二分查找实际上就是采用了分治法的思想
以下模板都以升序数组为准
场景:数组元素有序且不重复
有的话返回索引,没有返回-1
int binarySearch(vector<int>& arr, int target) {
int left = 0, right = nums.size() - 1;
while (left <= right) {//<=指可以取到右区间,是[left,right]
int mid = left + ((right - left) >> 1);
if (nums[mid] == target) return mid;
else if (nums[mid] > target) right = mid - 1;//证明target可能在mid左侧
else left = mid + 1;//证明nums[mid] < target, target可能在mid右侧
}
return -1;
}
二分查找左/有边界是二分查找的变式,一般有如下场景:
1)第一种情况
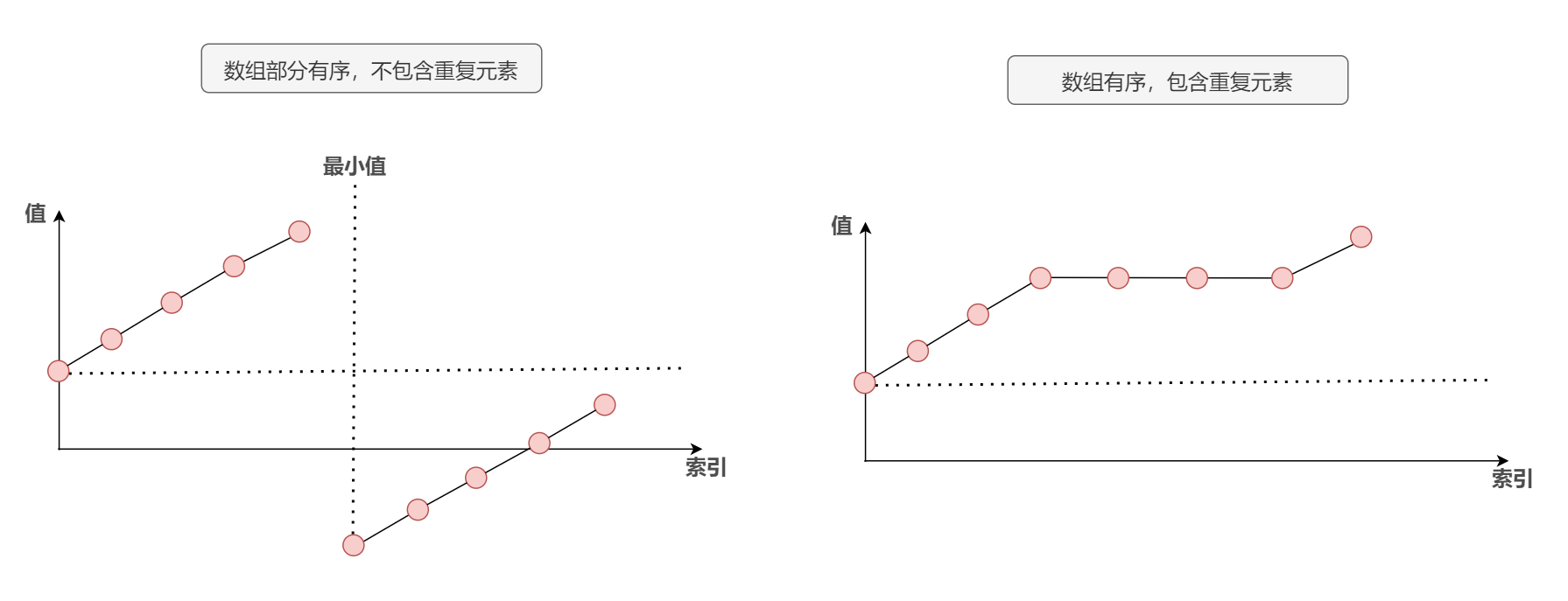
2)第二种情况
1)针对第一种情况:
int binarySearch(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (left < right) {//这是左闭右开[,),不包含最后一个数,left = right 的时候会跳出
int mid = left + ((right - left) >> 1);
if (nums[mid] < targrt) left = mid + 1;
else right = mid;//nums[mid] >= target, 都需要往左边收缩边界(主要)
}
//因为里面是没有判断left = right 这个索引的位置,需要打个补丁
return nums[left] == target ? left : -1;
}
2)针对第二种情况(模板有误)
1)针对第一种情况
int binarySearch(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
int mid;
while (left < right) {
mid = left + ((right - left) >> 1) + 1;//需要注意,这里多加了个1,这样无论是奇偶数,中间位置都偏右,这样避免了死循环(如果不加1,比如{2,2},target为2,就会死循环)
if (nums[mid] > target) right = mid - 1;//收缩右边界
else left = mid;//numd[mid] <= target,都需要收缩左边界(主要)
}
//打个补丁,这里写左右都可以
return nums[left] == target ? left : -1;
}
2)针对第二种情况
分别查找左右边界即可
1)第一种情况
vector<int> searchRange(vector<int>& nums, int target) {
vector<int> res{-1,-1};//res[0]存左边界,res[1]存右边界
int left = 0, right = nums.size() - 1;
int mid;
while (left < right) {//先找左边边界
mid = left + ((right - left) >> 1);
if (nums[mid] < target) left = mid + 1;
else right = mid;
}
res[0] = nums[left] == target ? left : -1;
if (res[0] != -1) {//存在左边边界查找右边边界
if (left == nums.size() - 1 || nums[left + 1] != target) {//可能只有一个target,它的位置可能在末尾/其他位置
res[1] = left;
}
else {//有多个target
right = nums.size() - 1;
while (left < right) {
mid = left + ((right - left) >> 1) + 1;
if (nums[mid] > target) right = mid - 1;
else left = mid;
}
res[1] = nums[left] == target ? left : -1;
}
}
return res;
}
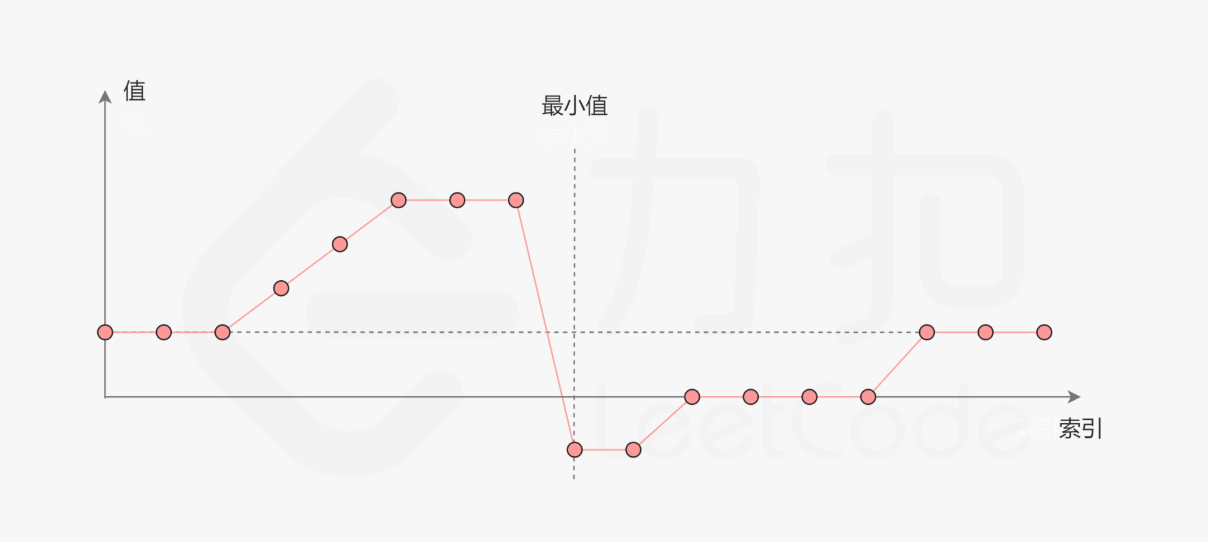
二分查找的一种变式:找极值,即是v或者^的最值点;
我们查找的时候不再是和target进行比较,而是和相邻元素比较,以达到某种单调区间检测的效果
下面以查找^的极值点写一个模板:
int binarySearch(vector<int>& nums) {
int left = 0, right = nums.size() - 1;
int mid;
while (left <= right) {
mid = left + ((right - left) >> 1);
if (nums[mid] > nums[mid] + 1 && nums[mid] > nums[mid - 1]) return mid;
else if (nums[mid] > nums[mid + 1]) right = mid - 1;//极值点在左边
else left = mid + 1;//极值点在右边
}
return -1;
}
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
我想找到给定字符串中的所有匹配项,包括重叠匹配项。我怎样才能实现它?#Example"a-b-c-d".???(/\w-\w/)#=>["a-b","b-c","c-d"]expected#Solutionwithoutoverlappedresults"a-b-c-d".scan(/\w-\w/)#=>["a-b","c-d"],but"b-c"ismissing 最佳答案 在积极的前瞻中使用捕获:"a-b-c-d".scan(/(?=(\w-\w))/).flatten#=>["a-b","b-c","c-d"]参见Rubyde
这应该是一个简单的问题,但我找不到任何相关信息。给定一个Ruby中的正则表达式,对于每个匹配项,我需要检索匹配的模式$1、$2,但我还需要匹配位置。我知道=~运算符为我提供了第一个匹配项的位置,而string.scan(/regex/)为我提供了所有匹配模式。如果可能,我需要在同一步骤中获得两个结果。 最佳答案 MatchDatastring.scan(regex)do$1#Patternatfirstposition$2#Patternatsecondposition$~.offset(1)#Startingandendingpo
我有以下数组:arr=[1,3,2,5,2,4,2,2,4,4,2,2,4,2,1,5]我想要一个包含前三个奇数元素的数组。我知道我可以做到:arr.select(&:odd?).take(3)但我想避免遍历整个数组,而是在找到第三个匹配项后返回。我想出了以下解决方案,我相信它可以满足我的要求:my_arr.each_with_object([])do|el,memo|memo但是有没有更简单/惯用的方法来做到这一点? 最佳答案 使用lazyenumerator与Enumerable#lazy:arr.lazy.select(&:o
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
是否有内置的Ruby方法或众所周知的库可以返回对象的整个方法查找链?Ruby查看一系列令人困惑的类(如thisquestion中所讨论)以查找与消息对应的实例方法,如果没有类响应消息,则调用接收方的method_missing。我将以下代码放在一起,但我确信它遗漏了某些情况或者它是否100%正确。请指出任何缺陷并指导我找到一些更好的代码(如果存在)。defmethod_lookup_chain(obj,result=[obj.singleton_class])ifobj.instance_of?Classreturnadd_modules(result)ifresult.last==B
我有以下数组:A=[1,2,3,4,5]B=[2,6,7,1]我想找到不相交的元素,如下:output=[3,4,5,6,7]我是这样实现的,output=A+B-(A&B)但它效率低下,因为我添加了两个数组,然后删除了公共(public)元素。它类似于查找不相交的元素。我能做得比这更好吗?如果是,怎么办? 最佳答案 如何只选择A中的元素而不是B中的元素以及B中的元素而不是A中的元素。(A-B)+(B-A) 关于arrays-在两个数组中查找不相交元素的有效方法是什么?,我们在Stack
给定一个数组['a','b','c','d','e','f'],我如何获得包含两个的所有子集的列表、三、四元素?我是Ruby的新手(从C#迁移过来),不确定“Ruby之道”是什么。 最佳答案 查看Array#combination然后是这样的:2.upto(4){|n|array.combination(n)} 关于ruby-使用Ruby在数组中查找大小为N的所有子集,我们在StackOverflow上找到一个类似的问题: https://stackoverf