 图1
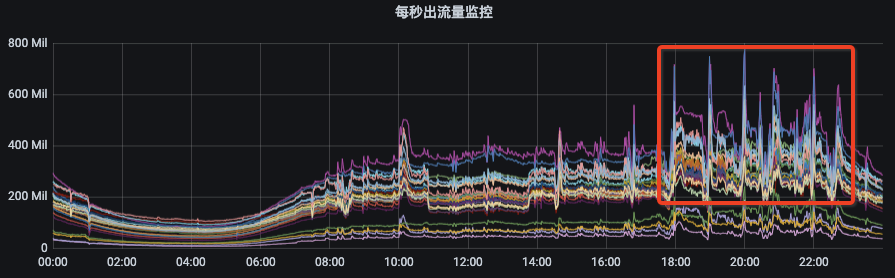
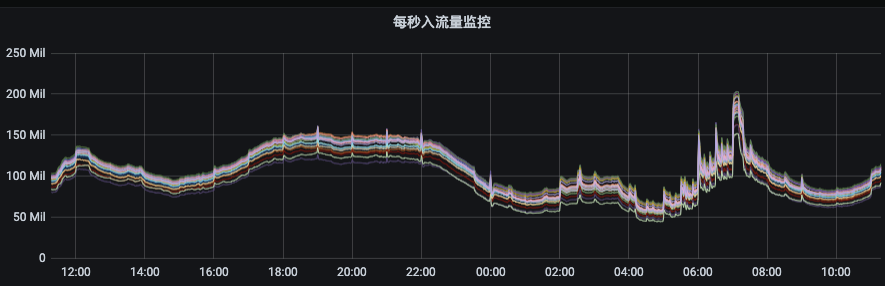
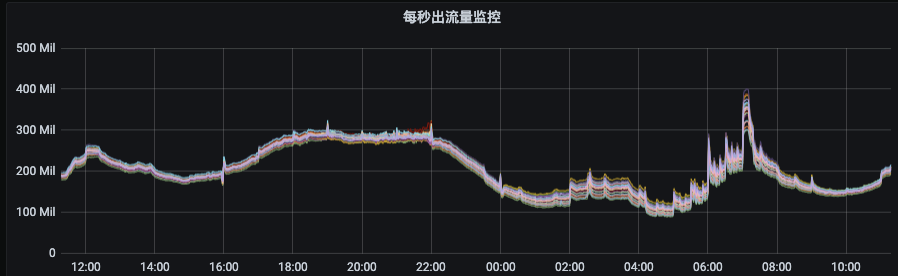
图1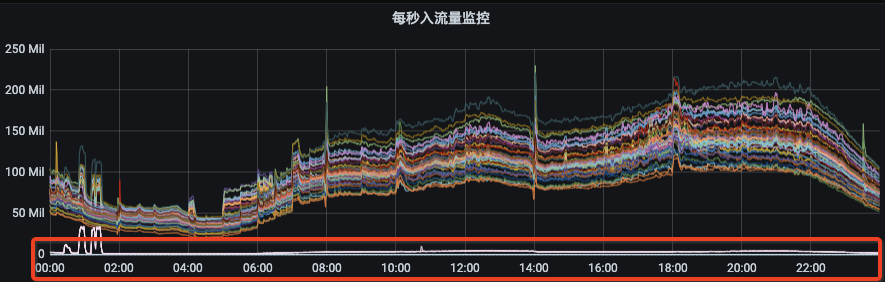 图2从图1可以看出资源组内各broker的流量分布并不是很均衡,而且由于部分topic分区集中分布在某几个broker上,当topic流量突增的时候,会出现只有部分broker流量突增。这种情况下,我们就需要扩容topic分区或手动执行迁移动操作。图2是我们Kafka集群的一个资源组扩容后的流量分布情况,流量无法自动的分摊到新扩容的节点上。此时,就需要我们手动的触发数据迁移,从而才能把流量引到新扩容的节点上。
图2从图1可以看出资源组内各broker的流量分布并不是很均衡,而且由于部分topic分区集中分布在某几个broker上,当topic流量突增的时候,会出现只有部分broker流量突增。这种情况下,我们就需要扩容topic分区或手动执行迁移动操作。图2是我们Kafka集群的一个资源组扩容后的流量分布情况,流量无法自动的分摊到新扩容的节点上。此时,就需要我们手动的触发数据迁移,从而才能把流量引到新扩容的节点上。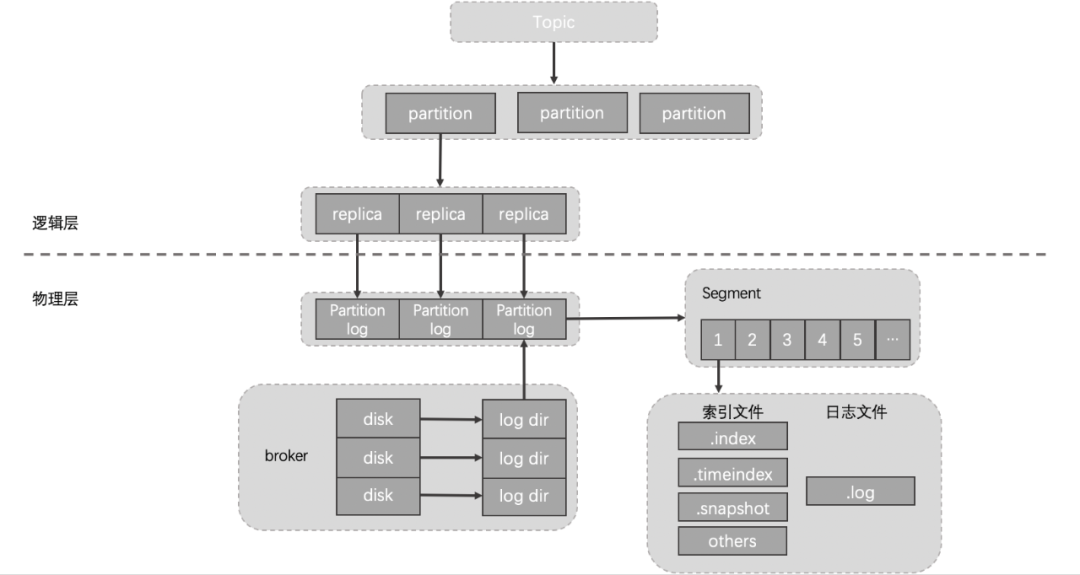 了解完Kafka存储机制之后,我们可以清晰的了解到,客户端写入Kafka的数据会按照topic分区被路由到broker的不同log目录下,只要我们不人工干预,那每次路由的结果都不会改变。因为每次路由结果都不会改变,那么问题来了:随着topic数量不断增多,每个topic的分区数量又不一致,最终就会出现topic分区在Kafka集群内分配不均的情况。比如:topic1是10个分区、topic2是15个分区、topic3是3个分区,我们集群有6台机器。那6台broker上总会有4台broker有两个topic1的分区,有3台broke上有3个topic3分区等等。这样的问题就会导致分区多的broker上的出入流量可能要比其他broker上要高,如果要考虑同一topic不同分区流量不一致、不同topic流量又不一致,再加上我们线上有7000个topic、13万个分区、27万个副本等等这些。这么复杂的情况下,集群内总会有broker负载特别高,有的broker负载特别低,当broker负载高到一定的时候,此时就需要我们的运维同学介入进来了,我们需要帮这些broker减减压,从而间接的提升集群总体的负载能力。当集群整体负载都很高,业务流量会持续增长的时候,我们会往集群内扩机器。有些同学想扩机器是好事呀,这会有什么问题呢?问题和上面是一样的,因为发往topic分区的数据,其路由结果不会改变,如果没有人工干预的话,那新扩进来机器的流量就始终是0,集群内原来的broker负载依然得不到减轻。
了解完Kafka存储机制之后,我们可以清晰的了解到,客户端写入Kafka的数据会按照topic分区被路由到broker的不同log目录下,只要我们不人工干预,那每次路由的结果都不会改变。因为每次路由结果都不会改变,那么问题来了:随着topic数量不断增多,每个topic的分区数量又不一致,最终就会出现topic分区在Kafka集群内分配不均的情况。比如:topic1是10个分区、topic2是15个分区、topic3是3个分区,我们集群有6台机器。那6台broker上总会有4台broker有两个topic1的分区,有3台broke上有3个topic3分区等等。这样的问题就会导致分区多的broker上的出入流量可能要比其他broker上要高,如果要考虑同一topic不同分区流量不一致、不同topic流量又不一致,再加上我们线上有7000个topic、13万个分区、27万个副本等等这些。这么复杂的情况下,集群内总会有broker负载特别高,有的broker负载特别低,当broker负载高到一定的时候,此时就需要我们的运维同学介入进来了,我们需要帮这些broker减减压,从而间接的提升集群总体的负载能力。当集群整体负载都很高,业务流量会持续增长的时候,我们会往集群内扩机器。有些同学想扩机器是好事呀,这会有什么问题呢?问题和上面是一样的,因为发往topic分区的数据,其路由结果不会改变,如果没有人工干预的话,那新扩进来机器的流量就始终是0,集群内原来的broker负载依然得不到减轻。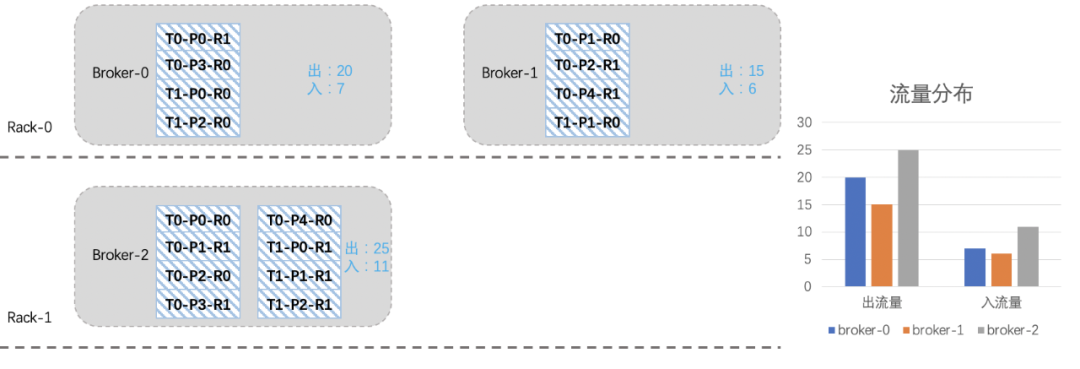 假设我们现在新扩入一台broker3(Rack2),如下图所示:由于之前考虑了topic在机架上的分布,所以从整体上看,broker2的负载要高一些。
假设我们现在新扩入一台broker3(Rack2),如下图所示:由于之前考虑了topic在机架上的分布,所以从整体上看,broker2的负载要高一些。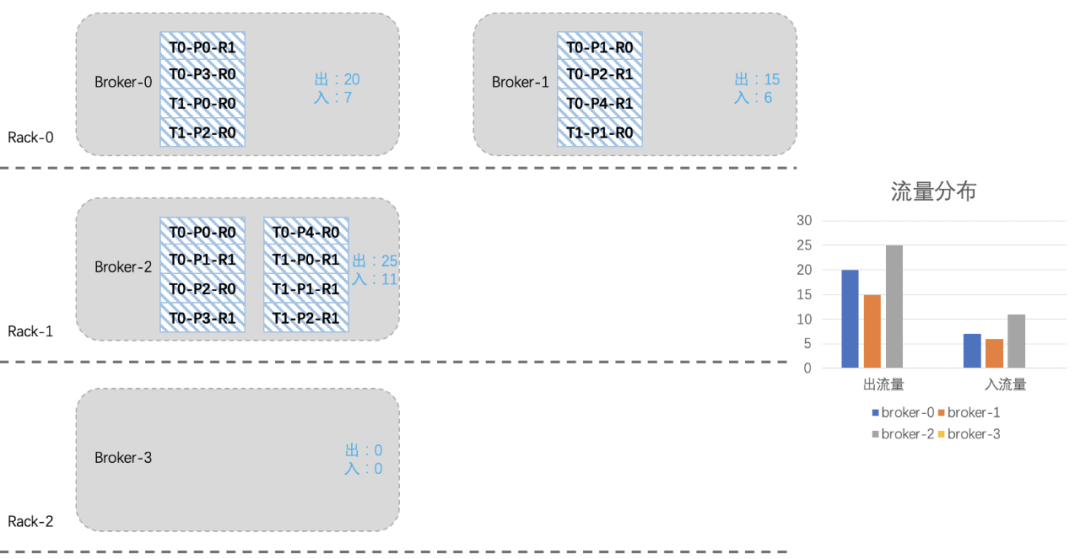 我们现在想把broker2上的一些分区迁移到新扩进来的broker3上,综合考虑机架、流量、副本个数等因素,我们将T0-P2-R0、T0-P3-R1、T0-P4-R0、T1-P0-R1四个分区迁移到broker3上。
我们现在想把broker2上的一些分区迁移到新扩进来的broker3上,综合考虑机架、流量、副本个数等因素,我们将T0-P2-R0、T0-P3-R1、T0-P4-R0、T1-P0-R1四个分区迁移到broker3上。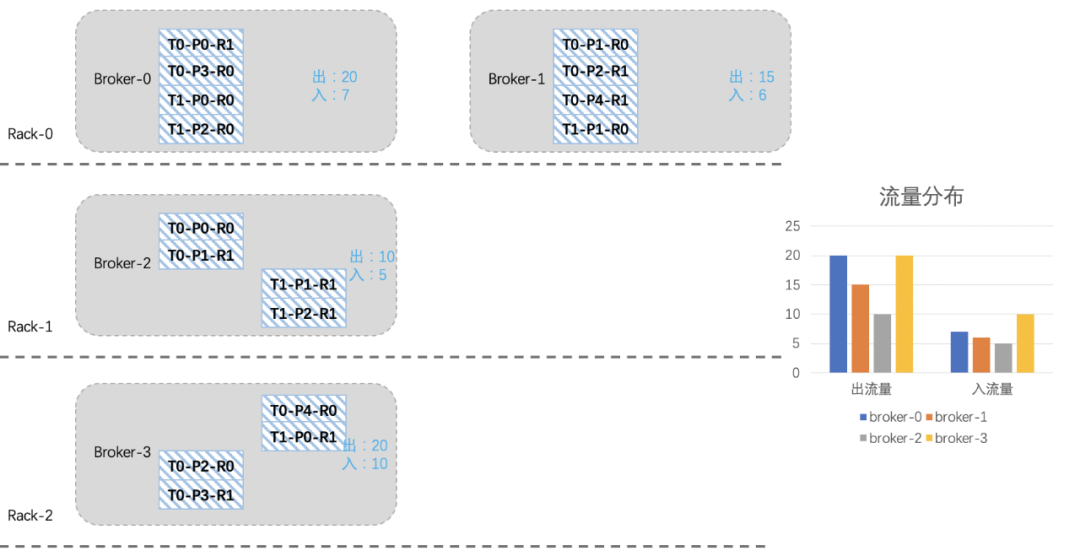 看起来还不是很均衡,我们再将T1-P2分区切换一下leader:
看起来还不是很均衡,我们再将T1-P2分区切换一下leader: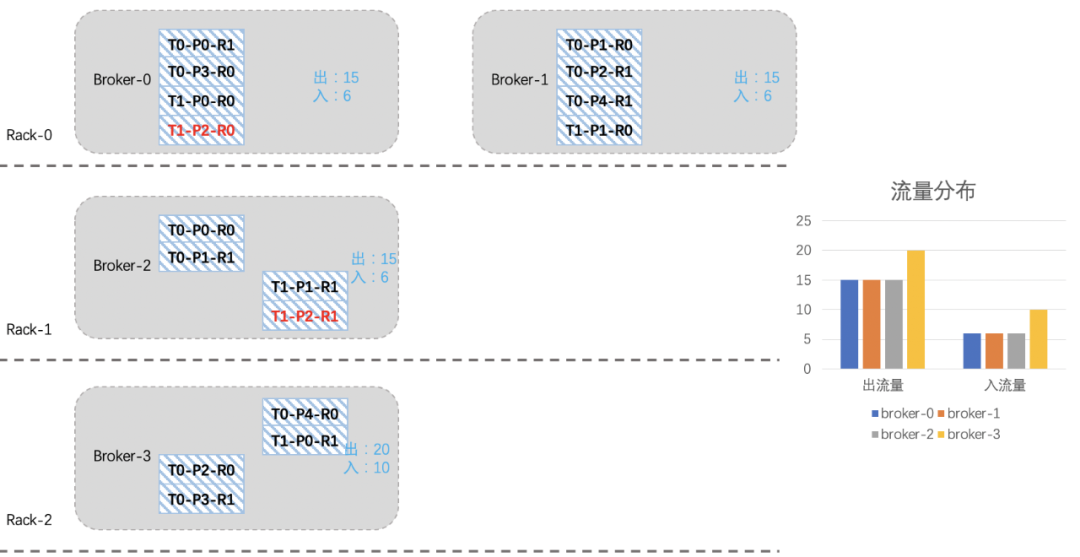 经历一番折腾后,整个集群就均衡许多了,关于上面迁移副本和leader切换的命令参考如下:Kafka 副本迁移脚本
经历一番折腾后,整个集群就均衡许多了,关于上面迁移副本和leader切换的命令参考如下:Kafka 副本迁移脚本# 副本迁移脚本:kafka-reassign-partitions.sh
# 1. 配置迁移文件
$ vi topic-reassignment.json
{"version":1,"partitions":[
{"topic":"T0","partition":2,"replicas":[broker3,broker1]},
{"topic":"T0","partition":3,"replicas":[broker0,broker3]},
{"topic":"T0","partition":4,"replicas":[broker3,broker1]},
{"topic":"T1","partition":0,"replicas":[broker2,broker3]},
{"topic":"T1","partition":2,"replicas":[broker2,broker0]}
]}
# 2. 执行迁移命令
bin/kafka-reassign-partitions.sh --throttle 73400320 --zookeeper zkurl --execute --reassignment-json-file topic-reassignment.json
# 3. 查看迁移状态/清除限速配置
bin/kafka-reassign-partitions.sh --zookeeper zkurl --verify --reassignment-json-file topic-reassignment.json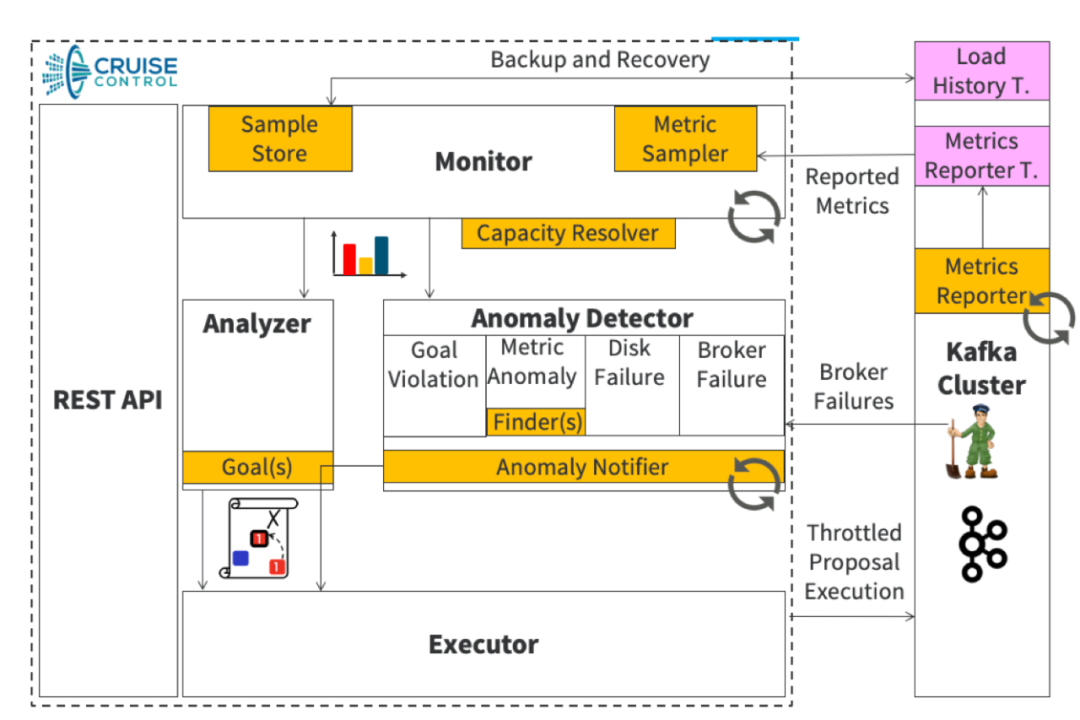 (来源:cruise control 官网)(1)MonitorMonitor分为客户端Metrics Reporter和服务端Metrics Sampler:
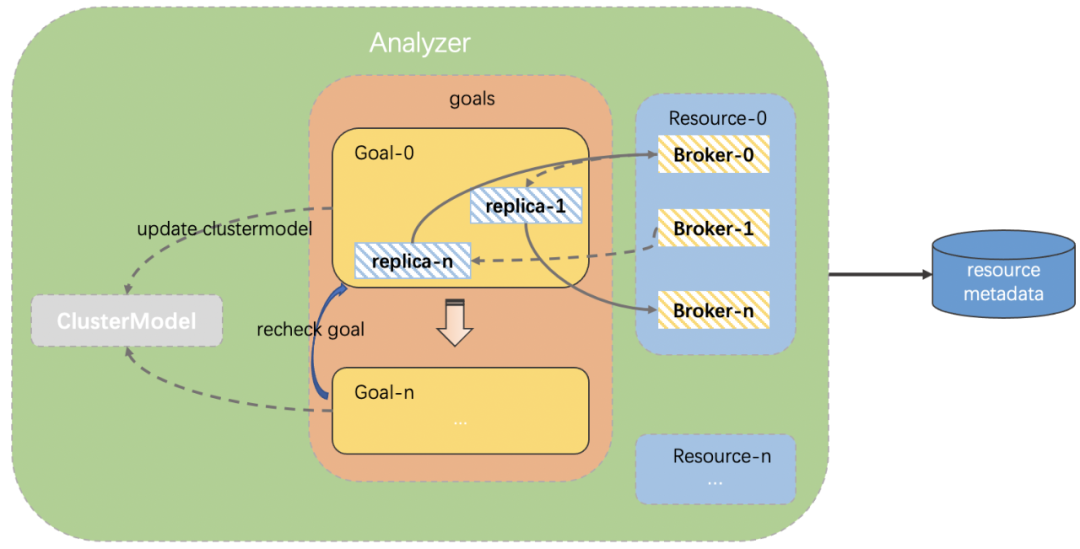
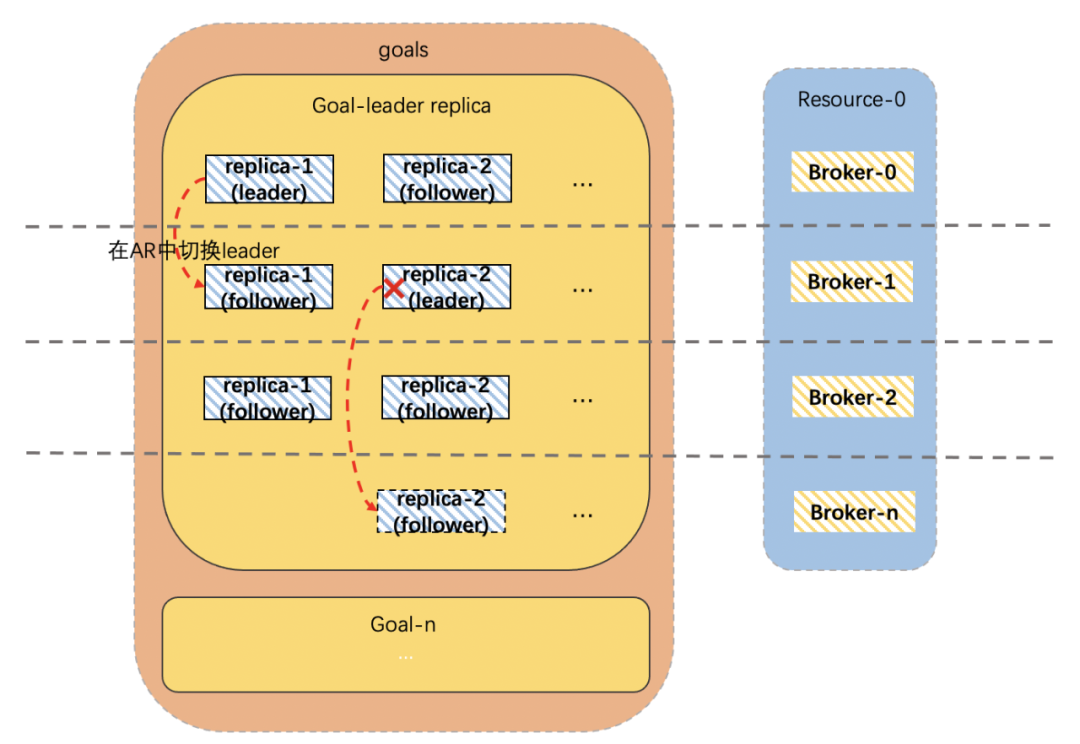
(来源:cruise control 官网)(1)MonitorMonitor分为客户端Metrics Reporter和服务端Metrics Sampler: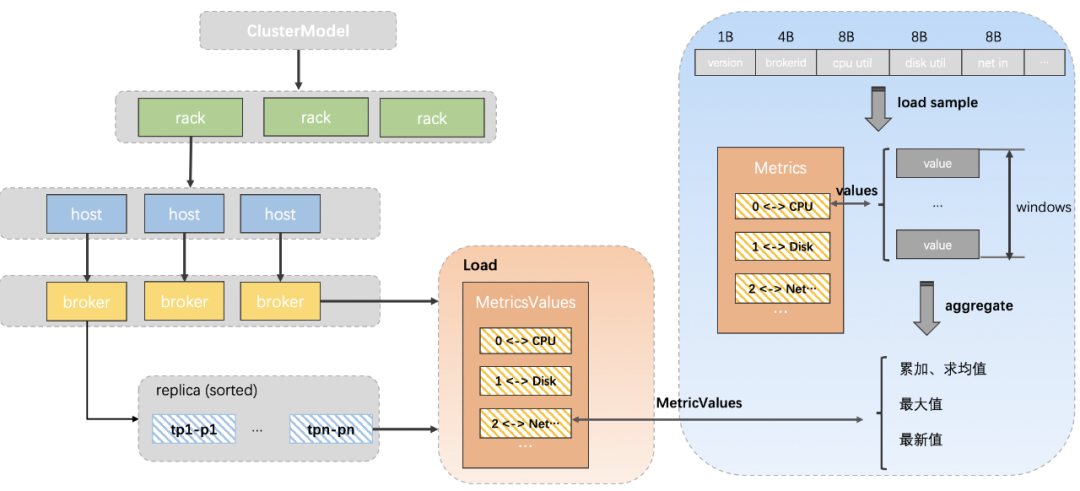 Analyzer 会遍历我们指定的broker(默认是集群所有的broker),由于每台broker及其下面的topic分区副本都有详细的指标信息,分析算法直接根据这些指标和指定资源对broker进行排序。本例子的资源就是topic分区leader副本数量,接着Analyzer会根据我们提前设置的最大/最小阈值、离散因子等来判断当前broker上某topic的leader副本数量是否需要增加或缩减,如果是增加,则变更clustermodel将负载比较高的broker上对应的topic leader副本迁移到当前broker上,反之亦然,在后面的改造点中,我们会对Analyzer的工作过程做简单的描述。遍历过所有broker,并且针对我们指定的所有资源都进行分析之后,就得出了最终版的clustermodel,再与我们最初生成的clustermodel对比,就生成了topic迁移计划。cruise control会根据我们指定的迁移策略分批次的将topic迁移计划提交给kafka集群执行。迁移计划示意图如下:
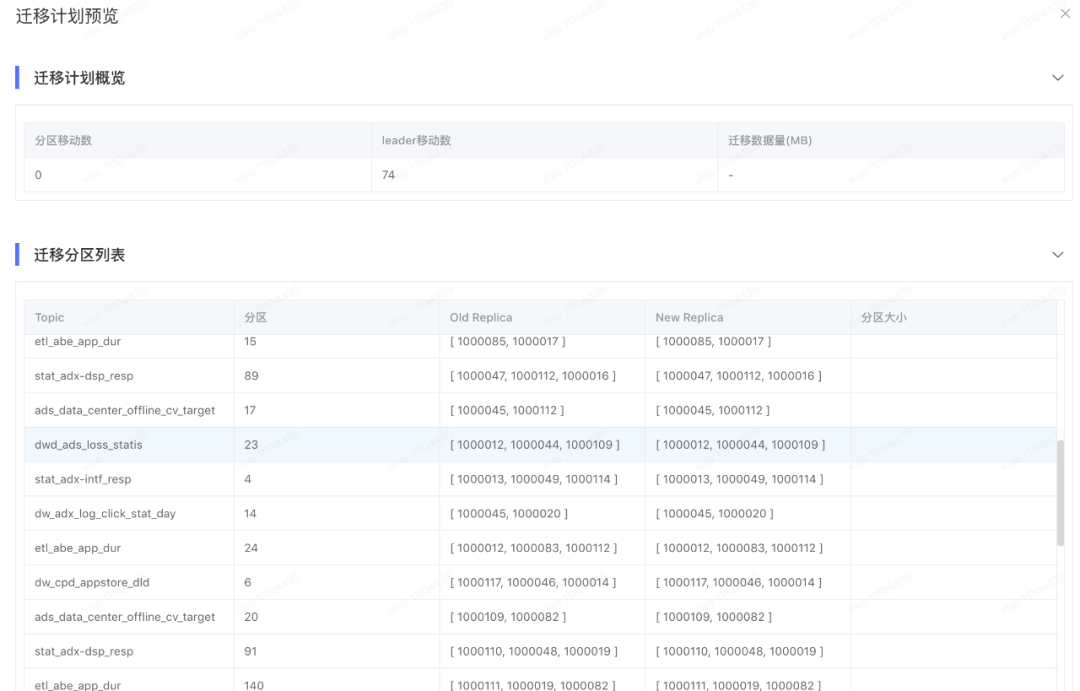
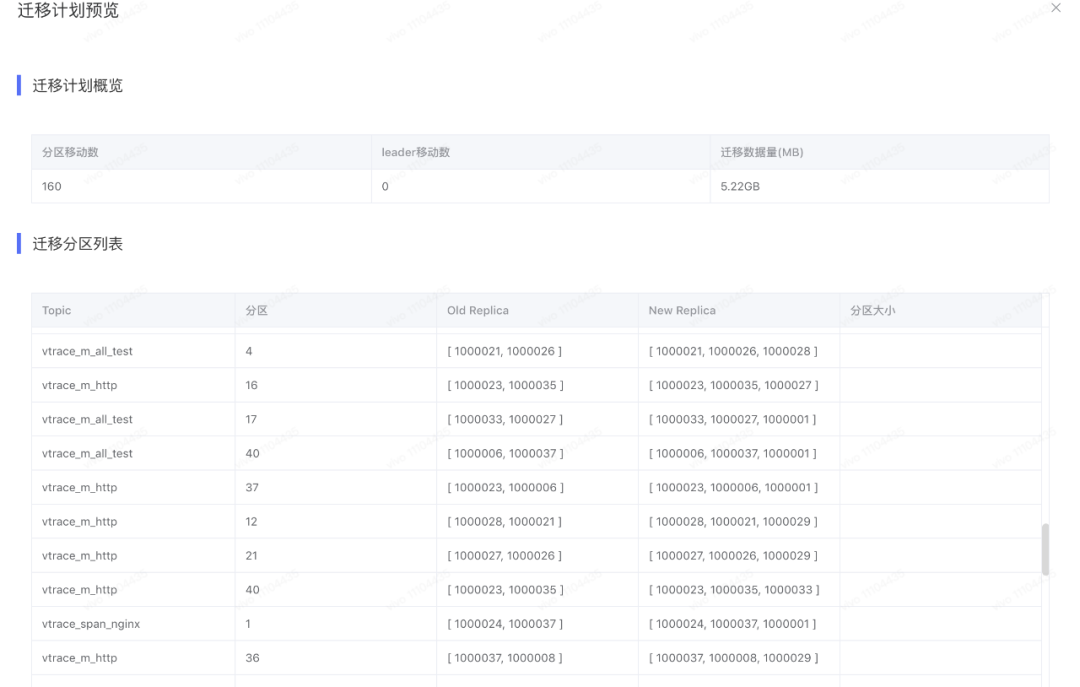
Analyzer 会遍历我们指定的broker(默认是集群所有的broker),由于每台broker及其下面的topic分区副本都有详细的指标信息,分析算法直接根据这些指标和指定资源对broker进行排序。本例子的资源就是topic分区leader副本数量,接着Analyzer会根据我们提前设置的最大/最小阈值、离散因子等来判断当前broker上某topic的leader副本数量是否需要增加或缩减,如果是增加,则变更clustermodel将负载比较高的broker上对应的topic leader副本迁移到当前broker上,反之亦然,在后面的改造点中,我们会对Analyzer的工作过程做简单的描述。遍历过所有broker,并且针对我们指定的所有资源都进行分析之后,就得出了最终版的clustermodel,再与我们最初生成的clustermodel对比,就生成了topic迁移计划。cruise control会根据我们指定的迁移策略分批次的将topic迁移计划提交给kafka集群执行。迁移计划示意图如下: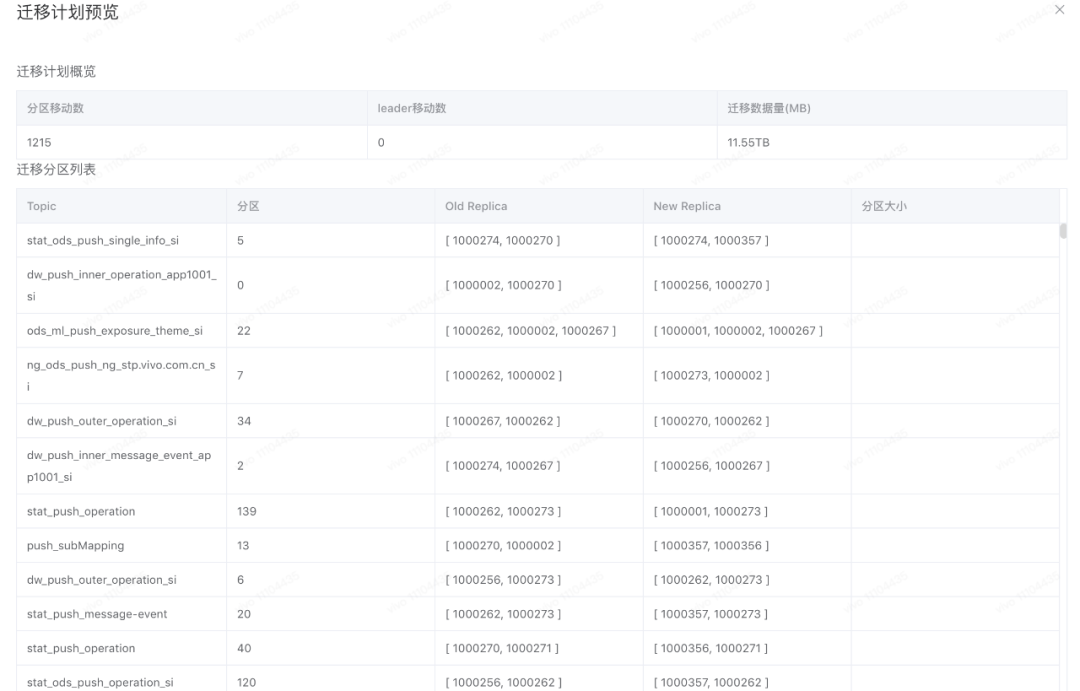
# 修改kafka的server.properties
metric.reporters=com.linkedin.kafka.cruisecontrol.metricsreporter.CruiseControlMetricsReporter
cruise.control.metrics.reporter.bootstrap.servers=域名:9092
cruise.control.metrics.reporter.security.protocol=SASL_PLAINTEXT
cruise.control.metrics.reporter.sasl.mechanism=SCRAM-SHA-256
cruise.control.metrics.reporter.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=\"ys\" password=\"ys\";mv cruise-control-2.0.xxx-SNAPSHOT.jar
cruise-control/build/libs;# 修改cruise control配置文件
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-256
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=\"ys\" password=\"ys\";
bootstrap.servers=域名:9092
zookeeper.connect=zkURL# 集群id
cluster_id=xxx
db_url=jdbc:mysql://hostxxxx:3306/databasexxx
db_user=xxx
db_pwd=xxx很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
我正在使用Devise在Rails应用程序中,并希望通过API公开一些模型数据,但应该像应用程序一样限制对API的访问。$curlhttp://myapp.com/api/v1/sales/7.json{"error":"Youneedtosigninorsignupbeforecontinuing."}很明显。在这种情况下是否有访问API的最佳实践?我更喜欢一步验证+获取数据,但这只是为了让客户的工作更轻松。他们将使用JQuery在客户端提取数据。感谢您提供任何信息!凡妮莎 最佳答案 我建议您按照以下帖子中的选项2:使用APIke
我正在开发一个Rails2.3.1网站。在整个网站中,我需要一个用于在各种页面(主页、创建帖子页面、帖子列表页面、评论列表页面等)上创建帖子的表单——只要说这个表单需要在由各种Controller)。这些页面中的每一个都显示在相应的Controller/操作中检索到的各种其他信息。例如,主页列出了最新的10篇文章、从数据库中提取的内容等。因此,我已将帖子创建表单移动到它自己的部分中,并将该部分包含在所有必要的页面中。请注意,部分POST中的表单到/questions(路由到PostsController::create——这是默认的Rails行为)。我遇到的问题是当Posts表单没有正
我正在按照我一直在研究的研讨会实现“服务对象”,我正在构建一个redditAPI应用程序。我需要对象返回一些东西,所以我不能只执行初始化程序中的所有内容。我有这两个选择:选项1:类需要实例化classSubListFromUserdefuser_subscribed_subs(client)@client=client@subreddits=sort_subs_by_name(user_subs_from_reddit)endprivatedefsort_subs_by_name(subreddits)subreddits.sort_by{|sr|sr[:name].downcase}
我有一个EC2实例正在运行。我有一个负载均衡器,它与EC2实例相关联。PingTarget:HTTP:3001/healthCheckTimeout:5secondsInterval:24secondsUnhealthythreshold:2Healthythreshold:10现在该实例显示为OutofService。我什至尝试更改监听端口等等。一切正常,直到重新启动我的EC2实例。任何帮助将不胜感激。仅供引用:我有一个在端口3001上运行的Rails应用程序,我有一个用于HTTP:80(loadbalancer)到HTTP:3001的监听器。我还在终端中通过ssh检查了正在运行的应