易懂,模块的加载更加高效。
2.与ES6模块相比,commonJS规范和AMD规范有什么缺点?
答: CommonJS规范的缺点是它只能在服务器端运行,而不能在浏览器端运行。
AMD规范的缺点是它增加了很多的书写工作,而且不能很好的处理循环依赖,代码复杂
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub