机器列表
node1 172.29.12.237 es+kibana node2 172.29.12.233 es node3 172.29.12.242 es
PS: ES8 自带 jdk ,所以不用配置
cat >> /etc/security/limits.conf <<EOF * soft nofile 65536 * hard nofile 65536 * soft nproc 65536 * hard nproc 65536 EOF echo "vm.max_map_count = 655360" >>/etc/sysctl.conf sysctl -p
新建普通用户
useradd es passwd es
以上操作,三个节点服务器都要进行
/data/es8/data和/data/es8/log(三个节点都要进行)
mkdir -p /data/es8/data mkdir -p /data/es8/log
上传软件包到服务器的/data/es8目录下 node1上传elasticsearch-8.2.3-linux-x86_64.tar.gz和kibana-8.2.3-linux-x86_64.tar.gz node2上传elasticsearch-8.2.3-linux-x86_64.tar.gz node3上传elasticsearch-8.2.3-linux-x86_64.tar.gz
3.2.1 解压文件
elasticsearch-8.2.3-linux-x86_64.tar.gz
cd /data/es8 tar -xvf elasticsearch-8.2.3-linux-x86_64.tar.gz
3.2.2 修改elasticsearch配置文件
cd /data/es8/elasticsearch-8.2.3/conf 导入配置到elasticsearch.yml配置文件,IP根据自己本机IP进行修改(这个位置必须为内网IP,不可设置为127.0.0.1) cat >> elasticsearch.yml <<EOF cluster.name: es8 node.name: node1 path.data: /data/es8/data path.logs: /data/es8/log/ network.host: 172.29.12.237 http.port: 9200 ingest.geoip.downloader.enabled: false EOF
3.2.3 设置权限
chown es.es /data/es8 -R
3.2.4 启动es
需要切换到es用户下进行启动
PS:第一次不建议使用 -d(代表后台启动),因为如果没搞过会错过下面的信息
su es cd /data/es8/elasticsearch-8.2.3 ./bin/elasticsearch
3.2.5 初次启动成功,会输出的下面的信息:

第3-4行:用户密码 生成用户:elastic 密码:cFjOf0i9k1XdjzyFfOQX 重置使用:bin/elasticsearch-reset-password -u elastic
第7-10行:如何让Kibana加入集群
运行Kibana并在Kibana启动时单击终端中的配置链接 复制注册令牌并将其粘贴到浏览器中的Kibana中(在接下来的30分钟内有效)
如果token失效:
./elasticsearch-create-enrollment-token -s kibana -- url "https://172.29.12.237:9200" 第13-15行:如何加入让新的node节点加入集群
新节点加入集群
bin/elasticsearch --enrollment-token <token-ID>
docker的话:
docker run -e "ENROLLMENT_TOKEN=<token-ID>" docker.elastic.co/elasticsearch/elasticsearch:8.0.1
如果token过期
[es@node1 bin]$ ./elasticsearch-create-enrollment-token -s node
3.2.6 验证
浏览器输入https://172.29.12.237:9200/ 账号密码就是3.2.5中的

注:这时候先不要停止node的es服务,需要等到集群加入完毕,kibana部署完成后,在使用-d重新在后台启动
3.3.1 配置系统文件(root)
参考配置2.1
3.3.2 配置普通用户(root)
参考配置2.2
3.3.3 配置es
解压elasticsearch-8.2.3-linux-x86_64.tar.gz
cd /data/es8 tar -xvf elasticsearch-8.2.3-linux-x86_64.tar.gz
导入配置到elasticsearch.yml配置文件,IP根据自己本机IP进行修改(这个位置必须为内网IP,不可设置为127.0.0.1)
cd /data/es8/elasticsearch-8.2.3/conf cat >> elasticsearch.yml <<EOF cluster.name: es8 node.name: node2 path.data: /data/es8/data path.logs: /data/es8/log/ network.host: 172.29.12.233 http.port: 9200 ingest.geoip.downloader.enabled: false EOF
3.3.4 node2加入到集群
su es cd /data/es8/elasticsearch-8.2.3/bin ./elasticsearch --enrollment-token token的值
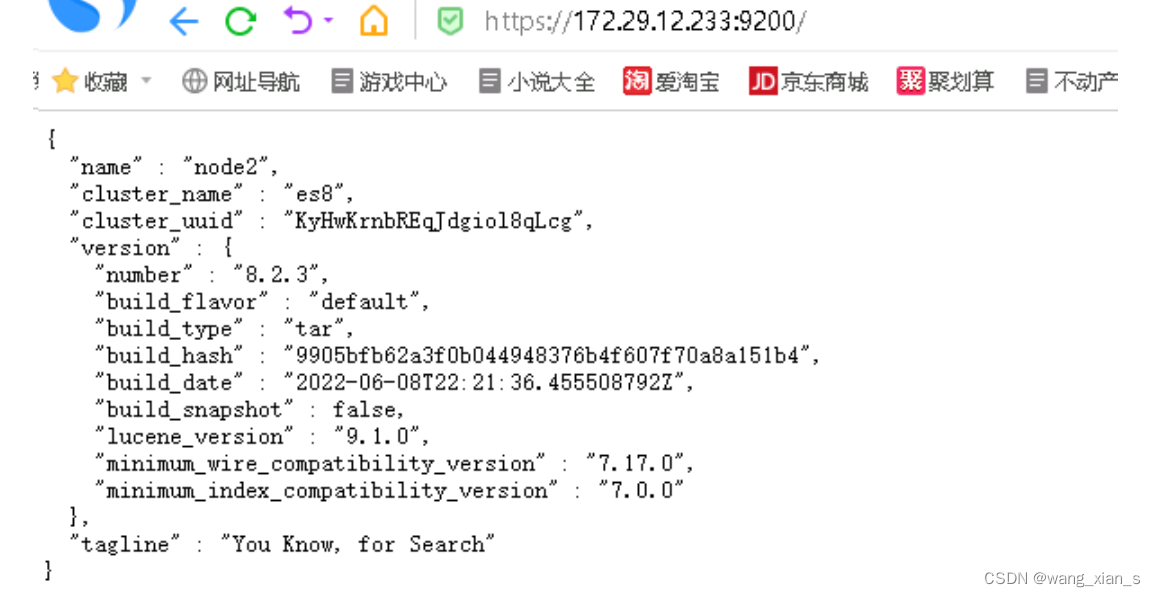
3.3.5 验证
浏览器输入https://172.29.12.233:9200/ 账号密码就是3.2.5中的
3.4.1 配置系统文件(root)
参考配置2.1
3.4.2 配置普通用户(root)
参考配置2.2
3.4.3 配置es
解压elasticsearch-8.2.3-linux-x86_64.tar.gz
cd /data/es8 tar -xvf elasticsearch-8.2.3-linux-x86_64.tar.gz
导入配置到elasticsearch.yml配置文件,IP根据自己本机IP进行修改(这个位置必须为内网IP,不可设置为127.0.0.1)
cd /data/es8/elasticsearch-8.2.3/conf cat >> elasticsearch.yml <<EOF cluster.name: es8 node.name: node3 path.data: /data/es8/data path.logs: /data/es8/log/ network.host: 172.29.12.242 http.port: 9200 ingest.geoip.downloader.enabled: false EOF
3.4.4 node3加入到集群
su es cd /data/es8/elasticsearch-8.2.3/bin ./elasticsearch --enrollment-token token的值
3.4.5 验证
浏览器输入https://172.29.12.233:9200/ 账号密码就是3.2.5中的
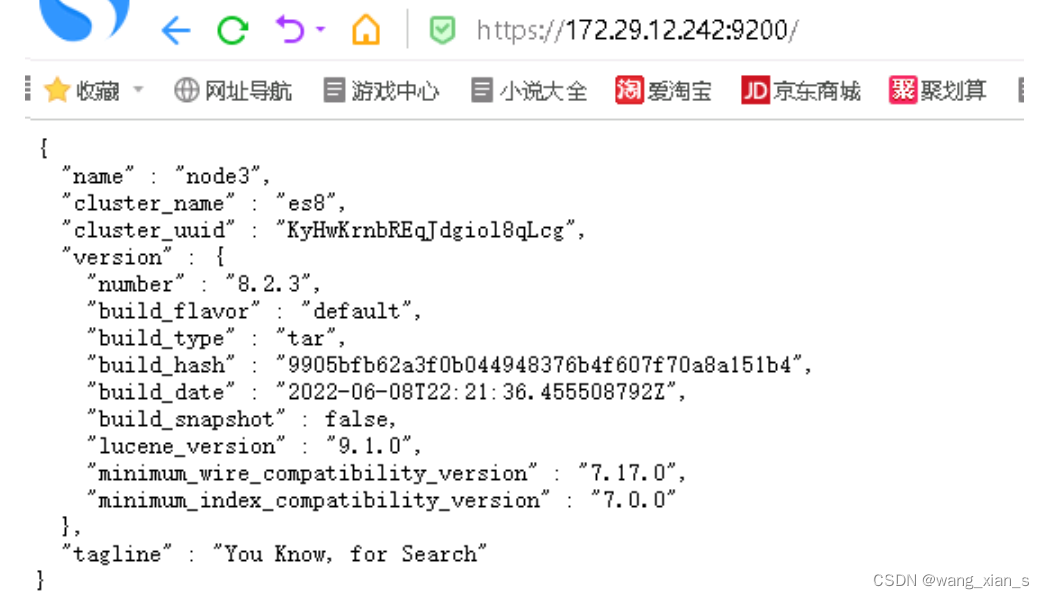
到这ES集群初步完成
kibana-8.2.3-linux-x86_64.tar.gz
cd /data/es8 tar -xvf kibana-8.2.3-linux-x86_64.tar.gz
cd /data/es8/kibana-8.2.3 最后面加入以下内容 cat >> config/kibana.yml <<EOF server.host: "0.0.0.0" i18n.locale: zh-CN EOF
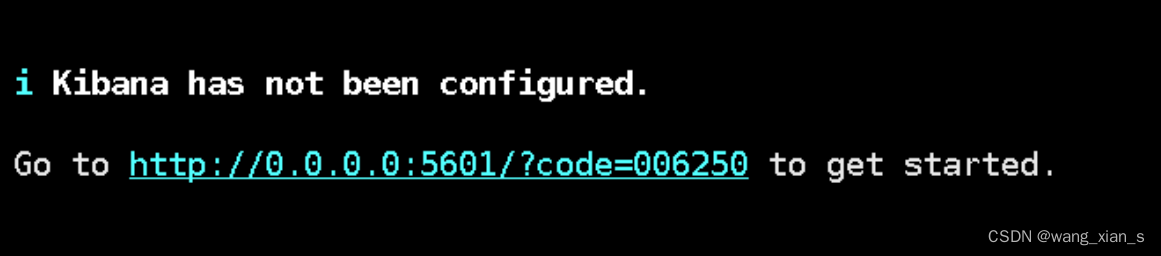
./bin/kibana
出现一下界面
填写在3.2.5中生成的kibana的token
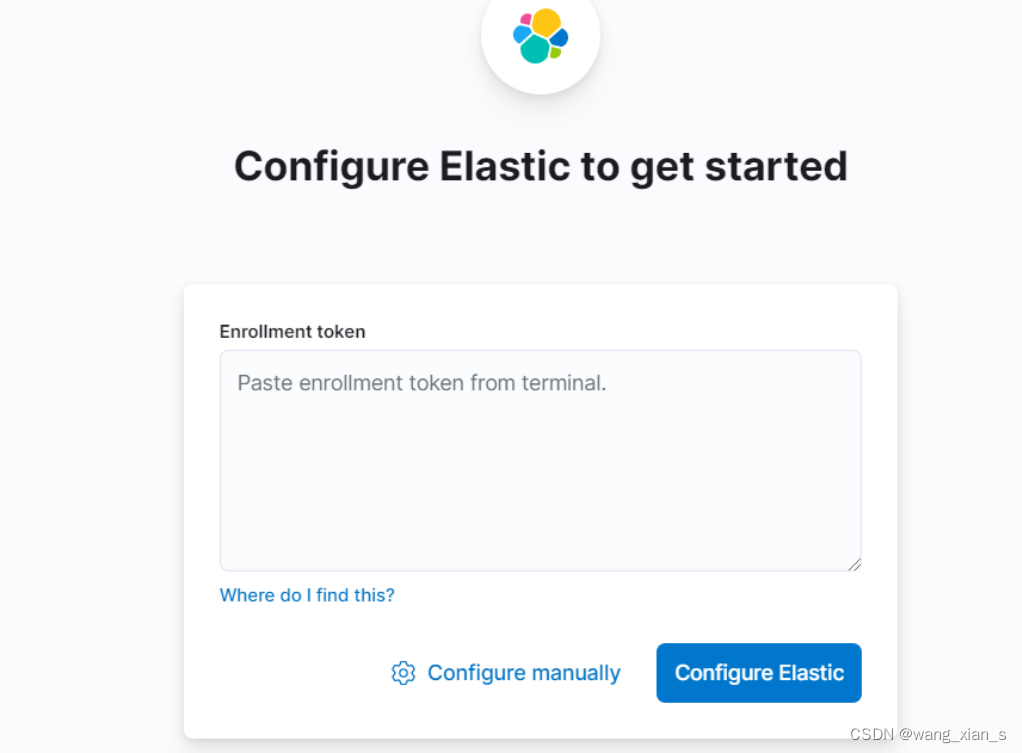
这个totken只有30分钟,如果过期可以使用一下命令生成新的token
./elasticsearch-create-enrollment-token -s kibana -- url "https://172.29.12.237:9200"
根据提示新开一个xshell窗口,进如到kibana目录下执行一下命令获取动态码

cd /data/es8/kibana-8.2.3 ./bin/kibana-verification-code

输入获取的动态码
kibana进行配置
配置完成后登录页面
账号密码就是3.2.5中的

我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
如何使用Capistrano将Rails应用程序部署到无法访问外部网络或存储库的生产或暂存服务器?我已经设法完成部署的一半,并意识到Capistrano没有在我的本地机器上下载gitrepo,但它首先连接到远程服务器并尝试在那里下载Git存储库。我希望有一个类似Javaee的构建系统,其中创建可交付成果并将该可交付成果发送到服务器。就像您构建.ear文件并将其部署到您想要的任何服务器上一样。显然在RoR中,你被迫(据我所知)在该服务器上构建应用程序,在那里创建一个gem存储库,在那里克隆最新的分支等等。有什么方法可以将准备运行的包发送到远程服务器吗? 最佳答