 毫不迟疑,GPT-3给出了音乐会的答案。再来加点难度,再给GPT-3酱紫的一张照片,让它来分辨照片中的帘子是什么类型的材质。
毫不迟疑,GPT-3给出了音乐会的答案。再来加点难度,再给GPT-3酱紫的一张照片,让它来分辨照片中的帘子是什么类型的材质。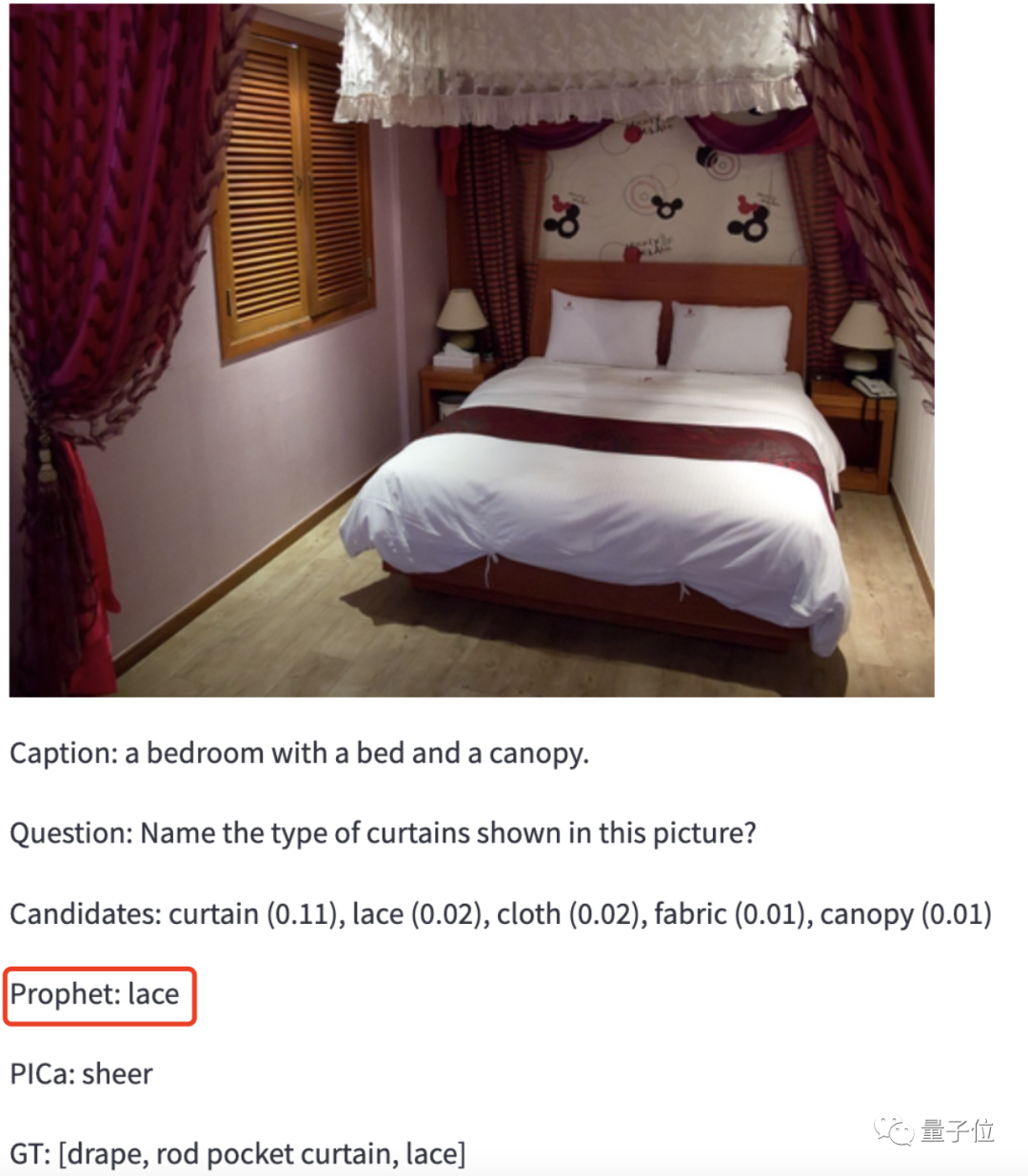 GPT-3:蕾丝。Bingo!(看来是有点儿东西在身上的)这个方法呢,是杭州电子科技大学和合肥工业大学的一个团队的最新成果:Prophet,半年前他们就已经着手进行这项工作。论文一作是杭电研究生邵镇炜,他在1岁那年被诊断患有“进行性脊肌萎缩症”,高考时遗憾与浙大擦肩,选择了离家近的杭州电子科技大学。目前该论文已经被CVPR2023接收。
GPT-3:蕾丝。Bingo!(看来是有点儿东西在身上的)这个方法呢,是杭州电子科技大学和合肥工业大学的一个团队的最新成果:Prophet,半年前他们就已经着手进行这项工作。论文一作是杭电研究生邵镇炜,他在1岁那年被诊断患有“进行性脊肌萎缩症”,高考时遗憾与浙大擦肩,选择了离家近的杭州电子科技大学。目前该论文已经被CVPR2023接收。
 更具体点,在OK-VQA数据集上,和Deepmind的拥有80B参数的大模型Flamingo对比,Prophet达到了61.1%的准确率,成功击败Flamingo(57.8%)。并且在所需要的算力资源上,Prophet也是“吊打”Flamingo。Flamingo-80B需要在1536块TPUv4显卡上训练15天,而Prophet只需要一块RTX-3090显卡训练VQA模型4天,再调用一定次数的OpenAI API即可。
更具体点,在OK-VQA数据集上,和Deepmind的拥有80B参数的大模型Flamingo对比,Prophet达到了61.1%的准确率,成功击败Flamingo(57.8%)。并且在所需要的算力资源上,Prophet也是“吊打”Flamingo。Flamingo-80B需要在1536块TPUv4显卡上训练15天,而Prophet只需要一块RTX-3090显卡训练VQA模型4天,再调用一定次数的OpenAI API即可。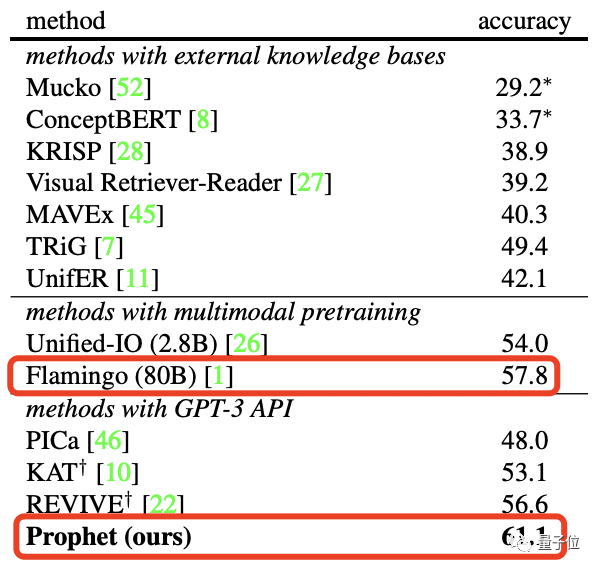 其实,类似Prophet这种帮助GPT-3处理跨模态任务的方法之前也有,比如说PICa,以及之后的KAT和REVIVE。不过它们在一些细节问题的处理中,可能就不尽如人意。举个栗子,让它们一起读下面这张图,然后回答问题:图片中的树会结什么水果?
其实,类似Prophet这种帮助GPT-3处理跨模态任务的方法之前也有,比如说PICa,以及之后的KAT和REVIVE。不过它们在一些细节问题的处理中,可能就不尽如人意。举个栗子,让它们一起读下面这张图,然后回答问题:图片中的树会结什么水果? 而PICa、KAT和REVIVE从图片中提取到的信息只有:一群人在广场上走路,完全忽略掉了后面还有一颗椰子树。最终给出的答案也只能靠瞎猜。而Prophet这边,就不会出现这种情况,它解决了上述方法提取图片信息不充分的问题,进一步激发了GPT-3的潜能。
而PICa、KAT和REVIVE从图片中提取到的信息只有:一群人在广场上走路,完全忽略掉了后面还有一颗椰子树。最终给出的答案也只能靠瞎猜。而Prophet这边,就不会出现这种情况,它解决了上述方法提取图片信息不充分的问题,进一步激发了GPT-3的潜能。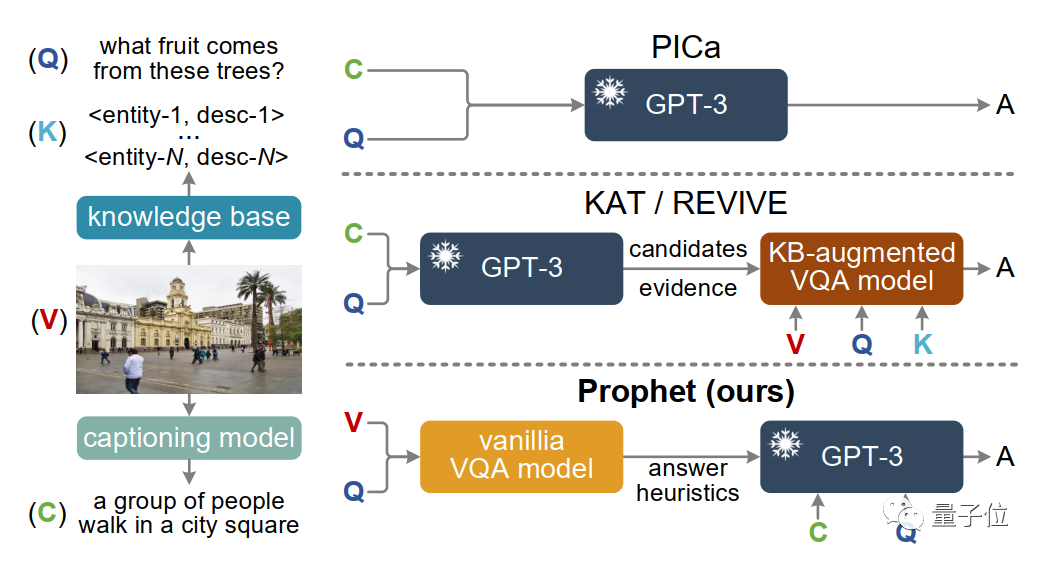 那Prophet是怎么做的呢?
那Prophet是怎么做的呢?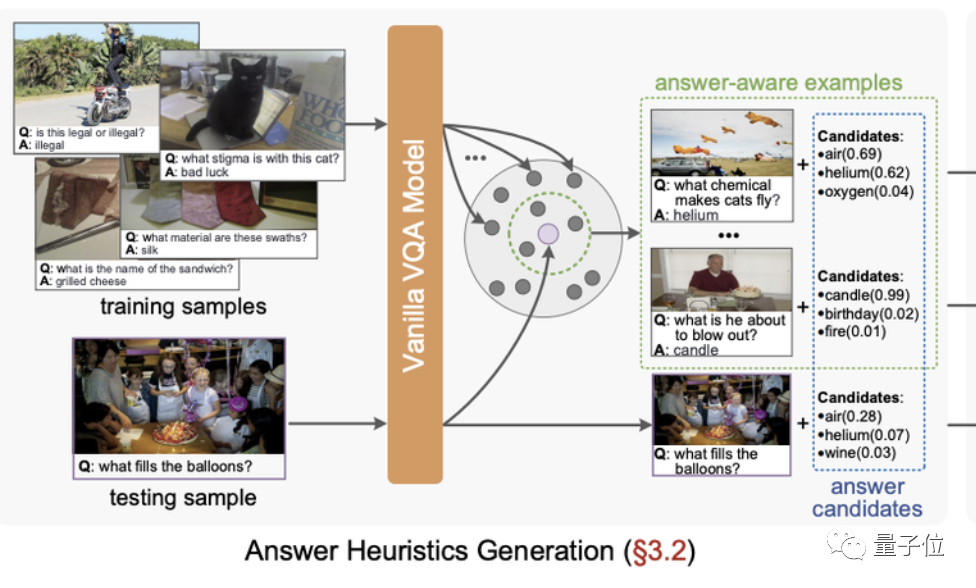 接下来就是第二阶段,这一步相对来说就很简单粗暴了。讲上一步得到的“启发性答案”组织到prompt中,然后再将prompt输入给GPT-3,在一定的提示之下完成视觉问答问题。不过虽然上一步已经给出一些答案提示,但这并不意味着GPT-3就要局限在这些答案中。若提示给出的答案置信度太低或者正确答案并不在那些提示中,GPT-3完全完全有可能生成新的答案。
接下来就是第二阶段,这一步相对来说就很简单粗暴了。讲上一步得到的“启发性答案”组织到prompt中,然后再将prompt输入给GPT-3,在一定的提示之下完成视觉问答问题。不过虽然上一步已经给出一些答案提示,但这并不意味着GPT-3就要局限在这些答案中。若提示给出的答案置信度太低或者正确答案并不在那些提示中,GPT-3完全完全有可能生成新的答案。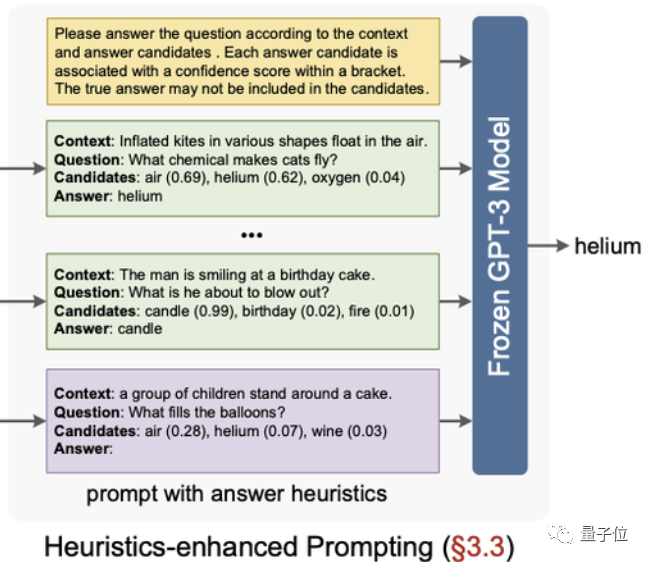
 不过虽然身体受限,但邵镇炜对知识的渴求并没有减弱。2017年高考他拿下644分的高分,以第一名的成绩被杭州电子科技大学计算机专业录取。期间还获得2018年中国大学生自强之星、2020年度国家奖学金和2021年度浙江省优秀毕业生等荣誉。本科期间,邵镇炜就已经开始跟着余宙教授进行科研活动。2021年,邵镇炜在准备研究生推免时与浙大擦肩,于是留校加入了余宙教授课题组攻读硕士研究生,目前他在读研二,研究方向是跨模态学习。余宙教授则是本次研究论文的二作以及通讯作者,他是杭电计算机学院最年轻的教授,教育部“复杂系统建模与仿真”实验室副主任。长期以来,余宙专攻多模态智能方向,曾带领研究团队多次获得国际视觉问答挑战赛VQA Challenge的冠亚军。
不过虽然身体受限,但邵镇炜对知识的渴求并没有减弱。2017年高考他拿下644分的高分,以第一名的成绩被杭州电子科技大学计算机专业录取。期间还获得2018年中国大学生自强之星、2020年度国家奖学金和2021年度浙江省优秀毕业生等荣誉。本科期间,邵镇炜就已经开始跟着余宙教授进行科研活动。2021年,邵镇炜在准备研究生推免时与浙大擦肩,于是留校加入了余宙教授课题组攻读硕士研究生,目前他在读研二,研究方向是跨模态学习。余宙教授则是本次研究论文的二作以及通讯作者,他是杭电计算机学院最年轻的教授,教育部“复杂系统建模与仿真”实验室副主任。长期以来,余宙专攻多模态智能方向,曾带领研究团队多次获得国际视觉问答挑战赛VQA Challenge的冠亚军。 研究团队的大部分成员都在杭电媒体智能实验室(MIL)。该实验室由国家杰青俞俊教授负责,近年来实验室围绕多模态学习方向发表一系列高水平期刊会议论文(TPAMI、IJCV、CVPR等),多次获得IEEE期刊会议的最佳论文奖。实验室主持国家重点研发计划、国家自然科学基金重点项目等国家级项目20余项,曾获得过浙江省自然科学一等奖,教育自然科学二等奖。
研究团队的大部分成员都在杭电媒体智能实验室(MIL)。该实验室由国家杰青俞俊教授负责,近年来实验室围绕多模态学习方向发表一系列高水平期刊会议论文(TPAMI、IJCV、CVPR等),多次获得IEEE期刊会议的最佳论文奖。实验室主持国家重点研发计划、国家自然科学基金重点项目等国家级项目20余项,曾获得过浙江省自然科学一等奖,教育自然科学二等奖。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o