
💭 写在前面:本章我们首先会明确冯诺依曼体系结构的概念,旨在帮助大家理解体系结构在硬件角度去理解数据流走向的问题。理解完之后我们再去谈操作系统,这个在之前的章节已经有所铺垫,当时我们只讲解了操作系统是什么,而这一章我们会讲解更多有关操作系统的细节,着重谈谈操作系统概念与定位、操作系统是如何去做管理的,引入 "先描述,再组织。" 的概念,最后我们在讲解系统调用,我们会使用斯坦福大学操作系统课 Pintos 项目作为基础增添一些新的用户级程序的系统调用接口。
 本篇博客全站热榜排名:9
本篇博客全站热榜排名:9

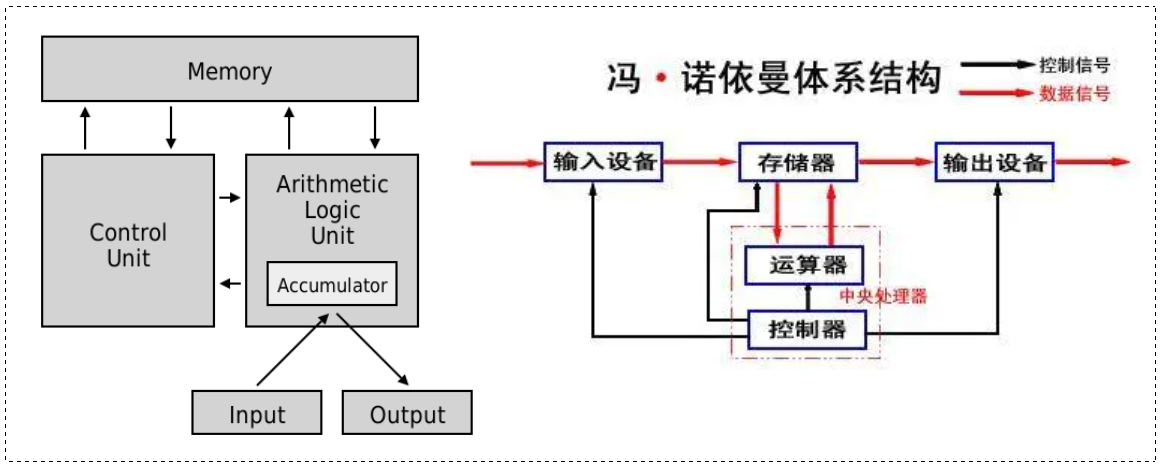
 冯诺依曼体系结构 (Von Neumann architecture) ,又称 "范纽曼型架构"。
冯诺依曼体系结构 (Von Neumann architecture) ,又称 "范纽曼型架构"。
它是我们常见的计算机,如电脑、笔记本或服务器大部分都遵守的一个架构体系。
📌 注意事项:
图中的存储器指的就是内存。
不考虑缓存情况,这里的 CPU 能且只能对内存进行读写,不能访问外设(输入或输出设备)
外设想要输入或输出数据,也只能写入内存或者从内存中读取。
所有设备都只能和内存打交道。
❓ 思考:为什么冯诺依曼体系中要存在 "内存" 这样的东西?
🔨 技 术 角 度
存储的速度:
 有很多种存储,且存储的速度方面是有差别的,给大家一个量化的概念去理解:
有很多种存储,且存储的速度方面是有差别的,给大家一个量化的概念去理解:
像 CPU、寄存器以及缓存的读写速度是纳秒级别的,而内存是微秒级别的,外设是毫秒级别,
甚至还有秒级别的设备,因此大家的速度差别是非常非常大的,速度有快有慢。
站在我们刚刚展出的冯诺依曼体系结构来看,就是 "输入设备" 是最快的,"输出设备" 是最慢的。
存储器是适中的,如果我们此时不考虑内存的存在:
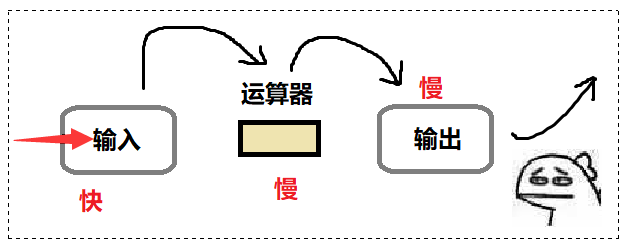
先让输入设备接收用户输入,如果用户不输入,或者输入设备在接受用户期间,
我们的 CPU 是属于闲置状态的,当 CPU 把数据拿到之后再进行计算还得写,写完后还得刷。
 (闲置状态)
(闲置状态)
CPU 把数据计算完再交给输出设备,交给它时速度非常慢,可能还要给用户展示。
总体来说,就是输入设备非常快,运算器和输出是非常慢的,这里就引出了 "木桶效应" 问题。
" 木桶如求盛水多,决于短板短几何。"
 因此,由此构建出的计算机效率是非常低下的!
因此,由此构建出的计算机效率是非常低下的!
所以我们就不能够只是裸地将外设和 CPU 直接粘合起来,构成所对应的计算机体系。
所以就有了冯诺依曼体系结构,在输入输出和运算, 控制器之间添加一个中间设备 —— 存储器。
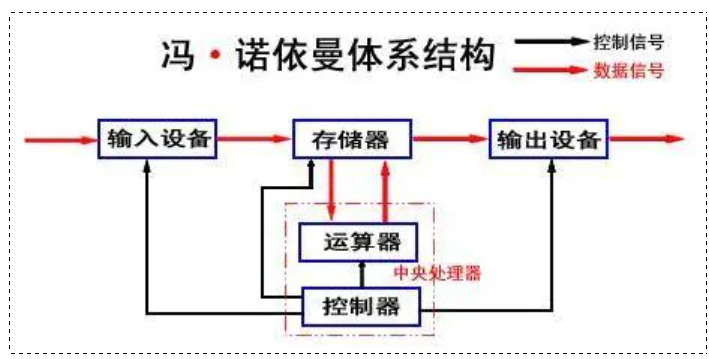
💡 存储器最大的价值:输入设备在输入数据时不是把数据直接交给 CPU 的,而是把数据先从外设交给存储器,再将存储器当中的数据再被 CPU 读取,CPU 计算完后再将数据写回存储器,再由内存刷新回输出设备。因此在整个计算机体系当中,内存是属于数据层面上的核心地位。
📌 数据角度:外设不和 CPU 直接交互,而是和内存交互。(CPU 也是如此)
 内存在我们看来,就是体系结构的一个大的缓存,适配外设和 CPU 速度不均的问题的。
内存在我们看来,就是体系结构的一个大的缓存,适配外设和 CPU 速度不均的问题的。
💰 成 本 角 度
 造价成本:寄存器
造价成本:寄存器 内存
磁盘 (外设)
💡 内存的意义:使用较低的钱的成本,能够获得较高的性能。
因为内存的存在,我们现在可以用不多的钱买上一台性价比不错的电脑,这就是内存的最大价值。
" 我们自己写的软件,编译好之后,要运行,必须先加载到内存。"
 为什么?因为这是 体系结构 决定的!如果不加载到内存 CPU 没办法执行的。
为什么?因为这是 体系结构 决定的!如果不加载到内存 CPU 没办法执行的。
所以我们自己编好的软件加载到内存,这是体系结构决定的,
当你在启动时,还没有执行程序时,你的数据其实已经预加载到内存当中了。
 这就牵扯到 "局部性原理" 的概念了:局部性原理是指 CPU 访问存储器时,
这就牵扯到 "局部性原理" 的概念了:局部性原理是指 CPU 访问存储器时,
无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
比如正在执行第10行代码,你有理由推断你接下来要执行的代码一定是第10行代码附近的代码。
因为局部性原理的存在,你在访问某些数据时可以将数据的周边数据提前给你加载出来,
 这,就是操作系统预加载数据的根本理论基础。
这,就是操作系统预加载数据的根本理论基础。
 我们先来看 运算器,运算器主要承担了运算的工作。
我们先来看 运算器,运算器主要承担了运算的工作。
计算机的计算种类无非两种:① 算数计算 ② 逻辑计算
加减乘除取模这一些就算算数计算,逻辑与逻辑或逻辑反这些就是逻辑计算。
在人的计算世界中,计算其实就是算账、算数。
人会推理一些东西,这实际上就是逻辑。所以计算机的计算和人的计算,无外乎就是这两种。
 虽然我们一直在说外设不和 CPU 在数据上交互,但并不代表它们之间没有交互。
虽然我们一直在说外设不和 CPU 在数据上交互,但并不代表它们之间没有交互。
比如输入设备把数据输入完后,中央处理器如何知道数据已经读取完了?
数据也不是一定 100% 能装载进来,如果没有装载进来呢?CPU 是不是就要和外设交互一下?
"喂,外设,数据你还没装载完呢,你跟内存商量下你们赶快把数据装载起来"
所以中央处理器还需要有协调数据流向,什么时候流,流多少的问题。
 这,实际上就是由 控制器 来控制外设的。
这,实际上就是由 控制器 来控制外设的。
几乎所有的硬件,只能被动地完成某种功能,不能主动地完成,一般都是要配合软件完成的。
🔺 总结:所有的外设在数据层面上不和 CPU 接轨,直接和内存处理。CPU 读数据直接从内存中读数据,处理完数据后的结果再刷新到内存。
对我们来说,实际上计算机为了提升整体性能,也加了许多其他的优化策略,比如寄存器和缓存,这些话题我们一言难尽,我们放到后面再去探讨。
🔍 复习链接:【看表情包学Linux】了解操作系统
 操作系统是一款软件,用来进行对软硬件资源进行管理的软件。
操作系统是一款软件,用来进行对软硬件资源进行管理的软件。
任何一款计算机系统都包含一个基本的程序集合,我们称之为操作系统()。
 操作系统包括:
操作系统包括:
定位:在整个计算机软硬件架构中,操作系统的定位是一款纯正的 "搞管理" 的软件。
管理的目的:① 对上:提供一个良好稳定的运行环境 ② 对下:管理好软硬件资源。
而我们今天要重点谈论的就是 "管理",什么叫做管理?如何理解?
如何理解 "管理",我们讲两个小故事。虽然我们不懂什么是管理,但是我们肯定是被管过的。
 我们先看看人是如何做事的,人做事:
我们先看看人是如何做事的,人做事:
决策 执行
 比如今天我打算晚上跟朋友一起开黑,这就是决策。
比如今天我打算晚上跟朋友一起开黑,这就是决策。
晚上吃完饭你很喊朋友上号,然后一起开黑去了,这就是执行。
这就是 决策过程 和 执行过程 ,虽然决策和执行在我们人身上似乎是混合体的,我决策我执行。
但是计算机中,为了能够做更好的功能解耦,决策和执行实际上是可以分离开来的。
"有人负责决策,也有人负责执行。"
举个学校的例子,校长做决策,辅导员去执行。校长连我的面都不见,如何管理我呢?
管理你要和你打交道,要和你见面吗?他是怎么做到的?
管理的本质:不是对管理对象进行直接管理,而是只要拿到管理对象的所有的相关数据,我们队数据的管理,就可以体现对人的管理。
"在公司中,你之前负责的模块经你手自己处理了大半年,模块的效率比之前翻了十倍一百倍,领导就知道你一定是做出成绩来了,如果你在公司里什么都没写,什么有效数据都没有产出,所有管理最终都要落实到对数据做管理。"
这是我又有一个问题了,如果你说它连我的面就不见,他又是如何拿到我的数据的呢?
 执行者可不是只拿数据,还可以落实对应的政策。
执行者可不是只拿数据,还可以落实对应的政策。
对管理的进一步理解:人认识世界的方式 —— 人是通过属性认识世界的。
 一切事物都可以通过抽取对象的属性,来达到描述对象的目的。
一切事物都可以通过抽取对象的属性,来达到描述对象的目的。
class OBJ {
// 成员属性
}继续刚才的例子,如果你自己就个是个当过程序员的校长,你想管理学校的同学,
那么就可以抽取所有同学的属性,描述对应的同学,我们知道 Linux 内核代码是由C语言写的。
那么C语言中有没有一种数据类型,能够达到描述某种对象的功能?他就是 ——

(劲爆啊,突如其来的动漫感,哈哈哈哈哈哈)
struct student {
学生的基本信息(身高,姓名,年级,电话...)
在校基本信息(专业,班级,年级)
考试成绩(平时成绩,期末成绩)
学校活动(...学生会, 班长?)
其他信息
struct student* next;
struct student* prev;
};如此一来,对学生的管理,就变成了对链表的增删查改。然后我们在有头插、尾插的各种方法。
现在如过我想找到考试成绩最好的学生,只需要遍历整个链表,找到那个学生的结点即可。
再比如,学校的挂科率太高了,要整治一下这个问题,我们就执行一个排序算法,以绩点排序。
按升序排列,找到若干名排在前面的绩点低的学生,再通过自带的信息联系到辅导员,进行管理。

管理的本质:对数据做管理 对某种数据结构的管理,管理的核心理念 ——
" 先描述,再组织。"
所谓的管理,其实就是 "先描述,再组织。"
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,
这部分由操作系统提供的接口,叫做系统调用。 系统调用在使用上,功能比较基础,对用户的要求相对也比较高。
为了更好的实战性学习,下面我将演示如何在斯坦福操作系统大作业 Pintos 项目,添加用户级系统调用。学习如何额外实现一些功能到系统调用中以供用户使用。因为涉及到 src/example 下的Makefile 的修改、lib 目录下 syscall-nr 系统调用号的增添以及定义调用宏等操作,所以需要对 Pintos 项目有一定的了解。本文旨在帮助大家 DIY 自己想实现的系统调用,增加到自己的 Pintos 项目中。为了方便讲解,我们添加两个非常简单的系统调用功能,调用的功能其实并不重要,重要的是关注添加系统调用的操作。我们会将下面两个我们自己实现的函数作为系统调用:
int fibonacci(int n) // 返回斐波那契数列的第n项
int max_of_four_int(int a, int b, int c, int d) // 返回 a b c d 中的最大值🔍 前置文章:
【OS Pintos】用户程序是如何工作的 | Pintos 运行原理 | 虚拟内存 | 页函数 | 系统调用
【OS Pintos】Project1 项目要求说明 | 进程中止信息 | 参数传递 | 用户内存访问
首先我们要进入 example 目录。examples 目录是在 Pintos 目录下的 src 子目录下的。
$ cd pintos/src/examples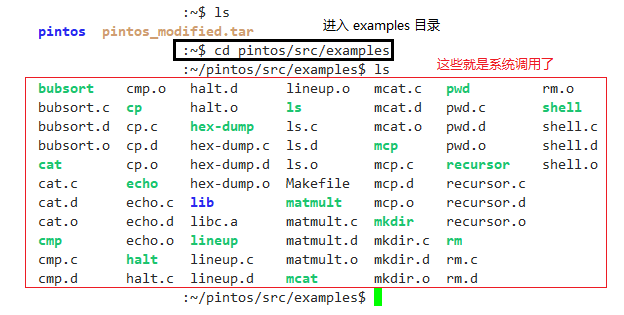
添加系统调用,自然需要修改 Makefile 文件,我们可以照着其他用户程序的编写方式去修改:
$ vim Makefile # 用vim编辑器打开Makefile (打开后如图所示)
(打开后如图所示)
 我们来分析一下这个 Makefile 文件,我们先看前面的注释……
我们来分析一下这个 Makefile 文件,我们先看前面的注释……
emm,这似乎是 Pintos 作者留下的注释哈:

大致意思就是:添加新的系统调用接口,需要先将它名字添加到 列表中,然后按 name_SRC 的格式添加到资源文件中(name 指的是系统调用的名字)。
 好,我们乖乖听话,按大哥的要求做!
好,我们乖乖听话,按大哥的要求做!
Vim 下输入 进入插入模式后,在
列表中添加一个文件名,比如取名 additional :
PROGS = cat cmp cp echo halt hex-dump ls mcat mcp mkdir pwd rm shell \
bubsort lineup matmult recursor additional
按照要求在 列表中添加完名字后,还需要将其添加到资源文件中,也在这个 Makefile 里,我们直接往下拉照葫芦画瓢,按格式添加即可:
additional_SEC = additional.c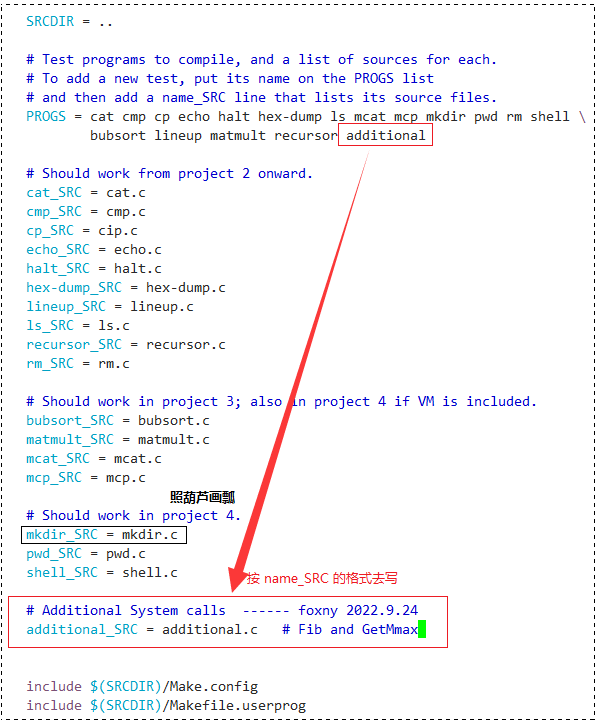
编辑完成后 !wq 退出 Vim 即可。
 记录系统调用编号的文件是 syscall-nr.h,它在 lib 目录下:
记录系统调用编号的文件是 syscall-nr.h,它在 lib 目录下:
$ cd pintos/src/lib # 进入user目录 (在cse目录下输入)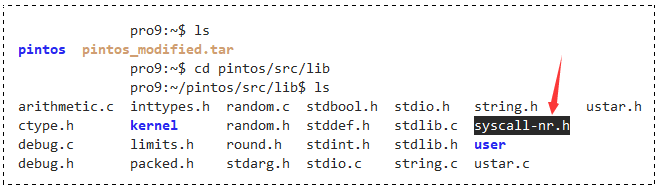
我们用 Vim 打开它,小心点输别输错了,不然自动创建新的文件就麻烦了:
$ vim syscall-nr.h
我们按照要求,在 enum 里添加两个函数的系统调用编号:
SYS_FIBONACCI,
SYS_MAX_OF_FOUR_INT,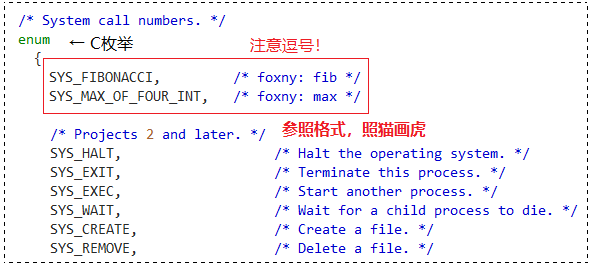
 我们需要在 syscall.h 文件夹中修改,它在进入 lib/user 目录下,走起:
我们需要在 syscall.h 文件夹中修改,它在进入 lib/user 目录下,走起:
$ cd pintos/src/lib/user # 进入user目录 (在cse目录下输入)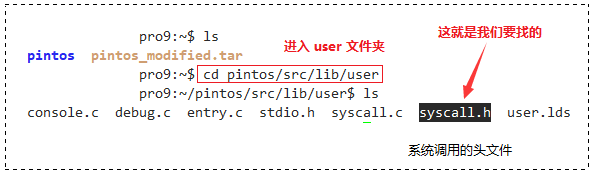
我们 Vim 进入 syscall.h:
$ vim syscall.h 
 我们给它加上新的接口函数的声明:
我们给它加上新的接口函数的声明:
int fibonacci(int n);
int max_of_four_int(int a, int b, int c, int d); 
Pintos 的 syscall 有 4 个参数调用宏,分别是 syscall0, syscall1, syscall2, sycall3(数字几就是几个参数)。
而 max_of_four_int 这个函数有 4 个参数要传,加上调用编号的话就是一共要传 5 个参数:
int max_of_four_int(int a, int b, int c, int d); 因为 Pintos 的自带的最多只能传4个,所以我们就不得不实现一个 syscall4 函数。举这个例子函数正式为教会大家学会如何处理 —— 自己实现的函数需要传的参数大于 syscall3 的情况。
因为 Pintos 的自带的最多只能传4个,所以我们就不得不实现一个 syscall4 函数。举这个例子函数正式为教会大家学会如何处理 —— 自己实现的函数需要传的参数大于 syscall3 的情况。
这就需要我们手写添加一个 syscall4 的宏。在 syscall.c 里添加 ,文件位置在 src/lib/user 下:
$ cd pintos/src/lib/user # 进入user目录 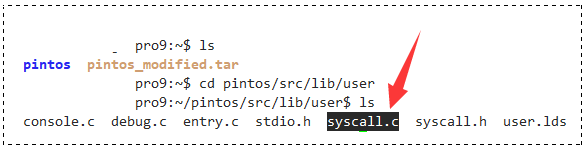
老样子,用 Vim 打开进行编辑:
$ vim syscall.c这个 syscall.c 的源码内容比较长,我们从前往后慢慢看:
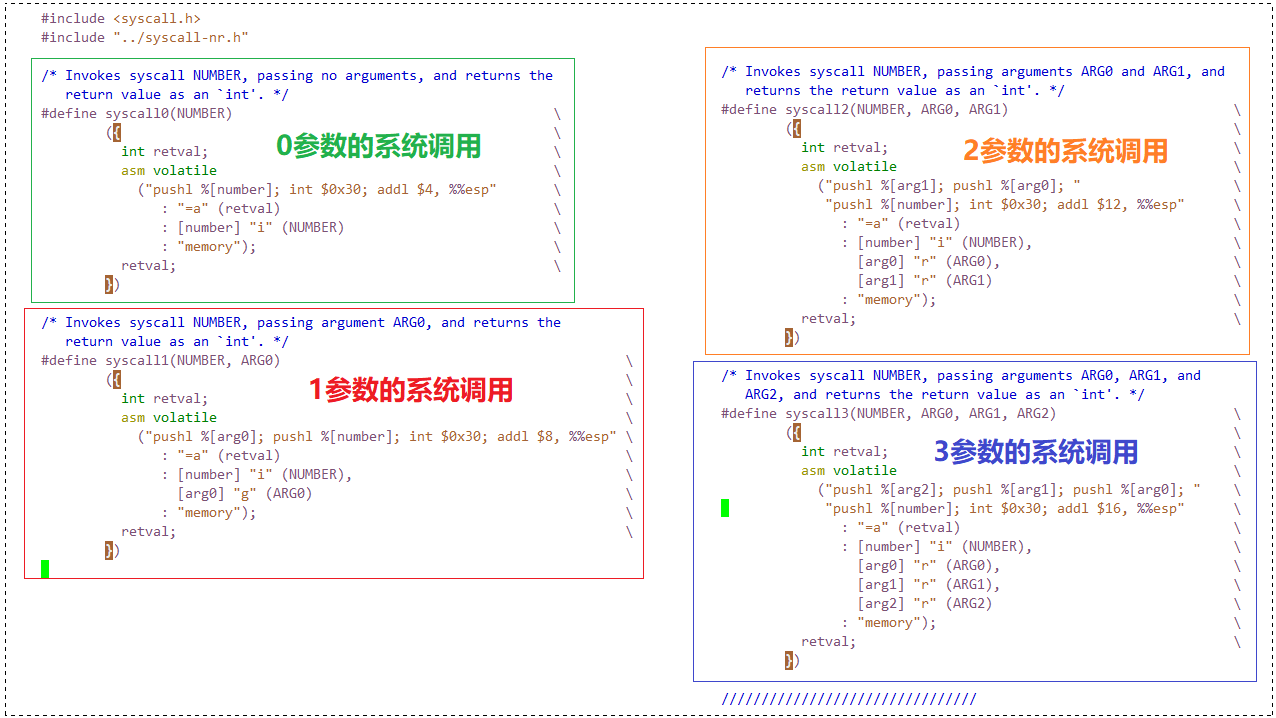
这些就是 Pintos 写好的系统调用宏,分别是无参,一个参数,两个参数,三个参数的系统调用宏。而我们新增的 max_of_four_int 函数需要传递 a,b,c,d 四个参数,而 Pintos 并没有实现,所以这需要我们自己去实现!
 我们仍然是用 照猫画虎大法, 在实现之前我们仔细观察下 syscall3 宏,有助于我们理解,自己实现 syscall4 也能更轻松。
我们仍然是用 照猫画虎大法, 在实现之前我们仔细观察下 syscall3 宏,有助于我们理解,自己实现 syscall4 也能更轻松。
/* Invokes syscall NUMBER, passing arguments ARG0, ARG1, and
ARG2, and returns the return value as an `int'. */
#define syscall3(NUMBER, ARG0, ARG1, ARG2) \
({ \
int retval; \
asm volatile \
("pushl %[arg2]; pushl %[arg1]; pushl %[arg0]; " \
"pushl %[number]; int $0x30; addl $16, %%esp" \
: "=a" (retval) \
: [number] "i" (NUMBER), \
[arg0] "r" (ARG0), \
[arg1] "r" (ARG1), \
[arg2] "r" (ARG2) \
: "memory"); \
retval; \
})💡 解读:不要被这一大坨宏吓到,后面的 \ 是代码换行,这是为了代码可读性而加的!
我们可以看到函数参数有 NUMBER,AGE0,AGE1,AGE2。NUMBER 接收的就是我们的系统调用号,AGE 就是 argument 的简写,就是要接收的参数。
这里是 syscall3,接收三个参数所以这里自然有三个 AGE,我们下面要实现 4 个参数时这里就需要再加一个 "AGE3"。随后 asm volatile 进行 pushl 操作,
注意!参数是 "从右往左" 压入的,即先压 AGE2,再压 AGE1……最后再压 NUMBER。
而后面的 addl $16 即需要的空间,每个 int 型参数占 4 个字节,这里加上系统调用号 NUMBER 一共要 pushl 4 个参数,所以需要索要 16 个字节:
通过这里我们就能知道,我们在实现 syscall4 参数调用宏时,会有 5 个参数,那么到时候这里就需要写 addl $16 。好了,开始照猫画虎写 syscall4 宏:
#define syscall4(NUMBER, ARG0, ARG1, ARG2, ARG3) \
({ \
int retval; \
asm volatile \
("pushl %[arg3]; pushl %[arg2]; pushl %[arg1]; pushl %[arg0]; " \
"pushl %[number]; int $0x30; addl $20, %%esp" \
: "=a" (retval) \
: [number] "i" (NUMBER), \
[arg0] "r" (ARG0), \
[arg1] "r" (ARG1), \
[arg2] "r" (ARG2), \
[arg3] "r" (ARG3) \
: "memory"); \
retval; \
})

 然后不要急着退出,我们 Step5 还要在这里进行操作。
然后不要急着退出,我们 Step5 还要在这里进行操作。
我们刚才已经为 max_of_four_int 定义了 syscall4 了,我们还要在 syscall.c 里实现这两个新函数的系统调用接口。我们刚才在 syscall.h 里已经给这两个函数写过函数声明了:
int fibonacci(int n);
int max_of_four_int(int a, int b, int c, int d); 现在也准备好了 syscall4,我们自然要在 syscall.c 里实现一下它们的系统调用接口。
Fibonacci 函数只有一个参数(没算调用号),使用 Pintos 自带的 syscall1 即可。max_of_four_int 有四个参数(没算调用号),就用我们刚才实现的 syscall4 就行。
这也是为什么我们要 Step by Step 地讲。先定义好系统调用号,然后定义 syscall.h 的系统调用接口,再实现 syscall4,最后再实现 syscall.c 的系统调用接口。按这样的顺序去做不会乱,也不至于写着写着怎么参数突然冒出一个系统调用号,搞得人一脸懵。
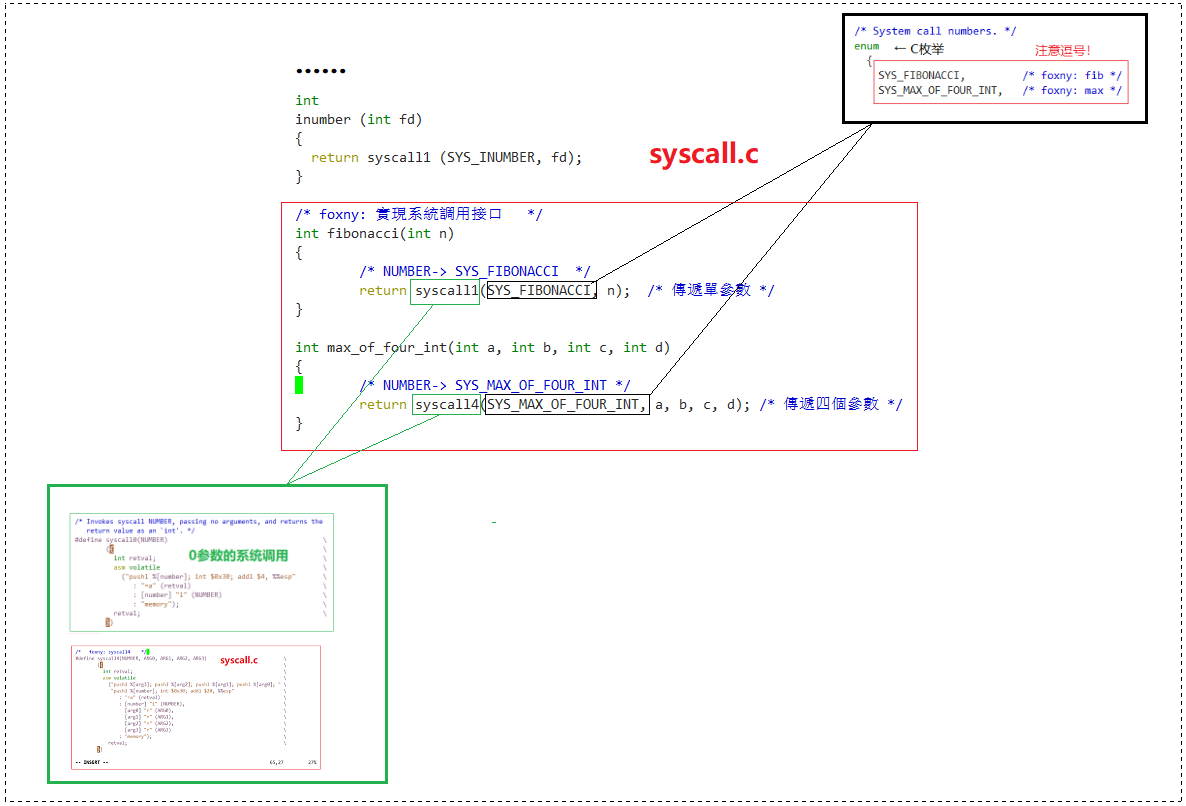
 啊哈哈哈哈哈哈,搞定!
啊哈哈哈哈哈哈,搞定!
在 userprog 下也是有个 syscall.c 文件的,如果你做过 Pintos Project1 你应该会对它很熟悉。
 我们需要在 userprog/syscall.c 这写上系统调用的功能实现:
我们需要在 userprog/syscall.c 这写上系统调用的功能实现:
$ cd pintos/src/userprog

至于 Fibonacci 和 max_of_four_int 函数的实现,和本篇博客主题无关(不是C基础教学),代码我直接给出,这不重要仅供参考。
💬 求第 个斐波那契数列(非递归法)
int fibonacci(int n)
{
/* Non-Rec method */
int a = 1;
int b = 1;
int c = 1;
while (n > 2) {
c = a + b;
a = b;
b = c;
n--;
}
return c;
}💬 求四数最大值:
int max_of_four_int(int a, int b, int c, int d)
{
int max = a; /* Suppose the first number is bigest */
if (max < b) max = b;
if (max < c) max = c;
if (max < d) max = d;
return max;
}

 实现完后保存退出即可,至此我们的任务就大功告成了。
实现完后保存退出即可,至此我们的任务就大功告成了。
💭 测试: pintos/src/userprog 下输入:
pintos --filesys-size=2 -p ../examples/additional -a additional -- -f -q run 'additional 10 20 62 40'🚩 效果演示:
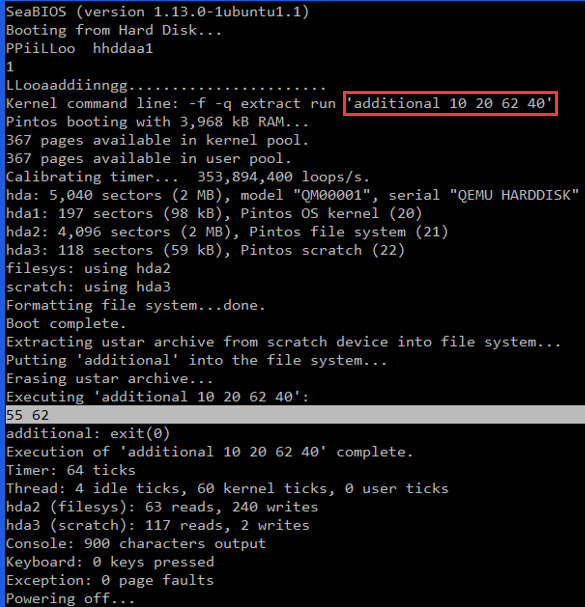
至此,新的用户级调用程序就增添完毕。

📌 [ 笔者 ] 王亦优
📃 [ 更新 ] 2023.1.18
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!| 📜 参考资料 C++reference[EB/OL]. []. http://www.cplusplus.com/reference/. Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. . 百度百科[EB/OL]. []. https://baike.baidu.com/. 比特科技. Linux[EB/OL]. 2021[2021.8.31 |
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
如何在ruby中调用C#dll? 最佳答案 我能想到几种可能性:为您的DLL编写(或找人编写)一个COM包装器,如果它还没有,则使用Ruby的WIN32OLE库来调用它;看看RubyCLR,其中一位作者是JohnLam,他继续在Microsoft从事IronRuby方面的工作。(估计不会再维护了,可能不支持.Net2.0以上的版本);正如其他地方已经提到的,看看使用IronRuby,如果这是您的技术选择。有一个主题是here.请注意,最后一篇文章实际上来自JohnLam(看起来像是2009年3月),他似乎很自在地断言RubyCL
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www