参考文章:https://blog.csdn.net/qq_34827674/article/details/107678226
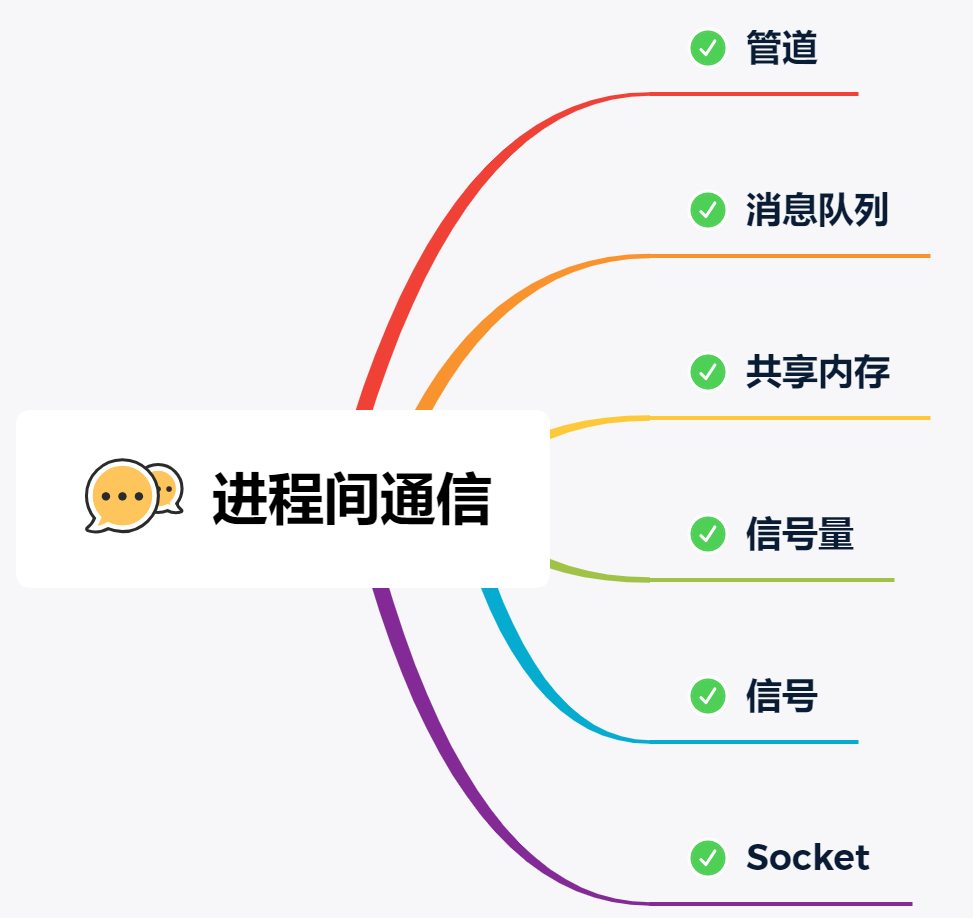
前提知识:每个进程都有自己的用户空间,而内核空间是每个进程共享的。因此进程之间想要进行通信,就需要通过内核来实现。
管道:
管道是最简单,效率最差的一种通信方式。
管道本质上就是内核中的一个缓存,当进程创建一个管道后,Linux会返回两个文件描述符,一个是写入端的描述符,一个是输出端的描述符,可以通过这两个描述符往管道写入或者读取数据。
如果想要实现两个进程通过管道来通信,则需要让创建管道的进程fork子进程,这样子进程们就拥有了父进程的文件描述符,这样子进程之间也就有了对同一管道的操作。
缺点:
消息队列:
管道的通信方式效率是低下的,不适合进程间频繁的交换数据。这个问题,消息队列的通信方式就可以解决。A进程往消息队列写入数据后就可以正常返回,B进程需要时再去读取就可以了,效率比较高。
而且,数据会被分为一个一个的数据单元,称为消息体,消息发送方和接收方约定好消息体的数据类型,不像管道是无格式的字节流类型,这样的好处是可以边发送边接收,而不需要等待完整的数据。
但是也有缺点,每个消息体有一个最大长度的限制,并且队列所包含消息体的总长度也是有上限的,这是其中一个不足之处。
另一个缺点是消息队列通信过程中存在用户态和内核态之间的数据拷贝问题。进程往消息队列写入数据时,会发送用户态拷贝数据到内核态的过程,同理读取数据时会发生从内核态到用户态拷贝数据的过程。
共享内存:
共享内存解决了消息队列存在的内核态和用户态之间数据拷贝的问题。
现代操作系统对于内存管理采用的是虚拟内存技术,也就是说每个进程都有自己的虚拟内存空间,虚拟内存映射到真实的物理内存。共享内存的机制就是,不同的进程拿出一块虚拟内存空间,映射到相同的物理内存空间。这样一个进程写入的东西,另一个进程马上就能够看到,不需要进行拷贝。
(这里的物理内存貌似不是内核空间的内存?)
信号量:
当使用共享内存的通信方式,如果有多个进程同时往共享内存写入数据,有可能先写的进程的内容被其他进程覆盖了。
因此需要一种保护机制,信号量本质上是一个整型的计数器,用于实现进程间的互斥和同步。
信号量代表着资源的数量,操作信号量的方式有两种:
(1)信号量实现互斥:
信号量初始化为1
(2)信号量实现同步:
由于多线程下各线程的执行顺序是无法预料的,有些时候我们希望多个线程之间能够密切合作,这时候就需要考虑线程的同步问题。
信号量初始化为0
信号:
在Linux中,为了响应各种事件,提供了几十种信号,可以通过kill -l命令查看。
如果是运行在shell终端的进程,可以通过键盘组合键来给进程发送信号,例如使用Ctrl+C产生SIGINT信号,表示终止进程。
如果是运行在后台的进程,可以通过命令来给进程发送信号,例如使用kill -9 PID产生SIGKILL信号,表示立即结束进程。
Socket:
前面提到的管道,消息队列,共享内存,信号量和信号都是在同一台主机上进行进程间通信,如果想要跨网络和不同主机上的进程进行通信,则需要用到socket。
实际上,Socket不仅可以跨网络和不同主机进行进程间通信,还可以在同一主机进行进程间通信。
Socket是操作系统提供给程序员操作网络的接口,根据底层不同的实现方式,通信方式也不同。
Socket的系统调用:
int socket(int domain, int type, int protocal)
针对TCP的Socket通信:
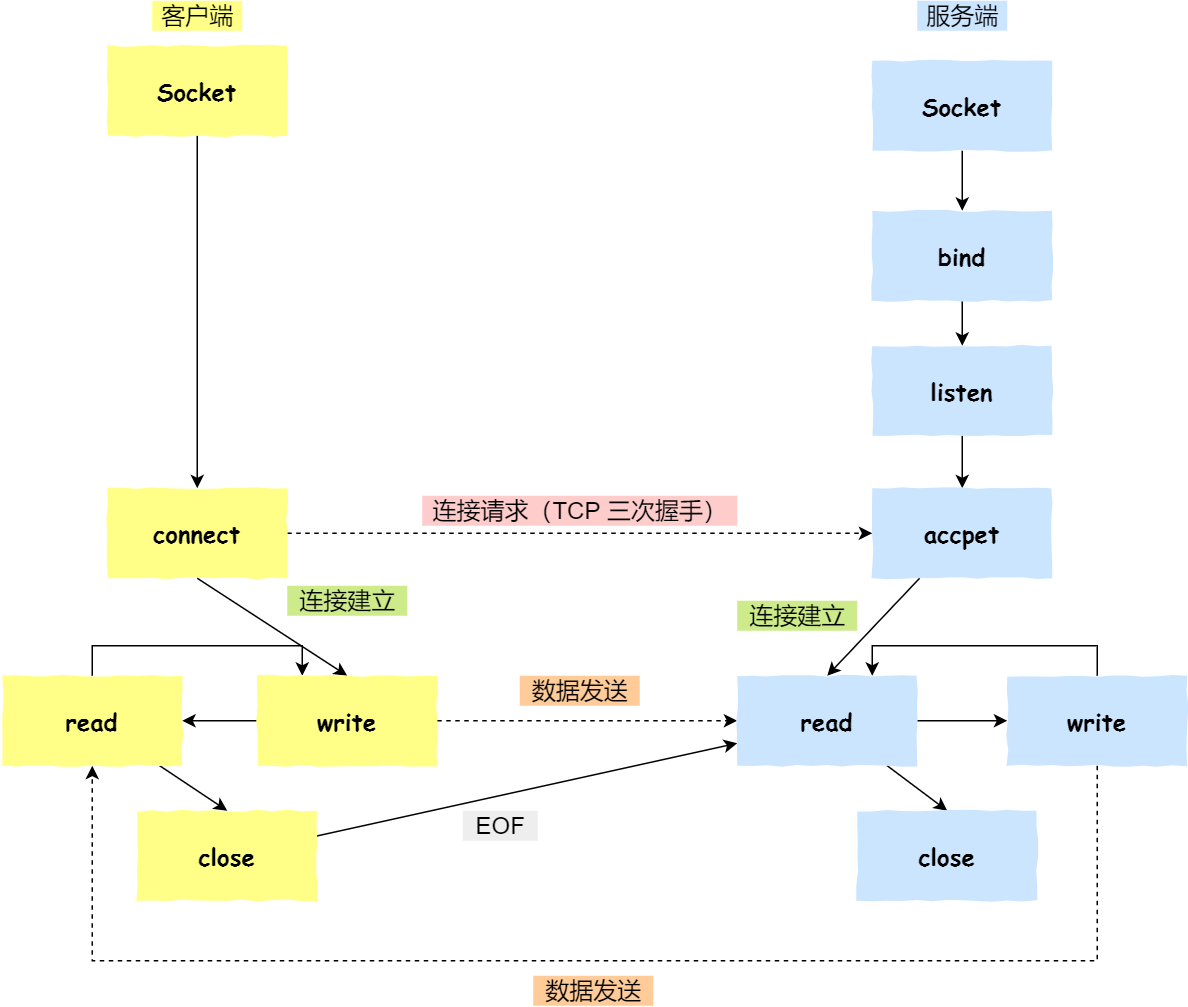
这里要注意的是,调用accept,连接成功得到的Socket是用来传输数据的,而第一次初始化Socket是用来监听的,是两个不同作用的Socket。
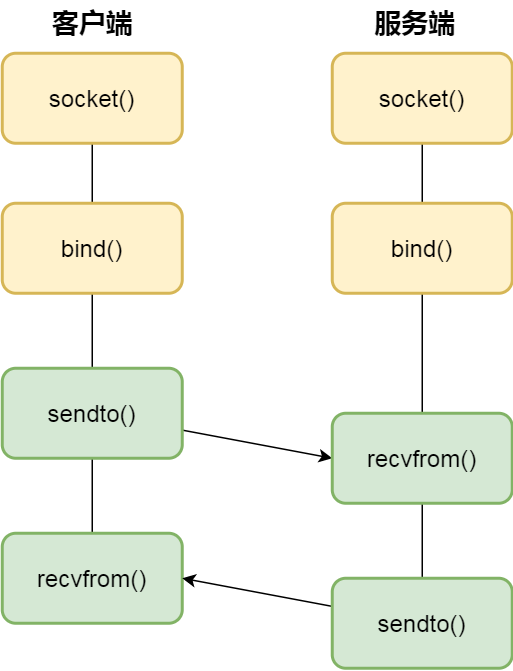
针对UDP的Socket通信:
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
这是针对我无法破坏的现有公共(public)API,但我确实希望对其进行扩展。目前,该方法采用字符串或符号或任何其他在作为第一个参数传递给send时有意义的内容我想添加发送字符串、符号等列表的功能。我可以只使用is_a吗?数组,但还有其他发送列表的方法,这不是很像ruby。我将调用列表中的map,所以第一个倾向是使用respond_to?:map。但是字符串也会响应:map,所以这行不通。 最佳答案 如何将它们全部视为数组?String的行为与仅包含String的Array相同:deffoo(obj,arg)[*arg].eac