Python通过手肘法实现k_means聚类
import matplotlib.pylab as plt
import numpy as np
# 计算两点距离
def distance(a, b):
return np.sqrt((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2)
# 取集合中心点
def means(arr):
x = 0
y = 0
for i in range(len(arr)):
x += arr[i][0]
y += arr[i][1]
if len(arr) > 0:
x /= len(arr)
y /= len(arr)
return np.array([x, y])
# 寻找距离已加入聚类中心数组最远的点,用于初始化聚类中心
def farthest(k_arr, arr):
point = [0, 0]
max_dist = 0
for e in arr:
dist = 0
for i in range(len(k_arr)):
dist += distance(k_arr[i], e)
if dist > max_dist:
max_dist = dist
point = e
return point
(1)先读取表中的数据
(2)如何随机获取其中一个点作为第一个聚类中心
(3)接下来每次获取距离之间所有聚类中心点最远的点作为下一个聚类中心点
(4)每次迭代时,遍历集合中的所有点,将其加入距离最小的聚类中心点数组中,更新聚类中心
(5)最后将数据可视化,返回分类好的数组
def k_means(k):
# 读取数据
kmeans_data = np.genfromtxt('kmeans_data.txt', dtype=float)
# 初始化
r = np.random.randint(len(kmeans_data) - 1)
k_arr = np.array([kmeans_data[r]])
class_arr = [[]]
for i in range(k - 1):
k_arr = np.concatenate([k_arr, np.array([farthest(k_arr, kmeans_data)])])
class_arr.append([])
# 迭代聚类
n = 20
class_temp = class_arr
for i in range(n): # 迭代次数
class_temp = class_arr
for e in kmeans_data: # 把集合中的每一个点聚到离它最近的类
k_idx = 0 # 假设距离第一个聚类中心最近
min_d = distance(e, k_arr[0])
for j in range(len(k_arr)): # 获取距离该元素最近的聚类中心
if distance(e, k_arr[j]) < min_d:
min_d = distance(e, k_arr[j])
k_idx = j
class_temp[k_idx].append(e) # 把该元素加到对应的类中
# 更新聚类中心
for l in range(len(k_arr)):
k_arr[l] = means(class_temp[l])
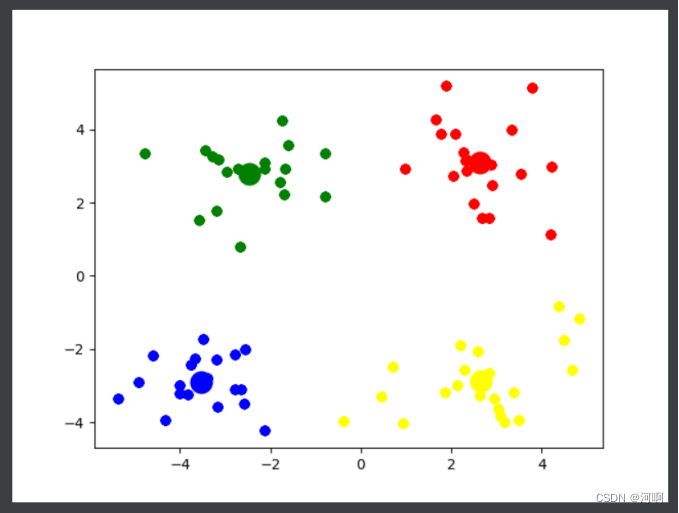
# 将数据可视化
col = ['red', 'blue', 'yellow', 'green', 'pink', 'black', 'purple', 'orange', 'brown']
for i in range(k):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidths=10, color=col[i])
plt.scatter([e[0] for e in class_temp[i]], [e[1] for e in class_temp[i]], color=col[i])
plt.show()
# 返回分类好的簇
return class_temp
(1)遍历k值的范围,从1到9
(2)kmeans获取分类好的数组
(3)遍历kmeans计算对应的SSE
(4)画出对应k值的SSE的折线图
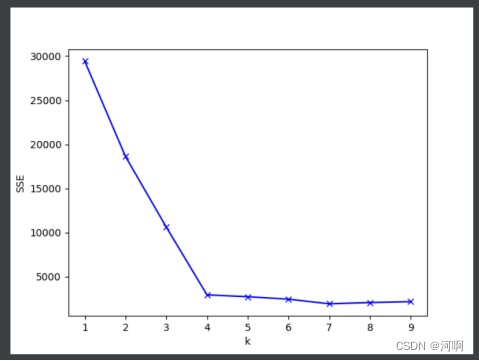
# 通过肘部观察法获取k值
def getK():
mean_dist = []
for k in range(1, 10):
# 获取分成k簇后的元素
kmeans = k_means(k)
sse = 0
# 计算SSE
for i in range(len(kmeans)):
mean = means(kmeans[i])
for e in kmeans[i]:
sse += distance(mean, e) ** 2
mean_dist.append(sse)
# 化成折线图观察最佳的k值
plt.plot(range(1, 10), mean_dist, 'bx-')
plt.ylabel('SSE')
plt.xlabel('k')
plt.show()
if __name__ == '__main__':
getK()
# 通过观察可知, 4 是最佳的k值
k_means(4)
import matplotlib.pylab as plt
import numpy as np
# 计算两点距离
def distance(a, b):
return np.sqrt((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2)
# 取集合中心点
def means(arr):
x = 0
y = 0
for i in range(len(arr)):
x += arr[i][0]
y += arr[i][1]
if len(arr) > 0:
x /= len(arr)
y /= len(arr)
return np.array([x, y])
# 寻找距离已加入聚类中心数组最远的点,用于初始化聚类中心
def farthest(k_arr, arr):
point = [0, 0]
max_dist = 0
for e in arr:
dist = 0
for i in range(len(k_arr)):
dist += distance(k_arr[i], e)
if dist > max_dist:
max_dist = dist
point = e
return point
def k_means(k):
# 读取数据
kmeans_data = np.genfromtxt('kmeans_data.txt', dtype=float)
# 初始化
r = np.random.randint(len(kmeans_data) - 1)
k_arr = np.array([kmeans_data[r]])
class_arr = [[]]
for i in range(k - 1):
k_arr = np.concatenate([k_arr, np.array([farthest(k_arr, kmeans_data)])])
class_arr.append([])
# 迭代聚类
n = 20
class_temp = class_arr
for i in range(n): # 迭代次数
class_temp = class_arr
for e in kmeans_data: # 把集合中的每一个点聚到离它最近的类
k_idx = 0 # 假设距离第一个聚类中心最近
min_d = distance(e, k_arr[0])
for j in range(len(k_arr)): # 获取距离该元素最近的聚类中心
if distance(e, k_arr[j]) < min_d:
min_d = distance(e, k_arr[j])
k_idx = j
class_temp[k_idx].append(e) # 把该元素加到对应的类中
# 更新聚类中心
for l in range(len(k_arr)):
k_arr[l] = means(class_temp[l])
# 将数据可视化
col = ['red', 'blue', 'yellow', 'green', 'pink', 'black', 'purple', 'orange', 'brown']
for i in range(k):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidths=10, color=col[i])
plt.scatter([e[0] for e in class_temp[i]], [e[1] for e in class_temp[i]], color=col[i])
plt.show()
# 返回分类好的簇
return class_temp
# 通过肘部观察法获取k值
def getK():
mean_dist = []
for k in range(1, 10):
# 获取分成k簇后的元素
kmeans = k_means(k)
sse = 0
# 计算SSE
for i in range(len(kmeans)):
mean = means(kmeans[i])
for e in kmeans[i]:
sse += distance(mean, e) ** 2
mean_dist.append(sse)
# 化成折线图观察最佳的k值
plt.plot(range(1, 10), mean_dist, 'bx-')
plt.ylabel('SSE')
plt.xlabel('k')
plt.show()
if __name__ == '__main__':
getK()
# 通过观察可知, 4 是最佳的k值
k_means(4)
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
从MB升级到新的MBP后,Apple的迁移助手没有移动我的gem。我这次是通过macports安装rubygems,希望在下次升级时避免这种情况。有什么我应该注意的陷阱吗? 最佳答案 如果你想把你的gems安装在你的主目录中(在传输过程中应该复制过来,作为一个附带的好处,会让你以你自己的身份运行geminstall,而不是root),将gemhome:键设置为您在~/.gemrc中的主目录中的路径. 关于通过MacPorts的RubyGems是个好主意吗?,我们在StackOverf
当我执行>rvminstall1.9.2时一切顺利。然后我做>rvmuse1.9.2也很顺利。但是当涉及到ruby-v时..sam@sjones:~$rvminstall1.9.2/home/sam/.rvm/rubies/ruby-1.9.2-p136,thismaytakeawhiledependingonyourcpu(s)...ruby-1.9.2-p136-#fetchingruby-1.9.2-p136-#downloadingruby-1.9.2-p136,thismaytakeawhiledependingonyourconnection...%Total%Rece